 大模型工业化的方法论,都藏在 GPU 里
大模型工业化的方法论,都藏在 GPU 里
本文转载自DataFunTalk
编辑推荐
大模型已经是人工智能的基础设施了,如何进一步普惠商用并盈利是当务之急。近日,NVIDIA 邀请百度、字节跳动火山翻译、腾讯微信等 6 位专家,围绕“AI 大模型技术路线和工业化落地实践”展开分享,以下为分享内容精华汇总。
数据智能时代,计算是刚需,也是痛点,最主要的特点就是一个字——大。
将“大”拆分成三个特点,则包括:
-
数据大批量
-
计算串行依赖
-
计算复杂性高
这囊括了数据和算法的复杂性,而数据、算法、算力是智能时代三要素,前两者的复杂性最后都要由算力来承载。
这使得业界对算力的需求在空间和时间上都极速膨胀,有如海啸之势。
GPU 却有办法将海啸在空间上细分成万千条涓涓细流,在时间上缩短流水的路径,在结构上精简路径分支,将大规模任务层层拆解成小规模任务,举重若轻般承载了海量算力需求,成为智能时代的算力基础。
针对上述三个特点,GPU 基于吞吐量、显存等指标,分别采用并行、融合、简化三种方法,在算子层面进行加速。
GPU 加速的主要方法论,亦适用于大模型的工业化。
伴随底层芯片、算力、数据等基础设施的完善和进步,全球 AI 产业正逐步从运算智能走向感知智能、认知智能,并相应形成“芯片、算力设施、AI 框架&算法模型、应用场景”的产业分工、协作体系。2019 年以来,AI 大模型带来问题泛化求解能力大幅提升,“大模型+小模型”逐步成为产业主流技术路线,驱动全球 AI 产业发展全面加速。
从 NVIDIA、百度、字节跳动火山翻译、腾讯微信等几位专家的分享,我们也不难发现,他们在业界落地大模型的时候,很大程度上都采用了并行、融合与简化的方法,并且还从训练、推理层面延伸到了算法建模层面。
01
并行
并行方法是一种空间换时间的方法,它将海啸细分成涓涓细流。具体而言,对于数据大批量的计算,每个计算步骤的耗时都比较长。GPU 利用并行计算,也就是把没有计算依赖的数据尽可能并行,把大批量拆分成小批量,以减少每个计算步骤的 GPU 空闲等待时间,提高计算吞吐量。
为了实际完成大模型的训练,就需要高效率的软件框架,使得训练在单个 GPU、单个节点甚至在大规模集群上都有很好的计算效率。
因此,NVIDIA 开发出了 Megatron 训练框架。
Megatron 采用了模型并行、Sequence 并行等优化手段以高效地训练 Transformer 大模型,可训练万亿级别参数量的模型。
在算法建模层面,火山翻译和百度主要对 MoE 模型等建模方法进行了探索。
1. 模型并行
模型并行可分为 Pipeline 并行和 Tensor 并行。
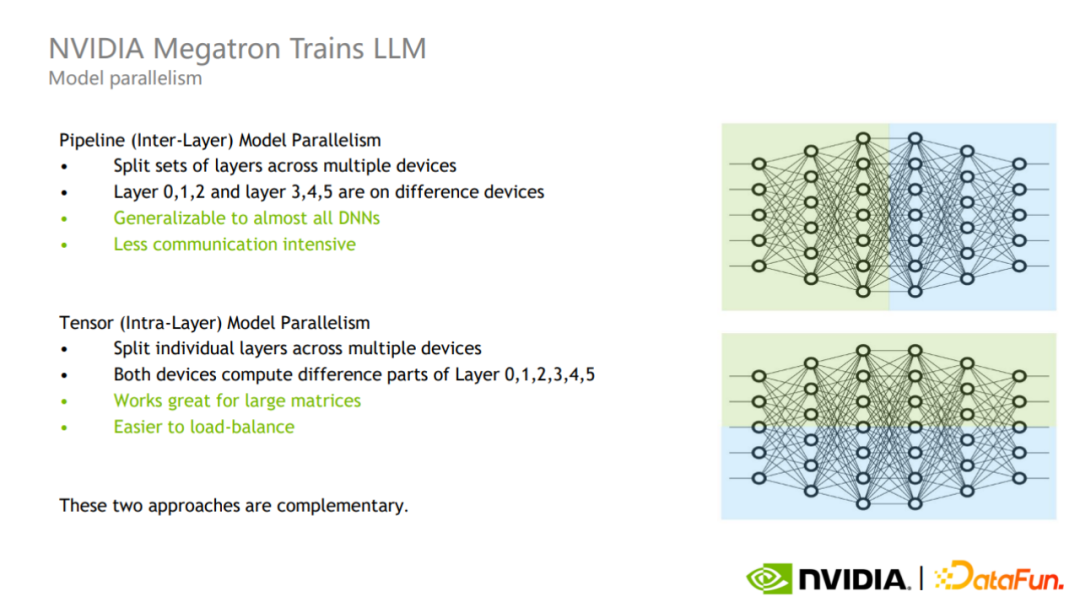
Pipeline 并行也就是层间并行(图中上半部分),将不同的层划分到不同的 GPU 进行计算。这种模式的通信只发生在层的边界,通信次数和通信数据量较少,但会引入额外的 GPU 空间等待时间。
Tensor 并行也就是层内并行(图中下半部分),将一个层的计算划分到不同的 GPU 上计算。这种模式的实现更加容易,对于大矩阵的效果更好,更好实现 GPU 之间的负载均衡,但通信次数和数据量都比较大。
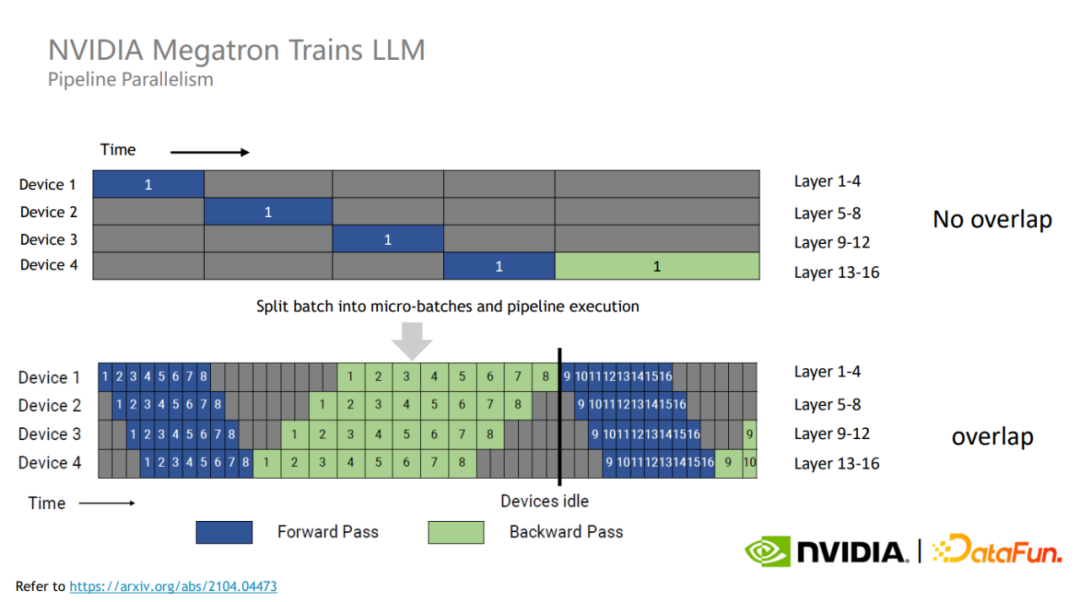
为了充分利用 GPU 资源,Megatron 将每个训练 batch 划分成了更小的 micro batch。
由于不同的 micro batch 之间没有数据依赖,因此可以互相覆盖等待时间,从而能够提高 GPU 的利用率,进而提高整体的训练性能。
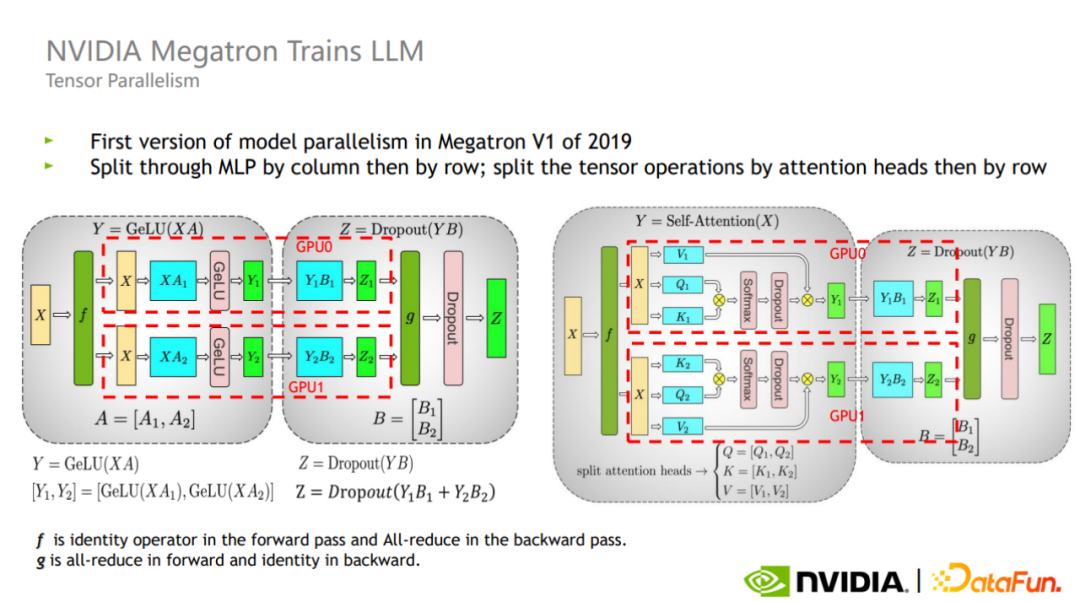
Tensor 并行把每个算子的计算划分到不同的 GPU 上,对于一个矩阵层,存在横切和纵切两种方式。
如图所示,Megatron 在 Transformer block 的 attention 和 MLP 部分都引入了这两种切分方式。
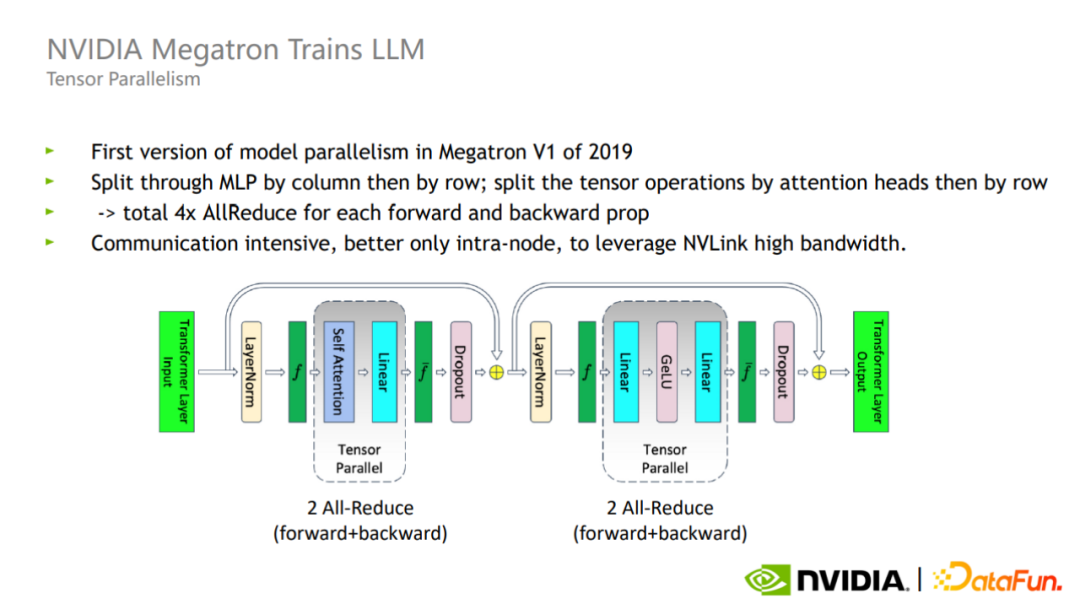
在 Tensor 并行模式下,每个 Transformer 层的前向反向加起来总共需要四次 All-reduce 通信,由于 All-reduce 的通信量较大,因此 Tensor 并行更适合单卡内部使用。
结合 Pipeline 并行和 Tensor 并行,Megatron 可以将在 32 个 GPU 上训练 1700 亿参数模型,扩展到在 3072 个 GPU 上训练 1 万亿参数规模的模型。
2. Sequence 并行
Tensor 并行其实并没有对 Layer-norm 以及 Dropout 做拆分,因此这两个算子在每个 GPU 之间是复制的。
然而,这些操作本身不需要大量计算,却非常占用激活显存。
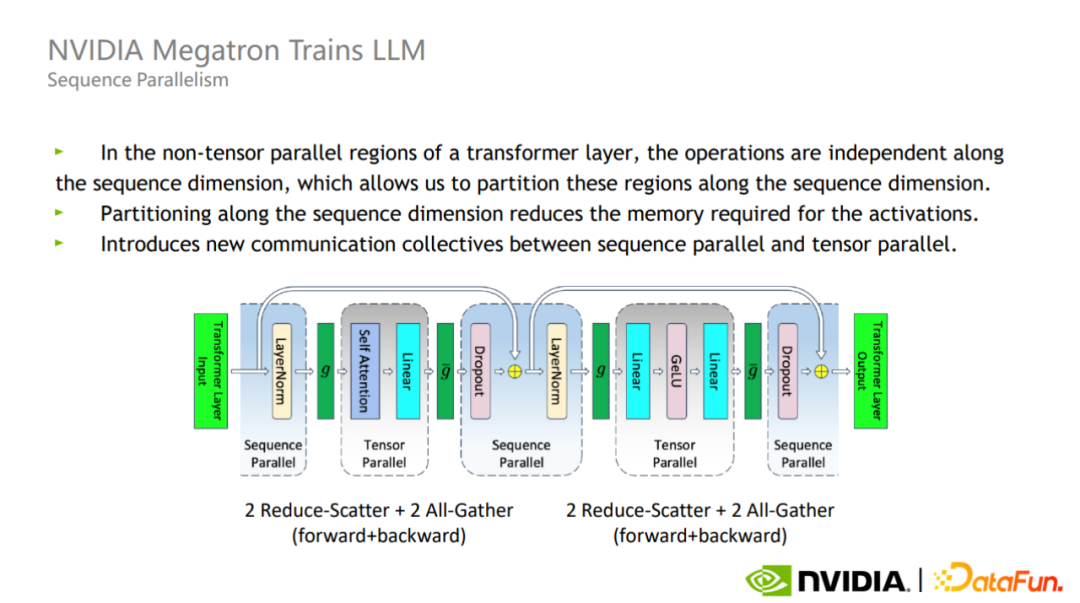
为此,Megatron 又提出了 Sequence 并行的优化方法。Sequence 并行的好处在于不会增加通信量,并且可以大大减少显存占用
由于 Layer-norm 和 Dropout 沿着序列的维度是独立的,因此可以按照 Sequence 维度进行拆分。
使用了 Sequence 并行之后,对于超大规模的模型而言,其实显存占用量还是很大的。因此,Megatron 又引入了激活重计算技术。
Megatron 的做法是,找到一些计算量很少但显存占用很大的算子,比如 Attention 里的 Softmax、Dropout 等算子,对这些算子进行激活重计算就可以显著减少显存,并且计算开销增加不大。
Sequence 并行和选择性激活重计算的结合可以将显存占用降低为原来的 1/5 左右。相对于原本直接将所有激活进行重计算的方案,其显存也只有其两倍,同时计算开销显著降低,并且随着模型规模增大,计算开销的占比也会逐渐降低。到万亿规模模型的时候,重计算的开销只占整体的 2% 左右。
3. 算法并行
MoE 模型因其设计思想简洁、可扩展性强等特点,使其在业界得到了越来越多的关注。
MoE 模型提出了这样的设计思想,也就是将大模型拆分成多个小模型。每个样本只需要激活部分专家模型进行计算,从而大大节省计算资源。
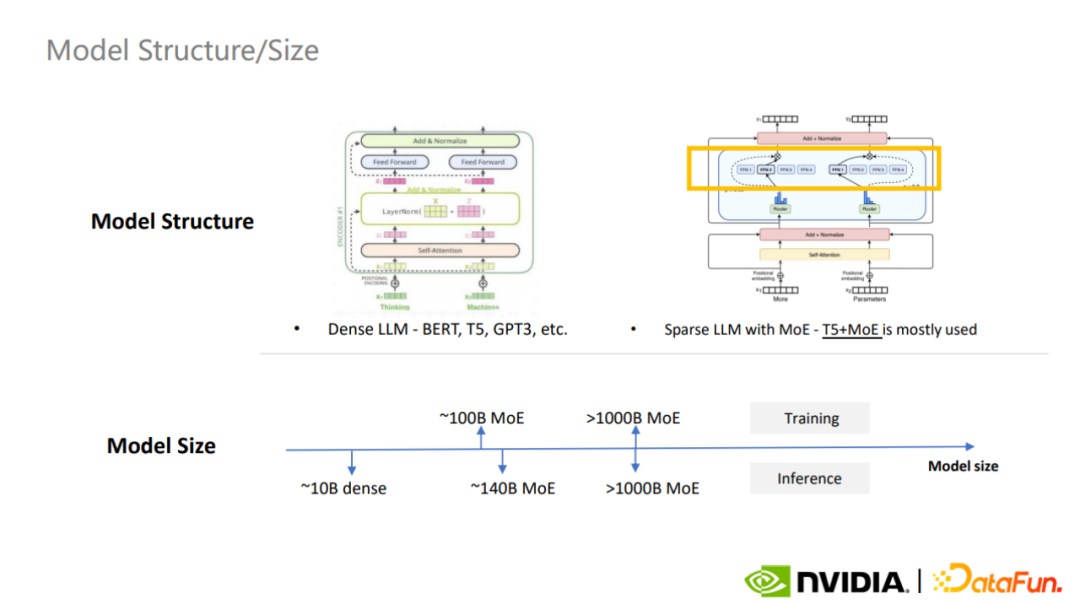
目前最常用的稠密大模型是 BERT、T5、GPT-3,最常用的稀疏 MoE 模型是 T5+MoE,MoE 正成为大模型构建的趋势。
可以说,MoE 在算法建模层面,结合了并行计算的思想。
大模型的通用性,体现在多个方面,除了我们已经熟知的几点,比如注意力机制归纳偏置更弱,模型容量大,模型数据大等等,还可以在任务建模方式上做优化,MoE 就是典型的代表。
对于火山翻译而言,MoE 的基本思路是通过宽度换取深度,因为模型深度越深,计算层数越多,进而推理时间越长。
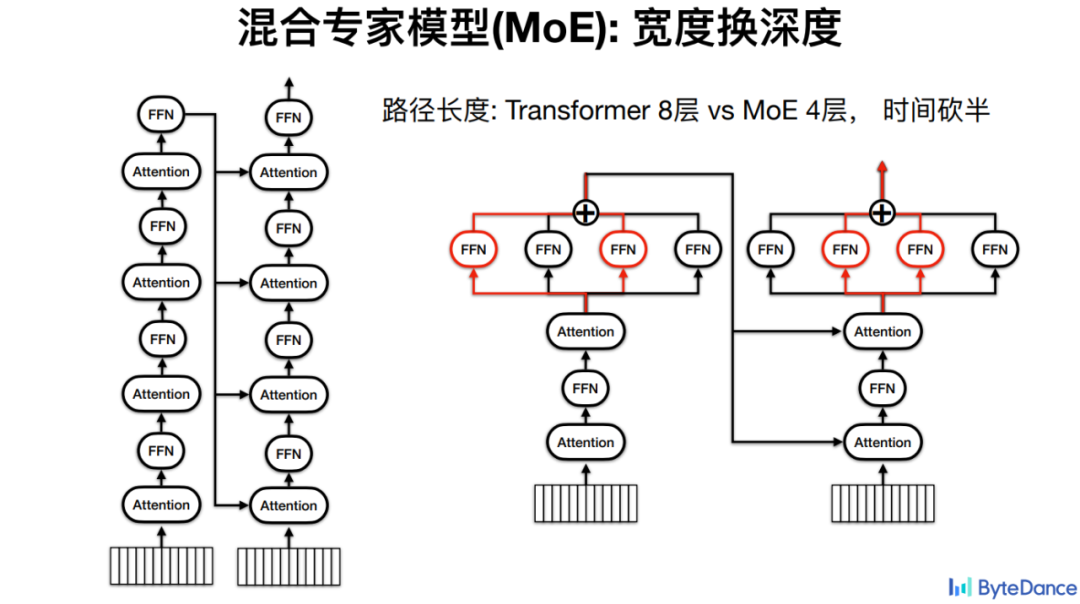
比如,对于拥有 4 层 Encoder、4 层 Decoder 的 Transformer 模型,每次计算必须经过所有 8 个 FFN 的计算。如果是混合专家模型,则可以把 FFN 平行放置,最终把计算路径减半,因而推理时间也减半。
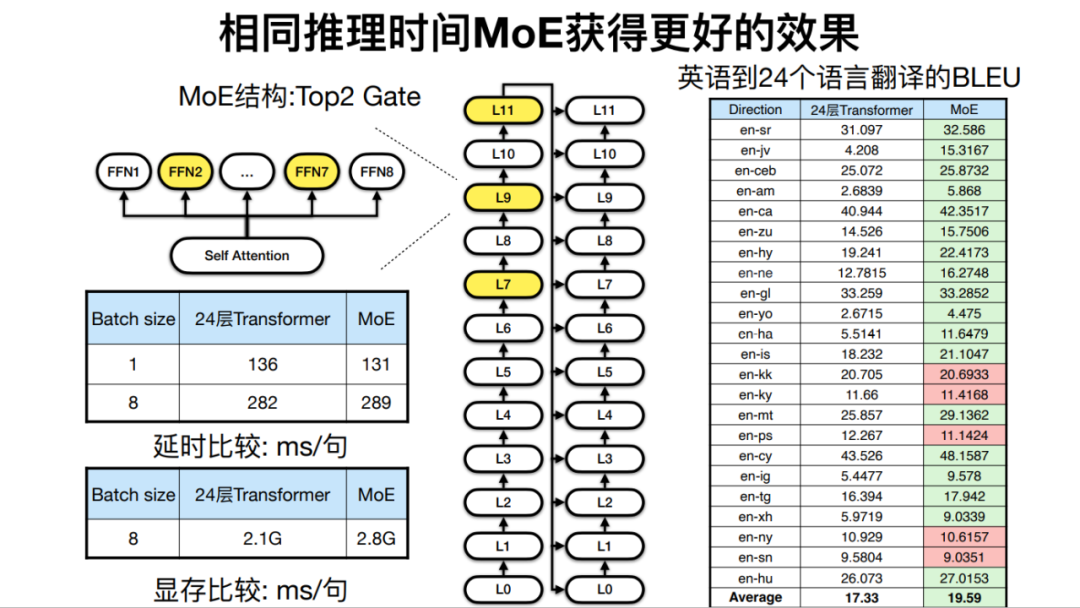
而在相同推理时间下,也就是模型深度相近的时候,由于 MoE 可以增加模型宽度,在机器翻译的最终效果上也有所提升。
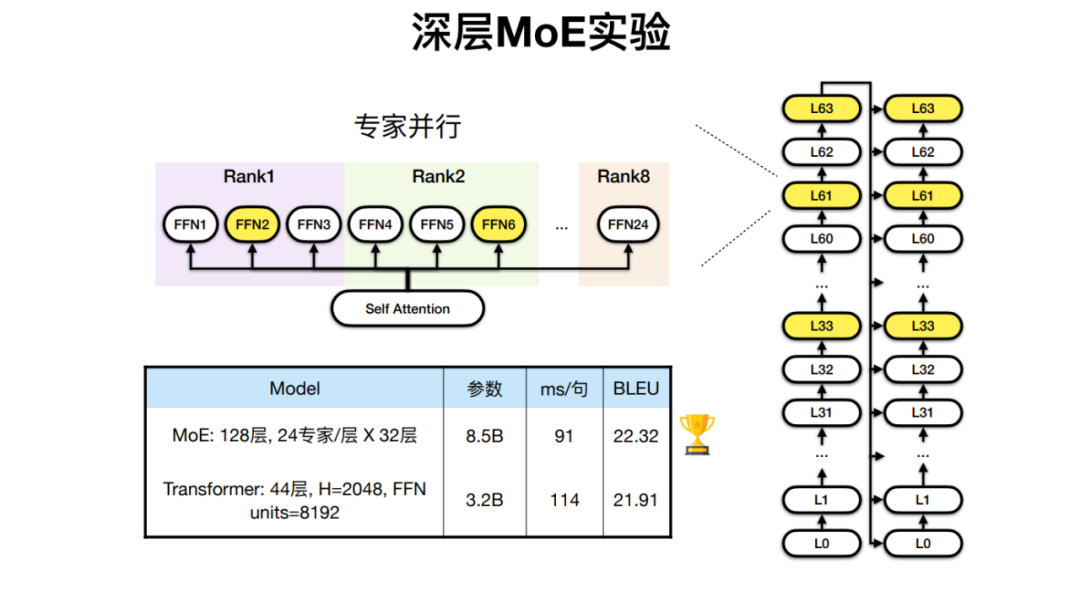
针对 24 种非洲语言和英、法语言的多语言翻译任务,火山翻译开发出了拥有 128 层 Transformer、24 个专家层的 MoE 模型,相比传统架构实现了更好的翻译效果。
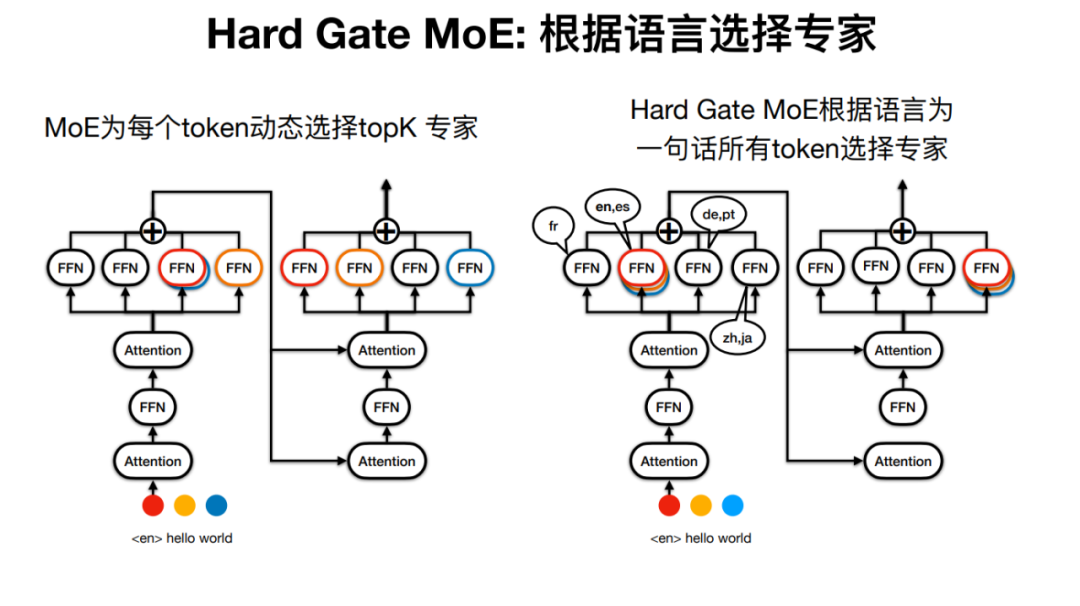
但 Sparse MoE 中的“专家模型”可能有些名不副实,因为对于一句话,比如其每个 Token 经过的专家都有可能是不同的。
火山翻译因此开发了 Hard Gate MoE,使得句子经过的专家由语种确定,这使得模型结构更加简单,实验结果也表明其翻译效果更好。
在算法建模的并行化探索中,百度也在知识增强跨模态生成大模型 ERNIE-ViLG 2.0 中采用了混合专家扩散模型框架。
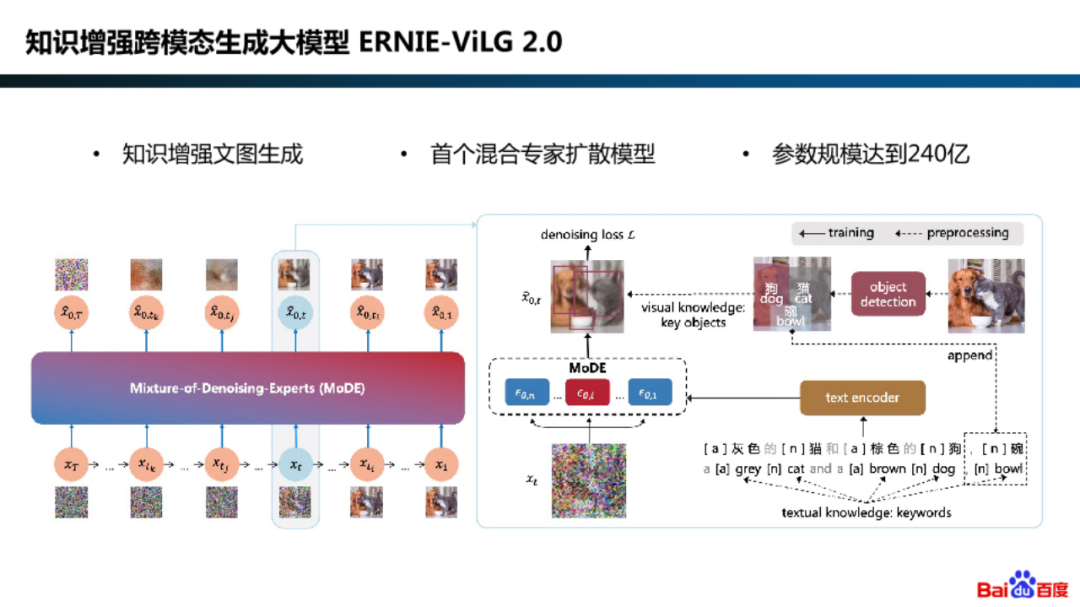
为何要对扩散模型采用专家模型?
其实是因为在不同的生成阶段,模型建模要求的不同。比如在初始阶段,模型着重学习从高斯噪声中生成有语义的图像,在最后阶段,模型着重从含噪图像中恢复图像细节。
实际上,在 ERNIE 3.0 的早期版本中就融合了自编码和自回归,其可在通用的语义表示上,针对具体的生成任务和理解任务,结合两种建模方式。
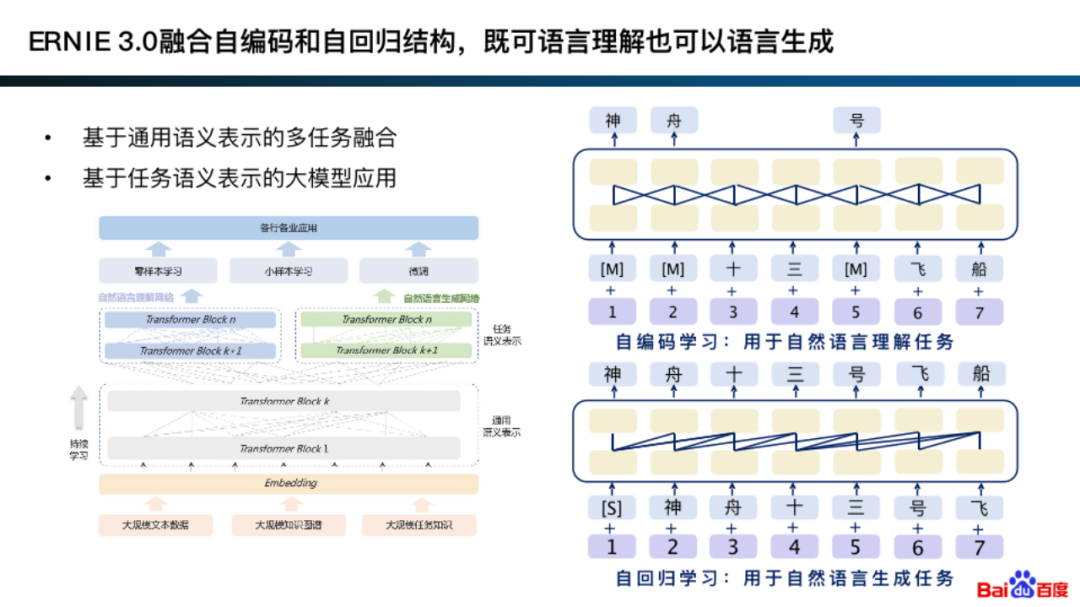
融合自编码和自回归的基本思想其实与专家模型的建模方法论类似。
具体来说,是在通用表示的基础上,根据理解任务适合自编码网络结构,生成任务适合自回归网络结构,来进行建模。此外,这种建模方式通常还能学习到更好的通用表示。
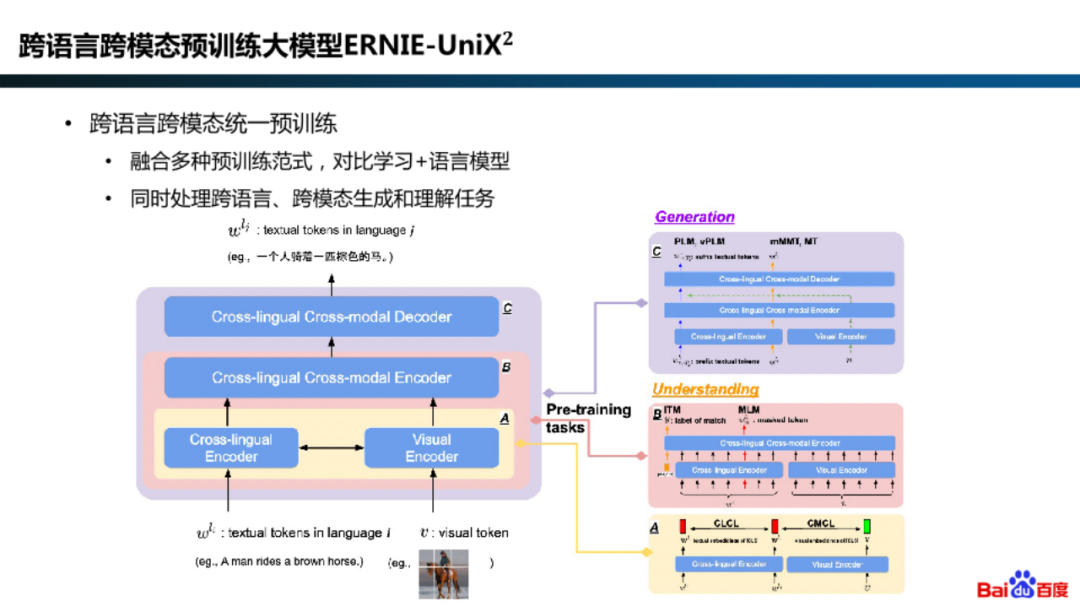
此外,在 ERNIE-UniX2 模型中,百度通过将对比学习、语言模型等预训练范式进行融合,将多语言、多模态的理解和生成任务进行了统一。
训练完 MoE 模型后,推理部署也是非常重视效率的环节。
在进行超大规模模型推理部署方案选择的时候,首先会根据模型的参数规模、模型结构、GPU 显存和推理框架,以及对模型精度和推理性能的权衡来决定是使用单卡推理还是多卡推理。如果显存不足,则会考虑模型压缩或多卡推理的方案。
多卡推理包括 Tensor 并行、Pipeline 并行、Expert 并行等模式。
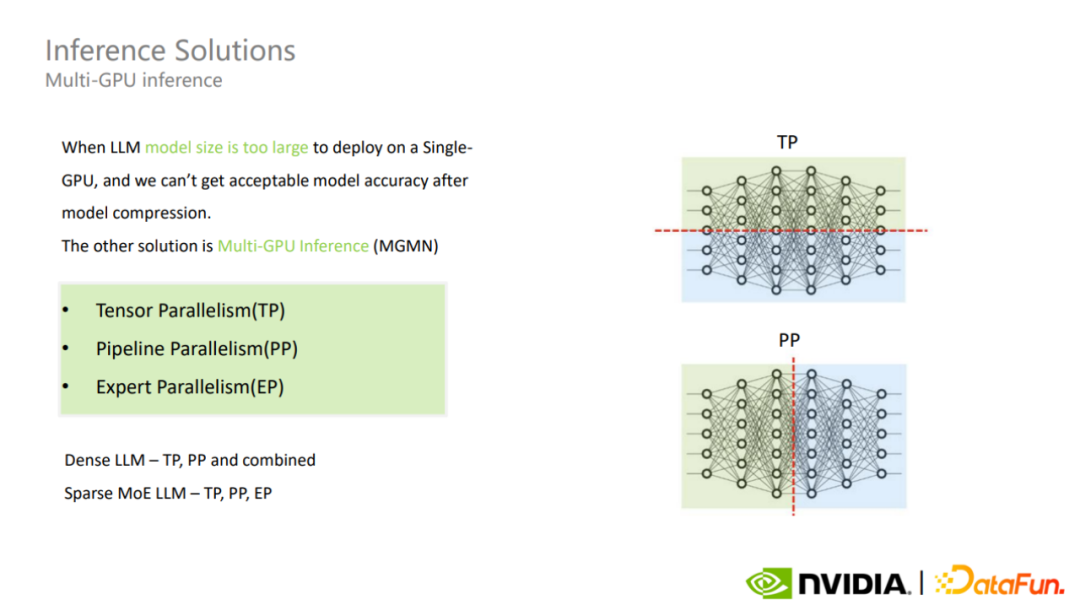
对 MoE 超大模型采用不同模式会遇到不同的挑战。其中,MoE 模型的 Tensor 并行和稠密模型类似。
如果选择 Expert 并行模式,每个 MoE Layer 的 Expert 就会被划分到不同的 GPU 上,这可能带来负载均衡问题,从而导致大量的 GPU 是空闲的,最终使得整体吞吐量不高。这是 MoE 多卡推理中需要关注的重点。
对于 Tensor 并行和 Pipeline 并行,除了通过微调减少卡间通讯以外,更直接的方法是提升卡间带宽。而当对 MoE 模型使用 Expert 并行导致负载均衡问题的时候,可以通过 Profiling 分析优化。
多卡推理方案增加了通信开销,对模型推理延时有一定影响。
02
融合
融合是解决并行计算中遇到的天然矛盾的方法,并行计算和串行计算是两种基本的计算模式。而在应用并行计算的时候,最典型的困难就是大量的串行依赖,以及因此产生的中间值显存占用问题,而 GPU 显存通常会成为大模型训练和推理的硬件性能瓶颈之一。
对于海量计算串行依赖问题,最主要的方法是将细流的路径缩短,也就是减少中间停留过程。具体来说,就是利用算子融合,把次序存在先后依赖关系的算子进行合并,以减少显存占用。
算子融合不仅在计算层面,也可以在算子设计层面实现。
1. 1F1B
Pipeline 并行中如果将前向和反向过程分开,就会出现显存占用过多问题。
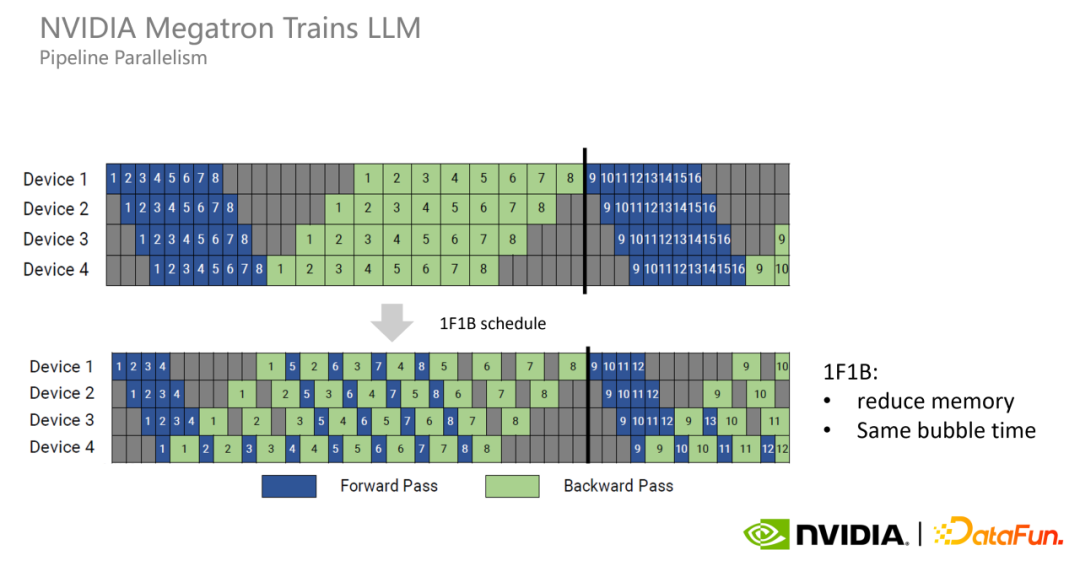
因此,Megatron 又提出了 Pipeline 并行的新模式 1F1B,每个 GPU 以交替的方式执行每个 micro batch 的正向和反向过程,以尽早释放其占用的显存,进而减少显存占用。
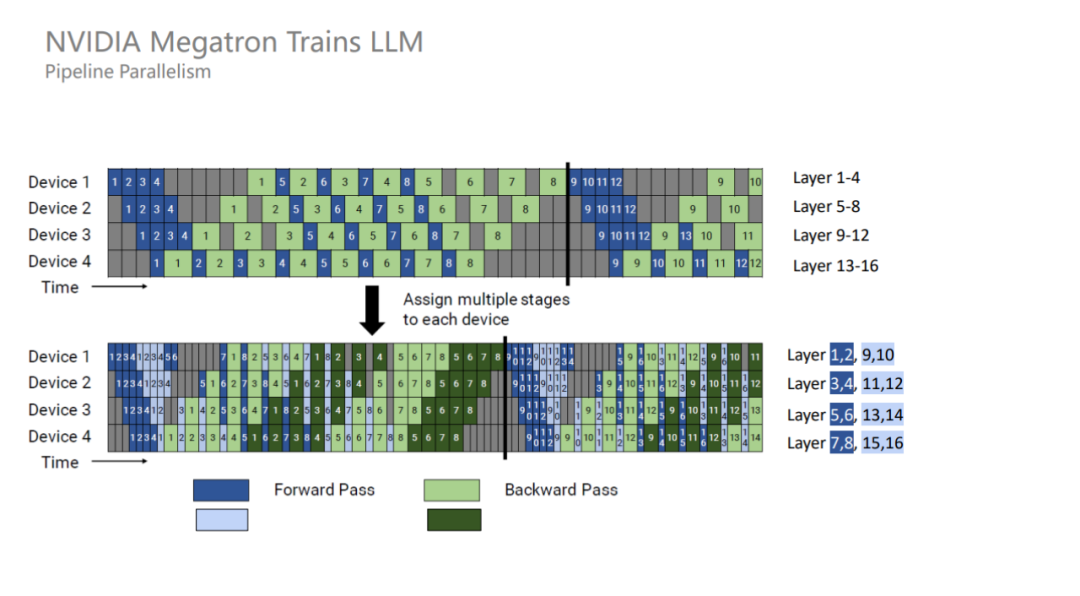
1F1B 并不能减少 bubble time,为了进一步减少 bubble time,Megatron 又提出了 interleaved 1F1B 模式。也就是原本每个 GPU 负责连续 4 个层的计算,现在变成负责连续两个层的计算,只有原来的一半,从而 bubble time 也变成了原来的一半。
2. Kernel 融合
当在做 GPU 计算的时候,每个计算流程都可以封装成一个 GPU 的 Kernel,放到 GPU 上执行,并且是顺序性的。传统的算子库为了通用性,会把算子设计的非常基本,因此数量也非常多,带来的弊端是显存占用多,因为需要存储大量的中间隐藏表示,另外这对带宽的要求也比较高,最终可能造成延迟或者性能损失。
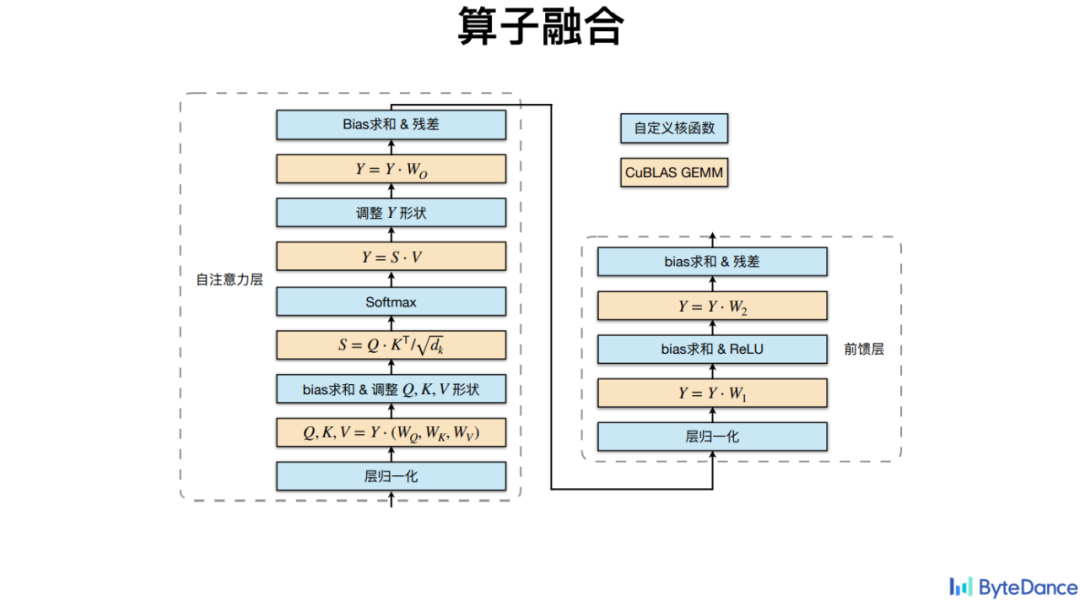
火山翻译基于 CuBLAS 乘法接口将其他非矩阵乘法算子进行了融合,包括了 Softmax、LayerNorm 等。
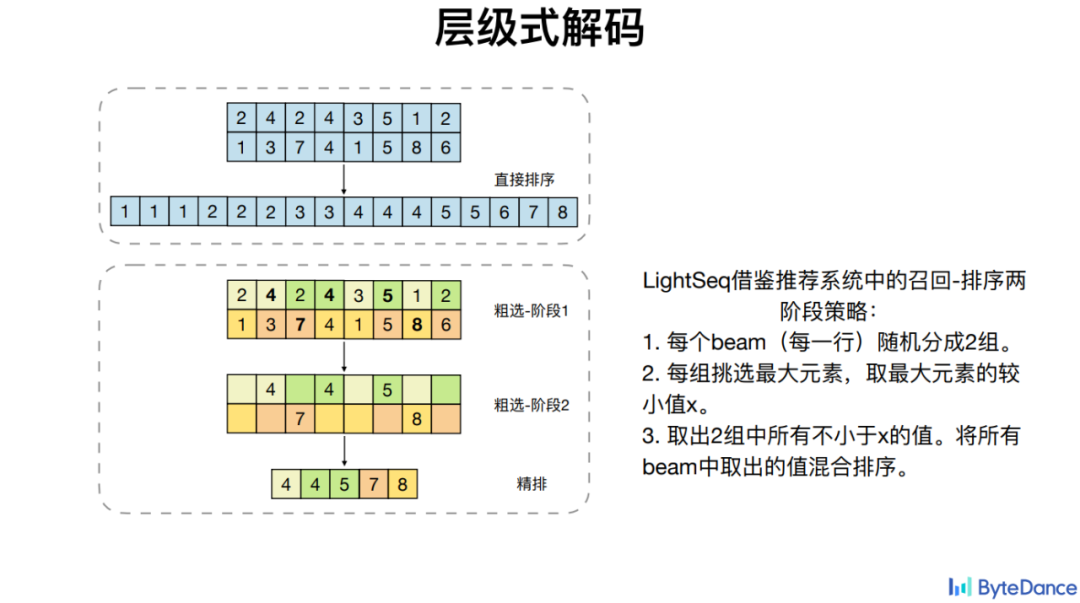
除了比较通用算子的融合,火山翻译还针对一些特定算子比如 Beam Search 无法很好利用 GPU 并行性的特点,优化其计算依赖问题,从而实现加速。
在四种主流 Transformer 模型上,LightSeq 算子融合在 PyTorch 的基础上取得了最高 8 倍的加速。
03
简化
简化是一种比较简单直观的加速方式,在细微处将流水分支精简。具体而言,就是对于计算高复杂性,在保证性能的前提下将算子复杂度简化,最终减少计算量。
超大规模模型的单卡推理一般会涉及模型压缩。
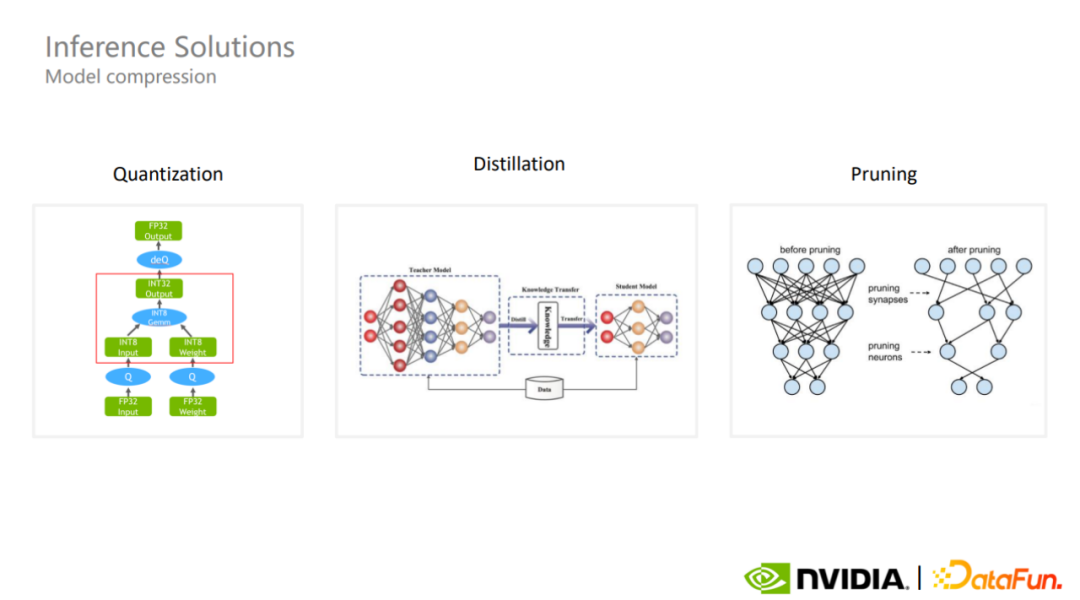
常见的模型压缩方案是量化、蒸馏和剪枝。量化是业内最常用的模型压缩方案之一。虽然量化的计算采用了更低的精度,但可以保持模型的参数量级,在某些情况下或许能更好地保证模型整体的精度。
1. 量化
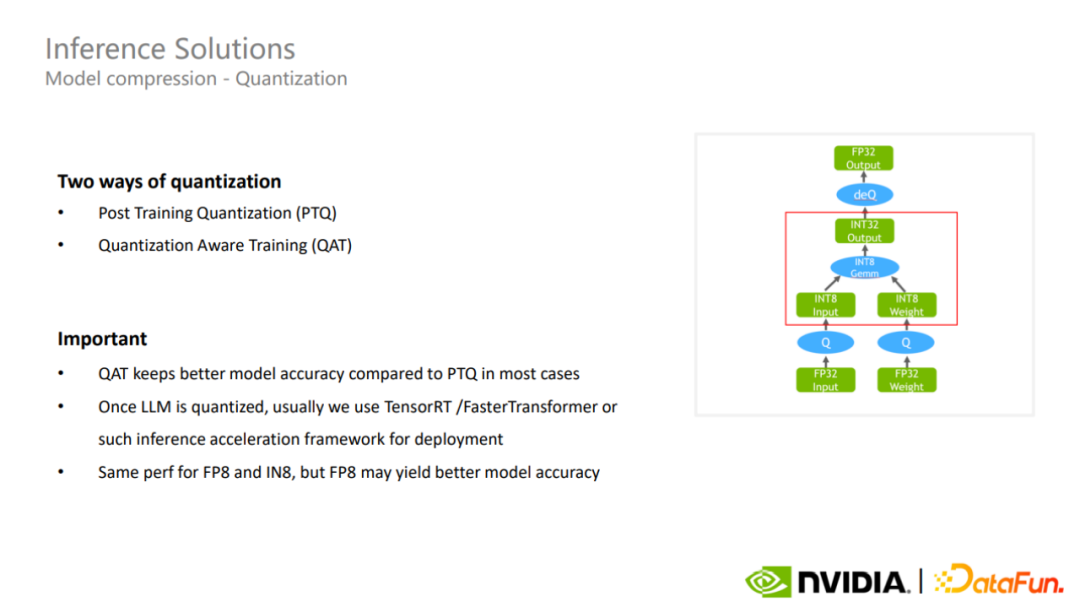
目前有两种量化方法,一种是训练后量化,一种是量化感知训练。后者通常比前者对模型的精度保持更好。
完成量化后,可以通过 TensorRT 或 FasterTransformer 等推理加速框架,进一步加速超大模型的推理。
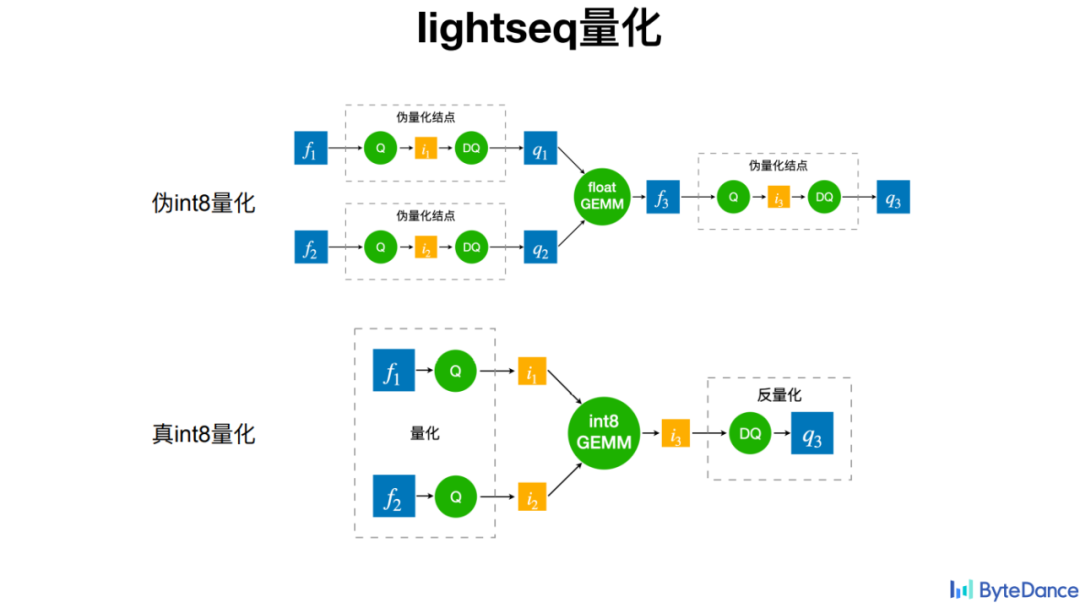
LightSeq 在训练过程的量化中采用了真 int8 量化,也就是在矩阵乘法之前,会执行量化操作,并且在矩阵乘法之后才执行反量化操作。而不像过去的伪量化那样,在矩阵乘法之前就执行了量化和反量化操作,以让模型适应量化所带来的损失和波动。后者在实际计算中并不能带来加速,反而可能增大延时,或者使得显存占用上升。而真 int8 量化在实际应用中也带来了很好的加速效果。
2. 蒸馏
第二种模型压缩方式是蒸馏。蒸馏可以针对不同应用场景采用不同的策略对超大模型进行压缩,在某些情况下,蒸馏可以让超大模型拥有更好的泛化能力。
3. 剪枝

最后一种模型压缩方案是剪枝。剪枝可分为全模型剪枝和部分层剪枝,对于超大模型,了解模型关键层非常重要,需要避开这些对精度影响最大的部分的剪枝,这对于稀疏 MoE 模型也是适用的。
4. 大模型工业化
大模型的研究和落地已成趋势,预计在 2022 年,关于大规模语言模型和 Transformers 的论文超过 1 万篇,比五年前 Transformers 刚提出的时候增长了 7 倍。另外,大模型也有非常广泛的应用,比如图片生成、推荐系统、机器翻译,甚至是生命科学、代码生成等。
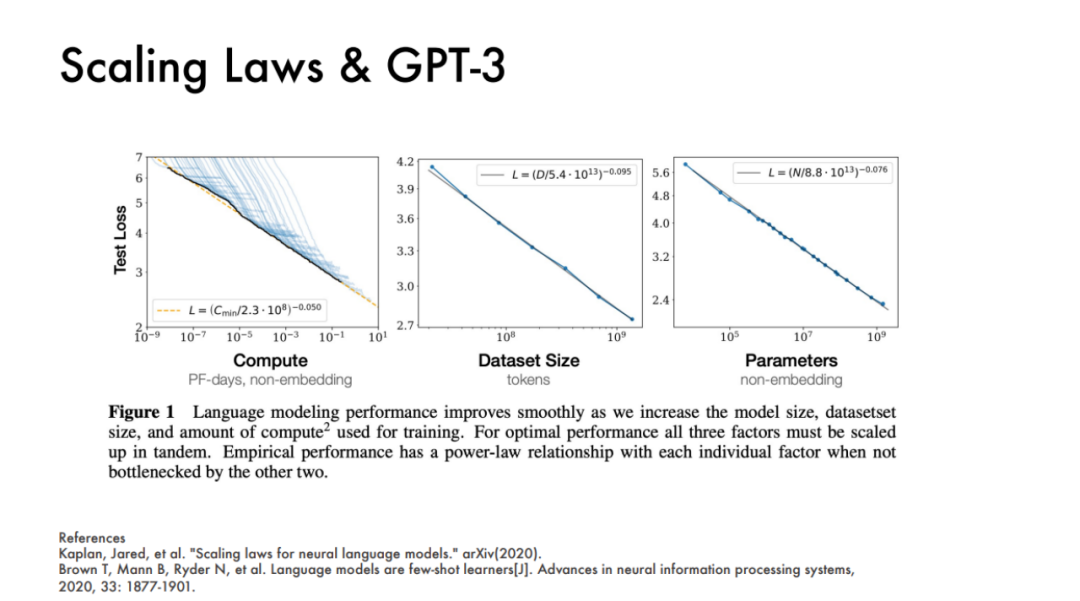
OpenAI 也曾经在 2020 年发表过两篇论文,就展示过一个模型的表现基本上和三个主要的因素挂钩,即算力、数据集大小、模型参数量,以这三个指标就能很好地预测模型的效果。

Richard Sutton 曾经说过,在过去 70 年的 AI 发展中,一个反复出现的趋势是一个通用的能够高效利用计算资源的方法,总会是最后的赢家。
根据 Richard Sutton 的“赢家定律”,深度学习在过去近十年是赢在了通用性。
但如今,大模型训练的挑战已不言而喻。以 GPT-3 为例,其在训练的时候如果使用原始的混合精度,需要保存训练时的参数和梯度以及 FP 32 的主参数,如果使用 Adam 优化器,还要保存两个优化器的动量信息,则最终总共需要 2.8 个 TB 的显存,这远远超出了单卡的显存容量,需要超过 35 张 A100 才能承载。
NVIDIA 2021 年的论文“Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM”中得出一个经验公式,表明单次迭代参数量为 1750 亿的 GPT-3 模型就需要 4.5 亿 FLOPs 的算力。如果整个训练周期包含 95000 次迭代的话,就需要 430 ZettaFLOPs。换句话说,需要一块 A100 训练 16000 天,这还是不考虑计算效率的结论。
也就是说,光靠堆积这三个指标在大模型工业化时代将极大浪费资源。
DeepMind 在 2022 年发表的 ChinChilla 的论文中曾表示,实际上 GPT-3、OPT、PaLM 等大模型,基本都属于欠拟合模型。如果基于同样的计算资源,调小模型参数量,并训练更多步骤,最终的模型效果才能更好一些。这也是微信在 WeLM 大规模语言模型中遵循的设计思想。
业界各企业基本都在开始将注意力从规模上放松,转而关注大模型落地时的效率问题。
比如,从整体执行效率来看,经过 Megatron 优化的几乎所有模型都有 30% 的吞吐量提升,并且随着模型大小的增加,可以实现更高的 GPU 利用率。在 1750 亿参数的 GPT-3 模型上,GPU 利用率可以达到 52.8%。而在 5300 亿参数规模以上的模型上,利用率可以达到 57%。
也就是说,根据 Richard Sutton 的“赢家定律”,效率,将成为大模型工业化的主基调。
原文标题:大模型工业化的方法论,都藏在 GPU 里
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
22文章
3780浏览量
91193 -
大模型
+关注
关注
2文章
2476浏览量
2794
原文标题:大模型工业化的方法论,都藏在 GPU 里
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
开源鸿蒙助力工业数字化、赋能新型工业化
新型工业化物联网平台是什么
材料失效分析方法汇总

PyTorch GPU 加速训练模型方法
武汉数字孪生工业互联网可视化技术,赋能新型工业化智能制造工厂


爱立信吴日平:高性能可编程网络赋能新型工业化
工业大模型赋能新型工业化的路径探索
新型工业化塑造更强竞争力
“AI+工业互联网”赋能新型工业化的路径分析
工业智能网关助力推进新型工业化

元宇宙赋能新型工业化,推动工业制造业数字化转型发展
工信部:加快推进新型工业化 推动人工智能创新应用
热点分享|新型工业化成为中国经济发展领域的高频热词





 工商网监
工商网监
评论