 纳多德视点 | InfiniBand十大优势
纳多德视点 | InfiniBand十大优势

InfiniBand(直译为“无限带宽”技术,缩写为IB)是一个用于高性能计算的计算机网络通信标准,它具有极高的吞吐量和极低的延迟,用于计算机与计算机之间的数据互连。
在最新发布的全球最强超级计算机排名 Top500 的榜单中,InfiniBand 网络再次以绝对的数量和性能优势蝉联超级计算机互连设备数量榜首,比上次排行榜的数量又有了大幅度的增长。纵观这次的榜单,可以归纳出以下三个趋势:
基于InfiniBand网络的超级计算机以197台的数量大幅领先于其它网络技术。特别在 Top100 的系统中,基于 InfiniBand 网络的超级计算机更是遥遥领先,InfiniBand 网络已经成为了追求性能的超级计算机的标配。
NVIDIA网络产品成为Top500系统中的主流互连设备,其中超过三分之二的超级计算机在使用NVIDIA网络互连,NVIDIA 网络的性能和技术领先性已经得到了广泛认可。
还值得一提的是,InfiniBand网络不仅在传统的HPC业务,在企业级数据中心和公有云上也已被广泛使用。目前性能第一的企业级超级计算机NVIDIA Selene 和微软公司的Azure公有云都在利用InfiniBand网络来发挥其超高的业务性能。
无论是数据通讯技术的演进、互联网技术的革新、还是视觉呈现的升级,都是得益于更强大的计算、更大容量更安全的存储以及更高效的网络;基于InfiniBand网络为基础的集群架构方案,不仅可以提供更高带宽的网络服务,同时也降低了网络传输负载对计算资源的消耗,降低了延时,又完美地将HPC与数据中心融合。
为什么InfiniBand网络在 Top500 中受到如此高的重视?其性能优势起到了决定性的作用。下面,纳多德将InfiniBand十大优势总结如下:
1. 简单的网络管理
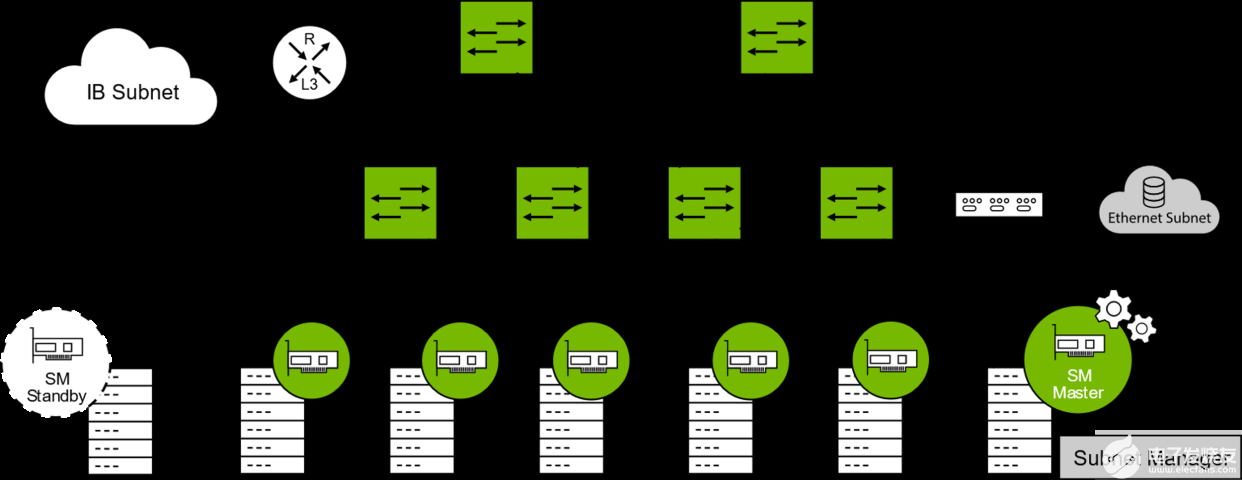
InfiniBand是第一个真正意义上原生按照SDN设计的网络架构,它由子网管理器来管理。
子网管理器对本地子网进行配置并确保能连续运行。所有的信道适配器和交换机都必须实现一个SMA,该SMA与子网管理器一起实现对通信的处理。每个子网必须至少有一个子网管理器来进行初始化管理以及在链路连接或断开时对子网进行重新配置。通过仲裁机制来选择一个子网管理器作为主子网管理器,而其他子网管理器工作于待机模式(每个待机模式下的子网管理器都会备份此子网的拓扑信息,并检验此子网是否能够运行)。若主子网管理器发生故障,一个待机子网管理器接管子网的管理以确保不间断运行。
2. 高带宽
自InfiniBand诞生以来,很长一段时间InfiniBand网络速率的发展都是快于Ethernet的,主要原因就是因为InfiniBand应用于高性能计算中服务器之间的互连,对带宽上的需求更高。

各个速率的缩写如下:
SDR - Single Data Rate
DDR - Double Data Rate
QDR - Quad Data Rate
FDR - Fourteen Data Rate
EDR - Enhanced Data Rate
HDR - High Dynamic Range
NDR - Next Data Rate
XDR - eXtreme Data Rate
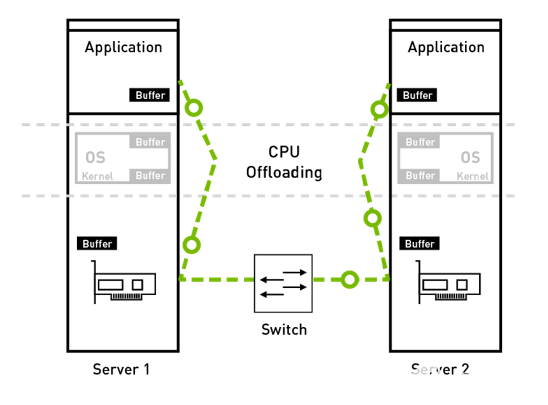
加速计算的一个关键技术,是CPU卸载。InfiniBand网络架构可以以最少的CPU资源来传输数据,这点是通过下面的方式来做到的:
硬件卸载整个传输层协议栈
Bypass内核,zero copy
RDMA,把一个服务器内存中的数据直接写入另一台的内存,不需要CPU的参与
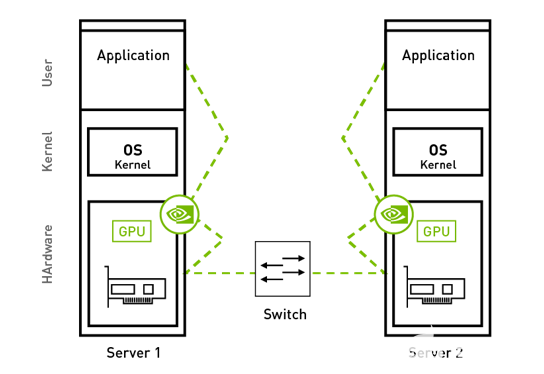
同时可以使用GPU Direct技术,可以直接访问GPU内存中的数据,将GPU内存中的数据传输到其他节点。这样可以加速计算类的应用,比如AI, Deep Learning等。
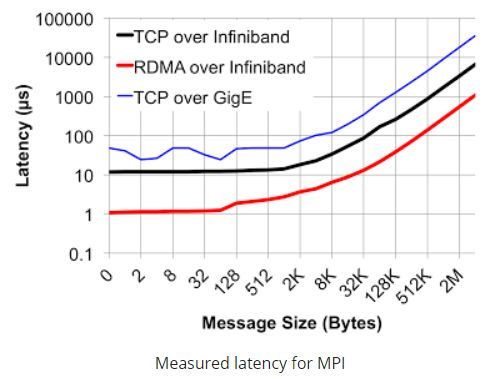
4.低延迟
此处主要分为两部分进行对比,一部分在交换机上,作为网络传输模型中的二层技术,Ethernet交换机普遍采用了MAC查表寻址和存储转发的方式(有部分产品借鉴了InfiniBand的Cut-though技术)由于需要考虑诸如IP、MPLS、QinQ等复杂业务的处理,导致Ethernet交换机处理流程较长,一般会在若干us(支持cut-though的会在200ns以上),而InfiniBand交换机二层处理非常简单,仅需要根据16bit的LID就可以查到转发路径信息,同时采用了Cut-Through技术大大缩短了转发时延至100ns以下,远远快于Ethernet交换机;网卡层面如前所述,采用RDMA技术,网卡转发报文不需要经过CPU,大大加快了报文在封装解封装处理的时延,一般InfiniBand的网卡收发时延(write,send)在600ns,而基于Ethernet上的TCP UDP应用的收发时延会在10us左右,相差十几倍之多。
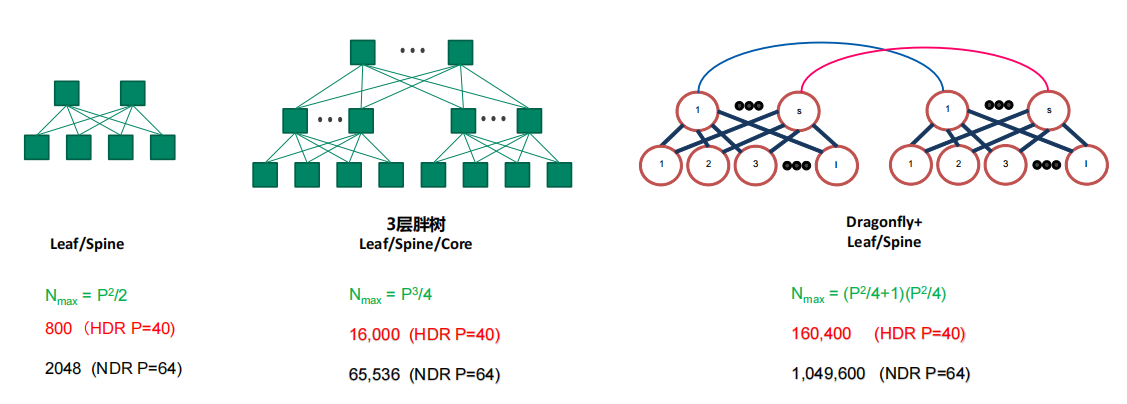
5.扩展性和灵活性
IB网络一个主要的优势就是单个子网可以部署一个48,000节点,形成一个巨大的2层网络。而且IB网络不依赖ARP等广播机制,不会产生广播风暴或者额外的带宽浪费。
多个IB子网也可以通过路由器和交换机连接。
IB支持多种网络拓扑:
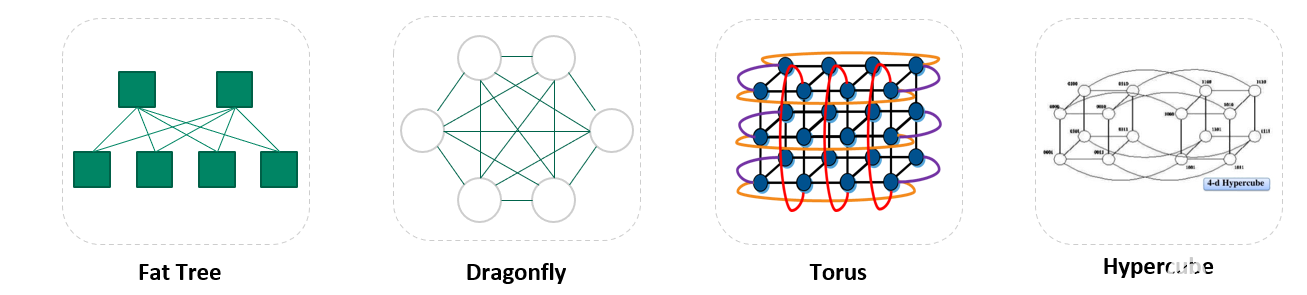
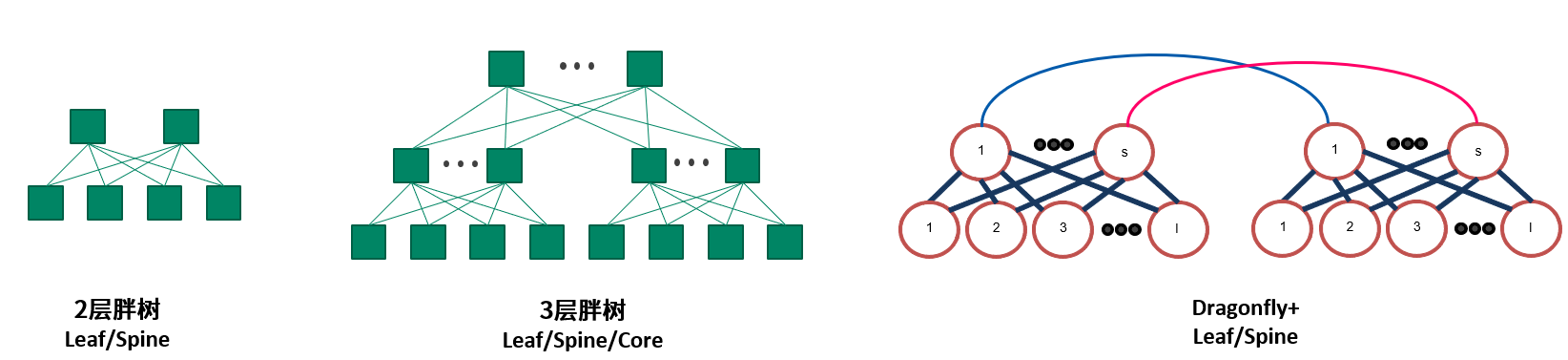
规模较小时,建议选用2层fat-tree。更大规模可以采用3层fat-tree的组网拓扑。一定规模以上,可以采用Dragonfly+的拓扑节约一部分成本。
6.QoS
如果多个不同的应用在同一个子网运行,并且其中一些应用需要比其他更高的优先级,IB网络如何提供QoS支持呢?
QoS是一种能力,可以为不同的应用,用户或者数据流提供不同的优先级服务。高优先级的应用可以被映射到不同的端口队列,队列里的报文可以被优先发送。
InfiniBand采用虚通道(VL,即Virtual Lanes)方式来实现QoS。虚通道是一些相互分立的逻辑通信链路,它们共享一条物理链接,每条物理链接可支持多达15条的标准虚通道和一条管理通道(VL15)。
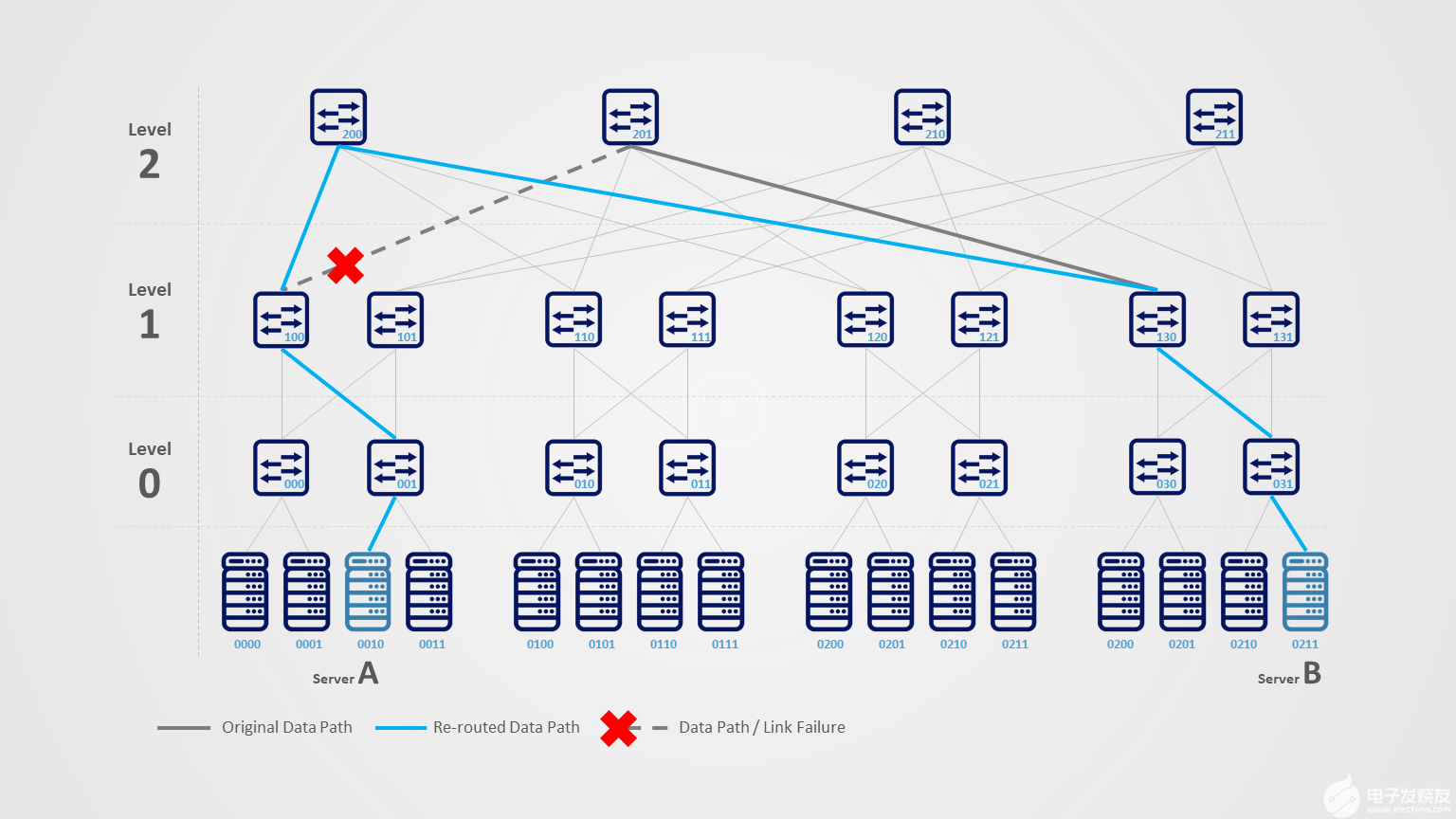
7.网络稳定性和弹性
理想情况下,网络非常稳定,没有任何故障。但是长期运行的网络不可避免的会出现一些故障,InfiniBand如何处理这些失败,并且快速恢复的呢?
NVIDIA IB解决方案提供一个机制,叫做Self-Healing Networking。自愈网络是一个硬件能力,它基于IB交换机。自愈网络可以让链路故障恢复的时间仅仅需要1毫秒,比普通的恢复时间快5000x倍。
8.优化的负载均衡
在高性能数据中心里面,一个很重要的需求,是如何提高网络的利用率。其中一种方法是使用负载均衡。
负载均衡是一种路由策略,它让流量在多个可用端口上发送。
Adaptive Routing就是这样一个特性,它可以让流量在交换机端口上均匀的分布。AR在交换机上硬件支持,由Adaptive Routing Manager管理。
当AR开启,交换机上的Queue Manager会监测所有GROUP EXIT端口的流量,均衡每个队列的负载,把流量导向利用率低的端口。AR支持动态负载均衡,避免网络拥塞,并最大化网络带宽利用率。
9.网络计算 - SHARP
IB交换机还支持网络计算的技术,SHARP – Scalable Hierarchical Aggregation and Reduction Protocol.
SHARP是一个基于交换机硬件的软件,并且是一个集中管理的软件包。
SHARP可以把原来在CPU和GPU上运行的集合通信offload到交换机上,优化集合通信,避免了节点间的多次数据传输,减少了需要在网络上传输的数据量。因此,SHARP可以极大的提升加速计算的性能,基于MPI应用,比如AI,机器学习等等。
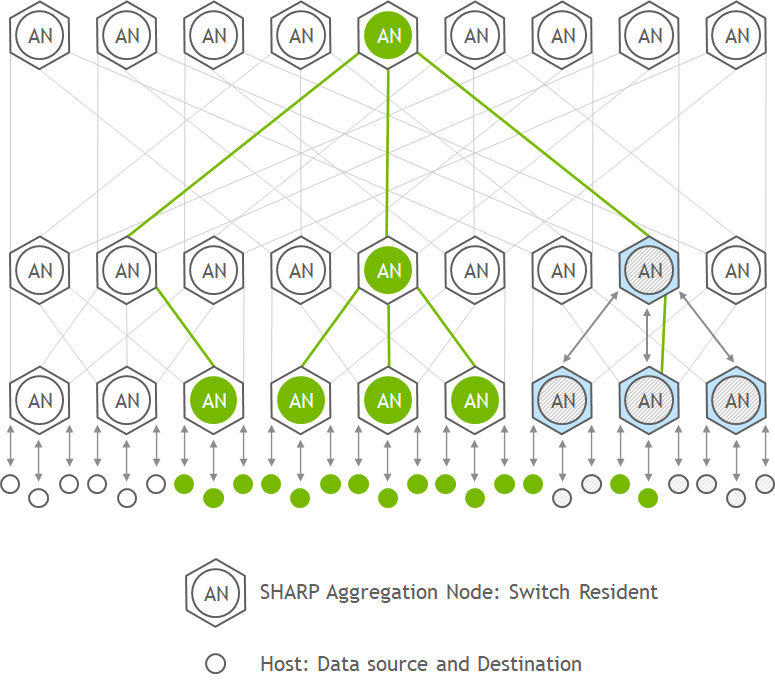
10.支持多种网络拓扑
InfiniBand网络可以支持非常多的topo,比如:
Fat Tree
Torus
Dragonfly+
Hypercube
HyperX
支持不同的网络topo,从而满足不同的需求,比如:
易于网络扩展
降低TCO
最大化阻塞比
最小化延迟
最大化传输距离
Infiniband凭借着无与伦比的技术优势,极大简化了高性能网络架构,并降低了多级架构层次造成的延时,为关键计算节点接入带宽的平滑升级提供有力支撑。InfiniBand 网络凭借其极致的性能,不断创新的技术架构,在更低功耗、更少硬件设备的前提下帮助用户实现了业务性能的最大化,其进入越来越多的使用场景自是大势所趋。
纳多德是NVIDIA网络产品的Elite Partner,携手NVIDIA实现光连接+网络产品与解决方案的强强联合,尤其是在InfiniBand高性能网络建设与应用加速方面拥有深刻的业务理解和丰富的项目实施经验,可根据用户不同的应用场景,提供最优的InfiniBand高性能交换机+智能网卡+AOC/DAC/光模块产品组合方案,为数据中心、高性能计算、边缘计算、人工智能等应用场景提供更具优势与价值的光网络产品和整体解决方案,以低成本和出色的性能,大幅提高客户业务加速能力。
审核编辑黄昊宇
-
InfiniBand
+关注
关注
1文章
29浏览量
9239
发布评论请先 登录
相关推荐
兆芯荣获2024年度十大信创芯片品牌
年度电解槽十大品牌+年度制氢十大供应商,稳石氢能荣获两大奖项!
华为发布2025数据中心能源十大趋势
华为发布2025充电网络产业十大趋势
华为发布2025智能光伏十大趋势
敦泰荣获车载显示年度十大知名品牌
InfiniBand网络内计算的关键技术和应用
InfiniBand与以太网的对比分析

“智能网联汽车全球十大发展突破”在京发布

中国信通院发布“2024云计算十大关键词”
AI浪潮下的十大消费者新趋势
度亘核芯荣获“2023年度中国十大光学产业技术”奖

深入探索InfiniBand网络、HDR与IB技术






 工商网监
工商网监
评论