 基于覆盖分数的采样方法用于视觉定位问题
基于覆盖分数的采样方法用于视觉定位问题
论文探讨了将连续学习用在视觉定位问题中,从而以增量方式在场景中训练模型。一般的将深度学习方法与视觉定位相结合,比如利用深度神经网络从输入图像直接回归相机姿态或者3D场景坐标,这些方法都假设在训练期间可以获得所有场景的静态数据分布,因为如果使用非平稳数据在视觉定位的深度网络中会导致灾难性遗忘,为了解决这个问题,论文提出了一种基于从固定缓冲区存储和回放图像的强基线,此外提出了一种新的基于覆盖分数的采样方法(Buff-CS),该方法将缓冲过程中的现有采样策略用于视觉定位问题,实验结果表明,在具有挑战性的数据集(7Scenes、12 Scenes、19 Scenes)上,通过结合前一场景,标准缓冲方法得到了改进。
为什么使用连续学习,它与一般的深度学习联合训练所有场景数据有何不同?连续学习是不断从传入的数据流中学习,在这种设置下,所有场景是依次遇到的,如图1所示。
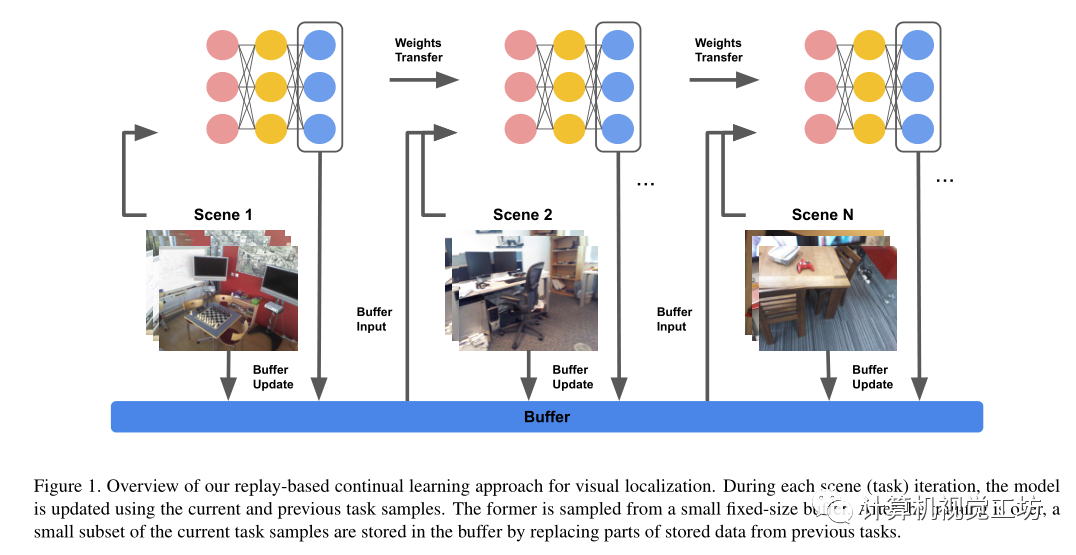
与对所有任务进行联合训练相比,以连续方式学习任务在样本和记忆效率方面有几个好处: 1)在联合训练环境中,每次场景发生变化时模型都需要在数据库中的所有场景上进行重新训练,即使是没有发生任何变化的场景。向数据库中添加新场景还需要模型重新训练,这会影响可伸缩性,需要将完整的数据集存储在内存中。 2)连续学习旨在通过仅在改变或新场景和存储在小缓冲区中的先前场景的图像上微调模型来降低计算成本,由于仅需要将当前场景的数据与来自先前场景的图像的小缓冲区一起存储在存储器中,因此也降低了存储器成本。这对于存储容量受设备限制的移动应用程序更友好。Contributions:1)介绍了视觉定位背景下的连续学习问题。 2)在多个室内数据集上,利用现有的基于缓冲方法创建了一个经验回放基线。 3)根据场景的3D几何结构提出一种新的缓冲策略.连续学习:

Buffering:为了防止在训练时发生灾难性遗忘,少量先前的数据存储在固定大小为B的缓冲区中。当前任务或类的输入图像和相应的标签存储在缓冲区中,将这个在缓冲区中存储图像的过程称为Img-buff,除了图像之外还存储了提供更好的流形结构的中间表示,例如存储预softmax层逻辑提供了类概率的分布,该类概率对类间语义关系进行编码。缓冲区存储中间表示为Rep-buff。Replay:回放是在学习当前任务的同时对缓冲区中存储的过去场景的样本进行重新迭代的过程。当前任务样本和缓冲区B中的任务样本的最终损失计算如下:
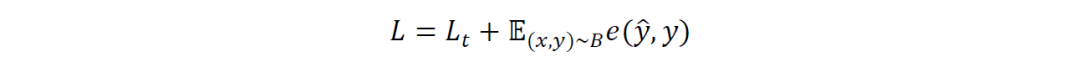
存储在B中的中间表示可以通过知识蒸馏的过程用作伪标签。例如来自当前网络状态的逻辑被约束为与存储在缓冲存储器B中的相应逻辑相似
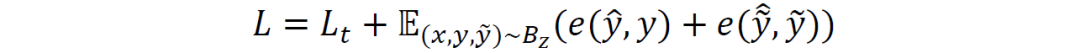
缓冲算法:缓冲算法决定当前任务中的哪些样本将被存储以供将来回放以及缓冲区中存储的哪些样本要被替换,算法有两个阶段,第一阶段包括填充缓冲区,直到其充满,然后第二阶段决定额外传入实例的缓冲概率。将连续学习用在视觉定位:本文基于之前提出的一种基于学习的方法,HSC-Net,其在一组参数化的分层网络层中保持场景的隐式表示,这些分层网络层预测每个2D像素位置的3D场景坐标,然后使用PnP,2D-3D对应关系用于获得最终查询相机姿态估计。在连续学习设置中,场景按顺序呈现,对于Img buff,仅将输入图像和相应的3D场景坐标y存储在B中,此外Rep buff存储了中间聚类级别预测(此为HSCNet中的东西),与分类问题不同,视觉定位在场景或类上是多样的,并且是独立的,在特定子场景的图像上学习定位不会使场景的其他部分通用化,为了在给定场景的所有子场景上保持定位性能,缓冲区需要保持最大化场景覆盖率的图像,此论文提出了一种方法去采样图像从而提供更好的场景覆盖率,称为Buff-CS,即如果与缓冲图像观察到的实例相比,传入的新实例提供了新的场景观察,则将缓冲概率增加到1,

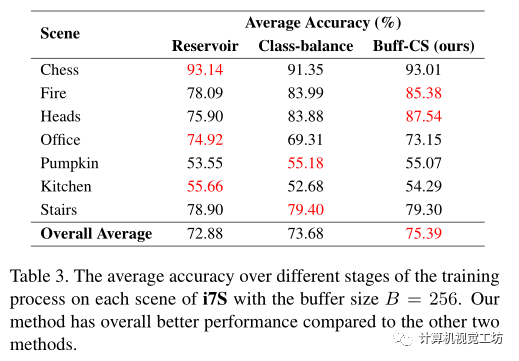
实验:数据集为7Scenes、12Scenes,为了以顺序的方式评估连续学习方法,论文将单独的七个场景和十二个场景集成到单个坐标系。 采用了两种缓冲方法作为基线,即Reservoir和Class-balance。Reservoir旨在从未知大小的输入流中采样k个数据实例,其中k是预定义的样本大小,这种方法保证了单个帧被选择到缓冲区的概率相同。Class-balance旨在进一步解决在连续学习中的类不平衡问题。此方法使类尽可能保持平衡,同时保留每个类/场景的分布。 在视觉定位的连续学习任务中,单个场景以增量方式被馈送到训练网络,也就是说第一场景中的数据被训练以估计场景坐标,然后训练权重被用作第二场景的初始化,为了在连续学习设置中训练HSCNet,在相应场景的训练完成后,对每个场景的训练数据进行采样并存储在缓冲器中,如前所述,仅缓冲输入图像和相应标签被称为Img-buff,另外缓冲中间表示被称为Rep-buff,对于Img-buff将RGB图像、深度图和地面真实姿态存储到缓冲区。对于Rep-buff还存储了预softmax层逻辑和预测的场景坐标。 表1报告了训练完成后在所有场景上平均的姿势准确度和覆盖得分方面的表现
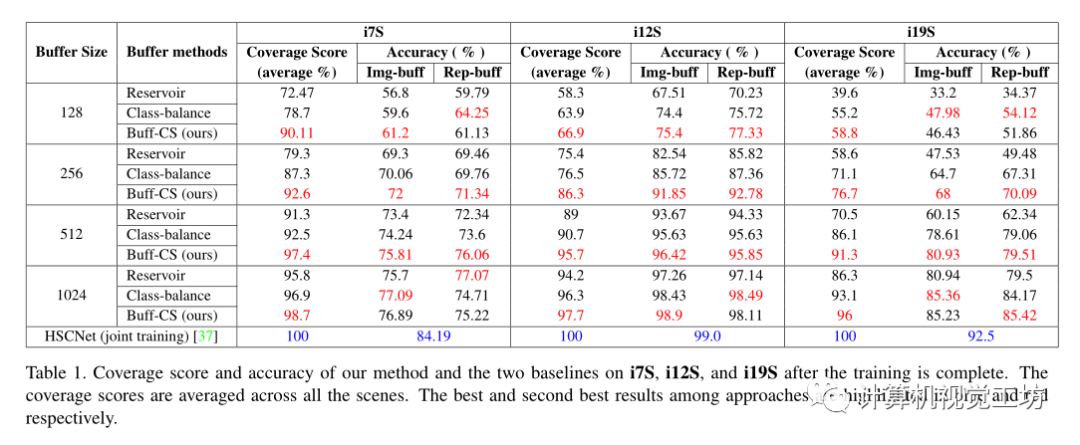
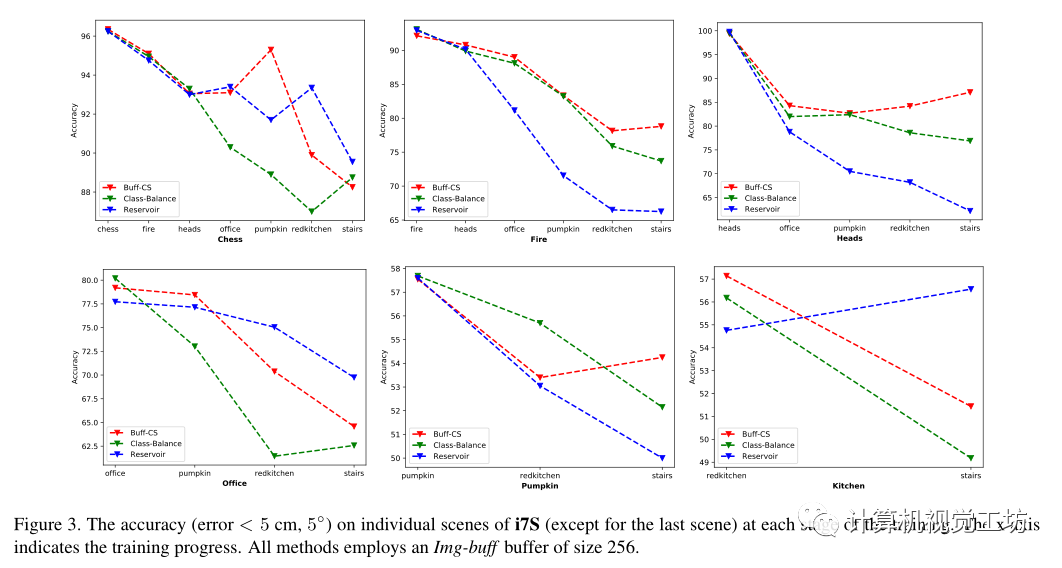
表3中的平均精度评估了三种方法在完成新任务后对先前任务的性能。表3显示了平均精度
总结:在多个室内定位数据集上对所提出的方法进行了评估,这些数据集在不同设置下相对于基线表现出更好的或有竞争力的性能。 论文实验部分可以说是论文的亮点,有时间还是去读一下论文实验部分,其有更好的分析。
审核八年级:郭婷
-
神经网络
+关注
关注
42文章
4774浏览量
100899 -
深度学习
+关注
关注
73文章
5508浏览量
121295
原文标题:把连续学习的思路用在基于图像的相机定位问题中( ICCV 2021)
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
视觉定位在焊接机器人中的作用


适用于机器视觉应用的智能机器视觉控制平台

SegVG视觉定位方法的各个组件
一种将NeRFs应用于视觉定位任务的新方法





激光焊接视觉定位引导方法


用STM8做一个用于抽取频谱的东西, 如何采样128个点用于FFT数据计算?
UWB定位技术与GPS定位区别及应用






 工商网监
工商网监
评论