 强势的点云处理神经网络PointNe介绍
强势的点云处理神经网络PointNe介绍
前言
PointNet是由斯坦福大学的Charles R. Qi等人在《PointNet:Deep Learning on Point Sets for 3D Classification and Segmentation》一文中提出的模型,它可以直接对点云进行处理的,对输入点云中的每一个点,学习其对应的空间编码,之后再利用所有点的特征得到一个全局的点云特征。Pointnet提取的全局特征能够很好地完成分类任务,但局部特征提取能力较差,这使得它很难对复杂场景进行分析。
PointNet++是Charles R. Qi团队在PointNet论文基础上改进版本,其核心是提出了多层次特征提取结构,有效提取局部特征提取,和全局特征。
F-PointNet将PointNet的应用拓展到了3D目标检测上,可以使用PointNet或PointNet++进行点云处理。它在进行点云处理之前,先使用图像信息得到一些先验搜索范围,这样既能提高效率,又能增加准确率。
PointNet
1.1 PointNet思路流程
1)输入为一帧的全部点云数据的集合,表示为一个nx3的2d tensor,其中n代表点云数量,3对应xyz坐标。
2)输入数据先通过和一个T-Net学习到的转换矩阵相乘来对齐,保证了模型的对特定空间转换的不变性。
3)通过多次mlp对各点云数据进行特征提取后,再用一个T-Net对特征进行对齐。
4)在特征的各个维度上执行maxpooling操作来得到最终的全局特征。
5)对分类任务,将全局特征通过mlp来预测最后的分类分数;对分割任务,将全局特征和之前学习到的各点云的局部特征进行串联,再通过mlp得到每个数据点的分类结果。
1.2 PointNet网络结构
它提取的“全局特征”能够很好地完成分类任务。下面看一下PointNet的框架结构:
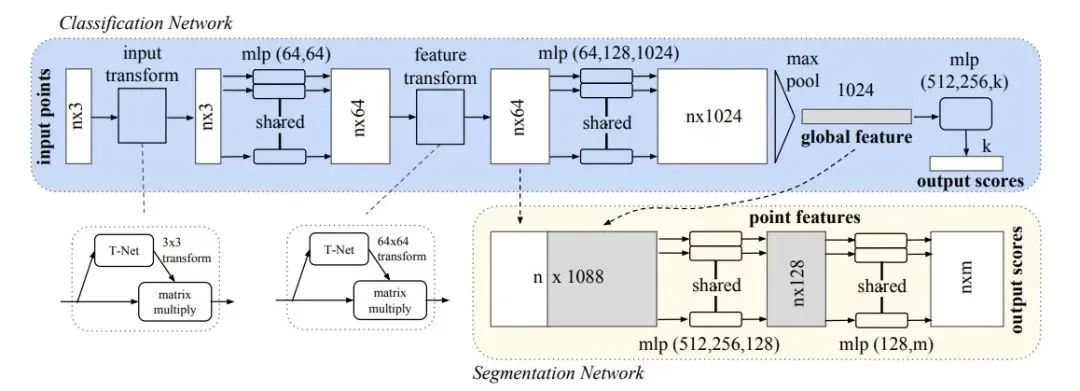
下面解释一个网络中各个部件的作用。
1)transform:第一次,T-Net 3x3,对输入点云进行对齐:位姿改变,使改变后的位姿更适合分类/分割;第二次,T-Net 64x64,对64维特征进行对齐。2)mlp:多层感知机,用于提取点云的特征,这里使用共享权重的卷积。
3)max pooling:汇总所有点云的信息,进行最大池化,得到点云的全局信息。
4)分割部分:局部和全局信息组合结构(concate,语义分割)。
5)分类loss:交叉熵:分割loss:分类+分割+L2(transform,原图的正交变换)。
1.3T-Net网络结构
将输入的点云数据作为nx3x1单通道图像,接三次卷积和一次池化后,再reshape为1024个节点,然后接两层全连接,网络除最后一层外都使用了ReLU激活函数和批标准化。
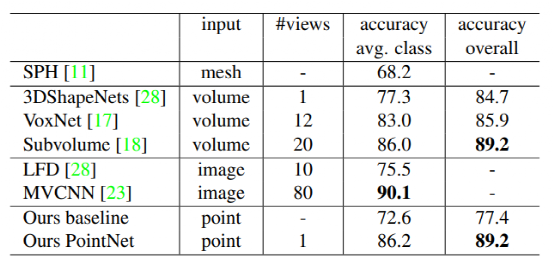
1.4 模型效果
ModelNet40 上的分类结果:
ShapeNet部分数据集上的分割结果:
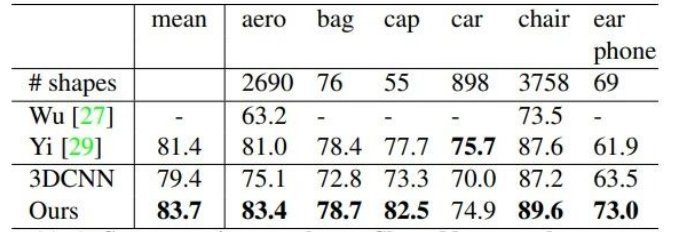
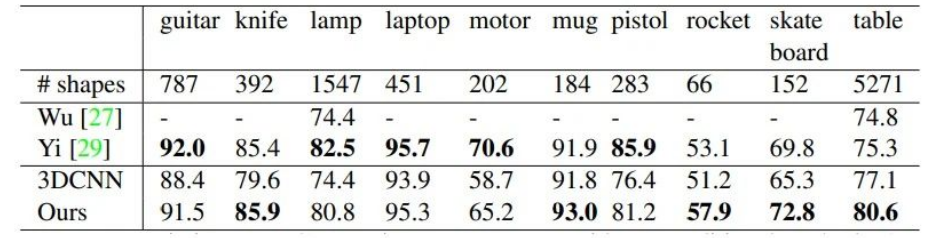
不足:缺乏在不同尺度上提取局部信息的能力。
PointNet++
Pointnet提取的全局特征能够很好地完成分类任务,由于模型基本上都是单点采样,代码底层用的是2Dconv,只有maxpooling整合了整体特征,所以局部特征提取能力较差,这使得它很难对复杂场景进行分析。
PointNet++的核心是提出了多层次特征提取结构,有效提取局部特征提取,和全局特征。
2.1 思路流程
先在输入点集中选择一些点作为中心点,然后围绕每个中心点选择周围的点组成一个区域,之后每个区域作为PointNet的一个输入样本,得到一组特征,这个特征就是这个区域的特征。
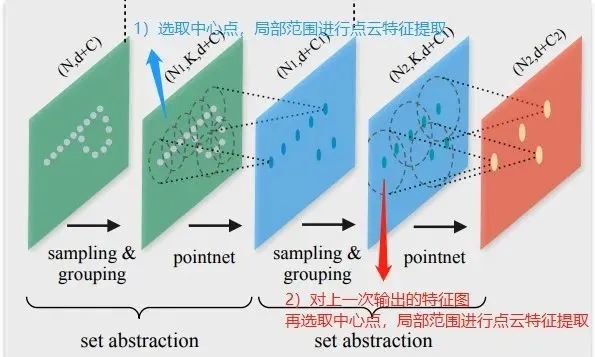
之后中心点不变,扩大区域,把上一步得到的那些特征作为输入送入PointNet,以此类推,这个过程就是不断的提取局部特征,然后扩大局部范围,最后得到一组全局的特征,然后进行分类。
2.2 整体网络结构
PointNet++ 在不同尺度提取局部特征,通过多层网络结构得到深层特征。PointNet++按照任务也分为 classification (分类网络)和 segmentation (分割网络)两种,输入和输出分别与PointNet中的两个网络一致。
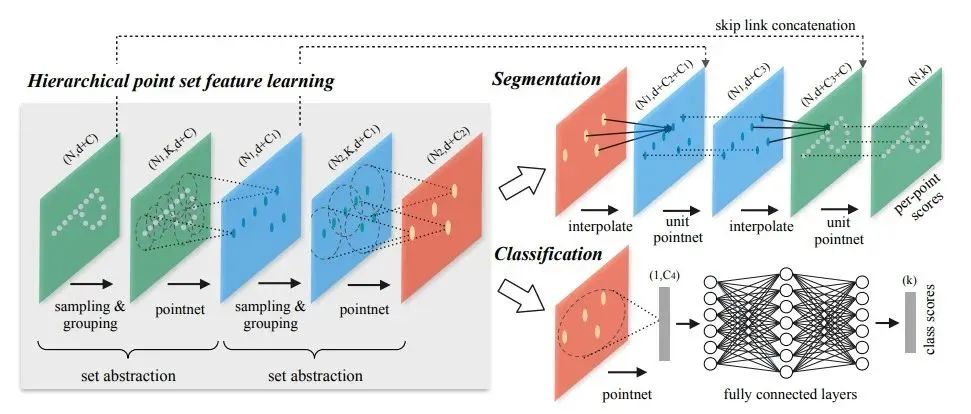
PointNet++会先对点云进行采样(sampling)和划分区域(grouping),在各个小区域内用基础的PointNet网络进行特征提取(MSG、MRG),不断迭代。
对于分类问题,直接用PointNet提取全局特征,采用全连接得到每个类别评分。对于分割问题,将高维的点反距离插值得到与低维相同的点数,再特征融合,再使用PointNet提取特征 。
比较PointNet++两个任务网络的区别:
在得到最高层的 feature 之后,分类网络使用了一个小型的 PointNet + FCN 网络提取得到最后的分类 score;
分割网络通过“跳跃连接” 操作不断与底层 “低层特征图”信息融合,最终得到逐点分分类语义分割结果。(“跳跃连接”对应上图的 skip link connection;低层特征图 具有分辨率较大,保留较丰富的信息,虽然整体语义信息较弱。)
2.3网络结构组件
1)采样层(sampling)
激光雷达单帧的数据点可以多达100k个,如果对每一个点都提取局部特征,计算量是非常巨大的。因此,作者提出了先对数据点进行采样。作者使用的采样算法是最远点采样(farthest point sampling, FPS),相对于随机采样,这种采样算法能够更好地覆盖整个采样空间。
2)组合层(grouping)
为了提取一个点的局部特征,首先需要定义这个点的“局部”是什么。一个图片像素点的局部是其周围一定曼哈顿距离下的像素点,通常由卷积层的卷积核大小确定。同理,点云数据中的一个点的局部由其周围给定半径划出的球形空间内的其他点构成。组合层的作用就是找出通过采样层后的每一个点的所有构成其局部的点,以方便后续对每个局部提取特征。
3)特征提取层(feature learning)
因为PointNet给出了一个基于点云数据的特征提取网络,因此可以用PointNet对组合层给出的各个局部进行特征提取来得到局部特征。值得注意的是,虽然组合层给出的各个局部可能由不同数量的点构成,但是通过PointNet后都能得到维度一致的特征(由上述K值决定)。
2.4 不均匀点云组合grouping方法
不同于图片数据分布在规则的像素网格上且有均匀的数据密度,点云数据在空间中的分布是不规则且不均匀的。当点云不均匀时,每个子区域中如果在分区的时候使用相同的球半径,会导致部分稀疏区域采样点过小。作者提出多尺度成组 (MSG)和多分辨率成组 (MRG)两种解决办法。
1)多尺度组合MSG:对于选取的一个中心点设置多个半径进行成组,并将经过PointNet对每个区域抽取后的特征进行拼接(concat)来当做该中心点的特征,这种做法会产生很多特征重叠,结果会可以保留和突出(边际叠加)更多局部关键的特征,但是这种方式不同范围内计算的权值却很难共享,计算量会变大很多。
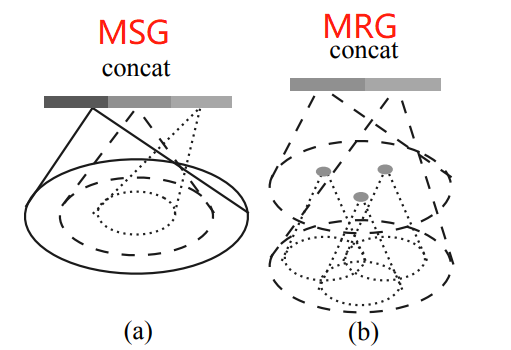
2)多分辨率组合MRG:MRG避免了大量的计算,但仍然保留了根据点的分布特性自适应地聚合信息的能力。对不同特征层上(分辨率)提取的特征再进行concat,以b图为例,最后的concat包含左右两个部分特征,分别来自底层和高层的特征抽取,对于low level点云成组后经过一个pointnet和high level的进行concat,思想是特征的抽取中的跳层连接。
当局部点云区域较稀疏时,上层提取到的特征可靠性可能比底层更差,因此考虑对底层特征提升权重。当然,点云密度较高时能够提取到的特征也会更多。这种方法优化了直接在稀疏点云上进行特征抽取产生的问题,且相对于MSG的效率也较高。
选择哪一种?
当局部区域的密度低时,第一矢量可能不如第二矢量可靠,因为计算第一矢量的子区域包含更稀疏的点并且更多地受到采样不足的影响。在这种情况下,第二个矢量应该加权更高。另一方面,当局部区域的密度高时,第一矢量提供更精细细节的信息,因为它具有以较低水平递归地表达较高分辨率检查的能力。
2.5 模型效果
分类对比:

分割对比:
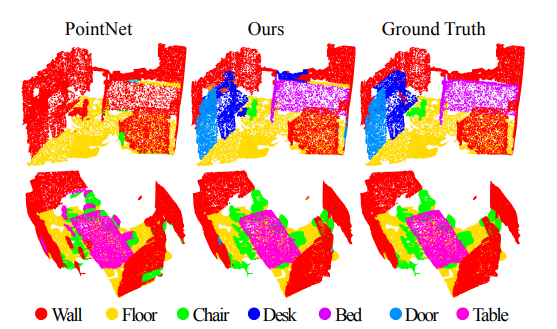
小结复杂场景点云一般采用PointNet++进行处理,而简单场景点云则采用PointNet。如果只从点云分类和分割两个任务角度分析,分类任务只需要max pooling操作之后的特征信息就可完成,而分割任务则需要更加详细的local context信息。
F-PointNet 也是直接处理点云数据的方案,但这种方式面临着挑战,比如:如何有效地在三维空间中定位目标的可能位置,即如何产生 3D 候选框,假如全局搜索将会耗费大量算力与时间。
F-PointNet是在进行点云处理之前,先使用图像信息得到一些先验搜索范围,这样既能提高效率,又能增加准确率。
3.1 基本思路
首先使用在 RGB 图像上运行的 2D 检测器,其中每个2D边界框定义一个3D锥体区域。然后基于这些视锥区域中的 3D 点云,我们使用 PointNet/PointNet++ 网络实现了 3D实例分割和非模态 3D 边界框估计。总结一下思路,如下:
基于图像2D目标检测。
基于图像生成锥体区域。
在锥体内,使用 PointNet/PointNet++ 网络进行点云实例分割。
它是在进行点云处理之前,先使用图像信息得到一些先验搜索范围,这样既能提高效率,又能增加准确率。先看看下面这张图:
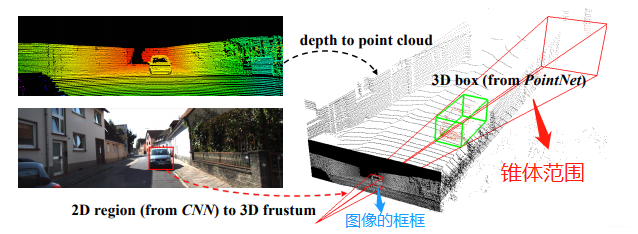
在这张图里,左上角的意思是先把图像和点云信息标定好(这个属于传感器的外参标定,在感知之前进行;获取两个传感器之间旋转矩阵和平移向量,就可以得到相互的位置关系)。
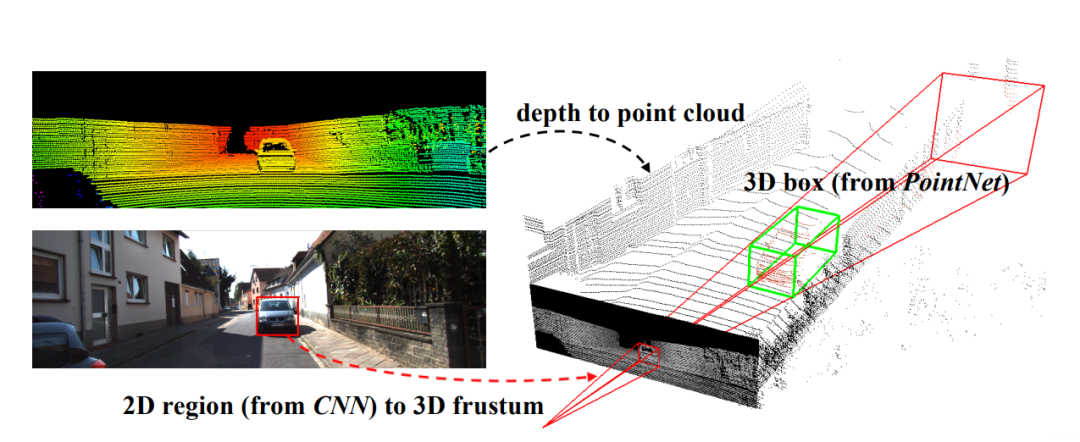
左下角是用目标检测算法检测出物体的边界框(BoundingBox),有了边界框之后,以相机为原点,沿边界框方向延伸过去就会形成一个锥体(上图的右半部分),该论文题目里frustum这个词就是锥体的意思。然后用点云对该物体进行识别的时候,只需要在这个锥体内识别就行了,大大减小了搜索范围。
3.2 模型框架
模型结构如下:(可以点击图片放大查看)
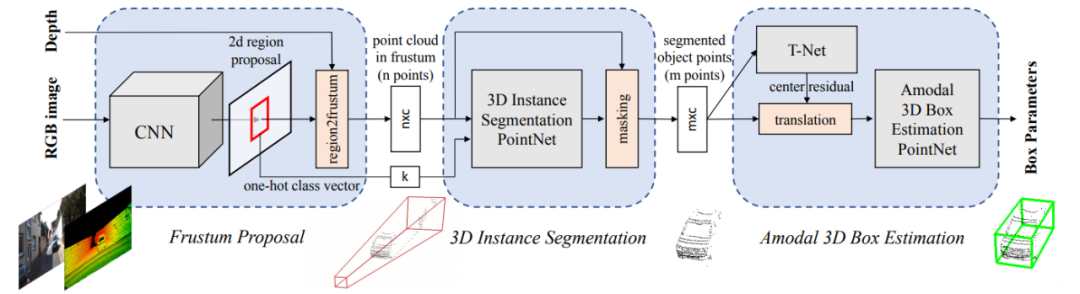
网络共分为三部分,第一部分是使用图像进行目标检测并生成锥体区域,第二部分是在锥体内的点云实例分割,第三部分是点云物体边界框的回归。
3.3基于图像生成锥体区域
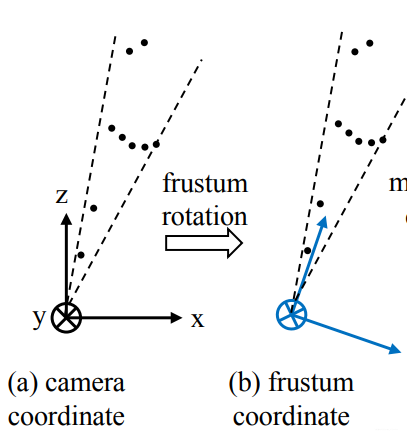
由于检测到的目标不一定在图像的正中心,所以生成的锥体的轴心就不一定和相机的坐标轴重合,如下图中(a)所示。为了使网络具有更好的旋转不变性,我们需要做一次旋转,使相机的Z轴和锥体的轴心重合。如下图中(b)所示。
3.4 在锥体内进行点云实例分割
实例分割使用PointNet。一个锥体内只提取一个物体,因为这个锥体是图像中的边界框产生的,一个边界框内也只有一个完整物体。
在生成锥体的时候提到了旋转不变性,此处完成分割这一步之后,还需要考虑平移不变性,因为点云分割之后,分割的物体的原点和相机的原点必不重合,而我们处理的对象是点云,所以应该把原点平移到物体中去,如下图中(c)所示。
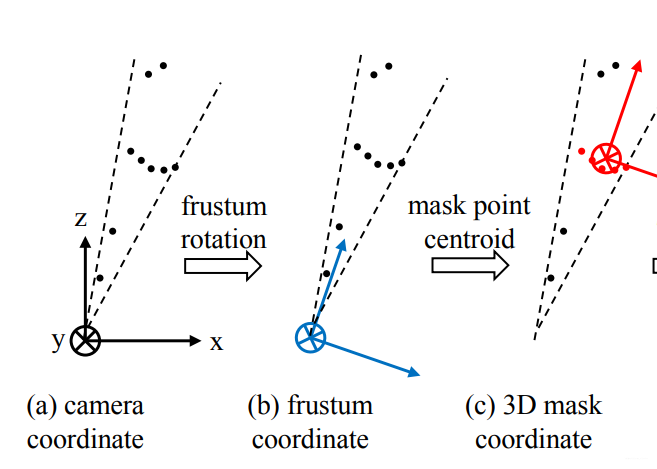
3.5 生成精确边界框
生成精确边界框的网络结构:
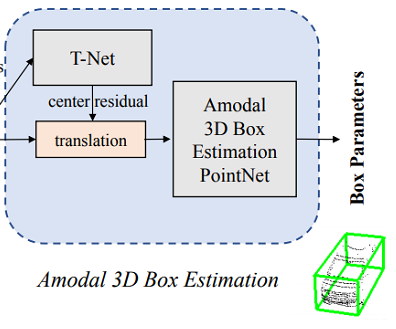
从这个结构里可以看出,在生成边界框之前,需要经过一个T-Net,这个东西的作用是生成一个平移量,之所以要做这一步,是因为在上一步得到的物体中心并不完全准确,所以为了更精确地估计边界框,在此处对物体的质心做进一步的调整,如下图中(d)所示。
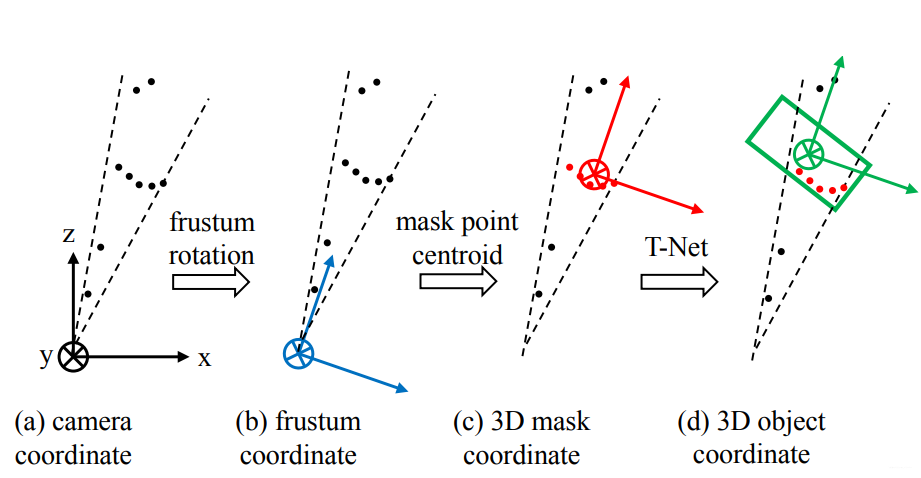
下面就是边界框回归了,对一个边界框来讲,一共有七个参数,包括:
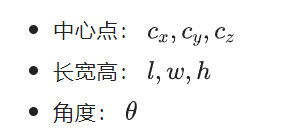
最后总的残差就是以上目标检测、T-Net和边界框残差之和,可以据此构建损失函数。
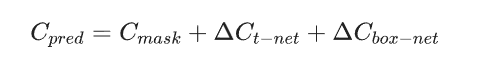
3.6 PointNet关键点
(1) F-PointNet使用2D RGB图像
F-PointNet使用2D RGB图像原因是:1.当时基于纯3D点云数据的3D目标检测对小目标检测效果不佳。所以F-PointNet先基于2D RGB做2D的目标检测来定位目标,再基于2d目标检测结果用其对应的点云数据视锥进行bbox回归的方法来实现3D目标检测。2.使用纯3D的点云数据,计算量也会特别大,效率也是这个方法的优点之一。使用成熟的2D CNN目标检测器(Mask RCNN)生成2D检测框,并输出one-hot 分类向量(即基于2D RGB图像的分类)。
(2)锥体框生成
2D检测框结合深度信息,找到最近和最远的包含检测框的平面来定义3D视锥区域frustum proposal。然后在该frustum proposal里收集所有的3D点来组成视锥点云(frustum point cloud)。
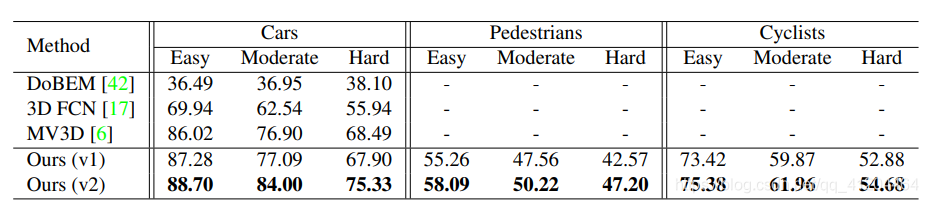
3.7 实验结果
与其他模型对比:
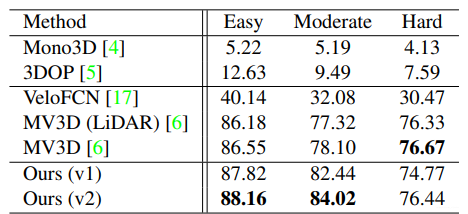
模型效果:

3.8 优点
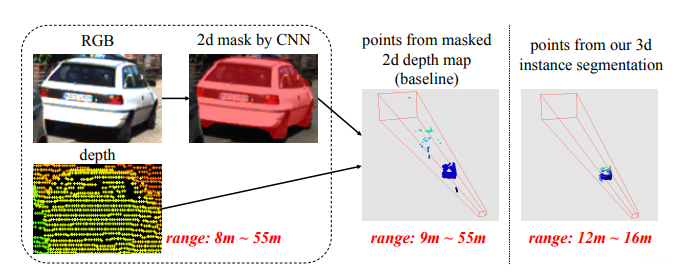
(1)舍弃了global fusion,提高了检测效率;并且通过2D detector和3D Instance Segmentation PointNet对3D proposal实现了逐维(2D-3D)的精准定位,大大缩短了对点云的搜索时间。下图是通过3d instance segmentation将搜索范围从9m~55m缩减到12m~16m。
(2)相比于在BEV(Bird's Eye view)中进行3D detection,F-PointNet直接处理raw point cloud,没有任何维度的信息损失,使用PointNet能够学习更全面的空间几何信息,特别是在小物体的检测上有很好的表现。下图是来自Hao Su 2018年初的课程,现在的KITTI榜有细微的变动。
(3)利用成熟的2D detector对proposal进行分类(one-hot class vector,打标签),起到了一定的指导作用,能够大大降低PointNet对三维空间物体的学习难度。
3.9 模型代码
开源代码:GitHub - charlesq34/frustum-pointnets: Frustum PointNets for 3D Object Detection from RGB-D Data
作者代码的运行环境:
系统:Ubuntu 14.04 或 Ubuntu 16.04
深度框架:TensorFlow1.2(GPU 版本)或 TensorFlow1.4(GPU 版本)
其他依赖库:cv2、mayavi等。
审核编辑:刘清
-
神经网络
+关注
关注
42文章
4762浏览量
100523 -
RGB
+关注
关注
4文章
798浏览量
58379 -
FPS
+关注
关注
0文章
35浏览量
11962
原文标题:一文搞懂PointNet全家桶——强势的点云处理神经网络
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
卷积神经网络与传统神经网络的比较
怎么对神经网络重新训练
rnn是递归神经网络还是循环神经网络
递归神经网络与循环神经网络一样吗
人工神经网络模型的分类有哪些
递归神经网络是循环神经网络吗
循环神经网络算法原理及特点
循环神经网络处理什么数据
循环神经网络和卷积神经网络的区别
人工智能神经网络芯片的介绍
反向传播神经网络和bp神经网络的区别
卷积神经网络训练的是什么
卷积神经网络的原理是什么
详解深度学习、神经网络与卷积神经网络的应用






 工商网监
工商网监
评论