 一个时代有一个时代的计算架构
一个时代有一个时代的计算架构
Can Machines Think?
这是阿兰·图灵在1950年论文《计算机器和智能》中的经典提问,围绕着图灵的目标,软件和硬件开启了分头行动。
软件,以算法为核心,衍生出了神经网络,并在深度学习的加持下,让人工智能浪潮实现全面汹涌。
硬件,以芯片为载体,从CPU、GPU到各类AI芯片,从执行人的计算程序,到像人一样计算。芯片和AI,硬件和软件,一个源头流出的两条大河,终于在此刻合流交汇。
但背后的驱动力也越来越明显:
一个时代有一个时代的架构。
现在,面向AI时代的计算架构,呼之欲出。
让机器执行人的思考和计算:从CPU到GPU
要想知道未来到哪去,必先知道自己从哪儿来。
今天,一切智能机器无论大小,都少不了一块CPU。正是这个好比“大脑”的东西,让大大小小的硬件可以执行人写好的规则,实现各式各样的功能。
世界首块CPU诞生于1971年,但它的概念可以追溯到世界上第一台具有现代意义的通用计算机——EDVAC身上。
EDVAC是ENIAC(世界第一台电子计算机)的小老弟,由冯·诺伊曼设计。EDVAC最大的改变之一,就是将计算机划由运算器、控制器、存储器、输入和输出这五个部分组成。
这就是著名的冯·诺伊曼架构。从这个架构里,我们就可以看到CPU的雏形。
——从彼时至今,无论CPU的具体实现怎么变、晶体管数量翻多少番,它的构成始终由运算器、控制器和寄存器这三大部分组成。
其中,运算器也叫算术逻辑单元(ALU),负责算术运算和逻辑运算。寄存器细分为指令寄存器和数据寄存器等,负责暂存指令、ALU所需的操作数、ALU算出的结果等。
控制器则负责整体调度工作,包括对要执行的指令进行译码、从内存中调取数据给寄存器、向运算器和寄存器发出具体操作指令等。
从上面这个分工我们也能看出CPU的大概工作流程,简单来说就是这四步:
1、从内存提取指令;2、解码;3、执行;4、写回。
其中写回到寄存器的结果,可供后续指令快速访问。
看起来,整个流程没有什么bug。
但仔细回看一下CPU三大组成的各自分工,可以发现控制器和寄存器是这里面要负责的东西最多、要存的东西最多的两部分。
从下面这张CPU的简略架构图也能看出,运算器“偏居一隅”,几乎80%的空间都被控制单元和存储单元占据。

这样的设计就造成CPU最擅长的是逻辑控制,而非计算。
同时,依照冯·诺依曼架构“顺序执行”的原则,“古板”的CPU只能执行完一条指令再来下一条,计算能力进一步受限。
当然,你说CPU灵活性高、通用性强,我们可以将它进行同构并行。
但别忘了,单个CPU的性能上限就那么高、能容纳的核数也有限,这种方法能挖掘的潜能实在有限。
所以,要是让CPU来完成计算量动辄上亿的AI任务,实在是“爱莫能助”。就比如在自动驾驶领域,系统需要同时查看人行道、红绿灯等路况,如果交给CPU来计算,总不能车都撞上了还没算出来结果吧。
所以,针对CPU“拉垮”的计算能力,GPU站在了浪潮之巅。
正如其全称“图形计算单元”,GPU的初衷主要是为了接替CPU进行图形渲染的工作。
因为图像上的每一个像素点都需要处理,这项任务计算量相当大。尤其遇上一个复杂的三维场景,就需要在一秒内处理几千万个三角形顶点和光栅化几十亿的像素。
不过,由于每个像素点处理的过程和方式相差无几,这项艰巨的任务可以靠并行计算来化解。
而这恰好就是GPU最得天独厚的优势,尤其以处理这种逻辑简单、类型统一的琐碎计算任务为甚。
GPU之所以擅长并行计算,从其架构里就决定了。
GPU几乎主要由计算单元ALU组成,仅有少量的控制单元和存储单元。
这也就意味着,GPU可以拥有数百、数千甚至上万核心来同时处理计算任务,使计算的并行度得到成千上万倍的提升——相比现在普通电脑最多8核CPU同时工作,这是一个多么恐怖的数字。
再举一个最简单的例子来直观感受一下。
比如现在我们来计算一下5000个数相加之后的总和。
如果我们用CPU来算,即使派上8核CPU,每个核也需要计算625个数;假设每计算一个数需要1s,即使8核并行计算,总共也需要625s。(这里暂时不考虑支持向量指令的CPU)而GPU,核心数成千上万,计算5000个数字只需每核算1个数,1s就能搞定。
625sVS1s,这是何等的差距。
除了并行计算能力,GPU的内存带宽也是CPU的几十倍 ,决定了它将数据从内存移动到计算核心的速度更快,整体计算性能更加让CPU望尘莫及。
由于GPU的设计并没有专门跟图形绑定的逻辑,属于一种通用的并行计算架构,所以除了图像处理,它其实也非常适用于科学计算,乃至复杂的AI任务。
所以在2012年,当Hinton及其弟子Alex Krizhevsky将其作为深度学习模型AlexNet的计算芯片,一举赢得Image Net图像识别大赛之后,GPU在AI领域的名声就一炮打响。
而早就基于自家GPU推出了CUDA系统的英伟达,又凭借着三年时间里将GPU性能提升65倍,并提供后端模型训练和前端推理应用的全套深度学习解决方案,奠定了自己在该领域的王者地位。
直到今天,GPU也还是AI时代算力的核心、人工智能硬件领域的霸主。
然而,GPU属于通用计算芯片和架构,并非专门为AI打造,无法实现性能和功耗的统一。它的计算能力越强代表核心越多,功耗也就越大。
比如RTX 4090,450W;比如今年9月刚上市的H100,直接史无前例,700W。这种情况还大有逐年攀升之势。
还是拿自动驾驶举例,在电车基本成为主流的当下,如此高的功耗势必对续航里程造成困扰。更别提越来越多的终端也开始具备AI能力(比如手机、智能音箱),它们不仅要求计算能力,对功耗的要求也更加严格,再强的GPU在这里也显得很弱势。
另外,一些更复杂的AI场景(如云端推理、模型训练等),常常动辄就需要上百块GPU一起运算,这让整个计算平台的功耗控制也是相当棘手。很多机构不得不考虑能源和环保问题。
这不,今年7月诞生的目前最大的多语言开源模型BLOOM,就动用了384块A100炼成,释放的热量最终都用来给学校供暖了。
所以,综上来看,CPU和GPU的出现,虽然帮助机器拥有了执行人的思考和计算的能力,尤其后者让AI计算任务得到了相当大的加速,但一些缺点还是让它们无法大展身手。
因此要想让机器像人一样思考和计算,通用计算芯片的架构决定了不会是最佳方案。
让机器像人一样思考和计算:AI芯片大爆发
数据驱动的方式方法,让机器像人一样思考和计算展现了可能。
但背后的计算需求,也让过去的计算架构越显强弩之末。
据统计,光是在2012年到2018年的六年时间里,人们对于算力的需求增长了就超过30万倍。也就说,每3.5个月AI算力就大约翻一倍。如今这个数字还在继续攀升。
所谓“通不如精”,以CPU和GPU为代表的通用计算芯片架构,已经无法很好地匹配和满足这一需求,所以在各类新AI技术层出不穷的同时,新计算、新架构、新芯片在过去几年也迎来了前所未有的大爆炸。
因此这几年,我们看到了很多除了CPU和GPU以外的各种“xPU”,诸如谷歌TPU、Graphcore IPU、特斯拉NPU、英伟达DPU……
尽管它们的分类不同,有的属于半定制化的FPGA,有的属于全定制化的ASIC,有的应用于终端,有的应用于云端……但作为专门为AI任务和需求而生的新芯片,它们都有着比CPU/GPU功耗低、计算性能高、成本更低等优势,落地到哪里就给哪里带去了翻天覆地的变化,比如最近几年的智能手机、自动驾驶、机器人、VR等领域。
按照能力和用途,这些AI芯片们在这个过程中上演了这样两个阶段:
首先是仅作为加速器,辅助CPU完成HPC、模型训练/推理等AI任务。
(AI芯片几乎都不具有图灵完备,所以必须要和CPU一起搭配使用,这也是所谓的“异构融合”大趋势。)
它们的结构类似串联,可以用“CPU+xPU”这样的公式来表达。
这一组合最经典的其实就是CPU+GPU,它俩到现在其实也还在流行。
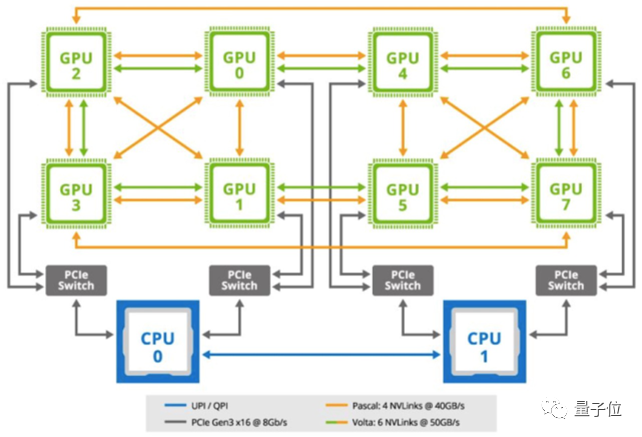
只不过如前面所说,GPU不算专门为AI设计的芯片,无法在这一领域发挥出极致的性能,所以这里的xPU更多的指TPU、IPU、DPU等AI加速芯片。
(当然,GPU还是自有它的用处,所以它有时也会加入进来,形成“CPU+GPU+xPU”的结构。)
这一模式最大的特点就是,CPU只负责少量的计算,一般为那些情况比较复杂、计算难度不确定、灵活性要求高的部分;大部分“脏活累活”都由计算能力超强、能耗又没那么高的xPU来完成。
就如下图所示,在实际情况中,它们的分工很可能遵守“二八定律”——xPU负责整个系统80%的计算任务,剩下的20%由CPU+GPU分担,其中GPU的比例又高达16%,留给CPU的只剩下4%。
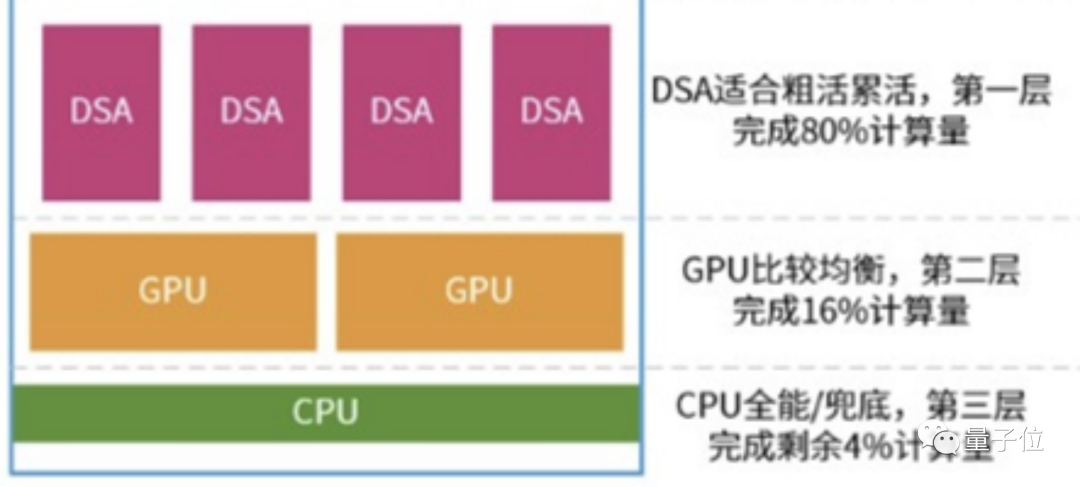
如果进行软硬件融合的进一步优化,三者之间的比例还可能变动为90%、9%和1%。
这样各司其职、各挥所长的安排可以保证最极致的性能和性价比,做到从前CPU和GPU单上无法企及的高度。
其次,AI芯片作为专用芯片,针对专门的领域推出,负责某一特定AI任务的计算。
(说通俗点,就是某一块专用芯片能在自动驾驶领域使用,换了机器人领域就不行)。
在这种模式下,各xPU已成为各系统的主角,决定该系统的整体性能和效果。
这就导致一些自动驾驶公司,在宣传它们的技术时,只把xPU拉出来大肆宣传,基本不提CPU和GPU的事儿了。
那么CPU在干嘛?当然是利用自己擅长的逻辑控制来把控整个流程。
因此此时,CPU和AI芯片的关系更像一种并联结构,我们就可以用“CPU、xPU”的公式来表达(当然,GPU也仍然可能参与其中)。
如前面所说,由于CPU基本不决定计算性能,我们也就不用再寄希望于CPU的战斗力有多强。
进一步地,我们可以认为,这种模式其实是将通用计算芯片的核心地位削减了——CPU的地位又变了。
那么,成为“中流砥柱”的AI芯片们究竟有多大威力?我们来看3个案例。
首先是云端。
在这个领域,互联网巨头们有着“本土作战”的优势,因此大多可以不依赖英伟达等传统巨头。
如谷歌2015年就推出了自己的云端加速AI芯片TPU。
它的中文名叫张量处理器,属于ASIC芯片的一种,专为加速深度学习框架TensorFlow而设计。
得益于用量化技术进行8位整数运算、脉动阵列、基于复杂指令集(CISC)等设计,它与同期的CPU和GPU相比(英特尔至强E5-2699 v3与Tesla K80 GPU),可以提供大约15-30倍的性能提升。
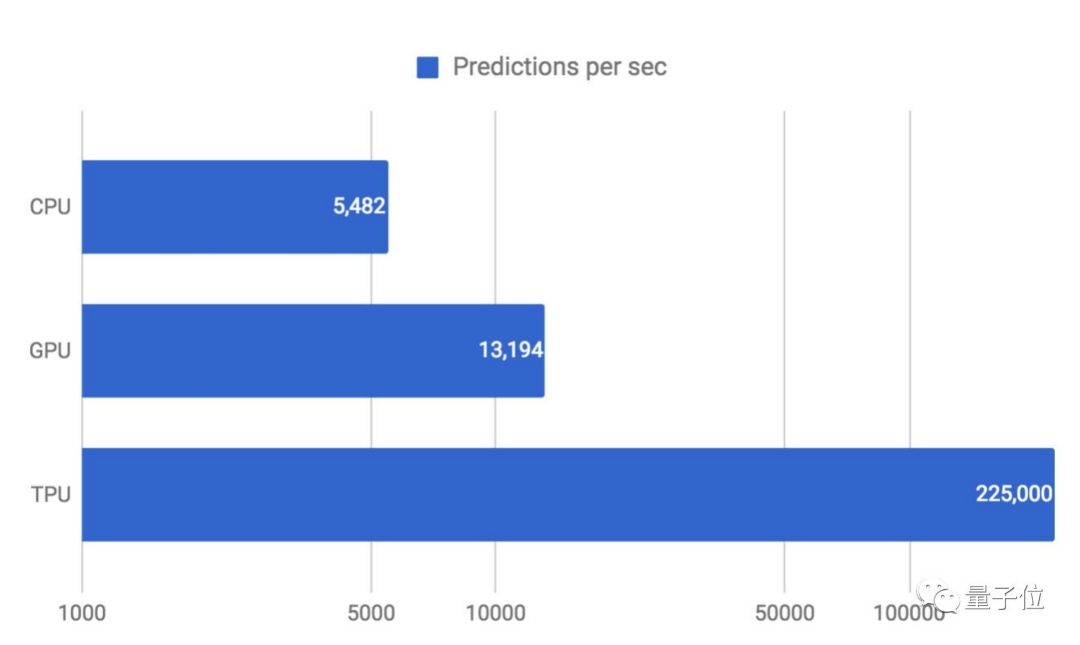
如下图所示,当将延迟全部控制在7毫秒之内时,TPU每秒可运行的MLP0预测可达22.5万次。同等情况下,CPU只有5000多,GPU也仅为1.3万+。
效率方面(性能/瓦特)的提升也高达30-80倍:
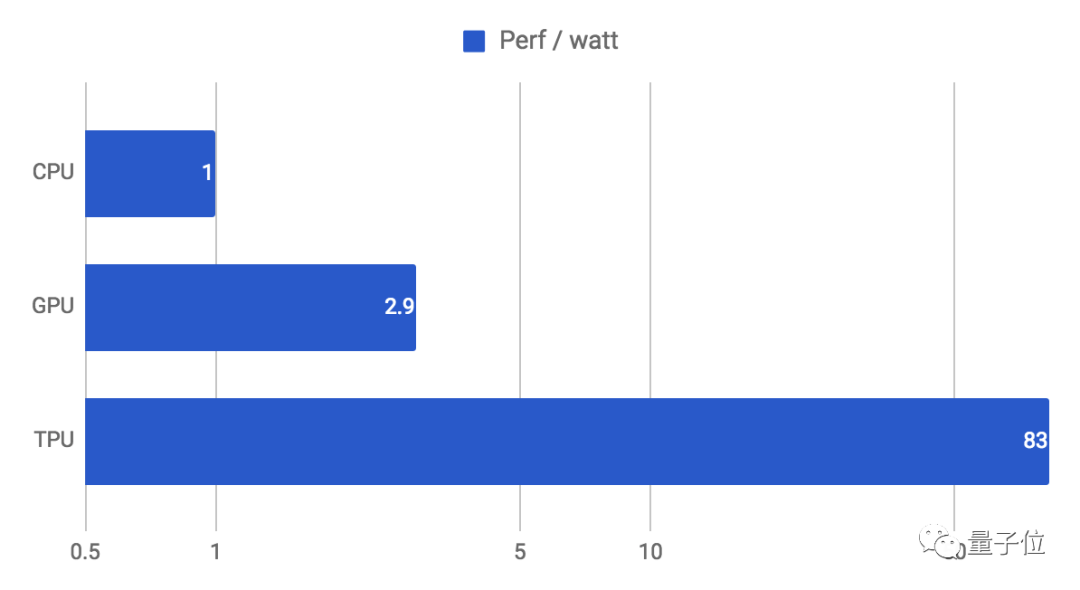
(谷歌第一代TPU功耗约为40W,性能最强的第四代也只有175W,而同时期的A100已达400W。)
这样的成绩意味着它既可以大规模运行于最先进的神经网络,也可以同时把成本控制在可接受的程度上。
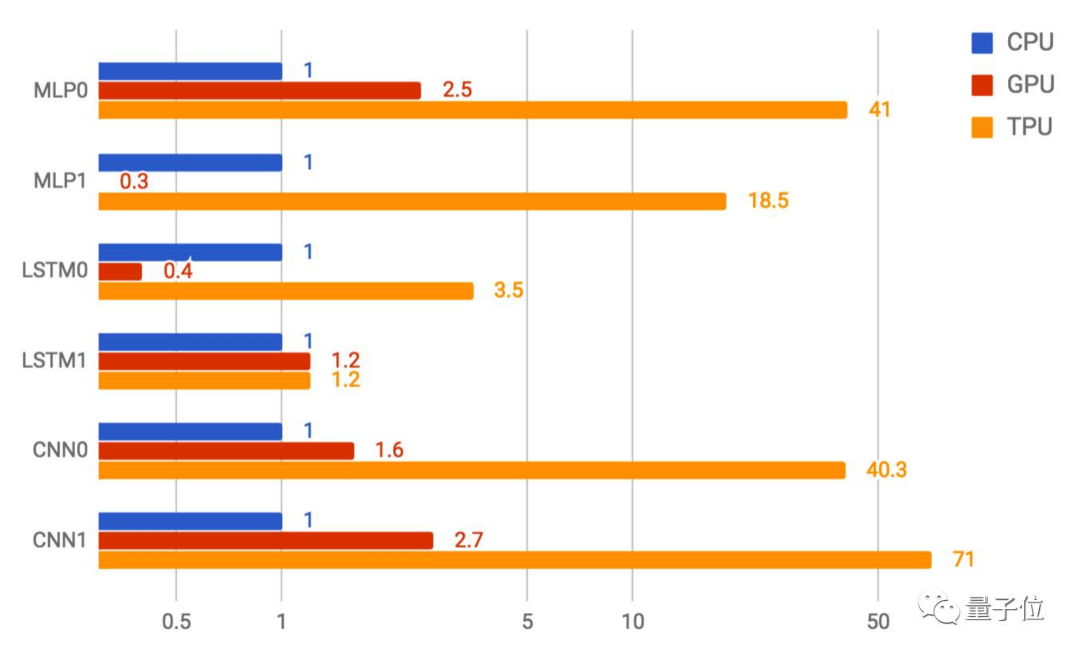
△TPU在以上6种神经网络中的CNN1上表现最好,性能是GPU的26倍
它的出现,不仅打破了深度学习硬件执行的瓶颈,也在一定程度上撼动了英伟达等传统巨头的地位。
谷歌也对它重用有加,搜索、街景、照片、翻译等服务以及AlphaGo背后的神经网络计算,都交由它来完成。TPU的出现,成为了AI时代云端计算需求的代表性解决方案。
终端方面,最具代表性的场景是AI司机变革下的汽车领域,即自动驾驶。
目前,自动驾驶芯片有两条主要技术路线:
一是英伟达Orin靠“魔改”GPU所走的通用架构路线;另一个是特斯拉、高通、Mobileye等青睐的专用芯片技术路线,也就是CPU+(GPU)+xPU的形式。
比如特斯拉FSD芯片就是主要由CPU、GPU和NPU组成。

△图源wikichip,特斯拉FSD芯片die shot图
其中,NPU是里面占比最大的处理器,是整个架构的重点。
它是由特斯拉硬件团队自研的一种ASIC芯片,主要用来对视觉算法中的卷积运算和矩阵乘法运算进行有效加速。
具体来看,每块NPU的运行频率为2GHz,峰值性能可达每秒36.86万亿次运算(TOPs),总功耗却仅为7.5W。
所以,正是从特斯拉开始,专为自动驾驶所需的神经网络打造的NPU开始成为汽车芯片的主要组成部分,传统的通用芯片CPU、GPU开始退居辅助位置。
国内方面,唯一实现车载智能芯片大规模前装量产的地平线,其代表芯片征程系列,也是采用“CPU+ASIC”的技术路线,ASIC部分用的是自研的BPU。
它的使用使最新的征程5芯片算力达到了128TOPS,功耗也只有30W。
由此,征程5靠4.3TOPS/W能耗比,一举超过了特斯拉FSD(2TOPS/W)、也超过了2022年高端智能电动车标配的英伟达Orin(3.9TOPS/W)。
这种性能和功耗展现出的对比,甚至是标志性的。背后是芯片架构在AI时代正在发生的变化趋势:
CPU在其中的作用和地位一直在变化,而这其实反映的是AI时代计算架构客观需求的进化——
一开始是完全规则驱动,只有CPUGPU等通用计算芯片进行发力,但由于架构的规则都是被写死的,无法适应越来越快的算力需求;
于是开始了半规则驱动,CPUGPU等通用计算芯片的核心能力继续发力,但已开始有专用芯片的介入,让AI计算架构不再依赖于完全写死的规则,相对灵活地发挥出价值;
再到后来,便开启了自定义规则驱动的阶段,此时专用型AI芯片占据核心地位,CPU/GPU仅仅作辅助之用,AI计算架构获得最大的自由度。
而我们的机器也终于能够从执行人的思考和计算,越来越接近像人一样思考和计算。
但这还不是终点。
终极计算架构:Neural Computing
终点是什么?不同视角会有不同的答案。
最近正在被更多人认同的是:Neural Computing,神经网络架构,或者说神经网络统一架构。
即一个大一统的神经网络计算架构,一套架构驱动所有场景、领域或任务,比如图像处理、视频编解码、图像的生成、渲染,只需要很少的一点点改动或者一点点算法的调优,就能解决各式各样的问题。
其特点,就是用技术驱动的方式去集成少量的规则,让硬件因软件而打造,软件为实现算法而生,这样更符合AI算法模型和任务的特点,也才能真正让模型跃迁驱动性能跃迁。而不再是传统的用硬件迭代解决问题。
而且这种方法论,不只是单纯的展望,因为正在被实践。
比如智能车载芯片,不仅用神经网络做了分割、检测和识别等语义级信息,而且能够清晰地看到一个趋势,包括ISP(Image Signal Processing)这样的图像处理任务,也都能够用神经网络实现了。
而业内,视频编解码相关的方法,神经网络也比传统方式实现得更好,信噪比更优异。
这两年火爆的NeRF,涉及到过去非常考验硬件能力的图像渲染,需要基于光线追踪等等图形学理论建立复杂规则的算法,也都被证明神经网络可以做得更好。
甚至用的还是很简单的神经网络计算方法,通过学习再推理的方式重构整个过程,把过去花费大力气求解的3D点云恢复重建等问题,更直接高效解决,实力和潜力,都不言自明了。
更重要的是,这种实践被放到了一个更具时代变革的趋势上:计算架构领域到了一个分久必合的时候,到了一个传统冯诺依曼架构亟待突破的时候。
这是两个时代的划分,背后是人与机器关系的两种范式。
1.0时代,依赖于经验和规则,把人类理性分析转换成计算机可具体执行的规则代码,不仅定义目标,也定义整个执行的过程。
这个时代里有很多经典的算法排序,会告诉机器每一步做什么,以及怎么做。CPU和GPU都是这个时代里的集大成者。
2.0时代,依靠的是神经网络学习和迭代,人类提目标、要求,有时目标甚至会是一个大致的方向和框架,但机器会在神经网络驱动下,搞清楚如何去执行,如何围绕目标求解最优解——机器有了自主性。于是就得从算法、架构到芯片确保机器的这种自主性。
1.0时代可以很多精细的规则、后处理、后融合,把所有人类对于具体场景任务的know-how变成计算机可严格执行的代码,再与“摩尔定律”和硬件革新配合,做到极致的高效。
然而AI模型范式下对数据的需求,以及先进制程的濒临极限,摩尔定律失效已然是再明显不过的事实。
所以计算架构和范式,一定会进入2.0时代,人类架构的是神经网络模型,模型自己去求解目标和结果,整个过程不再依赖人写死的规则和经验。这会是软件、硬件到认知方法方方面面的根本性改变——传统的计算架构不再适用。
这种对自主机器到来的判断,实际也能理解很多新现象。
比如马斯克为什么把特斯拉的下一步,定在机器人形态上。
百度创始人李彦宏,把自动驾驶、智能车,放在了“汽车机器人”的维度上思考和谈论。
以及当前以智能车载芯片知名的地平线,全名里为啥是“机器人技术”。
因为一旦沿着AI落地展开思考和推演,最后能作为独立品类、物种展现AI核心变革力的,有且只有机器人,或者说就是自主机器人。
它可以是家里扫地的那种,可以是提供自动驾驶出行的那种,也可以是仿照人类形体而生的那种——从感知到控制都有自主权,会是边缘的而非云端的,会是去中心化的而非中心化的。
而既然自主机器人是AI最终的归属,那更本质的要打造的产品,就是驱动这个自主机器人的大脑,就是处理器,或者更本质地说是计算架构。
这个本质问题的搞清楚,也能理解整个芯片半导体、信息计算产业的兴衰规律。
按照经济学的观点说,需求决定了供应,经济基础决定了上层建筑。
这也是为什么一个时代会有一个时代的芯片,因为一个时代会有一个时代的计算架构。
既然神经网络已经开启了“机器像人一样思考和计算”的变革,那固化执行人类思考和计算过程的架构,注定让出中心地位,通用计算芯片也会逐渐失去主导权。
One more thing
这种无情的历史变迁,也让另一个知名类比更具现实骨感。
在AI浪潮汹涌的热潮中,CPU一而再被质疑,一而再被挑战,后来英特尔的高管给出了极具中国色彩的比喻——
“CPU是所有XPU平台的中央神经系统,这就有点像中国人的主食米饭,别的XPU都是菜,不同地方的人喜欢不同的菜,但他们都需要和大米来搭配。”
这个类比,彼时彼刻,不得不承认既形象又巧妙。
只是比喻后来也跟此时此刻一样精准:追求低碳水的新时代里,谁也没想到,米饭竟然不再必要了。
审核编辑 :李倩
-
cpu
+关注
关注
68文章
10870浏览量
211871 -
神经网络
+关注
关注
42文章
4772浏览量
100799 -
人工智能
+关注
关注
1791文章
47314浏览量
238599
原文标题:一个时代有一个时代的计算架构
文章出处:【微信号:WW_CGQJS,微信公众号:传感器技术】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
为什么说雷达功能是UWB的一个“宝藏”

【「大模型时代的基础架构」阅读体验】+ 第一、二章学习感受
【「大模型时代的基础架构」阅读体验】+ 未知领域的感受
大模型时代的算力需求
名单公布!【书籍评测活动NO.41】大模型时代的基础架构:大模型算力中心建设指南
一个socket对应一个连接吗
宁德时代调整组织架构,曾毓群亲自掌舵制造与采购
AI时代的芯片革命:GPU、FPGA与TPU竞相涌现
华为云函数工作流:引领未来无服务器计算时代

芯盾时代深度参编的行业标准《总体架构》即将施行

从一个锚点到一座港湾:华为加速“巨幕手机”时代到来






 工商网监
工商网监
评论