 ROS机器人操作系统底层原理及代码剖析
ROS机器人操作系统底层原理及代码剖析
目的
本文介绍ROS机器人操作系统(Robot Operating System)的实现原理,从最底层分析ROS代码是如何实现的。
1、序列化
把通信的内容(也就是消息message)序列化是通信的基础,所以我们先研究序列化。
尽管笔者从事机器人学习和研发很长时间了,但是在研究ROS的过程中,“序列化”这个词还是这辈子第一次听到。
所以可想而知很多人在看到“把一个消息序列化”这样的描述时是如何一脸懵逼。
但其实序列化是一个比较常见的概念,你虽然不知道它但一定接触过它。
下面我们先介绍“序列化”的一些常识,然后解释ROS里的序列化是怎么做的?
1.1什么是序列化?
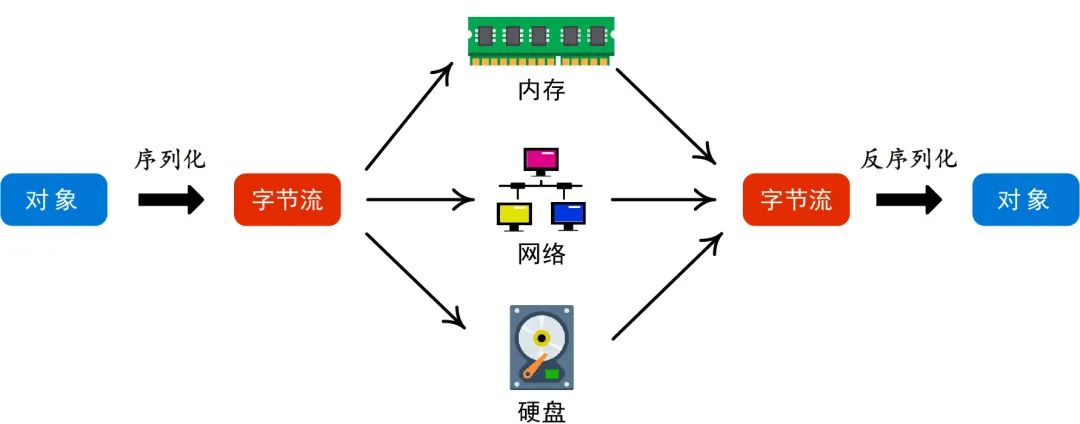
“序列化”(Serialization )的意思是将一个对象转化为字节流。
这里说的对象可以理解为“面向对象”里的那个对象,具体的就是存储在内存中的对象数据。
与之相反的过程是“反序列化”(Deserialization )。
虽然挂着机器人的羊头,但是后面的介绍全部是计算机知识,跟机器人一丁点关系都没有,序列化就是一个纯粹的计算机概念。
序列化的英文Serialize就有把一个东西变成一串连续的东西之意。
形象的描述,数据对象是一团面,序列化就是将面团拉成一根面条,反序列化就将面条捏回面团。
另一个形象的类比是我们在对话或者打电话时,一个人的思想转换成一维的语音,然后在另一个人的头脑里重新变成结构化的思想,这也是一种序列化。
面对序列化,很多人心中可能会有很多疑问。
首先,为什么要序列化?或者更具体的说,既然对象的信息本来就是以字节的形式储存在内存中,那为什么要多此一举把一些字节数据转换成另一种形式的、一维的、连续的字节数据呢?
如果我们的程序在内存中存储了一个数字,比如25。那要怎么传递25这个数字给别的程序节点或者把这个数字永久存储起来呢?
很简单,直接传递25这个数字(的字节表示,即0X19,当然最终会变成二进制表示11001以高低电平传输存储)或者直接把这个数字(的字节表示)写进硬盘里即可。
所以,对于本来就是连续的、一维的、一连串的数据(例如字符串),序列化并不需要做太多东西,其本质是就是由内存向其它地方拷贝数据而已。
所以,如果你在一个序列化库里看到memcpy函数不用觉得奇怪,因为你知道序列化最底层不过就是在操作内存数据而已(还有些库使用了流的ostream.rdbuf()->sputn函数)。
可是实际程序操作的对象很少是这么简单的形式,大多数时候我们面对的是包含不同数据类型(int、double、string)的复杂数据结构(比如vector、list),它们很可能在内存中是不连续存储的而是分散在各处。比如ROS的很多消息都包含向量。
数据中还有各种指针和引用。而且,如果数据要在运行于不同架构的计算机之上的、由不同编程语言所编写的节点程序之间传递,那问题就更复杂了,它们的字节顺序endianness规定有可能不一样,基本数据类型(比如int)的长度也不一样(有的int是4个字节、有的是8个字节)。
这些都不是通过简单地、原封不动地复制粘贴原始数据就能解决的。这时候就需要序列化和反序列化了。
所以在程序之间需要通信时(ROS恰好就是这种情况),或者希望保存程序的中间运算结果时,序列化就登场了。
另外,在某种程度上,序列化还起到统一标准的作用。
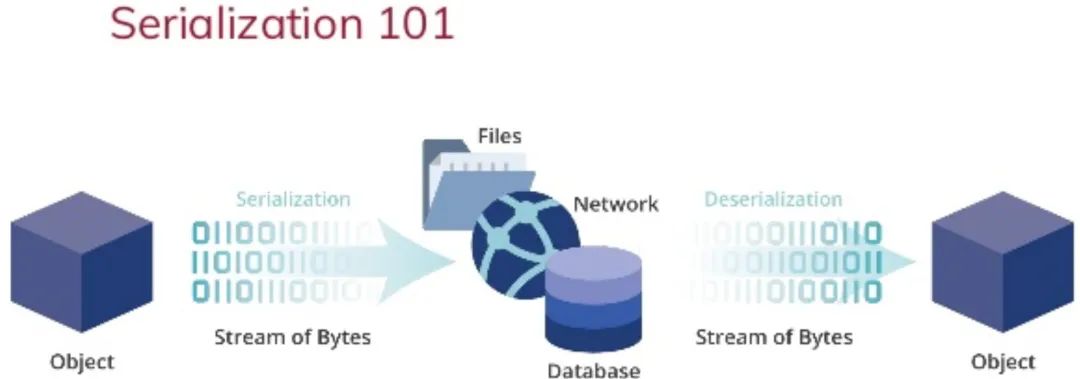
我们把被序列化的东西叫object(对象),它可以是任意的数据结构或者对象:结构体、数组、类的实例等等。
把序列化后得到的东西叫archive,它既可以是人类可读的文本形式,也可以是二进制形式。
前者比如JSON和XML,这两个是网络应用里最常用的序列化格式,通过记事本就能打开阅读;
后者就是原始的二进制文件,比如后缀名是bin的文件,人类是没办法直接阅读一堆的0101或者0XC9D23E72的。
序列化算是一个比较常用的功能,所以大多数编程语言(比如C++、Python、Java等)都会附带用于序列化的库,不需要你再去造轮子。
以C++为例,虽然标准STL库没有提供序列化功能,但是第三方库Boost提供了[ 2 ]谷歌的protobuf也是一个序列化库,还有Fast-CDR,以及不太知名的Cereal,Java自带序列化函数,python可以使用第三方的pickle模块实现。
总之,序列化没有什么神秘的,用户可以看看这些开源的序列化库代码,或者自己写个小程序试试简单数据的序列化,例如这个例子,或者这个,有助于更好地理解ROS中的实现。
1.2ROS中的序列化实现
理解了序列化,再回到ROS。我们发现,ROS没有采用第三方的序列化工具,而是选择自己实现,代码在roscpp_core项目下的roscpp_serialization中,见下图。这个功能涉及的代码量不是很多。
为什么ROS不使用现成的序列化工具或者库呢?可能ROS诞生的时候(2007年),有些序列化库可能还不存在(protobuf诞生于2008年),更有可能是ROS的创造者认为当时没有合适的工具。
1.2.1serialization.h
核心的函数都在serialization.h里,简而言之,里面使用了C语言标准库的memcpy函数把消息拷贝到流中。
下面来看一下具体的实现。
序列化功能的特点是要处理很多种数据类型,针对每种具体的类型都要实现相应的序列化函数。
为了尽量减少代码量,ROS使用了模板的概念,所以代码里有一堆的template。
从后往前梳理,先看Stream这个结构体吧。在C++里结构体和类基本没什么区别,结构体里也可以定义函数。
Stream翻译为流,流是一个计算机中的抽象概念,前面我们提到过字节流,它是什么意思呢?
在需要传输数据的时候,我们可以把数据想象成传送带上连续排列的一个个被传送的物体,它们就是一个流。
更形象的,可以想象磁带或者图灵机里连续的纸带。在文件读写、使用串口、网络Socket通信等领域,流经常被使用。例如我们常用的输入输出流:
cout<<"helllo"; 由于使用很多,流的概念也在演变。想了解更多可以看这里。
struct Stream
{
// Returns a pointer to the current position of the stream
inline uint8_t* getData() { return data_; }
// Advances the stream, checking bounds, and returns a pointer to the position before it was advanced.
// hrows StreamOverrunException if len would take this stream past the end of its buffer
ROS_FORCE_INLINE uint8_t* advance(uint32_t len)
{
uint8_t* old_data = data_;
data_ += len;
if (data_ > end_)
{
// Throwing directly here causes a significant speed hit due to the extra code generated for the throw statement
throwStreamOverrun();
}
return old_data;
}
// Returns the amount of space left in the stream
inline uint32_t getLength() { return static_cast<uint32_t>(end_ - data_); }
protected:
Stream(uint8_t* _data, uint32_t _count) : data_(_data), end_(_data + _count) {}
private:
uint8_t* data_;
uint8_t* end_;
};
注释表明Stream是个基类,输入输出流IStream和OStream都继承自它。
Stream的成员变量data_是个指针,指向序列化的字节流开始的位置,它的类型是uint8_t。
在Ubuntu系统中,uint8_t的定义是typedef unsigned char uint8_t;
所以uint8_t就是一个字节,可以用size_of()函数检验。data_指向的空间就是保存字节流的。
输出流类OStream用来序列化一个对象,它引用了serialize函数,如下。
struct OStream : public Stream
{
static const StreamType stream_type = stream_types::Output;
OStream(uint8_t* data, uint32_t count) : Stream(data, count) {}
/* Serialize an item to this output stream*/
template<typename T>
ROS_FORCE_INLINE void next(const T& t)
{
serialize(*this, t);
}
template<typename T>
ROS_FORCE_INLINE OStream& operator<<(const T& t)
{
serialize(*this, t);
return *this;
}
};
输入流类IStream用来反序列化一个字节流,它引用了deserialize函数,如下。
struct ROSCPP_SERIALIZATION_DECL IStream : public Stream
{
static const StreamType stream_type = stream_types::Input;
IStream(uint8_t* data, uint32_t count) : Stream(data, count) {}
/* Deserialize an item from this input stream */
template<typename T>
ROS_FORCE_INLINE void next(T& t)
{
deserialize(*this, t);
}
template<typename T>
ROS_FORCE_INLINE IStream& operator>>(T& t)
{
deserialize(*this, t);
return *this;
}
};
自然,serialize函数和deserialize函数就是改变数据形式的地方,它们的定义在比较靠前的地方。它们都接收两个模板,都是内联函数,然后里面没什么东西,只是又调用了Serializer类的成员函数write和read。所以,serialize和deserialize函数就是个二道贩子。
// Serialize an object. Stream here should normally be a ros::OStream
template<typename T, typename Stream>
inline void serialize(Stream& stream, const T& t)
{
Serializer::write(stream, t);
}
// Deserialize an object. Stream here should normally be a ros::IStream
template<typename T, typename Stream>
inline void deserialize(Stream& stream, T& t)
{
Serializer::read(stream, t);
}
所以,我们来分析Serializer类,如下。我们发现,write和read函数又调用了类型里的serialize函数和deserialize函数。
头别晕,这里的serialize和deserialize函数跟上面的同名函数不是一回事。
注释中说:“Specializing the Serializer class is the only thing you need to do to get the ROS serialization system to work with a type”(要想让ROS的序列化功能适用于其它的某个类型,你唯一需要做的就是特化这个Serializer类)。
这就涉及到的另一个知识点——模板特化(template specialization)。
template<typename T> struct Serializer
{
// Write an object to the stream. Normally the stream passed in here will be a ros::OStream
template<typename Stream>
inline static void write(Stream& stream, typename boost::call_traits::param_type t)
{
t.serialize(stream.getData(), 0);
}
// Read an object from the stream. Normally the stream passed in here will be a ros::IStream
template<typename Stream>
inline static void read(Stream& stream, typename boost::call_traits::reference t)
{
t.deserialize(stream.getData());
}
// Determine the serialized length of an object.
inline static uint32_t serializedLength(typename boost::call_traits::param_type t)
{
return t.serializationLength();
}
};
接着又定义了一个带参数的宏函数ROS_CREATE_SIMPLE_SERIALIZER(Type),然后把这个宏作用到了ROS中的10种基本数据类型,分别是:uint8_t, int8_t, uint16_t, int16_t, uint32_t, int32_t, uint64_t, int64_t, float, double。
说明这10种数据类型的处理方式都是类似的。看到这里大家应该明白了,write和read函数都使用了memcpy函数进行数据的移动。
注意宏定义中的template<>语句,这正是模板特化的标志,关键词template后面跟一对尖括号。
关于模板特化可以看这里。
template
{
template<typename Stream> inline static void write(Stream& stream, const Type v)
{
memcpy(stream.advance(sizeof(v)), &v, sizeof(v) );
}
template<typename Stream> inline static void read(Stream& stream, Type& v)
{
memcpy(&v, stream.advance(sizeof(v)), sizeof(v) );
}
inline static uint32_t serializedLength(const Type&)
{
return sizeof(Type);
}
};
ROS_CREATE_SIMPLE_SERIALIZER(uint8_t)
ROS_CREATE_SIMPLE_SERIALIZER(int8_t)
ROS_CREATE_SIMPLE_SERIALIZER(uint16_t)
ROS_CREATE_SIMPLE_SERIALIZER(int16_t)
ROS_CREATE_SIMPLE_SERIALIZER(uint32_t)
ROS_CREATE_SIMPLE_SERIALIZER(int32_t)
ROS_CREATE_SIMPLE_SERIALIZER(uint64_t)
ROS_CREATE_SIMPLE_SERIALIZER(int64_t)
ROS_CREATE_SIMPLE_SERIALIZER(float)
ROS_CREATE_SIMPLE_SERIALIZER(double)
对于其它类型的数据,例如bool、std::string、std::vector、ros::Time、ros::Duration、boost::array等等,它们各自的处理方式有细微的不同,所以不再用上面的宏函数,而是用模板特化的方式每种单独定义,这也是为什么serialization.h这个文件这么冗长。
对于int、double这种单个元素的数据,直接用上面特化的Serializer类中的memcpy函数实现序列化。
对于vector、array这种多个元素的数据类型怎么办呢?方法是分成几种情况,对于固定长度简单类型的(fixed-size simple types),还是用各自特化的Serializer类中的memcpy函数实现,没啥太大区别。
对于固定但是类型不简单的(fixed-size non-simple types)或者既不固定也不简单的(non-fixed-size, non-simple types)或者固定但是不简单的(fixed-size, non-simple types),用for循环遍历,一个元素一个元素的单独处理。
那怎么判断一个数据是不是固定是不是简单呢?这是在roscpp_traits文件夹中的message_traits.h完成的。
其中采用了萃取Type Traits,这是相对高级一点的编程技巧了,笔者也不太懂。
对序列化的介绍暂时就到这里了,有一些细节还没讲,等笔者看懂了再补。
2、消息订阅发布
2.1ROS的本质
如果问ROS的本质是什么,或者用一句话概括ROS的核心功能。那么,笔者认为ROS就是个通信库,让不同的程序节点能够相互对话。
很多文章和书籍在介绍ROS是什么的时候,经常使用“ROS是一个通信框架”这种描述。
但是笔者认为这种描述并不是太合适。“框架”是个对初学者非常不友好的抽象词汇,用一个更抽象难懂的概念去解释一个本来就不清楚的概念,对初学者起不到任何帮助。
而且笔者严重怀疑绝大多数作者能对机器人的本质或者软件框架能有什么太深的理解,他们的见解不会比你我深刻多少。
既然提到本质,那我们就深入到最基本的问题。
在接触无穷的细节之前,我们不妨先做一个哲学层面的思考。
那就是,为什么ROS要解决通信问题?
机器人涉及的东西千千万万,机械、电子、软件、人工智能无所不包,为什么底层的设计是一套用来通信的程序而不是别的东西。
到目前为止,我还没有看到有人讨论过这个问题。这要回到机器人或者智能的本质。
当我们在谈论机器人的时候,最首要的问题不是硬件设计,而是对信息的处理。一个机器人需要哪些信息,信息从何而来,如何传递,又被谁使用,这些才是最重要的问题。
人类飞不鸟,游不过鱼,跑不过马,力不如牛,为什么却自称万物之灵呢。
因为人有大脑,而且人类大脑处理的信息更多更复杂。
抛开物质,从信息的角度看,人与动物、与机器人存在很多相似的地方。
机器人由许多功能模块组成,它们之间需要协作才能形成一个有用的整体,机器人与机器人之间也需要协作才能形成一个有用的系统,要协作就离不开通信。
需要什么样的信息以及信息从何而来不是ROS首先关心的,因为这取决于机器人的应用场景。
因此,ROS首先要解决的是通信的问题,即如何建立通信、用什么方式通信、通信的格式是什么等等一系列具体问题。
带着这些问题,我们看看ROS是如何设计的。
2.2客户端库
实现通信的代码在ros_comm包中,如下。
其中clients文件夹一共有127个文件,看来是最大的包了。
现在我们来到了ROS最核心的地带。
客户端这个名词出现的有些突然,一个机器人操作系统里为什么需要客户端。
原因是,节点与主节点master之间的关系是client/server,这时每个节点都是一个客户端(client),而master自然就是服务器端(server)。
那客户端库(client libraries)是干什么的?就是为实现节点之间通信的。
虽然整个文件夹中包含的文件众多,但是我们如果按照一定的脉络来分析就不会眼花缭乱。
节点之间最主要的通信方式就是基于消息的。为了实现这个目的,需要三个步骤,如下。
弄明白这三个步骤就明白ROS的工作方式了。这三个步骤看起来是比较合乎逻辑的,并不奇怪。
消息的发布者和订阅者(即消息的接收方)建立连接;
发布者向话题发布消息,订阅者在话题上接收消息,将消息保存在回调函数队列中;
调用回调函数队列中的回调函数处理消息。
2.2.1一个节点的诞生
在建立连接之前,首先要有节点。
节点就是一个独立的程序,它运行起来后就是一个普通的进程,与计算机中其它的进程并没有太大区别。
一个问题是:ROS中为什么把一个独立的程序称为“节点”
这是因为ROS沿用了计算机网络中“节点”的概念。
在一个网络中,例如互联网,每一个上网的计算机就是一个节点。前面我们看到的客户端、服务器这样的称呼,也是从计算机网络中借用的。
下面来看一下节点是如何诞生的。我们在第一次使用ROS时,一般都会照着官方教程编写一个talker和一个listener节点,以熟悉ROS的使用方法。
我们以talker为例,它的部分代码如下。
int main(int argc, char **argv)
{
/* You must call one of the versions of ros::init() before using any other part of the ROS system. */
ros::init(argc, argv, "talker");
ros::NodeHandle n;
main函数里首先调用了init()函数初始化一个节点,该函数的定义在init.cpp文件中。
当我们的程序运行到init()函数时,一个节点就呱呱坠地了。
而且在出生的同时我们还顺道给他起好了名字,也就是"talker"。
名字是随便起的,但是起名是必须的。
我们进入init()函数里看看它做了什么,代码如下,看上去还是挺复杂的。它初始化了一个叫g_global_queue的数据,它的类型是CallbackQueuePtr。
这是个相当重要的类,叫“回调队列”,后面还会见到它。init()函数还调用了network、master、this_node、file_log、param这几个命名空间里的init初始化函数各自实现一些变量的初始化,这些变量都以g开头,例如g_host、g_uri,用来表明它们是全局变量。
其中,network::init完成节点主机名、IP地址等的初始化,master::init获取master的URI、主机号和端口号。
this_node::init定义节点的命名空间和节点的名字,没错,把我们给节点起的名字就存储在这里。file_log::init初始化日志文件的路径。
void init(const M_string& remappings, const std::string& name, uint32_t options)
{
if (!g_atexit_registered) {
g_atexit_registered = true;
atexit(atexitCallback);
}
if (!g_global_queue) {
g_global_queue.reset(new CallbackQueue);
}
if (!g_initialized) {
g_init_options = options;
g_ok = true;
ROSCONSOLE_AUTOINIT;
// Disable SIGPIPE
signal(SIGPIPE, SIG_IGN);
WSADATA wsaData;
WSAStartup(MAKEWORD(2, 0), &wsaData);
check_ipv6_environment();
network::init(remappings);
master::init(remappings);
// names:: namespace is initialized by this_node
this_node::init(name, remappings, options);
file_log::init(remappings);
param::init(remappings);
g_initialized = true;
}
}
完成初始化以后,就进入下一步ros::NodeHandle n定义句柄。
我们再进入node_handle.cpp文件,发现构造函数NodeHandle::NodeHandle调用了自己的construct函数。然后,顺藤摸瓜找到construct函数,它里面又调用了ros::start()函数。
没错,我们又绕回到了init.cpp文件。
ros::start()函数主要实例化了几个重要的类,如下。
完成实例化后马上又调用了各自的start()函数,启动相应的动作。
这些都做完了以后就可以发布或订阅消息了。
一个节点的故事暂时就到这了。
TopicManager::instance()->start();
ServiceManager::instance()->start();
ConnectionManager::instance()->start();
PollManager::instance()->start();
XMLRPCManager::instance()->start();
2.2.1XMLRPC是什么?
关于ROS节点建立连接的技术细节,官方文档说的非常简单,在这里ROS Technical Overview。没有基础的同学看这个介绍必然还是不懂。
在ROS中,节点与节点之间的通信依靠节点管理器(master)牵线搭桥。
master像一个中介,它介绍节点们互相认识。一旦节点们认识了以后,master就完成自己的任务了,它就不再掺和了。
这也是为什么你启动节点后再杀死master,节点之间的通信依然保持正常的原因。
使用过电驴和迅雷而且研究过BitTorrent的同学对master的工作方式应该很熟悉,master就相当于Tracker服务器,它存储着其它节点的信息。
我们每次下载之前都会查询Tracker服务器,找到有电影资源的节点,然后就可以与它们建立连接并开始下载电影了。
那么master是怎么给节点牵线搭桥的呢?ROS使用了一种叫XMLRPC的方式实现这个功能。
XMLRPC中的RPC的意思是远程过程调用(Remote Procedure Call)。
简单来说,远程过程调用的意思就是一个计算机中的程序(在我们这就是节点啦)可以调用另一个计算机中的函数,只要这两个计算机在一个网络中。
这是一种听上去很高大上的功能,它能让节点去访问网络中另一台计算机上的程序资源。
XMLRPC中的XML我们在1.1节讲消息序列化时提到了,它就是一种数据表示方式而已。
所以合起来,XMLRPC的意思就是把由XML表示的数据发送给其它计算机上的程序运行。
运行后返回的结果仍然以XML格式返回回来,然后我们通过解析它(还原回纯粹的数据)就能干别的事了。
想了解更多XMLRPC的细节可以看这个XML-RPC:概述。
举个例子,一个XMLRPC请求是下面这个样子的。因为XMLRPC是基于HTTP协议的,所以下面的就是个标准的HTTP报文。
POST / HTTP/1.1
User-Agent: XMLRPC++ 0.7
Host: localhost:11311
Content-Type: text/xml
Content-length: 78
"1.0"?>
circleArea
<double>2.41double >
如果你没学过HTTP协议,看上面的语句可能会感到陌生。《图解HTTP》这本小书可以让你快速入门。
HTTP报文比较简单,它分两部分,前半部分是头部,后半部分是主体。
头部和主体之间用空行分开,这都是HTTP协议规定的标准。
上面主体部分的格式就是XML,见的多了你就熟悉了。
所以,XMLRPC传递的消息其实就是主体部分是XML格式的HTTP报文而已,没什么神秘的。

对应客户端一个XMLRPC请求,服务器端会执行它并返回一个响应,它也是一个HTTP报文,如下。
它的结构和请求一样,不再解释了。所以,XMLRPC跟我们上网浏览网页的过程其实差不多。
HTTP/1.1 200 OK
Date: Sat, 06 Oct 2001 23:20:04 GMT
Server: Apache.1.3.12 (Unix)
Connection: close
Content-Type: text/xml
Content-Length: 124
"1.0"?>
<double>18.24668429131double >
2.2.2ROS中XMLRPC的实现
上面的例子解释了XMLRPC是什么?下面我们看看ROS是如何实现XMLRPC的。
ROS使用的XMLRPC介绍在这里:
http://wiki.ros.org/xmlrpcpp。这次ROS的创作者没有从零开始造轮子,而是在一个已有的XMLRPC库的基础上改造的。
XMLRPC的C++代码在下载后的ros_comm-noetic-develutilitiesxmlrpcpp路径下。
还好,整个工程不算太大。XMLRPC分成客户端和服务器端两大部分。
咱们先看客户端,主要代码在XmlRpcClient.cpp文件里。
擒贼先擒王,XmlRpcClient.cpp文件中最核心的函数就是execute,用于执行远程调用,代码如下。
// Execute the named procedure on the remote server.
// Params should be an array of the arguments for the method.
// Returns true if the request was sent and a result received (although the result might be a fault).
bool XmlRpcClient::execute(const char* method, XmlRpcValue const& params, XmlRpcValue& result)
{
XmlRpcUtil::log(1, "XmlRpcClient: method %s (_connectionState %s).", method, connectionStateStr(_connectionState));
// This is not a thread-safe operation, if you want to do multithreading, use separate
// clients for each thread. If you want to protect yourself from multiple threads
// accessing the same client, replace this code with a real mutex.
if (_executing)
return false;
_executing = true;
ClearFlagOnExit cf(_executing);
_sendAttempts = 0;
_isFault = false;
if ( ! setupConnection())
return false;
if ( ! generateRequest(method, params))
return false;
result.clear();
double msTime = -1.0; // Process until exit is called
_disp.work(msTime);
if (_connectionState != IDLE || ! parseResponse(result)) {
_header = "";
return false;
}
// close() if server does not supports HTTP1.1
// otherwise, reusing the socket to write leads to a SIGPIPE because
// the remote server could shut down the corresponding socket.
if (_header.find("HTTP/1.1 200 OK", 0, 15) != 0) {
close();
}
XmlRpcUtil::log(1, "XmlRpcClient: method %s completed.", method);
_header = "";
_response = "";
return true;
}
它首先调用setupConnection()函数与服务器端建立连接。
连接成功后,调用generateRequest()函数生成发送请求报文。
XMLRPC请求报文的头部又交给generateHeader()函数做了,代码如下。
// Prepend http headers
std::string XmlRpcClient::generateHeader(size_t length) const
{
std::string header =
"POST " + _uri + " HTTP/1.1
"
"User-Agent: ";
header += XMLRPC_VERSION;
header += "
Host: ";
header += _host;
char buff[40];
std::snprintf(buff,40,":%d
", _port);
header += buff;
header += "Content-Type: text/xml
Content-length: ";
std::snprintf(buff,40,"%zu
", length);
return header + buff;
}
主体部分则先将远程调用的方法和参数变成XML格式,generateRequest()函数再将头部和主体组合成完整的报文,如下:
std::string header = generateHeader(body.length());
_request = header + body;
把报文发给服务器后,就开始静静地等待。
一旦接收到服务器返回的报文后,就调用parseResponse函数解析报文数据,也就是把XML格式变成纯净的数据格式。
我们发现,XMLRPC使用了socket功能实现客户端和服务器通信。
我们搜索socket这个单词,发现它原始的意思是插座,如下。这非常形象,建立连接实现通信就像把插头插入插座。
虽说XMLRPC也是ROS的一部分,但它毕竟只是一个基础功能,我们会用即可,暂时不去探究其实现细节,
所以对它的分析到此为止。下面我们来看节点是如何调用XMLRPC的。
2.2.3节点间通过XMLRPC建立连接
在一个节点刚启动的时候,它并不知道其它节点的存在,更不知道它们在交谈什么,当然也就谈不上通信。
所以,它要先与master对话查询其它节点的状态,然后再与其它节点通信。
而节点与master对话使用的就是XMLRPC。
从这一点来看,master叫节点管理器确实名副其实,它是一个大管家,给刚出生的节点提供服务。
下面我们以两个节点:talker和listener为例,介绍其通过XMLRPC建立通信连接的过程,如下图所示。
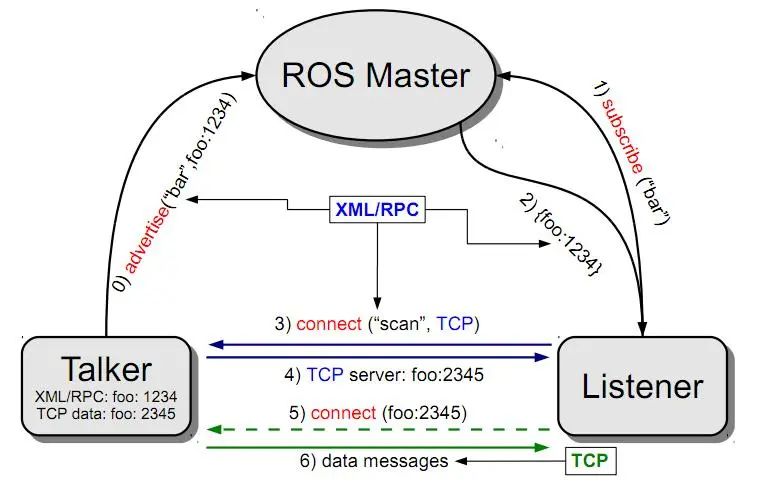
-
talker注册
假设我们先启动talker。启动后,它通过1234端口使用XMLRPC向master注册自己的信息,包含所发布消息的话题名。master会将talker的注册信息加入注册列表中;
2.listener注册
listener启动后,同样通过XMLRPC向master注册自己的信息,包含需要订阅的话题名;
3.master进行匹配
master根据listener的订阅信息从注册列表中查找,如果没有找到匹配的发布者,则等待发布者的加入,如果找到匹配的发布者信息,则通过XMLRPC向listener发送talker的地址信息。
4.listener发送连接请求
listener接收到master发回的talker地址信息,尝试通过XMLRPC向talker发送连接请求,传输订阅的话题名、消息类型以及通信协议(TCP或者UDP);
5.talker确认连接请求
talker接收到listener发送的连接请求后,继续通过XMLRPC向listener确认连接信息,其中包含自身的TCP地址信息;
6.listener尝试与talker建立连接
listener接收到确认信息后,使用TCP尝试与talker建立网络连接。
7.talker向listener发布消息
成功建立连接后,talker开始向listener发送话题消息数据,master不再参与。
从上面的分析中可以发现,前五个步骤使用的通信协议都是XMLRPC,最后发布数据的过程才使用到TCP。
master只在节点建立连接的过程中起作用,但是并不参与节点之间最终的数据传输。
节点在请求建立连接时会通过master.cpp文件中的execute()函数调用XMLRPC库中的函数。
我们举个例子,加入talker节点要发布消息,它会调用topic_manager.cpp中的TopicManager::advertise()函数,在函数中会调用execute()函数,该部分代码如下。
XmlRpcValue args, result, payload;
args[0] = this_node::getName();
args[1] = ops.topic;
args[2] = ops.datatype;
args[3] = xmlrpc_manager_->getServerURI();
master::execute("registerPublisher", args, result, payload, true);
其中,registerPublisher就是一个远程过程调用的方法(或者叫函数)。节点通过这个远程过程调用向master注册,表示自己要发布发消息了。
你可能会问,registerPublisher方法在哪里被执行了呢?我们来到ros_comm-noetic-devel ools osmastersrc osmaster路径下,打开master_api.py文件,然后搜索registerPublisher这个方法,就会找到对应的代码,如下。
匆匆扫一眼就知道,它在通知所有订阅这个消息的节点,让它们做好接收消息的准备。
你可能注意到了,这个被调用的XMLRPC是用python语言实现的。
也就是说,XMLRPC通信时只要报文的格式是一致的,不管C++还是python语言,都可以实现远程调用的功能。
def registerPublisher(self, caller_id, topic, topic_type, caller_api):
try:
self.ps_lock.acquire()
self.reg_manager.register_publisher(topic, caller_id, caller_api)
if topic_type != rosgraph.names.ANYTYPE or not topic in self.topics_types:
self.topics_types[topic] = topic_type
pub_uris = self.publishers.get_apis(topic)
sub_uris = self.subscribers.get_apis(topic)
self._notify_topic_subscribers(topic, pub_uris, sub_uris)
mloginfo("+PUB [%s] %s %s",topic, caller_id, caller_api)
sub_uris = self.subscribers.get_apis(topic)
finally:
self.ps_lock.release()
return 1, "Registered [%s] as publisher of [%s]"%(caller_id, topic), sub_uris
2.3master是什么?
当我们在命令行中输入roscore想启动ROS的节点管理器时,背后到底发生了什么?我们先用Ubuntu的which命令找找roscore这个命令在什么地方,发现它位于/opt/ros/melodic/bin/roscore路径下,如下图。再用file命令查看它的属性,发现它是一个Python脚本。

2.3.1roscore脚本
我们回到自己下载的源码:ros_comm文件夹中,找到roscore文件,它在 os_comm-melodic-devel ools oslaunchscripts路径下。
虽然它是个Python脚本,但是却没有.py后缀名。
用记事本打开它,迎面第一句话是#!/usr/bin/env python,说明这还是一个python 2版本的脚本。
我们发现这个roscore只是个空壳,真正重要的只有最后一行指令,如下
import roslaunch
roslaunch.main(['roscore', '--core'] + sys.argv[1:])
2.3.2roslaunch模块
2.3.2.1XMLRPC服务器如何启动?
roscore调用了roslaunch.main,我们继续追踪,进到ros_comm-noetic-devel ools oslaunchsrc oslaunch文件夹中,发现有个__init__.py文件,说明这个文件夹是一个python包,打开__init__.py文件找到def main(argv=sys.argv),这就是roscore调用的函数roslaunch.main的实现,如下(这里只保留主要的代码,不太重要的删掉了)。
def main(argv=sys.argv):
options = None
logger = None
try:
from . import rlutil
parser = _get_optparse()
(options, args) = parser.parse_args(argv[1:])
args = rlutil.resolve_launch_arguments(args)
write_pid_file(options.pid_fn, options.core, options.port)
uuid = rlutil.get_or_generate_uuid(options.run_id, options.wait_for_master)
configure_logging(uuid)
# #3088: don't check disk usage on remote machines
if not options.child_name and not options.skip_log_check:
rlutil.check_log_disk_usage()
logger = logging.getLogger('roslaunch')
logger.info("roslaunch starting with args %s"%str(argv))
logger.info("roslaunch env is %s"%os.environ)
if options.child_name:
# 这里没执行到,就不列出来了
else:
logger.info('starting in server mode')
# #1491 change terminal name
if not options.disable_title:
rlutil.change_terminal_name(args, options.core)
# Read roslaunch string from stdin when - is passed as launch filename.
roslaunch_strs = []
# This is a roslaunch parent, spin up parent server and launch processes.
from . import parent as roslaunch_parent
if options.core:
options.port = options.port or DEFAULT_MASTER_PORT
p = roslaunch_parent.ROSLaunchParent(uuid, args, roslaunch_strs=roslaunch_strs, is_core=options.core, port=options.port, local_only=options.local_only, verbose=options.verbose, force_screen=options.force_screen, force_log=options.force_log, num_workers=options.num_workers, timeout=options.timeout, master_logger_level=options.master_logger_level, show_summary=not options.no_summary, force_required=options.force_required, sigint_timeout=options.sigint_timeout, sigterm_timeout=options.sigterm_timeout)
p.start()
p.spin()
roslaunch.main开启了日志,日志记录的信息可以帮我们了解main函数执行的顺序。
我们去Ubuntu的.ros/log/路径下,打开roslaunch-ubuntu-52246.log日志文件,内容如下。
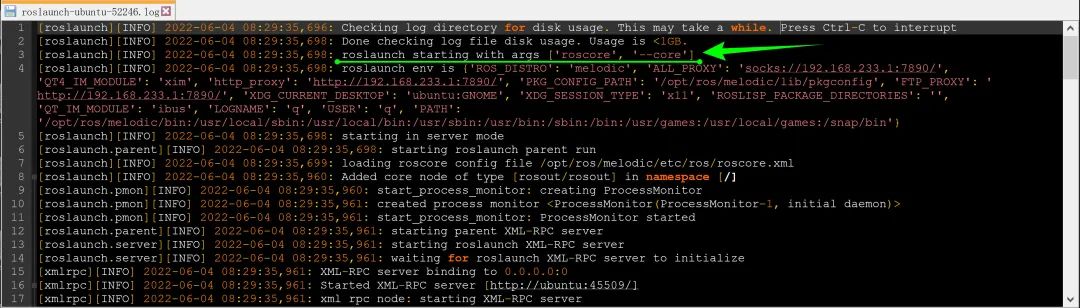
通过阅读日志我们发现,main函数首先检查日志文件夹磁盘占用情况,如果有剩余空间就继续往下运行。
然后把运行roscore的终端的标题给改了。
再调用ROSLaunchParent类中的函数,这大概就是main函数中最重要的地方了。
ROSLaunchParent类的定义是在同一路径下的parent.py文件中。为什么叫LaunchParent笔者也不清楚。
先不管它,我们再看日志,发现运行到了下面这个函数,它打算启动XMLRPC服务器端。
所以调用的顺序是:roslaunch\__init__.py文件中的main()函数调用parent.pystart()函数,start()函数调用自己类中的_start_infrastructure()函数,_start_infrastructure()函数调用自己类中的_start_server()函数,_start_server()函数再调用server.py中的start函数。
def _start_server(self):
self.logger.info("starting parent XML-RPC server")
self.server = roslaunch.server.ROSLaunchParentNode(self.config, self.pm)
self.server.start()
我们再进到server.py文件中,找到ROSLaunchNode类,里面的start函数又调用了父类XmlRpcNode中的start函数。
class ROSLaunchNode(xmlrpc.XmlRpcNode):
"""
Base XML-RPC server for roslaunch parent/child processes
"""
def start(self):
logger.info("starting roslaunch XML-RPC server")
super(ROSLaunchNode, self).start()
我们来到ros_comm-noetic-devel ools osgraphsrc osgraph路径,找到xmlrpc.py文件。找到class XmlRpcNode(object)类,再进入start(self)函数,发现它调用了自己类的run函数,run函数又调用了自己类中的_run函数,_run函数又调用了自己类中的_run_init()函数,在这里才调用了真正起作用的ThreadingXMLRPCServer类。
因为master节点是用python实现的,所以,需要有python版的XMLRPC库。
幸运的是,python有现成的XMLRPC库,叫SimpleXMLRPCServer。SimpleXMLRPCServer已经内置到python中了,无需安装。
所以,ThreadingXMLRPCServer类直接继承了SimpleXMLRPCServer,如下。
class ThreadingXMLRPCServer(socketserver.ThreadingMixIn, SimpleXMLRPCServer)
2.3.2.2master如何启动?
我们再来看看节点管理器master是如何被启动的,再回到parent.pystart()函数,如下。
我们发现它启动了XMLRPC服务器后,接下来就调用了_init_runner()函数。
def start(self, auto_terminate=True):
self.logger.info("starting roslaunch parent run")
try:
self._start_infrastructure()
except:
self._stop_infrastructure()
# Initialize the actual runner.
self._init_runner()
# Start the launch
self.runner.launch()
init_runner()函数实例化了ROSLaunchRunner类,这个类的定义在launch.py里。
def _init_runner(self):
self.runner = roslaunch.launch.ROSLaunchRunner(self.run_id, self.config, server_uri=self.server.uri, ...)
实例化完成后,parent.pystart()函数就调用了它的launch()函数。
我们打开launch.py文件,找到launch()函数,发现它又调用了自己类中的_setup()函数,而_setup()函数又调用了_launch_master()函数。
看名字就能猜出来,_launch_master()函数肯定是启动节点管理器master的,它调用了create_master_process函数,这个函数在nodeprocess.py里。
所以我们打开nodeprocess.py,create_master_process函数使用了LocalProcess类。这个类继承自Process类。nodeprocess.py文件引用了python中用于创建新的进程的subprocess模块。
create_master_process函数实例化LocalProcess类用的是’rosmaster’,即ros_comm-noetic-devel ools osmaster中的包。
main.py文件中的rosmaster_main函数使用了master.py中的Master类。
Master类中又用到了master_api.py中的ROSMasterHandler类,这个类包含所有的XMLRPC服务器接收的远程调用,一共24个,如下。
shutdown(self, caller_id, msg='')
getUri(self, caller_id)
getPid(self, caller_id)
deleteParam(self, caller_id, key)
setParam(self, caller_id, key, value)
getParam(self, caller_id, key)
searchParam(self, caller_id, key)
subscribeParam(self, caller_id, caller_api, key)
unsubscribeParam(self, caller_id, caller_api, key)
hasParam(self, caller_id, key)
getParamNames(self, caller_id)
param_update_task(self, caller_id, caller_api, param_key, param_value)
_notify_topic_subscribers(self, topic, pub_uris, sub_uris)
registerService(self, caller_id, service, service_api, caller_api)
lookupService(self, caller_id, service)
unregisterService(self, caller_id, service, service_api)
registerSubscriber(self, caller_id, topic, topic_type, caller_api)
unregisterSubscriber(self, caller_id, topic, caller_api)
registerPublisher(self, caller_id, topic, topic_type, caller_api)
unregisterPublisher(self, caller_id, topic, caller_api)
lookupNode(self, caller_id, node_name)
getPublishedTopics(self, caller_id, subgraph)
getTopicTypes(self, caller_id)
getSystemState(self, caller_id)
2.3.2.1检查log文件夹占用空间
roslaunch这个python包还负责检查保存log的文件夹有多大。在ros_comm-noetic-devel ools oslaunchsrc oslaunch\__init__.py文件中的main函数里,有以下语句。
看名字就知道是干啥的了。
rlutil.check_log_disk_usage()
再打开同一路径下的rlutil.py,发现它又调用了rosclean包中的get_disk_usage函数。
我们发现,这个函数里直接写死了比较的上限:disk_usage > 1073741824,当然这样不太好,应该改为可配置的。
数字1073741824的单位是字节,刚好就是1GB(102 4 3 1024^31024 3byte)。
我们要是想修改log文件夹报警的上限,直接改这个值即可。
def check_log_disk_usage():
"""
Check size of log directory. If high, print warning to user
"""
try:
d = rospkg.get_log_dir()
roslaunch.core.printlog("Checking log directory for disk usage. This may take a while.
Press Ctrl-C to interrupt")
disk_usage = rosclean.get_disk_usage(d)
if disk_usage > 1073741824:
roslaunch.core.printerrlog("WARNING: disk usage in log directory [%s] is over 1GB.
It's recommended that you use the 'rosclean' command."%d)
else:
roslaunch.core.printlog("Done checking log file disk usage. Usage is <1GB.")
except:
pass
我们刨根问底,追查rosclean.get_disk_usage(d)是如何实现的。
这个rosclean包不在ros_comm里面,需要单独下载。
打开后发现这个包还是跨平台的,给出了Windows和Linux下的实现。
如果是Windows系统,用os.path.getsize函数获取文件的大小,通过os.walk函数遍历所有文件,加起来就是文件夹的大小。
如果是Linux系统,用Linux中的du -sb命令获取文件夹的大小。哎,搞个机器人不仅要学习python,还得熟悉Linux,容易吗?
主节点会获取用户设置的ROS_MASTER_URI变量中列出的URI地址和端口号(默认为当前的本地IP和11311端口号)。
3、时间
不只是机器人,在任何一个系统里,时间都是一个绕不开的重要话题。下面我们就从万物的起点——时间开始吧。
ROS中定义时间的程序都在roscpp_core项目下的rostime中,见下图。
如果细分一下,时间其实有两种,一种叫“时刻”,也就是某个时间点;
一种叫“时段”或者时间间隔,也就是两个时刻之间的部分。这两者的代码是分开实现的,时刻是time,时间间隔是duration。
在Ubuntu中把rostime文件夹中的文件打印出来,发现确实有time和duration两类文件,但是还多了个rate,如下图所示。
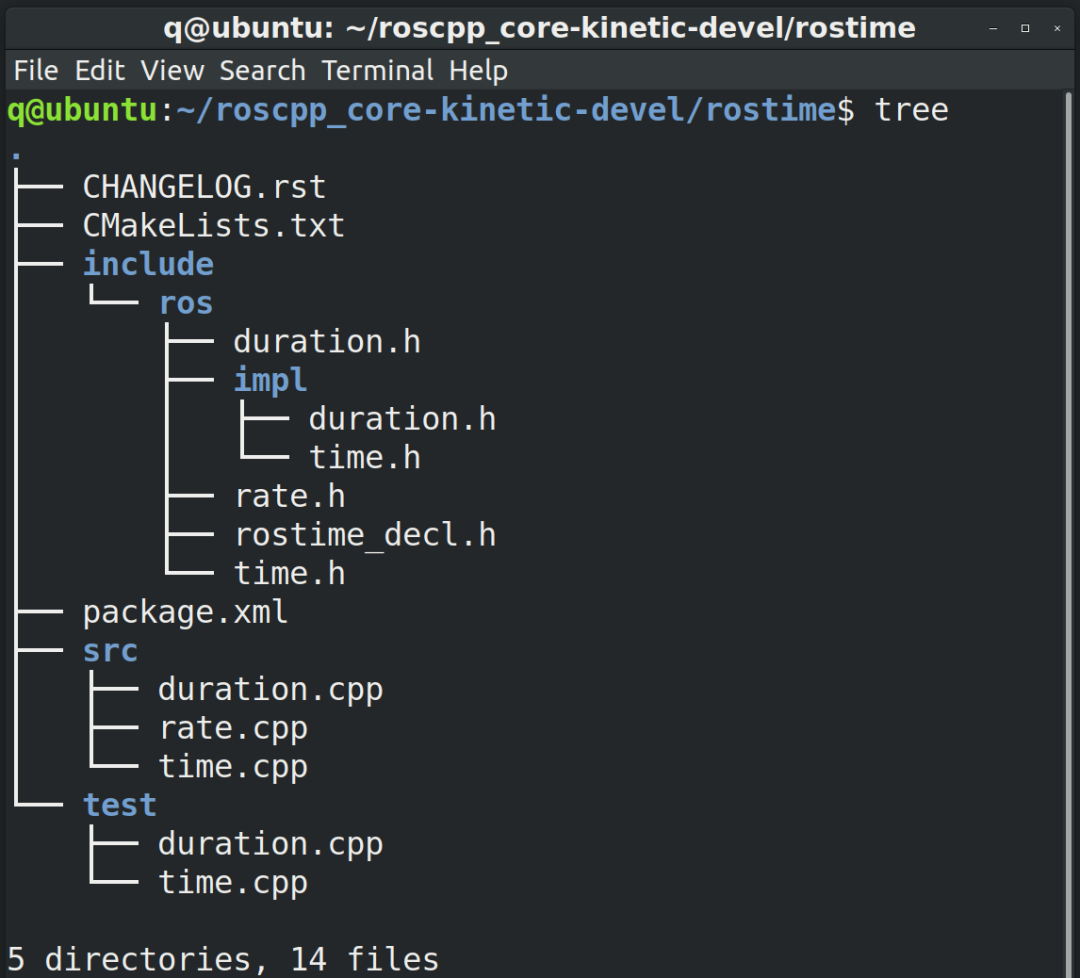
我们还注意到,里面有 CMakeLists.txt 和 package.xml 两个文件,那说明rostime本身也是个ROS的package,可以单独编译。
3.1时刻time
先看下文件间的依赖关系。跟时刻有关的文件是两个time.h文件和一个time.cpp文件。
time.h给出了类的声明,而impl ime.h给出了类运算符重载的实现,time.cpp给出了其它函数的实现。
3.1.1TimeBase基类
首先看time.h文件,它定义了一个叫TimeBase的类。注释中说,TimeBase是个基类,定义了两个成员变量uint32_t sec, nsec,还重载了+ ++、− -−、< <<、> >>、= ==等运算符。
成员变量uint32_t sec, nsec其实就是时间的秒和纳秒两部分,它们合起来构成一个完整的时刻。
至于为啥要分成两部分而不是用一个来定义,可能是考虑到整数表示精度的问题。
因为32位整数最大表示的数字是2147483647。如果我们要用纳秒这个范围估计是不够的。
你可能会问,机器人系统怎么会使用到纳秒这么高精度的时间分辨率,毕竟控制器的定时器最高精度可能也只能到微秒?
如果你做过自动驾驶项目,有使用过GPS和激光雷达传感器的经验,就会发现GPS的时钟精度就是纳秒级的,它可以同步激光雷达每个激光点的时间戳。
还有,为什么定义TimeBase这个基类,原因大家很容易就能猜到。
因为在程序里,时间本质上就是一个数字而已,数字系统的序关系(能比较大小)和运算(加减乘除)也同样适用于时间这个东西。
当然,这里只有加减没有乘除,因为时间的乘除没有意义。
3.1.2Time类
紧接着TimeBase类的是Time类,它是TimeBase的子类。我们做机器人应用程序开发时用不到TimeBase基类,但是Time类会经常使用。
3.1.3now()函数
Time类比TimeBase类多了now()函数,它是我们的老熟人了。在开发应用的时候,我们直接用下面的代码就能得到当前的时间戳:
ros::Time begin = ros::now(); //获取当前时间
now()函数的定义在rostimesrc ime.cpp里,因为它很常用很重要,笔者就把代码粘贴在这里,如下。
函数很简单,可以看到,如果定义了使用仿真时间(g_use_sim_time为true),那就使用仿真时间,否则就使用墙上时间。
Time Time::now()
{
if (!g_initialized)
throw TimeNotInitializedException();
if (g_use_sim_time)
{
boost::mutex::scoped_lock lock(g_sim_time_mutex);
Time t = g_sim_time;
return t;
}
Time t;
ros_walltime(t.sec, t.nsec);
return t;
}
在ROS里,时间分成两类,一种叫仿真时间,一种叫墙上时间。
顾名思义,墙上时间就是实际的客观世界的时间,它一秒一秒地流逝,谁都不能改变它,让它快一点慢一点都不可能,除非你有超能力。
仿真时间则是可以由你控制的,让它快它就快。之所以多了一个仿真时间,是因为有时我们在仿真机器人希望可以自己控制时间,例如为了提高验证算法的效率,让它按我们的期望速度推进。
在使用墙上时间的情况下,now()函数调用了ros_walltime函数,这个函数也在rostimesrc ime.cpp里。
剥开层层洋葱皮,最后发现,这个ros_walltime函数才是真正调用操作系统时间函数的地方,而且它还是个跨平台的实现(Windows和Linux)。
如果操作系统是Linux,那它会使用clock_gettime函数,在笔者使用的Ubuntu 18.04系统中这个函数在usrinclude路径下。
但是万一缺少这个函数,那么ROS会使用gettimeofday函数,但是gettimeofday没有clock_gettime精确,clock_gettime能提供纳秒的精确度。
如果操作系统是Windows,那它会使用标准库STL的chrono库获取当前的时刻,要用这个库只需要引用它的头文件,所以在time.cpp中引用了#include。
具体使用的函数就是
std::now().time_since_epoch()。
当然,时间得是秒和纳秒的形式,所以用了count方法:
uint64_t now_ns = std::duration_cast<std::nanoseconds>
(std::now().time_since_epoch()).count();
3.1.4WallTime类
后面又接着声明了WallTime类和SteadyTime类。
3.2时间间隔duration
时间间隔duration的定义与实现跟time时刻差不多,但是Duration类里的sleep()延时函数是在time.cpp里定义的,其中使用了Linux操作系统的nanosleep系统调用。
这个系统调用虽然叫纳秒,但实际能实现的精度也就是几十毫秒,即便这样也比C语言提供的sleep函数的精度好多了。如果是Windows系统则调用STL chrono函数:
std::sleep_for(std::nanoseconds(static_cast<int64_t>(sec * 1e9 + nsec)));
3.3频率rate
关于Rate类,声明注释中是这么解释的“Class to help run loops at a desired frequency”,也就是帮助(程序)按照期望的频率循环执行。
我们看看一个ROS节点是怎么使用Rate类的,如下图所示的例子。
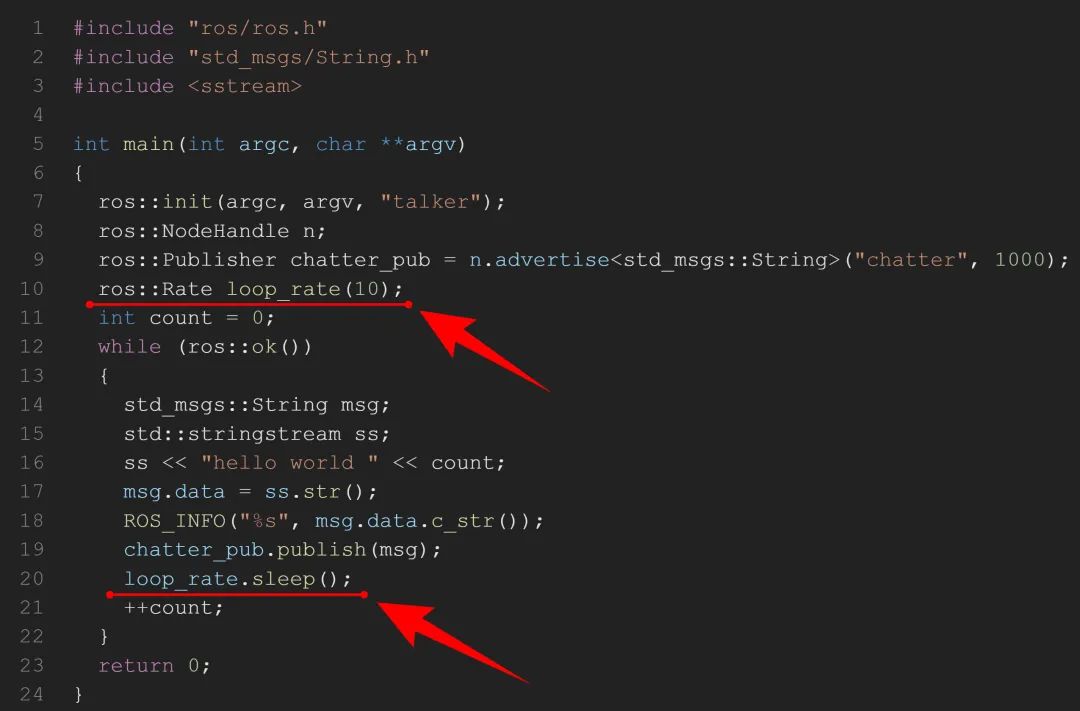
首先用Rate的构造函数实例化一个对象loop_rate。调用的构造函数如下。
可见,构造函数使用输入完成了对三个参数的初始化。
然后在While循环里调用sleep()函数实现一段时间的延迟。
既然用到延迟,所以就使用了前面的time类。
Rate::Rate(double frequency)
: start_(Time::now())
, expected_cycle_time_(1.0 / frequency)
, actual_cycle_time_(0.0)
{ }
3.4总结
至此rostime就解释清楚了。可以看到,这部分实现主要是依靠STL标准库函数(比如chrono)、BOOST库(date_time)、Linux操作系统的系统调用以及标准的C函数。这就是ROS的底层了。
说句题外话,在百度Apollo自动驾驶项目中也受到了rostime的影响,其cyber ime中的Time、Duration、Rate类的定义方式与rostime中的类似,但是没有定义基类,实现更加简单了。
审核编辑 :李倩
-
机器人
+关注
关注
212文章
29028浏览量
210066 -
函数
+关注
关注
3文章
4358浏览量
63438 -
ROS
+关注
关注
1文章
283浏览量
17321
发布评论请先 登录
相关推荐
研华科技加速智能自主系统与机器人应用发展
【书籍评测活动NO.58】ROS 2智能机器人开发实践
【「具身智能机器人系统」阅读体验】2.具身智能机器人的基础模块
《具身智能机器人系统》第10-13章阅读心得之具身智能机器人计算挑战
【「具身智能机器人系统」阅读体验】2.具身智能机器人大模型
【「具身智能机器人系统」阅读体验】1.初步理解具身智能
【「具身智能机器人系统」阅读体验】+初品的体验
ROSCon China 2024 | RDK第一本教材来了!地瓜机器人与古月居发布新书《ROS 2智能机器人开发实践》

深度剖析:MT6816 磁编码 IC 在机器人焊接变位机中的应用

ROS让机器人开发更便捷,基于RK3568J+Debian系统发布!

国产Cortex-A55人工智能教学实验箱_基于Python机械臂跳舞实验案例分享
基于鸿道(Intewell®)操作系统研发的农业机器人操作系统
技术融合与创新大象机器人水星Mercury X1人形机器人案例研究!

实现机器人操作系统——ADI Trinamic电机控制器ROS1驱动程序简介






 工商网监
工商网监
评论