 AMD-Xilinx FPGA功耗优化设计简介
AMD-Xilinx FPGA功耗优化设计简介

对于FPGA来说,设计人员可以充分利用其可编程能力以及相关的工具来准确估算功耗,然后再通过优化技术来使FPGA和相应的硬件设计满足其功耗方面的要求。
一、静态功耗和动态功耗来由以及其变化规律
在28nm工艺时,电流泄漏问题对ASIC和FPGA都变得严重,在16nm工艺下这一问题同样更加具有挑战性。为获得更高的晶体管性能,必须降低阈值电压,但同时也加大电流泄漏。AMD-Xilinx公司在降低电流泄漏方面做了许多优化后,源于泄漏的静态功耗在最差和典型工艺条件下的变化仍然有2:1。其泄漏功耗受内核电压(VCCINT)的影响很大,大约与其立方成比例,哪怕VCCINT仅上升5%,静态功耗就会提高约15%。另外泄漏电流还与结(或芯片)温密切相关。
FPGA中静态功耗的其它来源是工作电路的直流电流,但在很大程度上,这部分电流随工艺和温度的变化不大。例如I/O电源(如HSTL、SSTL和LVDS等I/O标准的端接电压)以及LVDS等电流驱动型I/O的直流电流。有些FPGA模拟模块也带来静态功耗,但同样与工艺和温度的关系不大。例如,Xilinx FPGA中用来控制时钟的数字时钟管理器(DCM)、锁相环(PLL),以及Xilinx FPGA中用于输入和输出IO可编程延迟的单元IODELAY。
动态功耗是指FPGA内核或I/O的开关活动引起的功耗。为计算动态功耗,是需要知道开关晶体管和连线的数量、电容和开关频率。在FPGA器件里面晶体管在金属连线间实现逻辑和可编程互连,电容则包括晶体管寄生电容和金属互连线电容。
动态功率的公式:PDYNAMIC=nCV2ƒ,其中,n=开关结点的数量,C=电容,V=电压摆幅,f=开关频率。
AMD-Xilinx在20nm & 16nm节点Ultrascale系列器件使用FinFET工艺,FinFET与Planar相比在相同速度条件下功耗低20%-50%。FinFET工艺通过抬升沟道,包裹沟道四周的栅极可以创建一种完全耗尽型沟道,从而克服平面晶体管的漏电流问题。FinFET所具有的更好的沟道控制能力可以用来实现更低的阈值和供电电压,从而来控制器件的功耗。
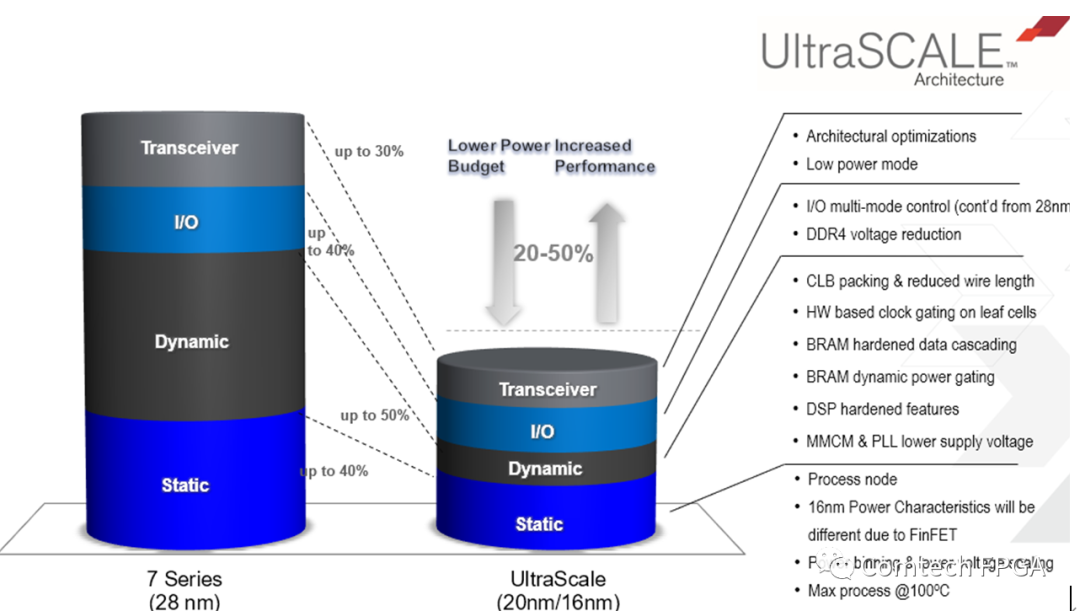
更紧凑的逻辑封装(通过内部FPGA架构改变)可以减少开关晶体管的数量,也可以采用更小尺寸的晶体管可以缩短晶体管之间的连线长度,从而降低动态功率。Ultrascale+ FPGA中的16nm晶体管栅极电容更小、互连线长度也更短,两者完美的结合起来可将结点的电容减小约15%至20%,这可进一步降低动态功率。
电压对于动态功率同样有比较大的影响。从28nm转向16nm工艺,仅仅通过将VCCINT从1.0V降至0.72V,Ultrascale FPGA设计的动态功率就降低了约50%。再加上结构增强带来的功率降低,总的动态功耗比28 nm工艺技术时降低达40%至50%。
(注:动态功率与VCCINT的平方成正比,但对于FPGA内核来说基本上与温度和工艺无关。)
二、利用FPGA设计技术降低功耗
Xilinx公司提供了两款功率分析工具。XPower Estimator (XPE)电子数据表工具可在设计人员在没有做实际的硬件和RTL设计前使用。在设计实施完成后,则可以采用第二款工具XPower Analyzer来检查所做的改变对功耗的影响。
降低功耗的一种方法就是为设计选择与需要最匹配的FPGA型号,然后利用其可编程能力进一步优化设计的功耗。正确的设计会同时优化静态功耗和动态功耗。源于泄漏电流的静态功率正比于逻辑资源的数量,也就是说正比于构造特定FPGA所使用的晶体管数量。因此,如果减少所使用的FPGA资源,采用更小的器件实现设计,那么就可以降低静态功耗。降低设计的规模有很多种的方案,最基本的一种技巧就是逻辑功能分时复用。如果两组电路完成一组线性功能并且彼此完全相同,那么就可以只用一组电路但将速率提高一倍来完成同样的功能,这样需要的逻辑资源就减少一半。另一种缩小逻辑规模的方法是利用Xilinx FPGA的部分重配置功能,当两部分电路不同时工作时,可以在某个时间段将某部分电路重新配置实现另一种电路功能。同时尽量保证不要让设计的时序太紧张,因为时序紧张会需要更多的逻辑和寄存器。
此外,还应当充分发挥FPGA架构中集成的硬IP块(BRAM、DSP、FIFO、Ethernet MAC、PCI Express)的优点。
如果资源充足的情况将功能移动到不太受限制的资源,例如,将状态机转移到BRAM、或者将计数器转移到DSP48模块、寄存器转移到移位寄存器逻辑,以及将BRAM转移到查找表RAM(LUTRAM)。
如下几种是常用优化资源节省功耗方式:
1.避免冗余DCM或PLL,优先使用PLL(相对MMCM省电),简单分频功能使用BUFGCE_DIV替代DCM或PLL;
2.Slice中移位寄存器实现寄存器打拍,注意slice移位寄存器无法实现复位;
3.硬核DSP& Block RAM优化时序尽量使用内部寄存器打拍,注意DSP& Block RAM硬核内部寄存器不支持异步复位;
4.Block RAM 增加CE需要使用数据时候才输出数据节省功耗;
5.级联Block RAM尽量拼深度,任何时候只打开其中一个Block RAM;
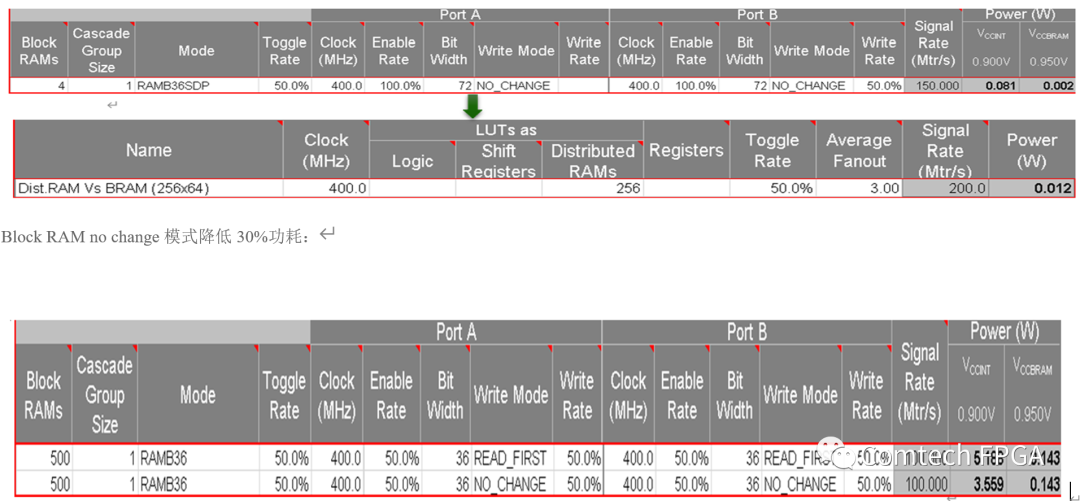
6.Block RAM no change模式降低30%功耗;
7.BUFGCE(扇出100K)或者BUFCE_LEAF(扇出100K)实现门控时钟降低功耗;
8.如果DSP27x18有效位宽10x10,尽量使用高位A[26:16] X [17 :7]低位填充0(进位链使用少),常量放B数据口降低功耗。
a、检查时钟资源使用是否合理
降低静态功率的另一个方法是仔细检查设计,避免冗余的直流电源消耗。设计中经常会使用到具有多余或隐藏DCM或PLL的模块,这种情况可能在模块设计后忘记将多余的资源去除,或者在构建下一代产品时使用了一些遗留代码。将DCM或PLL抽象到设计的顶层,这样模块之间就可以共享资源,从而可进一步减小设计的规模并降低直流功率。PLL相对MMCM省电,在PLL & MMCM同时满足设计需要的情况下优先使用PLL。在简单分频应用场景,使用BUFGCE_DIV替代DCM或PLL。
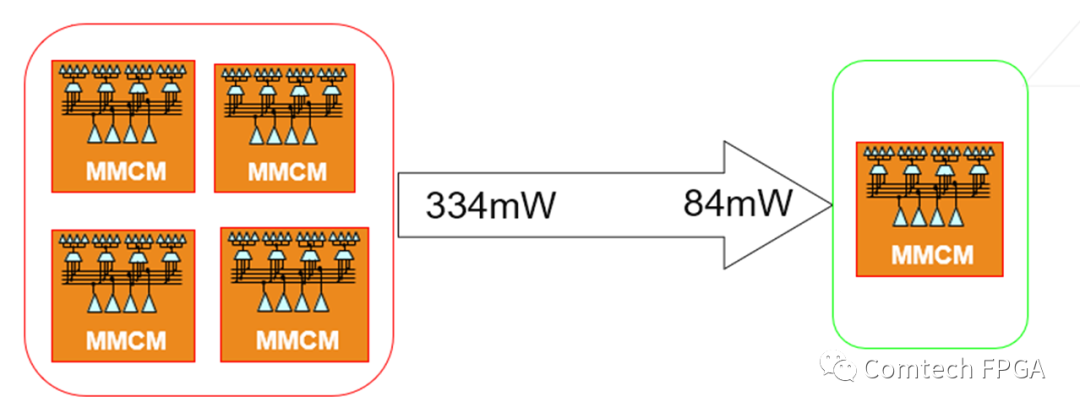
优化存储器模块使用可降低FPGA设计的动态功耗,从而进一步降低总体功耗。由于动态功耗受到容抗(面积或长度)和频率的函数影响比较大,因此应当检查设计中访问块存储器的方式并确定能够对容抗和频率进行优化的区域。
b、优化RAM的使用
AMD-Xilinx FPGA提供两种类型存储器阵列BRAM和LUTRAM。18Kbit或36Kbit的BRAM是针对大存储器模块而优化的,LUTRAM基于FPGA中的查找表,是针对细粒度存储而优化。Xilinx Ultrascale FPGA中,LUTRAM的单位是64bit。在这两种类型中,BRAM功耗更大一些,那么启用BRAM后静态功率是其功耗的最大部分,而其跳变的功耗相对动态功耗小。设计人员可以采取一些步骤来优化BRAM的功耗。例如,仅在读或写周期才启用BRAM;对于较小的存储器模块可以使用LUTRAM来代替BRAM,将BRAM留给较大的存储器模块使用。另一种技术是合理安排存储器阵列来减少其占用的延迟面积、使性能最大化并尽量降低其功耗。Xilinx工具也可以帮助选择适合的存储器阵列。例如考虑某个设计中需要两组存储器区域,可以先比较256 x 64bit存储器结构的功率,通过XPE工具显示出小存储器阵列最好用LUTRAM来实现,这样比用BRAM节约85%的功耗。这是因为如果采用BRAM的话,只能用4个36K位的模块来实现1个(256 x 64bit)4 Kbit的存储器,有很多空间被浪费。
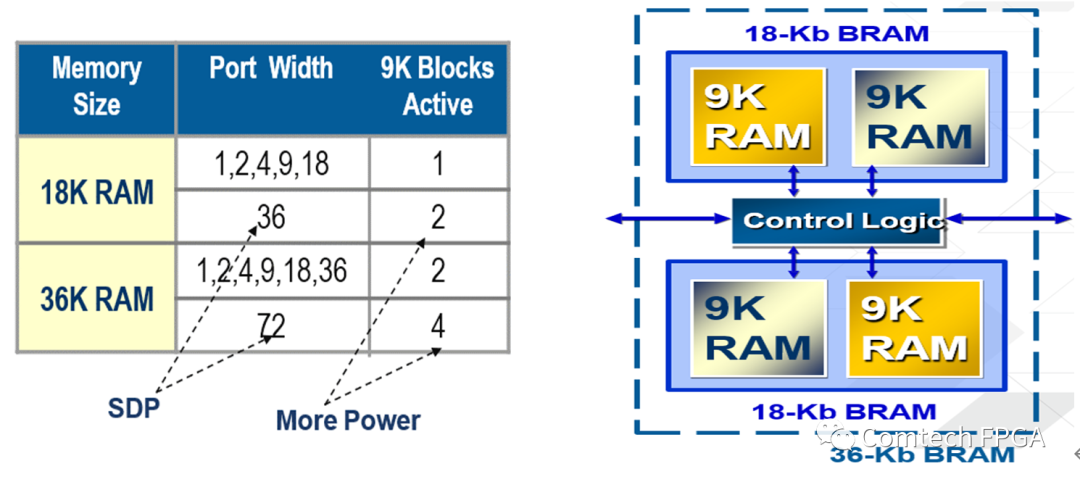
36Kb Block RAM 可以当成两个18Kb Block RAM使用,18(数据位宽) x 512(数据深度)时消耗一个9Kbit block,同样9Kbit Block RAM大小的存储空间36(数据位宽) x 256(数据深度)消耗两个9Kbit Block RAM。36Kb Block RAM 可以当成一个36Kb Block RAM使用时,36(数据位宽) x 512(数据深度)时消耗两个9Kbit Block RAM,同样18Kbit Block RAM大小的存储空间72(数据位宽) x 256(数据深度)消耗四个9Kbit Block RAM。
Block RAM增加CE需要使用数据时候才输出数据节省功耗:
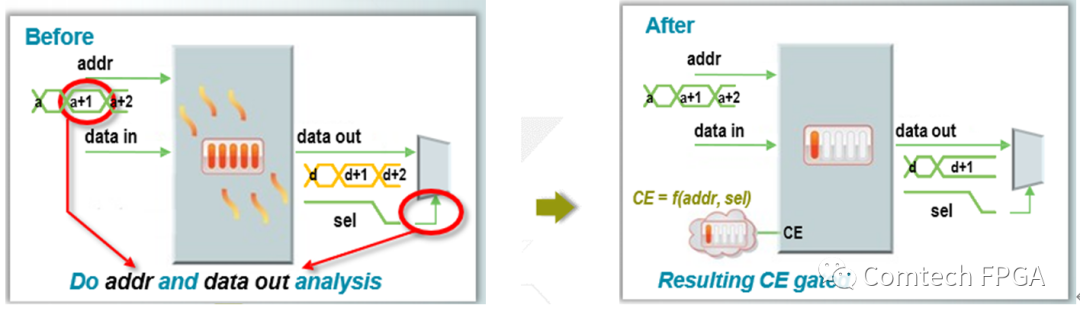
c、AMD-Xilinx FPGA的时钟门控功能
利用BUFGMUX时钟缓冲器将FPGA内的某个全局时钟关闭,或者动态选择较慢的时钟。还可以使用BUFGCE时钟缓冲器进行按时钟周期(cycle-by-cycle)的门控,与ASIC设计中使用的时钟门控技术类似。在实际设计中可以同时使用这两种功能。在某些设计中,一些模块并非始终使用,但对于功耗影响却很大,此时这些方法非常有用。以时钟周期为基础或者按多个时钟周期的组合开启或关闭可能有成千上万个负载规模大型时钟域。
d、在电路板级功耗降低
PCB设计师、机械工程师和系统架构师在电路板级可以考虑通过以下几个方面来降低FPGA的功耗,FPGA的内核电压和结温对于功耗的不同方面都有很强的影响。
控制VCCINT内核电压是板级降低功耗的一种方法。源于泄漏的静态功耗以及动态功耗都高度依赖于FPGA的内核电压。因此,减少泄漏的一种方法就是将内核电压设置在接近额定值的地方,而不是工作在Ultrascale电压范围0.85V(0.876V = +5%)。
采用现代开关稳压器,可以获得±1.5%的电压稳定度,而不是标准的±5%规格。保持内核电压在0.85V(而不是最大值0.876V),可将泄漏导致的静态功耗降低15%,同时动态功耗降低10%。
降低FPGA结温的一种简单明显的方法是利用散热更好的PCB或散热器。FPGA设计人员只要能够降低功耗的优化都是值得去尝试设计的。在结温100℃左右时,15℃的温度降低可以将源于泄漏导致的静态功耗降低20%。通过监控FPGA中的温度和电压也可以降低功耗。Ultrascale FPGA中包含一个称为System Monitor的模拟模块,可以监控外部和内部模拟电压以及芯片内部温度。System Monitor基于一个10位的A/D变换器,能够在-40℃至+125℃范围内提供准确可靠的测量结果。A/D变换器将片上传感器的输出数字化,可以利用它来监控多达17路外部模拟输入,从而监控系统性能与外部环境。模块内包括可配置的阈值和告警电平,通过可配置寄存器内存储测量结果,因此可方便地连接到用户逻辑或微处理器。
此外,I/O功率成为在功耗和性能平衡过程中需要考虑的另一重要因素,通过更为优化的I/O选择可以进一步降低总体功耗,驱动力量大电平标准所消耗的功率也更大,因此功率随输出速率和跳变速率线性变化。然而LVDS是个例外,因为它采用了与跳变速率无关的固定电流源,使用serial transceiver替代并行LVDS并行组实现FPGA数据互联可以节省功耗。使用set input delay替换IDELAY器件可以节省功耗。
结语
FPGA的动态和静态功率优化会一直都是设计中一个比较大的挑战,所以AMD-Xilinx将继续致力于优化FPGA的功率管理工具和设计方法,同时也将不断努力在芯片层面上解决功耗问题。本文参考UltraScale/UltraScale+ Power Reduction Techniques文档,同时也感谢AMD-Xilinx专家Tiko的热情指导。
审核编辑:汤梓红
-
FPGA
+关注
关注
1664文章
22502浏览量
639054 -
amd
+关注
关注
25文章
5707浏览量
140397 -
Xilinx
+关注
关注
73文章
2206浏览量
131855 -
功耗优化
+关注
关注
0文章
6浏览量
6317
发布评论请先 登录
如何测试FPGA的供电电源
Xilinx FPGA MIPI 接口简单说明

AMD Xilinx 7系列FPGA的Multiboot多bit配置

【AMD KV260视觉入门开发套件试用】1、开箱&烧录镜像系统体验
基于FPGA的Vivado功耗估计和优化
AMD收购FPGA领域的市场领导者Xilinx

利用FPGA的可编程能力以及相关的工具来准确估算功耗
AMD Xilinx K26从eMMC启动Ubuntu
AMD-Xilinx MPSoC的Watchdog在Linux中使用的简明教程
Rpi SenseHAT与AMD-Xilinx Kria KR260和Petalinux的接口




评论