 GMMSeg:生成式语义分割新范式!可同时处理闭集和开集识别
GMMSeg:生成式语义分割新范式!可同时处理闭集和开集识别
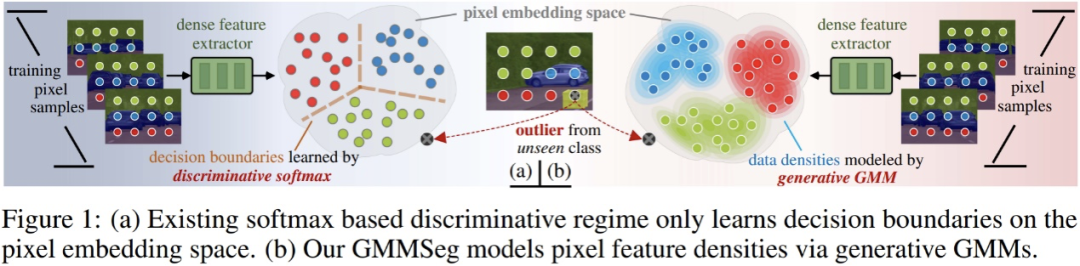
GMMSeg 同时具备判别式与生成式模型的优势,在语义分割领域,首次实现使用单一的模型实例,在闭集 (closed-set) 及开放世界 (open-world) 分割任务中同时取得先进性能。
当前主流语义分割算法本质上是基于 softmax 分类器的判别式分类模型,直接对 p (class|pixel feature) 进行建模,而完全忽略了潜在的像素数据分布,即 p (class|pixel feature)。这限制了模型的表达能力以及在 OOD (out-of-distribution) 数据上的泛化性。 在最近的一项研究中,来自浙江大学、悉尼科技大学、百度研究院的研究者们提出了一种全新的语义分割范式 —— 基于高斯混合模型(GMM)的生成式语义分割模型 GMMSeg。

GMMSeg: Gaussian Mixture based Generative Semantic Segmentation Models
论文链接:https://arxiv.org/abs/2210.02025
代码链接:https://github.com/leonnnop/GMMSeg
GMMSeg 对像素与类别的联合分布进行建模,通过 EM 算法在像素特征空间学习高斯混合分类器 (GMM Classifier),以生成式范式对每一个类别的像素特征分布进行精细捕捉。与此同时,GMMSeg 采用判别式损失来端到端的优化深度特征提取器。这使得 GMMSeg 同时具备判别式与生成式模型的优势。 实验结果表明,GMMSeg 在多种分割网络架构 (segmentation architecture) 及骨干网络 (backbone network) 上都获得了性能提升;同时,无需任何后处理或微调,GMMSeg 可以直接被应用到异常分割 (anomaly segmentation) 任务。 迄今为止,这是第一次有语义分割方法能够使用单一的模型实例,在闭集 (closed-set) 及开放世界 (open-world) 条件下同时取得先进性能。这也是生成式分类器第一次在大规模视觉任务中展示出优势。 判别式 v.s. 生成式分类器
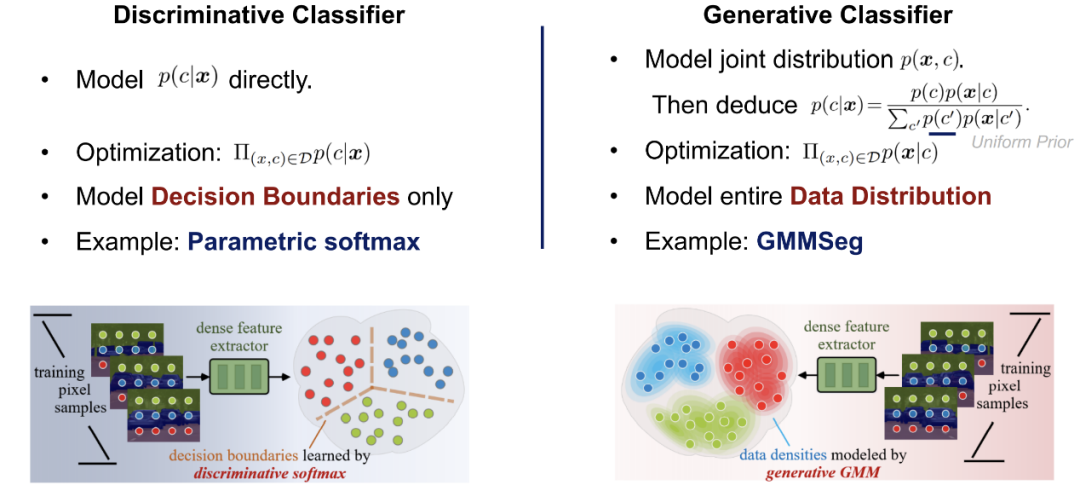
在深入探讨现有分割范式以及所提方法之前,这里简略引入判别式以及生成式分类器的概念。 假设有数据集合 D,其包含成对的样本 - 标签对 (x, y);分类器的最终目标是预测样本分类概率 p (y|x)。分类方法可以被分为两类:判别式分类器以及生成式分类器。
判别式分类器:直接建模条件概率 p (y|x);其仅仅学习分类的最优决策边界,而完全不考虑样本本身的分布,也因此无法反映样本的特性。
生成式分类器:首先建模联合概率分布 p (x, y),而后通过贝叶斯定理推导出分类条件概率;其显式地对数据本身的分布进行建模,往往针对每一个类别都会建立对应的模型。相比于判别式分类器,其充分考虑了样本的特征信息。
主流语义分割范式:判别式 Softmax 分类器 目前主流的逐像素分割模型大多使用深度网络抽取像素特征,而后使用 softmax 分类器进行像素特征分类。其网络架构由两部分组成: 第一部分为像素特征提取器,其典型架构为编码器 - 解码器对,通过将 RGB 空间的像素输入映射到 D - 维度的高维空间获取像素特征。 第二部分为像素分类器,即主流的 softmax 分类器;其将输入的像素特征编码为 C - 类实数输出(logits),而后利用 softmax 函数对输出(logits)归一化并赋予概率意义,即利用 logits 计算像素分类的后验概率:
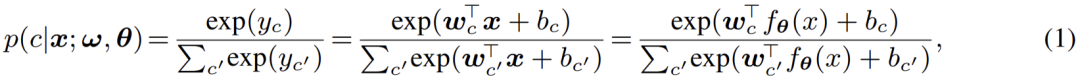
最终,由两个部分构成的完整模型将通过 cross-entropy 损失进行端到端的优化:
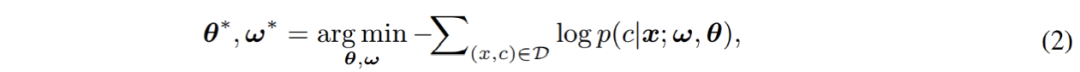
在此过程中,模型忽略了像素本身的分布,而直接对像素分类预测的条件概率 p (c|x) 进行估计。由此可见,主流的 softmax 分类器本质为判别式分类器。 判别式分类器结构简单,并因其优化目标直接针对于缩小判别误差,往往能够取得优异的判别性能。然而与此同时,其有一些尚未引起已有工作重视的致命缺点,极大的影响了 softmax 分类器的分类性能及泛化性:
首先,其仅仅对决策边界进行建模;完全忽视了像素特征的分布,也因而无法对每一个类别的具体特性进行建模与利用;削弱了其泛化性以及表达能力。
其次,其使用单一的参数对 (w,b) 建模一个类别;换言之,softmax 分类器依赖于单模分布 (unimodality) 假设;这种极强且过于简化的假设在实际应用往往不能成立,这导致其只能够取得次优的性能。
最后,softmax 分类器的输出无法准确反映真实的概率意义;其最终的预测只能作为与其他类别进行比较时的参考。这也正是大量主流分割模型较难检测出 OOD 输入的根本原因。
针对这些问题,作者认为应该对目前主流的判别式范式进行重新思考,并在本文中给出了对应的方案:生成式语义分割模型 ——GMMSeg。 生成式语义分割模型:GMMSeg 作者从生成式模型的角度重新梳理了语义分割过程。相较于直接建模分类概率 p (c|x),生成式分类器对联合分布 p (x, c) 进行建模,而后使用贝叶斯定理推导出分类概率:
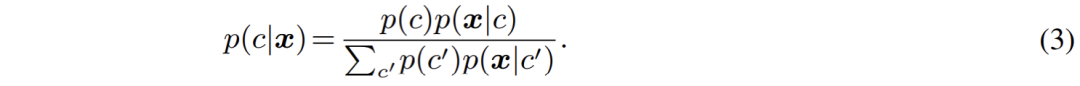
其中,出于泛化性考虑,类别先验 p (c) 往往被设置为 uniform 分布,而如何对像素特征的类别条件分布 p (x|c) 进行建模,就成为了当前的首要问题。 在本文中,即 GMMSeg 中,采用高斯混合模型对 p (x|c) 进行建模,其形式如下:
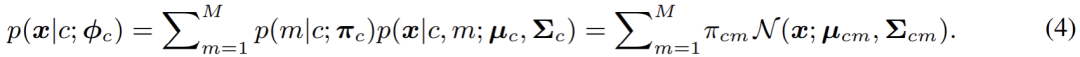
在分模型 (component) 数目不受限的情况下,高斯混合模型理论上能够拟合任意的分布,因而十分优雅且强大;同时,其混合模型的本质也使得建模多模分布 (multimodality),即建模类内变化,变得可行。基于此,本文采用极大似然估计来优化模型的参数:
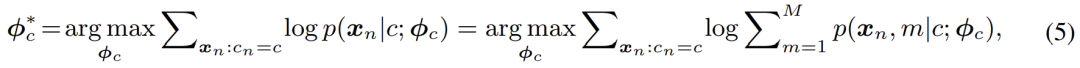
其经典的解法为 EM 算法,即通过交替执行 E-M - 两步逐步优化 F - 函数:
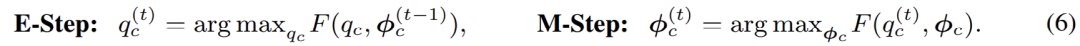
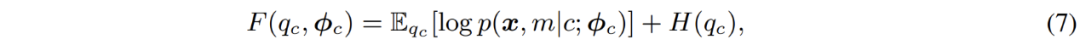
具体到高斯混合模型的优化;EM 算法实际上在 E - 步中,对数据点属于每一个分模型的概率进行了重新估计。换言之,其相当于在 E - 步中对像素点进行了软聚类 (soft clustering);而后,在 M - 步,即可利用聚类结果,再次更新模型参数。
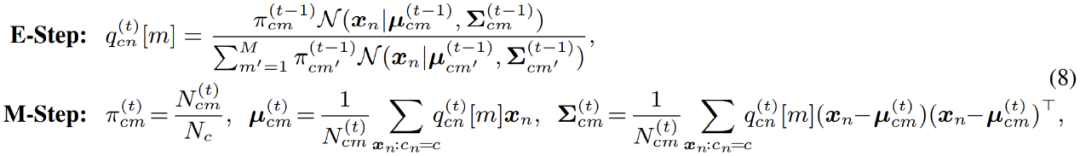
然而在实际应用中,作者发现标准的 EM 算法收敛缓慢,且最终结果较差。作者怀疑是由于 EM 算法对参数优化初始值过于敏感,导致其难以收敛到更优的局部极值点。受到近期一系列基于最优传输理论 (optimal transport) 的聚类算法的启发,作者对混合分模型分布额外引入了一个 uniform 先验:
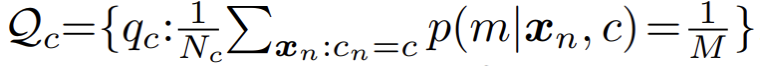
相应的,参数优化过程中的 E - 步骤被转化为约束优化问题,如下:
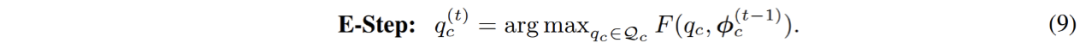
这个过程可以被直观的理解成,对聚类过程引入了一个均分的约束:在聚类过程中,数据点能够被一定程度上均匀的分配给每一个分模型。引入此约束之后,此优化过程就等价于下式列出的最优传输问题:
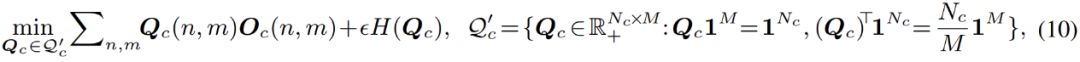
此式可以利用 Sinkhorn-Knopp 算法快速求解。而整个改进过后的优化过程被命名为 Sinkhorn EM,其被一些理论工作证明,具有与标准 EM 算法相同的全局最优解,且更不容易陷入局部最优解。 在线混合 (Online Hybrid) 优化 之后,在完整的优化过程中,文章中使用了一种在线混合 (online hybrid) 的优化模式:通过生成式 Sinkhorn EM,在逐渐更新的特征空间中,不断对高斯混合分类器进行优化;而对于完整框架中另一个部分,即像素特征提取器部分,则基于生成式分类器的预测结果,使用判别式 cross-entropy 损失进行优化。两个部分交替优化,互相对齐,使得整个模型紧密耦合,并且能够进行端到端的训练:

在此过程中,特征提取部分只通过梯度反向传播优化;而生成式分类器部分,则只通过 SinkhornEM 进行优化。正是这种交替式优化的设计,使得整个模型能够紧凑的融合在一起,并同时继承来自判别式以及生成式模型的优势。 最终,GMMSeg 受益于其生成式分类的架构以及在线混合的训练策略,展示出了判别式 softmax 分类器所不具有的优势:
其一,受益于其通用的架构,GMMSeg 与大部分主流分割模型兼容,即与使用 softmax 进行分类的模型兼容:只需要替换掉判别式 softmax 分类器,即可无痛增强现有模型的性能。
其二,由于 hybrid 训练模式的应用,GMMSeg 兼并了生成式以及判别式分类器的优点,且一定程度上解决了 softmax 无法建模类内变化的问题;使得其判别性能大大提升。
其三,GMMSeg 显式建模了像素特征的分布,即 p (x|c);GMMSeg 能够直接给出样本属于各个类别的概率,这使得其能够自然的处理未曾见过的 OOD 数据。
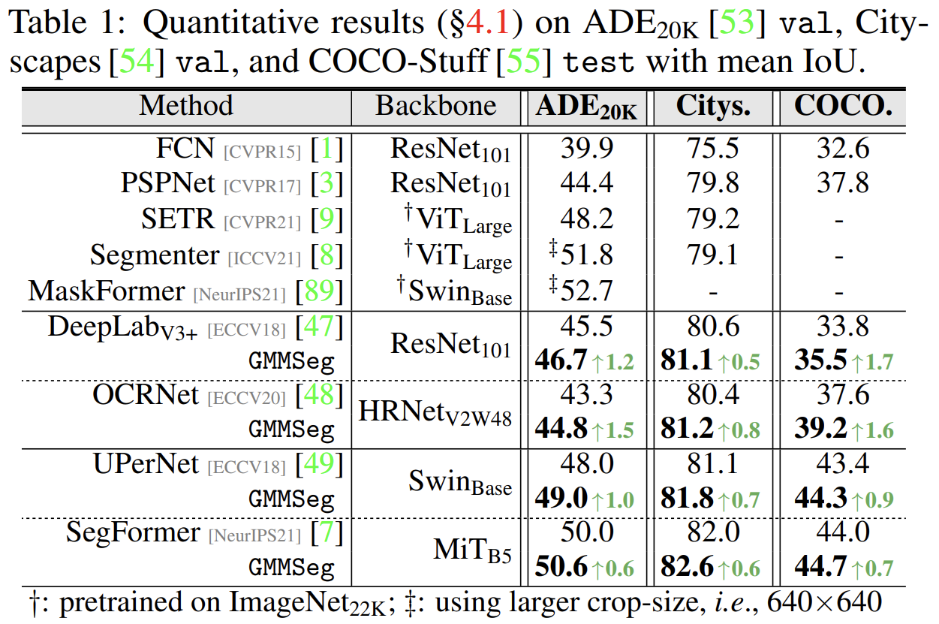
实验结果 实验结果表明,不论是基于 CNN 架构或者是基于 Transformer 架构,在广泛使用的语义分割数据集 (ADE20K, Cityscapes, COCO-Stuff) 上,GMMSeg 都能够取得稳定且明显的性能提升。

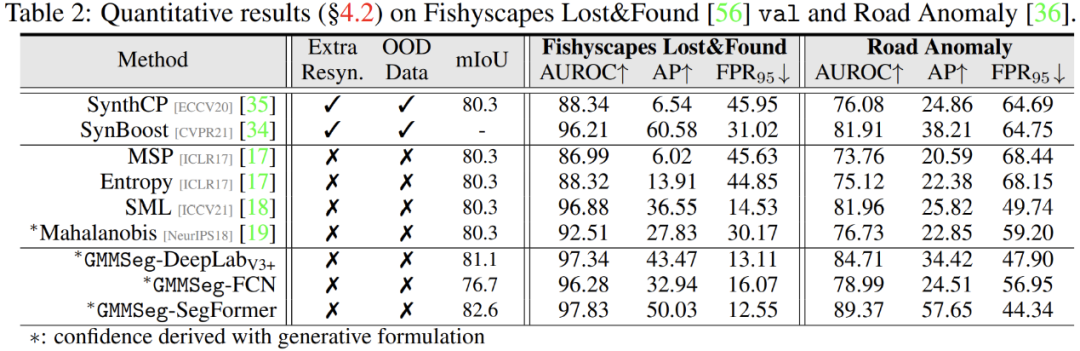
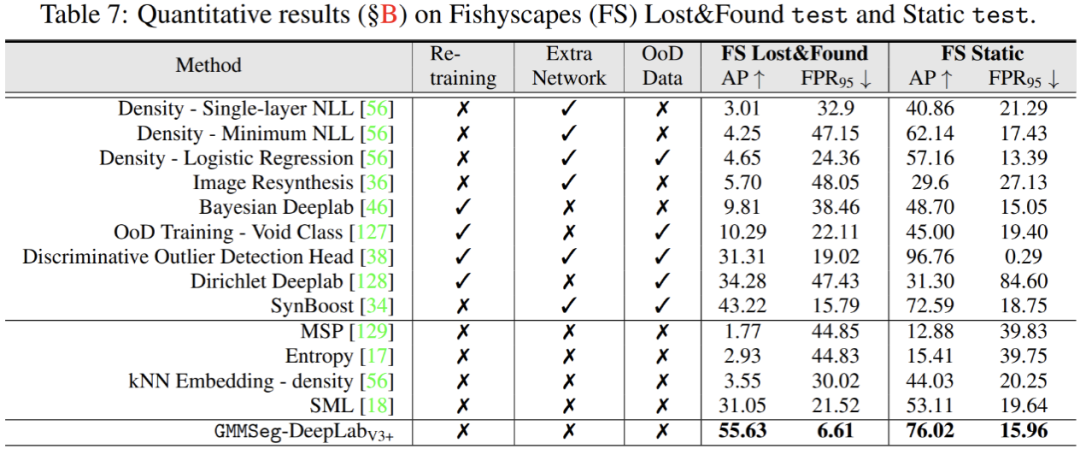
除此之外,在异常分割任务中,无需对在闭集任务,即常规语义分割任务中训练完毕的模型做任何的修改,GMMSeg 即可在所有通用评价指标上,超越其他需要特殊后处理的方法。

审核编辑 :李倩
-
算法
+关注
关注
23文章
4622浏览量
93063 -
分类器
+关注
关注
0文章
152浏览量
13202
原文标题:NeurIPS 2022 | GMMSeg:生成式语义分割新范式!可同时处理闭集和开集识别
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
RISC-V的指令集位宽的几点学习心得
C# 调用2020版本Labview生成的.NET指令集报错,2018不报错
简述微处理器的指令集架构
微处理器的指令集有哪些
RISC-V和arm指令集的对比分析
RISC-V指令集的特点总结
微处理器的指令集架构介绍
图像语义分割的实用性是什么
如何理解机器学习中的训练集、验证集和测试集
图像分割与语义分割中的CNN模型综述
请问NanoEdge AI数据集该如何构建?
语音数据集:智能驾驶中车内语音识别技术的基石
Harvard FairSeg:第一个用于医学分割的公平性数据集

自动驾驶数据集的生成模型之WoVoGen框架原理






 工商网监
工商网监
评论