 对话机器人之LaMDA
对话机器人之LaMDA
来自:NLP日志
提纲1 简介 2 LaMDA 3 总结
1 简介
LaMDA是在DeepMind的Sparrow跟openai的instructGPT之前由谷歌提出的对话机器人,全称Language Models for Dialog Applications,是一个在海量对话跟web数据上进行预训练再在人工标注数据上做进一步微调后得到的参数量高达137B的大模型。LaMDA除了在生成文本质量有所提升外,通过在人工标注数据上做进一步finetune以及让模型学会检索利用外部知识源的能力,使得模型在安全性以及事实性这两个关键问题上获得明显提升。
安全性指的是模型的回复应该满足一系列人为价值观,例如没有歧视跟偏见,不会生成伤害性建议。事实性指的模型的回复应该符合事实,跟外部知识源保持一致,而不是一本正经的胡说八道。
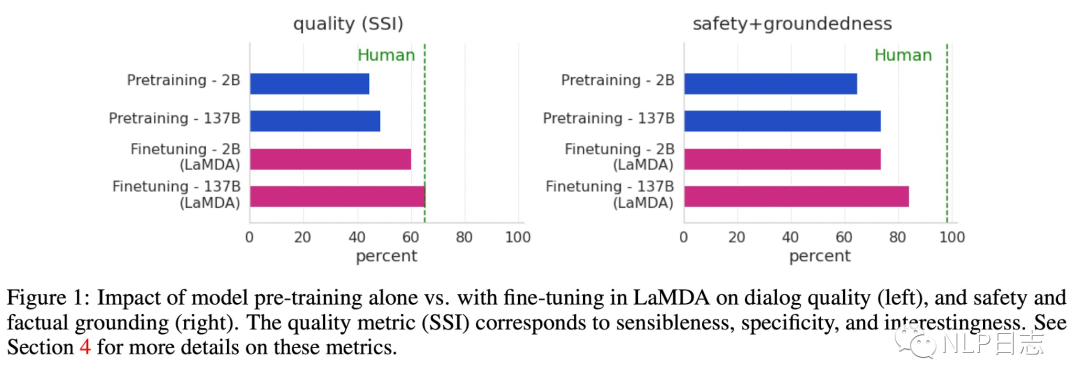
图1: LaMDA在生成文本在多个指标下有明显提升
2 LaMDA
Pre-training
LaMDA采用的是纯decoder的结构,类似于GPT,使用了46层Transformer,模型参数量高达130B,是Meena的50倍。预训练的任务是预测文本中的下一个token,解码策略跟Meenay一致,都是从top-40结果采样得到16个候选回复,再基于候选回复的对数似然得分跟长度选择最优的回复。不同于此前的对话模型只在对话数据上训练,LaMDA的预训练数据集包括对话数据(1.12B)和其他web文档数据(2.97B)。

图2: LaMDA预训练任务
Finetune
LaMDA的finetune包括两部分,一部分是针对生成文本质量跟安全性,另一部分则是学习如何利用外部的信息检索系统。其中质量(SS I)可以从三方面评估,分别是sensibleness(文本是否合理,跟历史对话是否有冲突),Specificity(对于前文是否有针对性,避免笼统回复,例如用户提问“I love Eurovision”,模型生成一个笼统回复“Me too”就不符合预期),Interestingness(文本是否能引起某人注意或者好奇,是否是超出期待的巧妙回复)。而安全性(Safety)的目标则是要符合谷歌AI的基本原则,避免生成会造成伤害的不符合预期的结果,或者带有偏见跟歧视。
a)Finetuning for quality and safety
这部分的finetune既包括给定上文生成回复的生成任务,也包括评估回复质量跟安全性的判别式任务。对于生成任务,训练样本格式由“
Finetune过程先对LaMDA的判别任务进行优化,使得模型可以预测候选回复的质量得分跟安全性得分,然后过滤掉安全性得分低于阈值的候选回复,再根据质量得分对候选回复进行排序(3*P(sensibleness)+P(specificity)+P(interestingness)),选择其中得分最高的回复作为模型生成的结果。再利用已经训练后LaMDA的打分模型,筛选出高质量的训练数据,用于LaMDA的生成任务的finetune,使得模型可以生成高质量的回复。根据下图也可以看到利用高质量数据进行的finetune让模型在各方面都有了明显的提升。
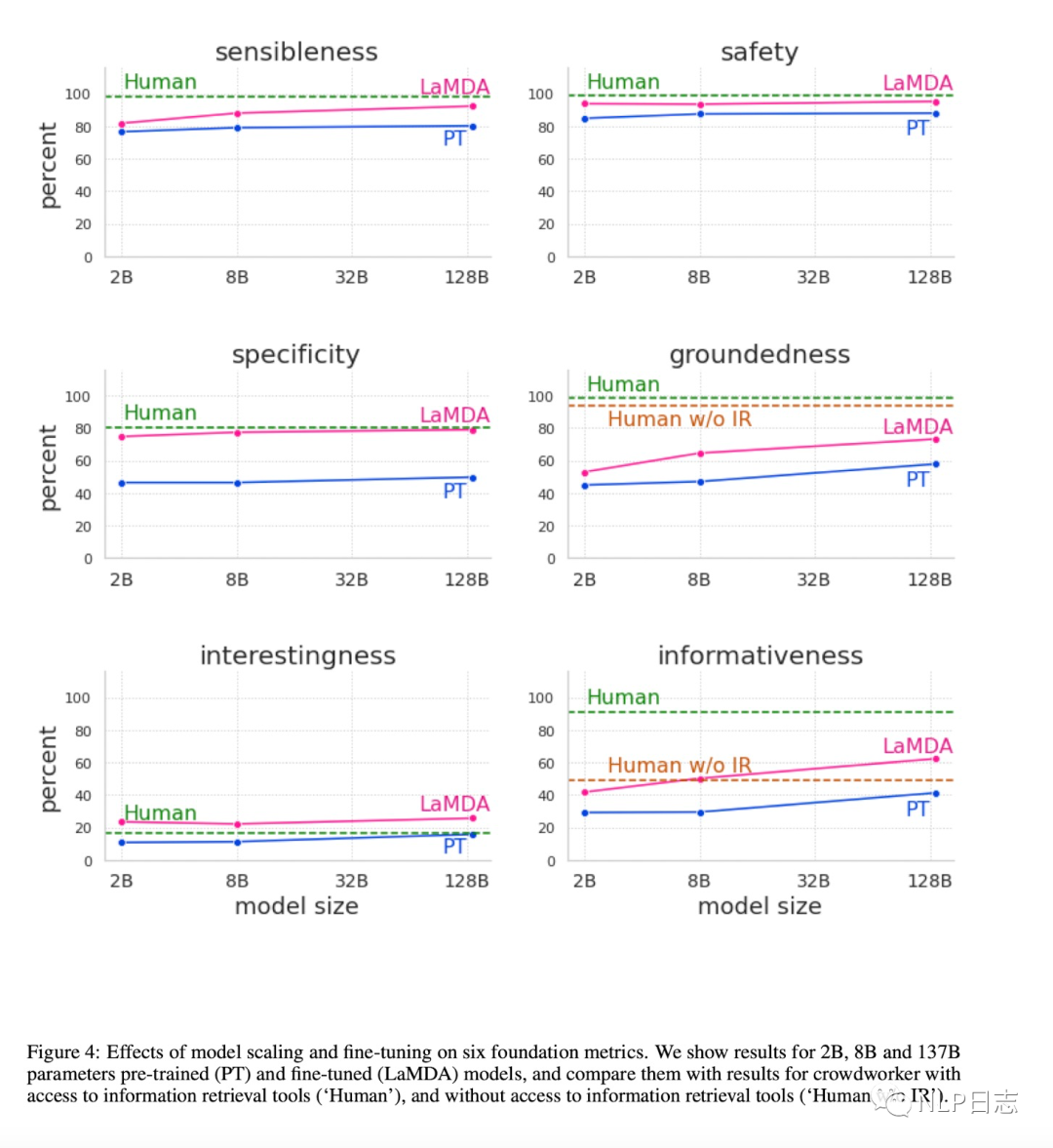
图3: finetune模型在多个指标上的提升
b)Finetuning to learn to call an external information retrieval system
这部分也称为Groundedness,针对语言模型的可能生成看起来可信,但是违背事实的幻视问题,LaMDA通过学习使用利用外部知识源去缓解这个问题。LaMDA构建一个包含信息检索系统,计算模块,翻译模块的工具(简称TS),这部分的finetune也包括两个子任务,第一个是将历史上文跟模型回复一起输入到模型中,生成对应的检索query。第二个子任务是将历史上文+模型回复+检索结果一同输入到模型中,让模型决定是生成新的检索query或者生成最终回复(根据生成的第一个字符串决定,如果是TS,则继续检索,如果是User则返回对应结果)
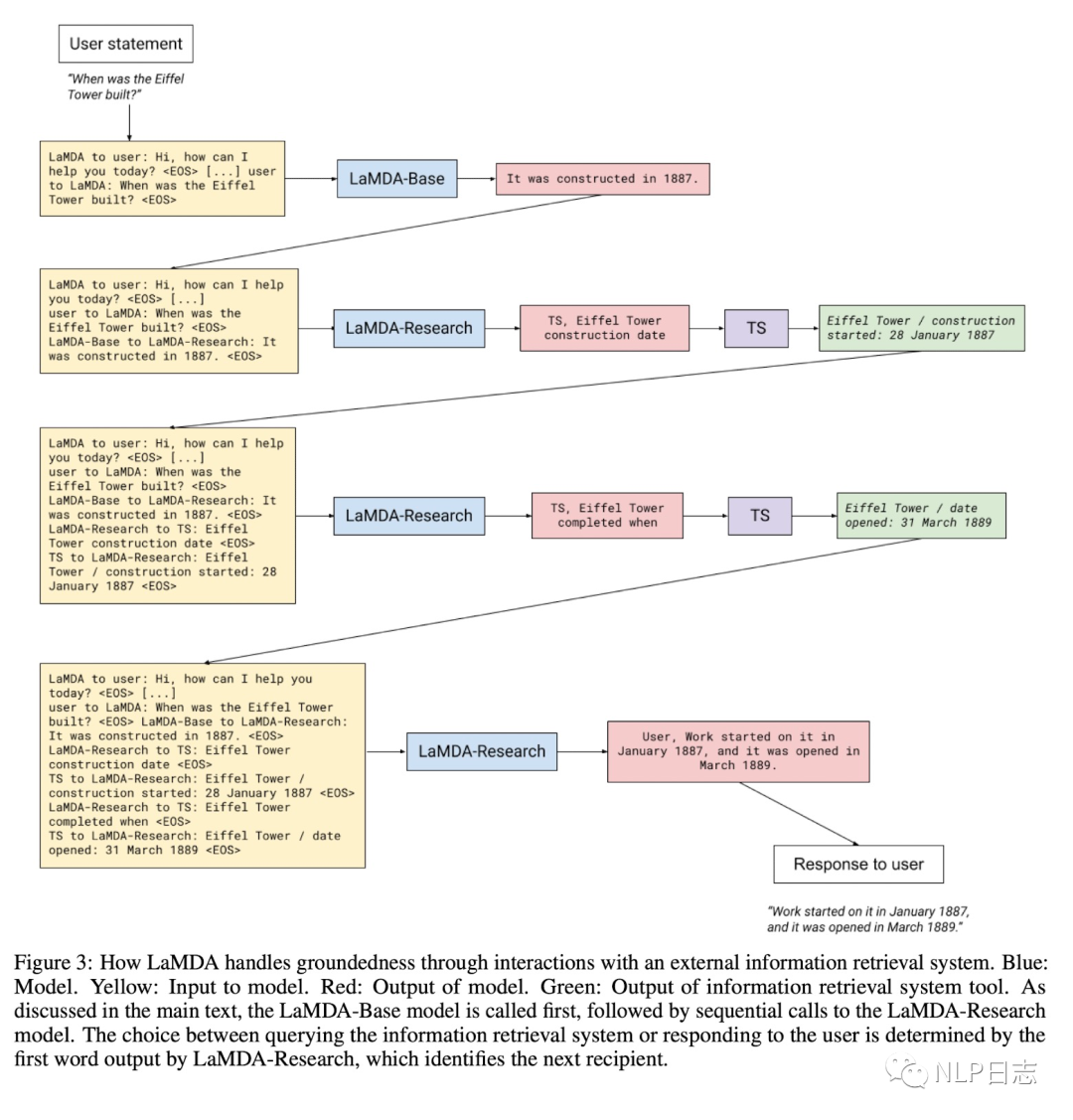
图4: LaMDA Search流程
在具体推理流程中,只用一个LaMDA模型,但是做了多个子任务,具体过程中该执行哪个子任务,则由当前输入的prompt决定,例如当前输入prompt是LaMDA to user就对应自动生成回复,如果当前prompt是LaMDA-Base to LaMDA-Research就对应生成检索query。
3 总结
从LaMDA跟后续的Sparrow,我们也可以看到一些共同点。1)可以使用一个强大的模型同时处理多个不同任务。2)finetune阶段高质量数据对于模型的最终性能影响颇大,为了得到这些高质量的数据,LaMDA跟Sparrow在搜集finetune数据有一套严格的方法论。3) 让模型学习检索利用外部知识源,可以缓解模型幻视的问题,让模型生成结果更佳有理可依,也让模型可以回答与时俱进的问题。4)为生成文本的安全性设计额外的子任务,从而缓解敏感性的问题。LaMDA的成功,依旧贯彻着大力出奇迹的思路,不仅模型的参数量庞大,预训练的语料庞大,连finetune阶段的人工标注数据也不是一般人可以承受的。
-
机器人
+关注
关注
212文章
28887浏览量
209513 -
模型
+关注
关注
1文章
3406浏览量
49457
原文标题:对话机器人之LaMDA
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论