 Xilinx FPGA中的基础逻辑单元
Xilinx FPGA中的基础逻辑单元
Xilinx FPGA的组成部分
本文是以Xilinx Kintex UltraScale+ 系列为参考所写,其他系列有所不同,可以参考相应的user guide文档。
Xilinx家的FPGA有这么些基本组成部分:
Configurable Logic Block (CLB)可编程逻辑块
Block Memory存储器
Transceivers收发器
从Implemented Design中可以看到FPGA中资源大致分布如下。中间蓝色是CLB可编程逻辑块、DSP或BRAM,两侧的彩色矩形块是I/O接口和收发器,划分的方块是不同的时钟域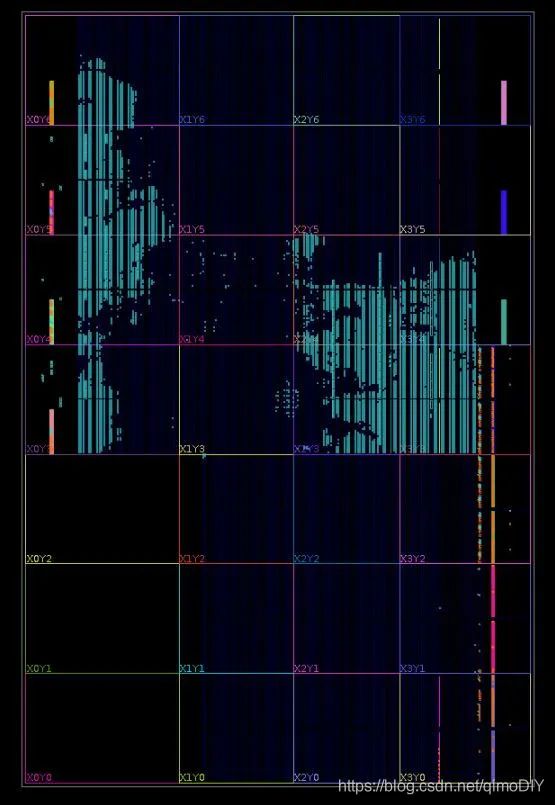
Configurable Logic Block (CLB)可编程逻辑块
CLB是FPGA内部实现可编程性的主要成分,其中可以包括:
LUT查找表
高速算术逻辑
分布式存储distributed memory或移位寄存器shift register logic (SRL) ability
Look-Up Table (LUT)查找表
每个CLB中包含一个slice,每个slice提供8个6输入查找表LUT和16个寄存器(slice就是CLB中一个小的分割,有的CLB中有两个,不知道怎么翻译这个词)。每个6输入LUT可以被设置成1个6输入查找表或者2个5输入查找表。可以这么配置的原因跟LUT结构有关。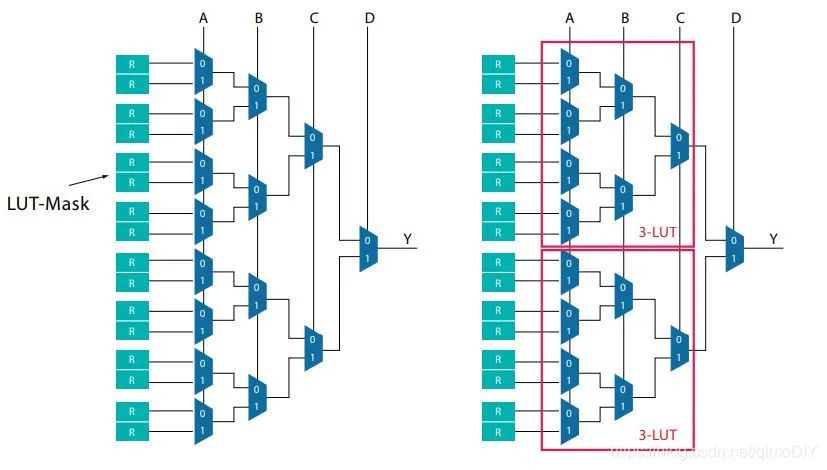
上图是一个4输入查找表的结构,[ABCD]作为4位二进制输入,总共有24=16种输入,每种输入对应的1位输出就存在左侧的寄存器中,因此查找表可以完成每一种二进制逻辑。在右侧可以看到一个4输入LUT其实是两个3输入LUT再加上一个2路复用器MUX,最后的MUX由新加入的一位控制,如果要拆开就把两个3输入LUT的结果绕开最后的MUX输出即可。同样就可以理解6输入LUT拆分成两个5输入LUT的原因。
之前介绍Altera的ALM时说过,LUT太深或太浅都不好,太深需要很多寄存器,而且MUX层数太多,延迟严重;太浅不方便配置逻辑,浪费过多空间。A家和X家根据客户实际使用情况调查过之后得到的结论相同,6输入LUT目前来说是最平衡的,如果需要的话就拆成小的LUT,一般以6输入为主。
LUT的输出如下,O6是作为6输入LUT的结果,O5是作为两个5输入LUT的结果,有2位。它的结果可以直接作为slice的输出,也可以传递到寄存器中储存。而存入寄存器的数据也可以不经过LUT,直接从外界读取。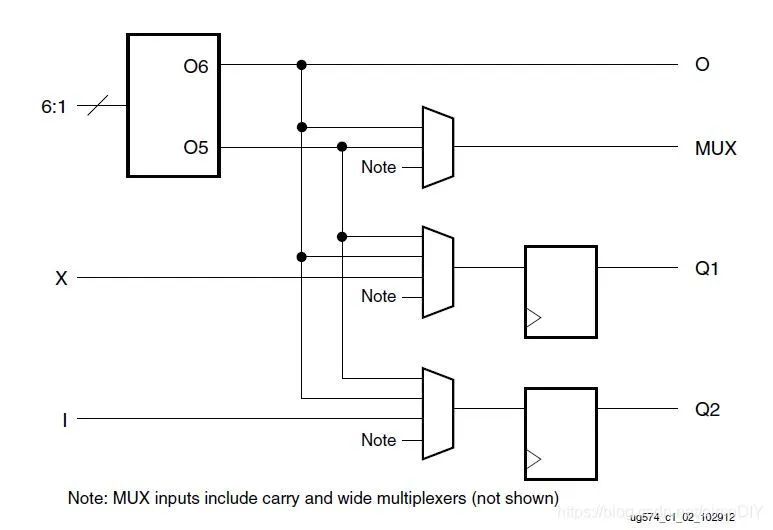
Xilinx的Toolchain会自动配置这部分内容,但是了解细节可以更好的利用FPGA中的资源,比如下面三段代码,第一段只用上了LUT查找表输出,第二段绕过了LUT输入到寄存器中,而第三段同时用上了LUT查找表和寄存器,可以说是对slice利用率最高的。
// Code 1
wire [1:0] output;
wire [5:0] input;
assign output[0] = input[0]&input[1]|input[2];
assign output[1] = input[3]|input[4]^input[5];
// Code 2
wire clk, rst;
reg [1:0] output;
reg [1:0] input; // Coming from previous registers
always @(posedge clk or posedge rst) begin
if(rst)
output <= 2'b00;
else
output <= input;
end
// Code 3
wire clk, rst;
reg [1:0] output;
wire [5:0] input;
always @(posedge clk or posedge rst) begin
if(rst)
output <= 2'b00;
else begin
output[0] <= input[0]&input[1]|input[2];
output[1] <= input[3]|input[4]^input[5];
end
end
在project比较小的时候自然不用注意这么多,project大大时候toolchain有一定的能力帮你平衡这些资源利用,这种抠牙缝的手段在FPGA特别小,或者代码太大,或者时钟很高时就有用了。在时钟高时,为了尽可能缩短信号之间的布线距离,能用寄存器缓冲的就要尽量用,但只是用pipeline的形式加入相当于浪费了一些slice中的LUT部分,最好的办法就是把寄存器加在逻辑中间,这样利用率就提高了。比如在不优化的情况下,第二段比第一段代码更高效,时钟环境更好(自己做总比不知道toolchain做了什么要好):
// Code 1
wire clk, rst;
wire [5:0] input;
reg [1:0] pipeline;
reg output;
always @(posedge clk or posedge rst) begin
if(rst) begin
pipeline <= 2'b00;
output <= 1'b0;
end
else begin
pipeline[0] <= &input; // And every bits from input
pipeline[1] <= pipeline[0]; // Pipeline it
output <= pipeline[1];
end
end
// Code 2
wire clk, rst;
wire [5:0] input;
reg [1:0] pipeline;
reg output;
always @(posedge clk or posedge rst) begin
if(rst) begin
pipeline <= 2'b00;
output <= 1'b0;
end
else begin
pipeline[0] <= &input[2:0]; // And first 3 bits from input
pipeline[1] <= &input[5:3]; // And last 3 bits from input
output <= pipeline[0] & pipeline[1];
end
end
高速算术逻辑
和Altera中的ALM相似,Xilinx的slice中也有小的加法器,使得小位数的加法、乘法、计数器可以在其中实现。但是高位数的算术运算就不适合在其中实现了,容易出现各种时钟问题,而且浪费大量逻辑资源,这种运算最好交给之后的DSP资源来实现。
分布式存储distributedmemory或移位寄存器shift register logic (SRL) ability
Slice也分两种,前面介绍的是普通的SLICEL (logic),也就是逻辑slice,还有一种是强化了存储功能的SLICEM (memory),也就是存储slice。SLICEM也可以当作SLICEL用,拥有SLICEL的一切功能,但SLICEM添加了地址线write address端口和写使能write enable端口,使得6输入LUT中的26=64个寄存器可以被配置成64-bits RAM,8个6输入LUT合起来就可以是一个512-bit RAM。

Xilinx还有一个特殊的设计,可以让这64 bits互相连接变成一个移位寄存器,比起使用后面的register寄存器利用率高很多。举个栗子的话:
// Shift registers
genvar i;
wire [3:0] addr_1 = 4'd15;
wire [41:0] D_1;
wire [41:0] Q_1;
assign D_1 = input;
assign output = Q_1;
// 42bit X 16
generate
for(i=0; i<42; i=i+1) begin : Shift
SRL16E #(
.INIT(16'h0000), // Initial contents of shift register
.IS_CLK_INVERTED(1'b0) // Optional inversion for CLK
)
Shift_UP2_1 (
.Q(Q_1[i]), // 1-bit output: SRL Data
.CE(1'b1), // 1-bit input: Clock enable
.CLK(clk), // 1-bit input: Clock
.D(D_1[i]), // 1-bit input: SRL Data
// Depth Selection inputs: A0-A3 select SRL depth
.A0(addr_1[0]),
.A1(addr_1[1]),
.A2(addr_1[2]),
.A3(addr_1[3])
);
end
endgenerate
也许有人会想,为什么要考虑那么多小技巧把代码变复杂,硬件编程跟软件编程的不同就在这里,用实际电路的思维来考虑,它的实现情况和用指令集数据库的软件编程有很多不同点。写简单的代码有时候被编译后就变成低效的结构。新手写RTL代码会出现a=b*c;这种,每次看到都会头皮发麻。
因此设计RTL时,推荐这种优化步骤:
尽量少用reset,并且不要同时用同步reset和异步reset
寄存器很多,能用尽量用,对时钟环境好(不要用always *,同样看到头皮发麻)
写寄存器的控制信号简单点,尽量也用寄存器pipeline一下
移位寄存器比较特殊,不要用复位信号,尽量用上LUT中的SRL,reset信号会让tool避免用SRL
少于64bits的存储用SLICEM来做,Xilinx tool中一般叫LUTRAM
位数较高的加法、计数器,以及尽可能所有常常调用的乘法用DSP来实现
Block Memory存储器
在CLB中的LUTRAM之外,Xilinx芯片中的内置存储器就是BRAM存储器了。每个BRAM可以被配置成两个独立的18kb RAM或者一个36kb RAM,每个BRAM有两个独立的读写端口
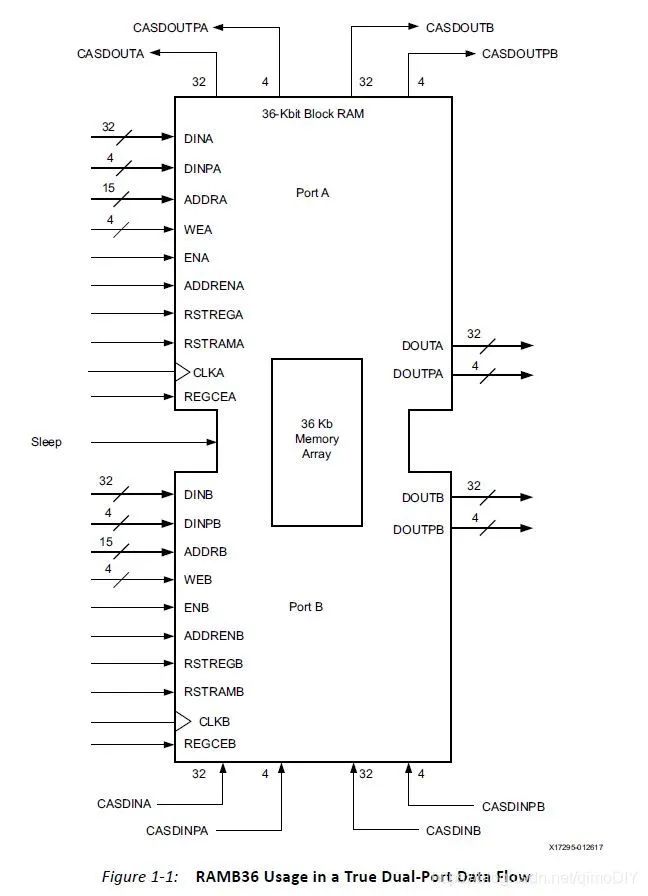 如果一个36kb的BRAM不够用,还可以把多个BRAM连接在一起:
如果一个36kb的BRAM不够用,还可以把多个BRAM连接在一起:
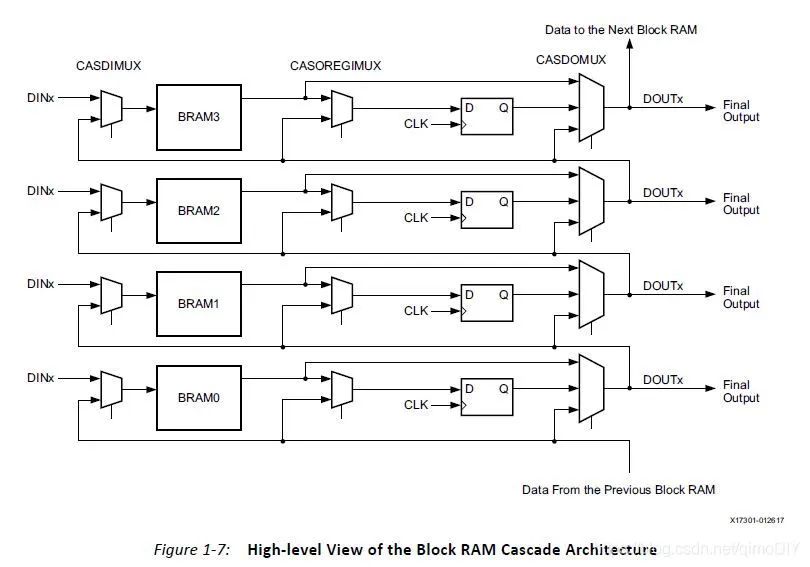
DSP数字信号处理器
Xilinx的FPGA中高位加法和乘法主要是由DSP数字信号处理器承担的,其结构如下
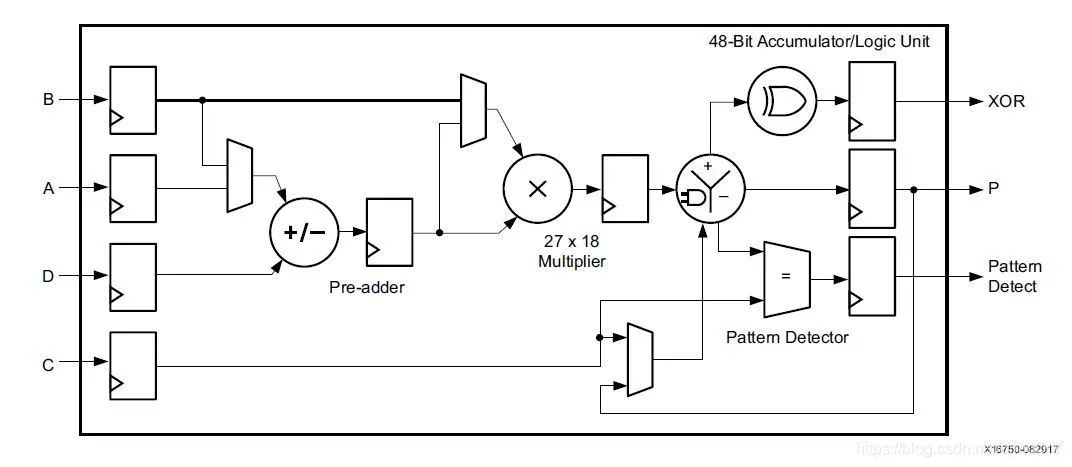 根据不同的配置,可以构成一系列公式,比如下面几种 P = ( A ± D ) ∗ B + C P = B 2 + P P = A ± D ± C P=(Apm D)*B+C P=B^2+P P=Apm Dpm CP=(A±D)∗B+CP=B2+PP=A±D±C
根据不同的配置,可以构成一系列公式,比如下面几种 P = ( A ± D ) ∗ B + C P = B 2 + P P = A ± D ± C P=(Apm D)*B+C P=B^2+P P=Apm Dpm CP=(A±D)∗B+CP=B2+PP=A±D±C
和Altera FPGA中的DSP相比,两个乘法器变成一个,多了平方选项和XOR逻辑,以及比较逻辑。相比起来Xilinx FPGA中的DSP虽然集成度没有那么高,但灵活性更高,更方便配置成各种需要的形式,设计FIR这类结构时,可以很明显感受到Xilinx中的DSP设计出的结构复杂度低很多,不需要考虑两个乘法器带来的协同性问题。
调用Xilinx的DSP有比较多的注意事项,代码也相对较长,之后可以单独写一篇。
Transceivers收发器
在Kintex UltraScale+系列中的收发器有Gigabit Transceivers H/Y (GTH/GTY)两种,后面的H和Y代表不同的传输速率,具体是哪个单词没有找到。这些高速收发器可以承担不同的接口任务,常见的有PCIe、SFP、10G网、SATA等。
让传输速率更高一直是通信行业的核心问题,这个毋庸置疑,无论哪种接口,要在FPGA上实现,不可避免的要用到这些收发器。
这里的细节太多,全写一遍可以出一本书,我也只懂些皮毛,这里放一张大概的结构图,挖个坑等我边写边填。 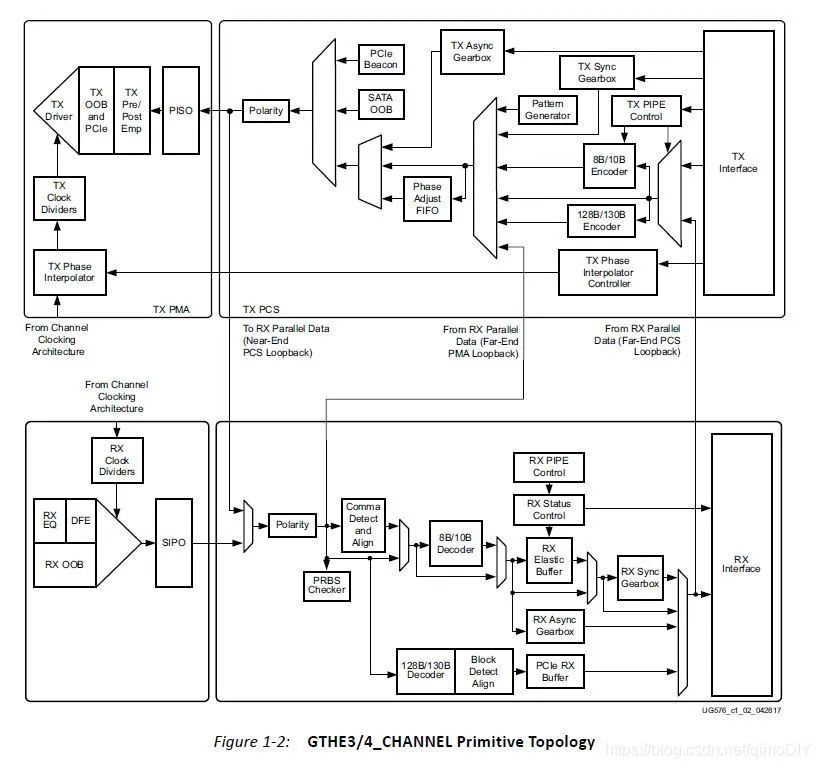
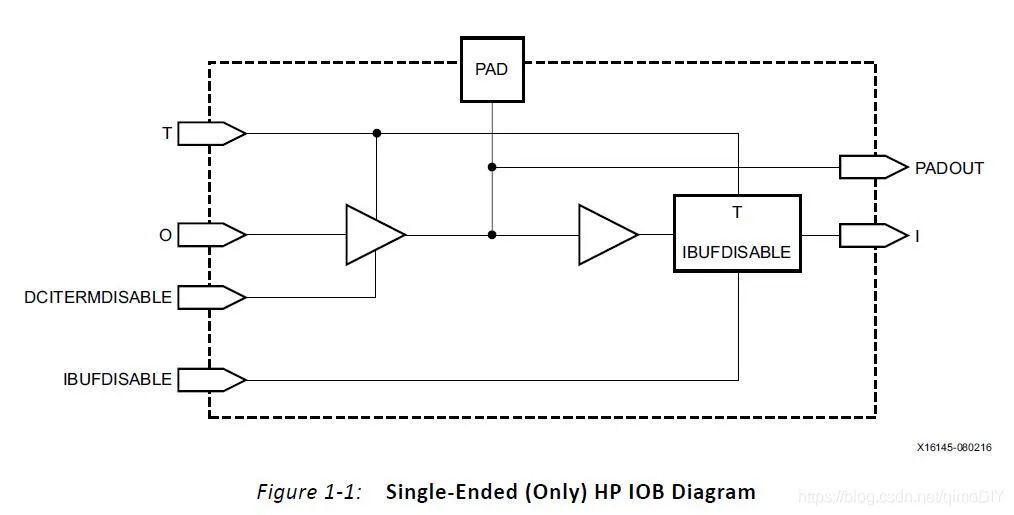
I/O pins输入输出端口
在Xilinx UltraScale系列中有三种I/O bank,一种是High-performance (HP)高性能、High-density (HD)高密度、High-range(HR)大范围。HP可以满足1.8V以下信号的性能需求,HD可以在支持低速接口的情况下尽可能减小面积,HR可以支持更多的3.3V以下标准。
总结
在我看来,和Altera的FPGA相比,Xilinx的FPGA与之最大区别就是DSP的不同。虽说两个公司对一些资源的名称不同,分割方式不同,但其逻辑的主体LUT没有太大区别,BRAM的区别也不大,只有DSP有结构上的不同。至于对外的接口,个人认为对内部逻辑影响不大。
-
dsp
+关注
关注
553文章
7987浏览量
348745 -
FPGA
+关注
关注
1629文章
21729浏览量
602986 -
Xilinx
+关注
关注
71文章
2167浏览量
121303 -
Altera
+关注
关注
37文章
781浏览量
153920 -
可编程逻辑
+关注
关注
7文章
515浏览量
44083
原文标题:Xilinx FPGA中的基础逻辑单元
文章出处:【微信号:gh_9d70b445f494,微信公众号:FPGA设计论坛】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
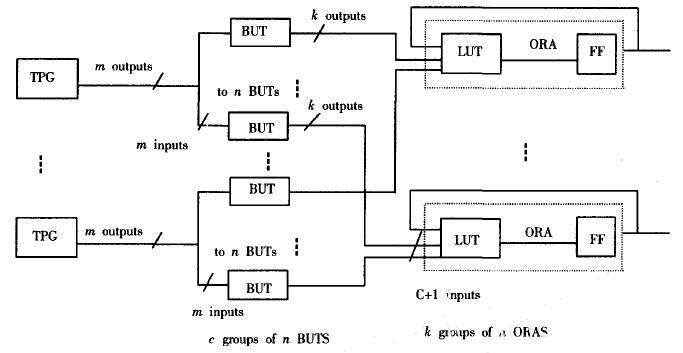
基于BIST利用ORCA结构测试FPGA逻辑单元的方法

如何在LUT和逻辑元件之间以及逻辑元件和逻辑单元之间进行交换
如何解决通用Xilinx FPGA DSP片和逻辑单元上的问题?
数字设计FPGA应用:FPGA的基本逻辑结构
xilinx7系列FPGA的7种逻辑代码配置模式






 工商网监
工商网监
评论