 面向智能移动平台的语义定位与建图
面向智能移动平台的语义定位与建图
一、背景
1、智能移动平台的定义平台包含两大特征,第一个是能够自主地对它周围的环境进行感知,基于感知信息自主运行,实现特定的任务,常见的移动平台是移动机器人和无人车。 为了实现或构建机器人或无人车,通常在算法方面有四大技术难点,即感知、状态估计、预测和执行控制。我的博士论文关注前面两点:感知和状态估计,总结为让无人车或机器人看见这个世界。
2、如何使用激光雷达传感器对周围环境感知通常来说基于机载或车载的传感器,图 1 是实验室自己的感知采集平台,平台上搭载了不同传感器,包括激光雷达、相机和 GPS。对于成熟的产品,需要融合各种传感器的不同模态信息,最后构建一个非常鲁棒和安全的感知系统。

图 1 感知采集平台 我的博士课题仅仅使用激光雷达传感器的数据作为算法输入,动机是测试使用单一传感器的感知性能。如果把所有的基于单一传感器的感知算法优化到最好,结合在一起就可以得到更加鲁棒、更加安全的感知系统。 64线激光雷达的数据如图 2 所示,旋转式的激光雷达实际是对环境进行深度扫描。在数据中,每一行实际是每一束激光旋转 360 度过程中采集的环境深度信息,每一列实际就是多线激光雷达在某一时刻采集的深度信息。

图 2 64 线激光雷达数据 在给定激光雷达激光束的标定参数以后,比如它的发射角和分辨率,也可以对每个距离采集信息的 3D 坐标进行解算,最后得到一个 3D 点云。我的博士论文就是使用这样的传感器的数据作为所有算法的输入。
3、为什么语义信息于激光雷达感知非常重要语义信息实际上是人类对环境的更高级别的理解。图 3 是原始点云信息和带有语义的点云信息对比,人类可以对环境有所理解,经过长时间的学习训练,对于机器人来说就是 3D 坐标,对于几何信息很难对周围环境进行理解,语义信息标注以后,无人车和机器人就能够更好的对环境进行理解,识别可通行区域的道路。我的博士论文就是想要利用语义信息使机器人的感知性能提升,实现机器人的感知。
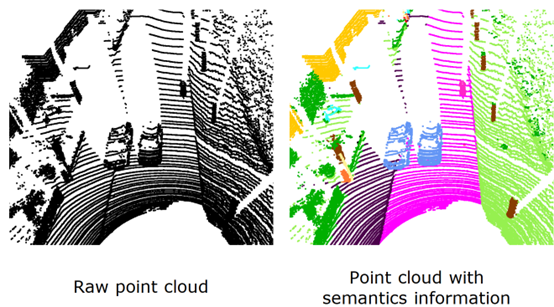
图 3 原始点云和语义信息点云对比
4、论文简介为了实现语义感知性能,论文主要是从三个方面进行: (1)如何利用现有的多类别的语义分割结果去提升机器人的感知和状态估计的性能,比如说提升定位和建图的性能; (2)对于不同的任务,不同的语义类别实际上是有不同的影响。针对不同的任务,可以提出更加刻意的语义信息来进一步提高算法的性能; (3)对语义信息进行简化后提出自动生成的语义算法,减轻对于人工标注的依赖。
二、使用多类别语义信息提高定位和建图性能基于语义信息的同时定位和建图(SLAM),SLAM 对于机器人自主导航非常重要,主要实现的是机器人在自主运行中,对环境地图进行构建,然后同时在所构建的地图环境中找到机器人当前位置。这是所有上游任务或下游任务的基础,要实现导航和规划,首先要知道环境长什么样子,知道当前环境中的位置,才能够实现下游任务,所以 SLAM 是机器人导航的基础。在第一个例子里面,想要在 SLAM 的过程中加入这样的多类别的语义信息,从而对 SLAM 的精度进行一个提升,如图 4 所示。
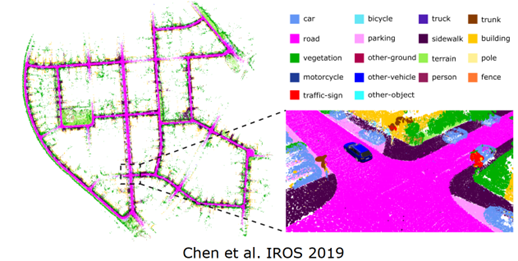
图 4 SLAM 过程增加多类别语义信息
1、为什么需要语义信息提升 SLAM 精度?当前的车辆的无人车行驶环境,在一个非常拥堵的高速路入口,图 5 左边展示的是传统的基于几何信息的 SLAM 结果,红色车辆代表的是位姿估计的真值,蓝色车辆代表传统的基于几何信息 SLAM 的估计出来的位姿值。可以看到在这样的一个具有挑战的场景中,传统的基于几何信息的 SLAM 没有办法很好的对当前车辆的位姿进行估计的,甚至给出了一个完全相反的运动方向,这样的算法在真实产品应用中会带来非常大的一个麻烦。

图 5 基于几何信息的 SLAM 但当拥有语义信息后,提出了语义 SLAM,如图 6 所示。可以更好的对车辆的位姿进行估计,最后可以看到估计出来的位姿的值和真值非常接近,同时也可以对环境的语义信息进行描述。

图 6 语义 SLAM 结果
2、具体如何实现语义 SLAM 的呢?图7是语义 SLAM 的实现框图,总共包含五个部分,在第一个部分展示的是 Raw Scan 算法,仅仅使用激光雷达点云作为输入,然后在第二个部分使用现有的语义分割结果,输出是每一个点对应的语义标签,这里采用的是提出的 RangeNet++方法,然后在第三个部分把语义信息和激光雷达的几何信息结合作为定位建图的输入,在建图部分使用动态物体去除算法,图 8 的左图展示不做任何处理时把语义观测叠加,可以看到由于当前场景中有动态的物体,会造成鬼影污染,污染会使地图没办法用于下一步的定位和导航,提出的算法就是把当的观测和历史累积的语义地图进行语义标签一致性的检测,如果当前观测里面的语义标签和地图中的语义标签不一样时,就把这样的语义标签当做运动的物体,对它进行去除,最后可以看到使用去除算法可以得到一个非常干净的语义地图。
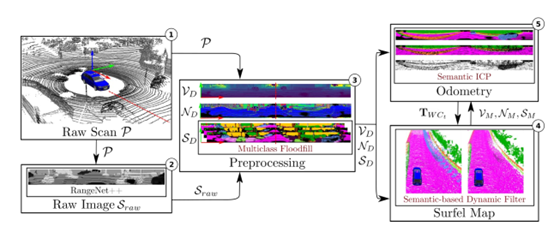
图 7 语义 SLAM 实现框图

图 8 语义动态去除 基于语义地图,进一步提出了基于语义信息的位姿估计算法,叫做 Semantic ICP。ICP 就是把当前观测和语义地图对齐,从而估计当前车辆或传感器的位姿,实现了累积定位。如图 9 所示,可以看到当前观测里面有动态物体,中间这幅图展示的是清理之后的语义地图,第三幅图展示的是在位姿估计过程中的每一个匹配,当前观测和地图的匹配之前的权值,颜色越深代表权值越低,可以清楚看到动态物体的权值,降低了它的权值,通过操作可以降低动态物体在位姿估计过程中对位姿估计带来的负面结果,从而提升位姿估计精度。

图 9 语义 ICP 图 10 展示的是算法在线运行的结果,可以看到语义 SLAM 可以实时的对环境的云地图进行构建,同时也可以准确的估计自身车的位姿,对动态物体进行去除,然后保留静态的语义地图。
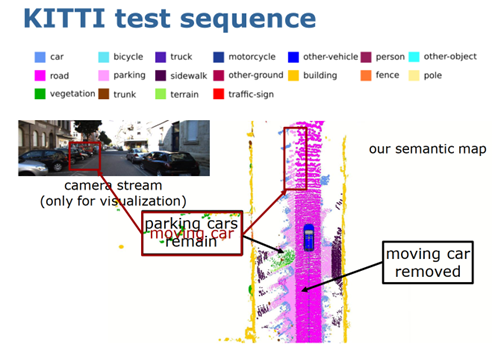
图 10 算法在线运行的结果 图 11 是第一个示例,在第一个示例中利用多类别的语义信息对 SLAM 的定位和建图性能提升。SLAM 实质上包含三个部分,定位、建图和闭环检测,闭环检测主要是机器人回到之前已经历过地方的时候,能不能判断出这个地方是已经历过的,如果能判断的话,可以加入闭环约束,通过约束消除长期运行的累积误差,从而构建出全局一致的地图和更加精确的位姿估计,所以闭环对于 SLAM 是非常重要的。传统的基于几何信息的闭环检测算法在一些挑战环境中无法正常工作,比如,当一个车从反方向开回到之前经历过的十字路口时,由于视角变换太大,所以无法识别十字路口是之前经历过的。
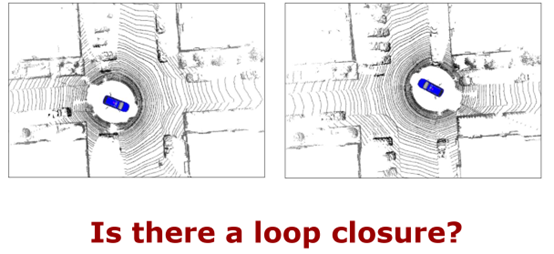
图 11 第一个示例 针对这个问题,在第二个示例中提出了利用深度学习和语义信息帮助机器人 SLAM 更好的找到闭环,提高全局地图构建精度和位姿估计的精度。 第二个例子的算法流程图如图 12 所示,左边所展示的就是算法把两帧激光雷达当做输入,然后除了使用激光雷达传统的几何信息,比如深度、法向量信息以外,也使用了语义信息,通过语义信息对地图点的描述性更强,所以可以更好找到闭环。右边是算法网络的流程图,是比较经典的编码器和解码器结构,首先编码器对两帧激光雷达进行提取,生成一个比较的特征,在第一个解码器中对两个激光雷达的加速度进行估计,可以更好的判断当前的观测是不是已经经历过的地方,如果已经找到了一个闭环,当车辆从反方向驶入时,当偏航角过大的时候,还是无法很好地闭环,所以针对这个任务设计了一个偏航角估计的解码器,解码器可以估计出两个激光雷达的相对偏航角,在找到闭环之后用偏航角估计可以更好的初始化位姿估计,从而更好的实现闭环。
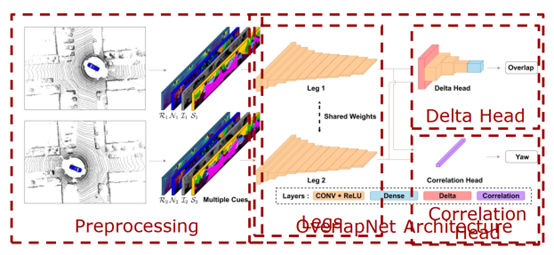
图 12 第二个例子的算法流程图 图 13 展示的是算法在线运行的结果,可以看到在经过长时间的运行之后,右边展示的是位姿估计的累积误差,颜色越红代表误差越大。红色点表示算法找到的闭环,在闭环后可以对累积误差进行消除。当机器人反方向驶入的时候,也能够找到闭环。
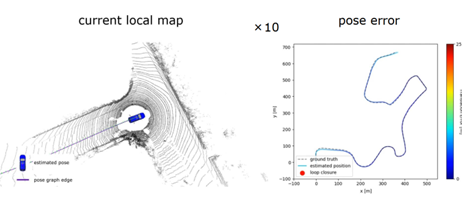
图 13 算法在线运行结果 图 14 展示的是在加入的闭环检测算法和没有加入闭环检测算法的定位和建图精度的比较,可以看到方法 SLAM 可以得到一个更加精确的定位和建图结果,相对于没有使用闭环检测的算法。
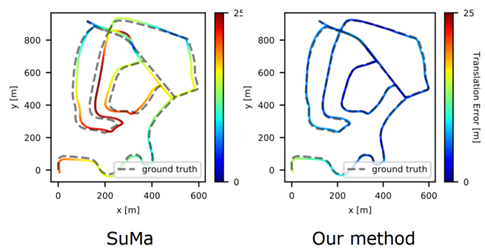
图 14 加入闭环检测和没有加入闭环检测算法 SLAM 对比 小结:第一部分实际上回答了要如何使用现有的语义信息多类别的从语义分割网络里得到的点云信息来对感知任务进行系统的提升,在第一个部分中以 SLAM 的闭环做了一个示例,在论文中也尝试了对全局定位算法进行深度学习的尝试,但是由于时间关系,在我的答辩过程中,每部分只提供了一个或两个示例。 在第一个问题中主要回答的是利用语义信息提高感知性能,在进行这个研究的过程中实际上也发现了对于定位和建图而言,更加在意的是当前的环境中这些物体是运动还是静止的,所以实质上对于特定的感知任务,每一个类别或者不同的语义信息带来的影响是不一样的。那么在第二个部分里面,就想要回答对于特定的感知任务是不是能够提出更加特意的语义信息从而进一步提高感知任务的精度。
三、对于特定的感知任务,提出更加特意的语义信息从而进一步提高感知任务的精度同样的以激光雷达 SLAM 为基础,提出了动态物体分割的算法,如图 15 所示。和现有的语义分割不一样的是,在动态物体分割中不是要区分一个物体的具体类别,而是要区分是运动物体还是静态物体,为了实现动态物体分割,提出了一个新的基于深度学习的利用序列信息的算法。
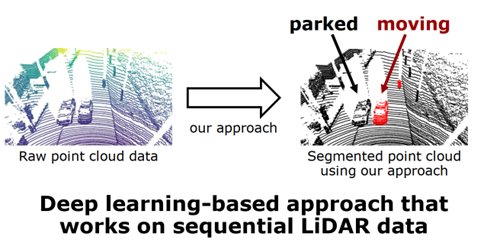
图 15 基于深度学习方法的序列雷达数据 动态物体分割的流程图如图 16 所示,可以看到使用的这个网络结构也是传统的编码器解码器结构。和传统的语义分割不一样的是,输出不是多类别语义分割,而是更加特意的二值分割动和不动的结果。这样的好处是把一个复杂的多类别的语义分割任务简化为二值的分类任务,可以更容易的得到这样一个结果,之后再对定位和建图进行提升。然后和多类别语义分割还有一个不同的就是,不使用单一的当前观测作为输入,而使用一系列的连续时空的观测作为网络的输入。为了更好的使用这样的时空信息,提出了一个所谓的残差图像。接下来具体介绍怎么生成和使用残差图像的。
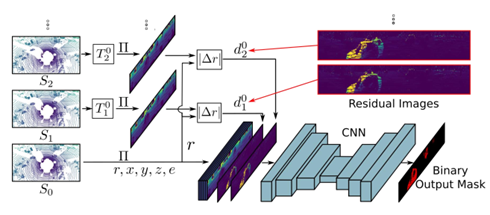
图 16 动态物体分割流程图 如图 17 所示,其中第一个图展示的是当前的观测,第二个图展示的是当前观测中动态物体的真值,下面的图像都是提出的残差图像,j=1 代表利用过去的第一帧和当前帧所比较得到的残差图像,以此类推。为了生成残差图像,首先把过去的观测投影到当前的坐标系,对于每一个过去观测中的点 rij→0投影到当前的坐标系,和对应的观测进行比较,从而生成残差图像。利用残差图像,这是一个非常直观的使用已有的人类先验知识引导网络如何识别动态物体,可以清楚看到在哪个位置有动态物体。利用这样连续多帧的去检测也是一个非常自然而言的想法,比如作为人类来说看一张图片没有很好的判断,如果看视频的话能够看到物体运动的性质。将连续多帧的物体作为输入可以更好的识别动态物体。
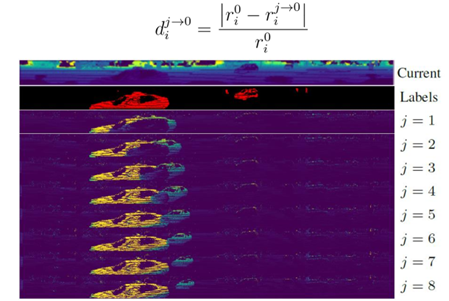
图 17 残差图像 图 18 展示的是算法在线运行的结果,可以看到算法可以很好的对正在运动的车辆和行人进行识别,也可以识别到静态背景,可以在不同环境中使用。
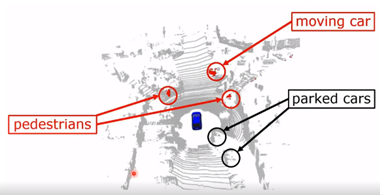
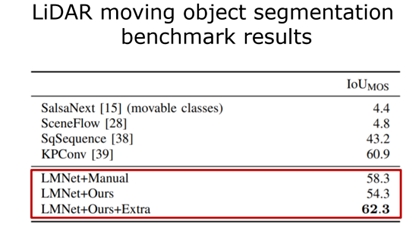
图 18 算法在线运行的结果 接下来是更多的数值的一个比较,如表 1 所示。那么对三个不同算法的定位结果进行对比,第一个只是用几何信息,第二个使用多类别的语义信息来对 SLAM 性能进行增强的结果,第三个算法是使用刚才提出的动态物体分割的结果。每个方法有两个数字,前面是旋转误差,后面是平移误差,可以看出更好的结果,比使用多类别语义信息更好的结果。
表 1 不同算法的定位结果对比
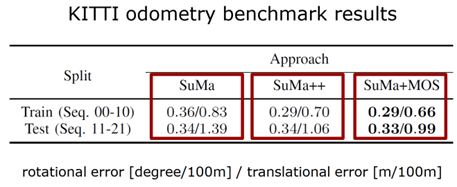
图 19 展示的是在使用动态物体分割以后建图的结果,上面是原始点云建图结果,存在鬼影,下面是动态物体分割后的更加干净的环境地图,可以更好的用于下游的任务。
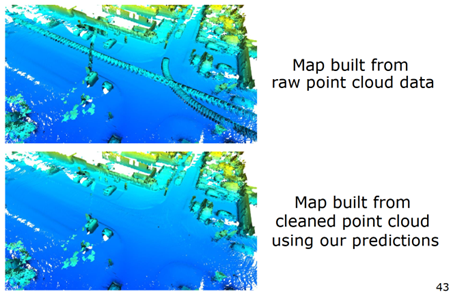
图 19 使用动态物体分割后建图的结果 小结:对于特定的激光雷达的感知任务,可以提出更加特意的语义信息。以 SLAM 为例,提出了动态物体分割,通过这种方式,对需要的语义信息进行简化,更加容易的得到语义信息,同时对相对应的任务进行性能提升。 简化语义信息后,非常大的好处就是可以找一些自动生成语义信息的方法,减轻对于人类手工标注的依赖。
四、特定语义任务自动生成标注自动生成物体标签的算法,如图 20 所示,拿一个序列的激光雷达点云作为算法输入,首先使用传统的方法进行位姿估计,通过一致性检测对大概的动态物体区域进行标注,然后对标注的可能物体进行实例的分割,最后对可能运动物体进行跟踪,生成动静的标签,根据速度或距离来确定标签。这里注意的是方法无法进行在线测试,一步一步进行,离线的生成标签好处在于中间帧不仅可以使用当前和过去的信息,还可以使用未来的信息,使用时空信息对动态物体进行检测,生成标签,再对网络进行训练,自动训练得到网络,部署到在线任务中去。
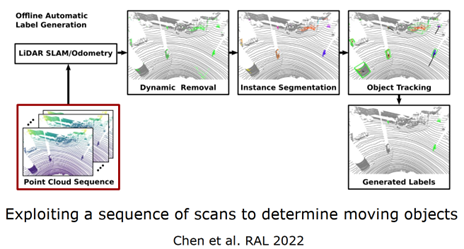
图 20 自动生成物体标签算法
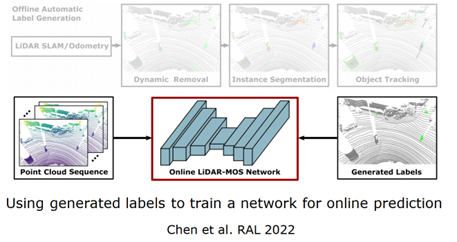
图 21 自动生成物体标签算法(续) 在不同的数据集上也可以进行,如图 22 所示,这是在美国和韩国采集的,算法都能够达到很好的性能。
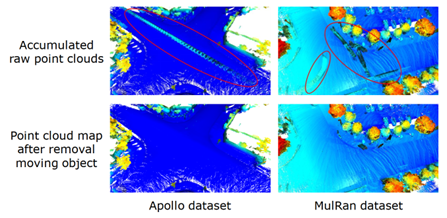
图 22 数据集 表 2 展示的是算法使用自动标签进行训练和使用真值训练得到标签的结果,IOU 越大效果越好。
表 2 自动标签和真值标签结果对比
使用同样的数据集,自动生成标签当然要比真实标签性能要差,但生成更多标签的时候能够提升网络的性能。 小结:简化所需的语义信息后,可以提出自动生成标签的方法去训练网络,减轻对人工标注的网络,从而使深度学习方法可以泛化到不同环境中。
五、总结最后,对整个博士论文进行一个总结,它实际上就是回答了三方面的内容,第一个方面就是如何使用现有的多类别语义信息提高激光雷达定位和建图的精度,然后针对于特定的任务,是不是可以提出更加特意的语义信息,从而对于语义信息进行简化,因为特意化以后能提升性能,第三个可以自动生成标签降低对手工标注的依赖。 博士期间的研究成果如图 23 所示。

图 23 博士期间成果 代码的公开如图 24 所示。

图 24 代码链接
问题 QA:1.semantic ICP 是只区别了动态物体还是静态物体之后的 ICP 吗? 除了动态物体的权值有所降低以外,比如栅栏或其他地方的权值也有所调整,没有特别针对静态物体或动态物体调整,不对动静进行区分,只是单纯的对每一个类别物体的语义一致性进行检测。 2.语义的视觉 SLAM 有哪些深挖的点?是否推荐多模态的语义 SLAM? 多模态当然是未来发展的热门方向,对于一个真正的产品落地肯定最后是多模态的结果,单一传感器总有不适用的场景,对于视觉来说黑夜和雨天影响很大,对于激光雷达来说雨雾也有很大的影响,所以大家也会尝试加入 IMU 和 GPS 以及毫米波雷达等等。对于视觉 SLAM 没有做特别多的工作,现在的了解的话,和这里的语义不太一样的定义。 3.激光语义 SLAM 和视觉语义 SLAM 的区别? 其实就是传感器的区别,视觉 SLAM 的信息更加丰富一点,因为有外观的 RGB 信息,可以更好的实现语义分割,在室外的话,单目没有深度信息,这是和激光雷达的区分。激光雷达没有颜色信息,很难区分物体。视觉的视角更宽一点。 4.研究语义 SLAM 的过程中需要注意那些内容? 按照思路顺下来,在答辩时能够更加了解如何你是一步一步进行研究的,大家可以参考顺序。如何获取更好的无监督的语义信息是现在比较难的一个点,还有一个是深度学习的瓶颈,它非常依赖于对语义信息的定义。得到的类别只是训练的类别,无法得到开放世界的类别。如何对不知道的类别进行检测,这是一个非常的难点。 5.语义 SLAM 的工程化有什么建议? 在自动驾驶公司用的比较多,和定义的语义不太一样,在高精地图中语义的信息使用非常重要。对于语义的定义是多种多样的,在实际工程的应用中,比如车道线的检测已经是非常好的了。工程化的难点是开放世界,对更多类别进行识别,算例是难点。如何轻量化网络,还有就是泛化系统的问题,都是城市场景的自动驾驶,在没有车道线的地方如何提取语义信息进行自动驾驶也是非常关注的。
审核编辑 :李倩
-
传感器
+关注
关注
2552文章
51363浏览量
755707 -
SLAM
+关注
关注
23文章
426浏览量
31893 -
激光雷达
+关注
关注
968文章
4020浏览量
190229
原文标题:面向智能移动平台的语义定位与建图
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
芯盾时代继续深化中建科技统一身份认证平台建设
【「具身智能机器人系统」阅读体验】2.具身智能机器人的基础模块

工业智能网关快速接入移动OneNET平台配置操作
一种半动态环境中的定位方法
思岚科技SLAMKit定位与建图解决方案介绍

【试用评选】为昕原理图设计EDA软件(Jupiter)试用活动评选结果公布
图像语义分割的实用性是什么
广和通发布基于骁龙460移动平台的智能模组SC208,加速移动终端智能化

广和通发布基于骁龙460移动平台的智能模组SC208,加速移动终端智能化

广和通发布基于骁龙460移动平台的智能模组SC208,加速移动终端智能化
广和通发布基于骁龙460移动平台的智能模组SC208
助力移动机器人下游任务!Mobile-Seed用于联合语义分割和边界检测






 工商网监
工商网监
评论