 阿里达摩院提出ABPN:高清人像美肤模型
阿里达摩院提出ABPN:高清人像美肤模型
一、论文&代码
论文:
https://openaccess.thecvf.com/content/CVPR2022/papers/Lei_ABPN_Adaptive_Blend_Pyramid_Network_for_Real-Time_Local_Retouching_of_CVPR_2022_paper.pdf
模型&代码:
https://www.modelscope.cn/models/damo/cv_unet_skin-retouching/summary
二、背景
随着数字文化产业的蓬勃发展,人工智能技术开始广泛应用于图像编辑和美化领域。其中,人像美肤无疑是应用最广、需求最大的技术之一。传统美颜算法利用基于滤波的图像编辑技术,实现了自动化的磨皮去瑕疵效果,在社交、直播等场景取得了广泛的应用。然而,在门槛较高的专业摄影行业,由于对图像分辨率以及质量标准的较高要求,人工修图师还是作为人像美肤修图的主要生产力,完成包括匀肤、去瑕疵、美白等一系列工作。通常,一位专业修图师对一张高清人像进行美肤操作的平均处理时间为1-2分钟,在精度要求更高的广告、影视等领域,该处理时间则更长。
相较于互娱场景的磨皮美颜,广告级、影楼级的精细化美肤给算法带来了更高的要求与挑战。一方面,瑕疵种类众多,包含痘痘、痘印、雀斑、肤色不均等,算法需要对不同瑕疵进行自适应地处理;另一方面,在去除瑕疵的过程中,需要尽可能的保留皮肤的纹理、质感,实现高精度的皮肤修饰;最后也是十分重要的一点,随着摄影设备的不断迭代,专业摄影领域目前常用的图像分辨率已经达到了4K甚至8K,这对算法的处理效率提出了极其严苛的要求。为此,我们以实现专业级的智能美肤为出发点,研发了一套高清图像的超精细局部修图算法ABPN,在超清图像中的美肤与服饰去皱任务中都实现了很好的效果与应用。
三、相关工作
3.1 传统美颜算法
传统美颜算法的核心就是让皮肤区域的像素变得更平滑,降低瑕疵的显著程度,从而使皮肤看起来更加光滑。一般来说,现有的美颜算法可划分为三步:1)图像滤波算法,2)图像融合,3)锐化。整体流程如下:
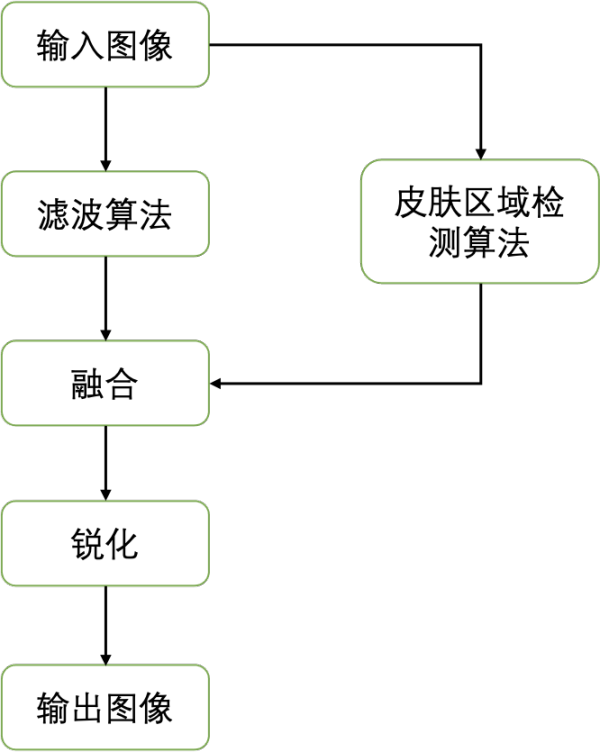
其中为了实现皮肤区域的平滑,同时保留图像中的边缘,传统美颜算法首先使用保边滤波器(如双边滤波、导向滤波等)来对图像进行处理。不同于常用的均值滤波、高斯滤波,保边滤波器考虑了不同区域像素值的变化,对像素变化较大的边缘部分以及变化较为平缓的中间区域像素采取不同的加权,从而实现对于图像边缘的保留。而后,为了不影响背景区域,分割检测算法通常被用于定位皮肤区域,引导原图与平滑后的图像进行融合。最后,锐化操作可以进一步提升边缘的显著性以及感官上的清晰度。下图展示了目前传统美颜算法的效果:

原图像来自unsplash[31]
从效果来看,传统美颜算法存在两大问题:1)对于瑕疵的处理是非自适应的,无法较好的处理不同类型的瑕疵。2)平滑处理造成了皮肤纹理、质感的丢失。这些问题在高清图像中尤为明显。
3.2 现有深度学习算法
为了实现皮肤不同区域、不同瑕疵的自适应修饰,基于数据驱动的深度学习算法似乎是更好的解决方案。考虑任务的相关性,我们对Image-to-Image Translation、Photo Retouching、Image Inpainting、High-resolution Image Editing这四类现有方法对于美肤任务的适用性进行了讨论和对比。
3.2.1 Image-to-Image Translation
图像翻译(Image-to-Image Translation)任务最开始由pix2pix[1]所定义,其将大量计算机视觉任务总结为像素到像素的预测任务,并且提出了一个基于条件生成对抗网络的通用框架来解决这类问题。基于pix2pix[1],各类方法被陆续提出以解决图像翻译问题,其中包括利用成对数据(paired images)的方法[2,3,4,5]以及利用非成对数据(unpaired images)的方法[6,7,8,9]。一些工作聚焦于某些特定的图像翻译任务(比如语义图像合成[2,3,5],风格迁移等[9,10,11,12]),取得了令人印象深刻效果。然而,上述大部分的图像翻译主要关注于图像到图像的整体变换,缺乏对于局部区域的注意力,这限制了其在美肤任务中的表现。
3.2.2 Photo Retouching
受益于深度卷积神经网络的发展,基于学习的方法[13,14,15,16]近年来在修图领域展现了出色的效果。然而,与大多数图像翻译方法相似的是,现有的retouching算法主要聚焦于操控图像的一些整体属性,比如色彩、光照、曝光等。很少关注局部区域的修饰,而美肤恰恰是一个局部修饰任务(Local Photo Retouching),需要在修饰目标区域的同时,保持背景区域不动。
3.2.3 Image Inpainting
图像补全(image inpainting)算法常用于对图像缺失的部分进行补全生成,与美肤任务有着较大的相似性。凭借着强大的特征学习能力,基于深度生成网络的方法[17,18,19,20]这些年在inpainting任务中取得了巨大的进步。然而,inpainting方法依赖于目标区域的mask作为输入,而在美肤以及其他局部修饰任务中,获取精确的目标区域mask本身就是一个非常具有挑战性的任务。因而,大部分的image inpainting任务无法直接用于美肤。近年来,一些blind image inpainting的方法[21,22,23]摆脱了对于mask的依赖,实现了目标区域的自动检测与补全。尽管如此,同大多数其他image inpainting方法一样,这些方法存在两个问题:a)缺乏对于目标区域纹理及语义信息的充分利用,b)计算量较大,难以应用于超高分辨率图像。
3.2.4 High-resolution Image Editing
为了实现高分辨率图像的编辑,[15,24,25,26]等方法通过将主要的计算量从高分辨率图转移到低分辨率图像中,以减轻空间和时间的负担。尽管在效率上取得了出色的表现,由于缺乏对于局部区域的关注,其中大部分方法都不适用于美肤这类局部修饰任务。
综上,现有的深度学习方法大都难以直接应用于美肤任务中,主要原因在于缺乏对局部区域的关注或者是计算量较大难以应用于高分辨率图像。
四、基于自适应混合金字塔的局部修图框架
美肤本质在于对图像的编辑,不同于大多数其他图像转换任务的是,这种编辑是局部的。与其相似的还有服饰去皱,商品修饰等任务。这类局部修图任务具有很强的共通性,我们总结其三点主要的困难与挑战:1)目标区域的精准定位。2)具有全局一致性以及细节保真度的局部生成(修饰)。3)超高分辨率图像处理。为此,我们提出了一个基于自适应混合金字塔的局部修图框架(ABPN: Adaptive Blend Pyramid Network for Real-Time Local Retouching of Ultra High-Resolution Photo, CVPR2022,[27]),以实现超高分辨率图像的精细化局部修图,下面我们对其实现细节进行介绍。
4.1 网络整体结构
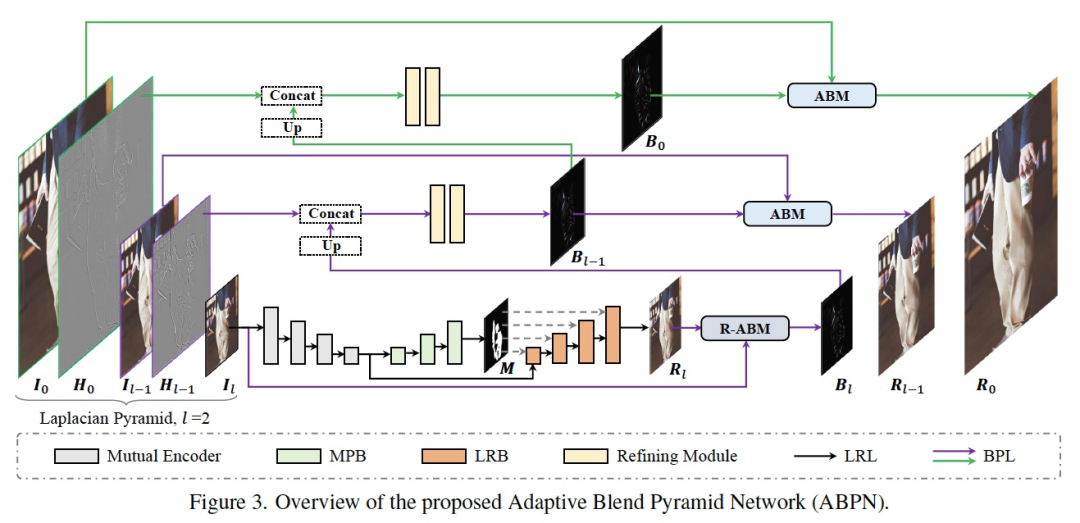
如上图所示,网络结构主要由两个部分组成:上下文感知的局部修饰层(LRL)和自适应混合金字塔层(BPL)。其中LRL的目的是对降采样后的低分辨率图像进行局部修饰,生成低分辨率的修饰结果图,充分考虑全局的上下文信息以及局部的纹理信息。进一步,BPL用于将LRL中生成的低分辨率结果逐步向上拓展到高分辨率结果。其中,我们设计了一个自适应混合模块(ABM)及其逆向模块(R-ABM),利用中间混合图层Bi,可实现原图与结果图之间的自适应转换以及向上拓展,展现了强大的可拓展性和细节保真能力。我们在脸部修饰及服饰修饰两个数据集中进行了大量实验,结果表明我们的方法在效果和效率上都大幅度地领先了现有方法。值得一提的是,我们的模型在单卡P100上实现了4K超高分辨率图像的实时推理。下面,我们对LRL、BPL及网络的训练loss分别进行介绍。
4.2 上下文感知的局部修饰层(Context-aware Local Retouching Layer)
在LRL中,我们想要解决三中提到的两个挑战:目标区域的精准定位以及具有全局一致性的局部生成。如Figure 3所示,LRL由一个共享编码器、掩码预测分支(MPB)以及局部修饰分支(LRB)构成。
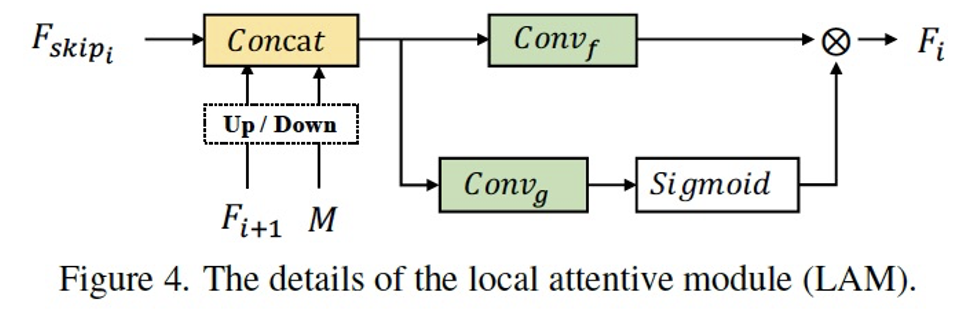

总得来说,我们使用了一个多任务的结构,以实现显式的目标区域预测,与局部修饰的引导。其中,共享编码器的结构可以利用两个分支的共同训练优化特征,提高修饰分支对于目标全局的语义信息和局部的感知。大多数的图像翻译方法使用传统的encoder-decoder结构直接实现局部的编辑,没有将目标定位与生成进行解耦,从而限制了生成的效果(网络的容量有限),相比之下多分支的结构更利于任务的解耦以及互利。在局部修饰分支LRB中我们设计了LAM(Figure 4),将空间注意力机制与特征注意力机制同时作用,以实现特征的充分融合以及目标区域的语义、纹理的捕捉。消融实验(Figure 6)展现了各个模块设计的有效性。
4.3 自适应混合金字塔层(Adaptive Blend Pyramid Layer)
LRL在低分辨率上实现了局部修饰,如何将修饰的结果拓展到高分辨率同时增强其细节保真度?这是我们在这部分想要解决的问题。
4.3.1 自适应混合模块(Adaptive Blend Module)
在图像编辑领域,混合图层(blend layer)常被用于与图像(base layer)以不同的模式混合以实现各种各样的图像编辑任务,比如对比度的增强,加深、减淡操作等。通常地,给定一张图片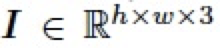 ,以及一个混合图层
,以及一个混合图层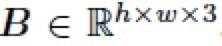 ,我们可以将两个图层进行混合得到图像编辑结果
,我们可以将两个图层进行混合得到图像编辑结果
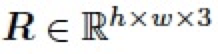
,如下:

其中 f 是一个固定的逐像素映射函数,通常由混合模式所决定。受限于转化能力,一个特定的混合模式及固定的函数 f 难以直接应用于种类多样的编辑任务中去。为了更好的适应数据的分布以及不同任务的转换模式,我们借鉴了图像编辑中常用的柔光模式,设计了一个自适应混合模块 (ABM),如下:
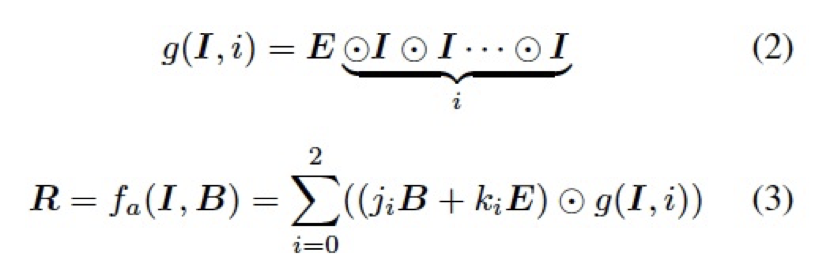
其中 表示 Hadmard product,
表示 Hadmard product,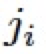 和
和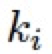 为可学习的参数,被网络中所有的 ABM 模块以及接下来的 R-ABM 模块所共享,
为可学习的参数,被网络中所有的 ABM 模块以及接下来的 R-ABM 模块所共享,
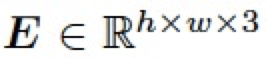
表示所有值为 1 的常数矩阵。 4.3.2 逆向自适应混合模块(Reverse Adaptive Blend Module) 实际上,ABM 模块是基于混合图层 B 已经获得的前提假设。然而,我们在 LRL 中只获得了低分辨率的结果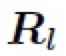 ,为了得到混合图层 B,我们对公式 3 进行求解,构建了一个逆向自适应混合模块 (R-ABM),如下:
,为了得到混合图层 B,我们对公式 3 进行求解,构建了一个逆向自适应混合模块 (R-ABM),如下:
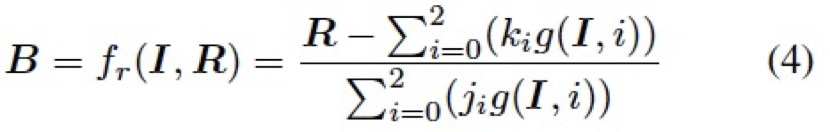
总的来说,通过利用混合图层作为中间媒介,ABM 模块和 R-ABM 模块实现了图像 I 和结果 R 之间的自适应转换,相比于直接对低分辨率结果利用卷积上采样等操作进行向上拓展(如 Pix2PixHD),我们利用混合图层来实现这个目标,有其两方面的优势:1)在局部修饰任务中,混合图层主要记录了两张图像之间的局部转换信息,这意味着其包含更少的无关信息,且更容易由一个轻量的网络进行优化。2)混合图层直接作用于原始图像来实现最后的修饰,可以充分利用图像本身的信息,进而实现高度的细节保真。
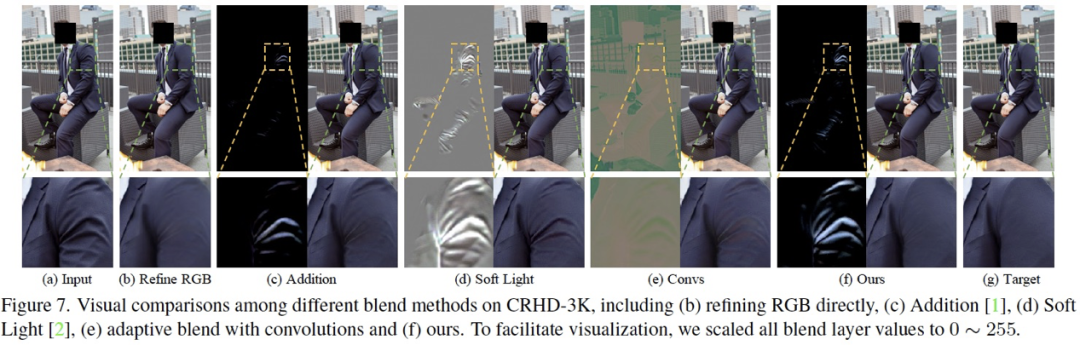
实际上,关于自适应混合模块有许多可供选择的函数或者策略,我们在论文中对设计的动机以及其他方案的对比进行了详细介绍,这里不进行更多的阐述了,Figure 7 展示了我们的方法和其他混合方法的消融对比。 4.3.3 Refining Module

4.4 损失函数

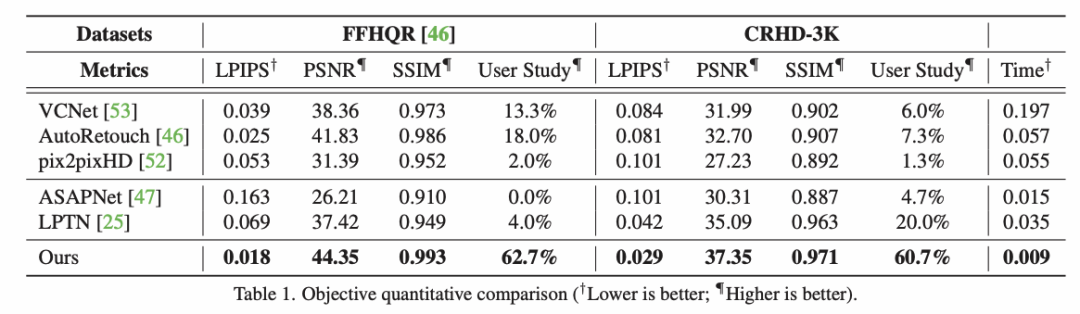
实验结果5.1 与 SOTA 方法对比
5.2 消融实验

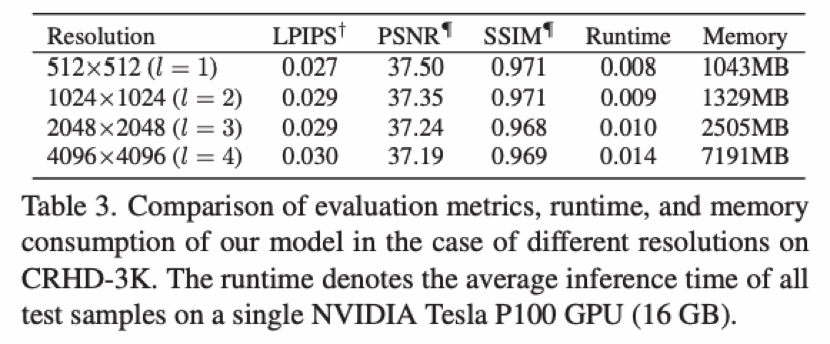
5.3 运行速度与内存消耗
效果展示 美肤效果展示:
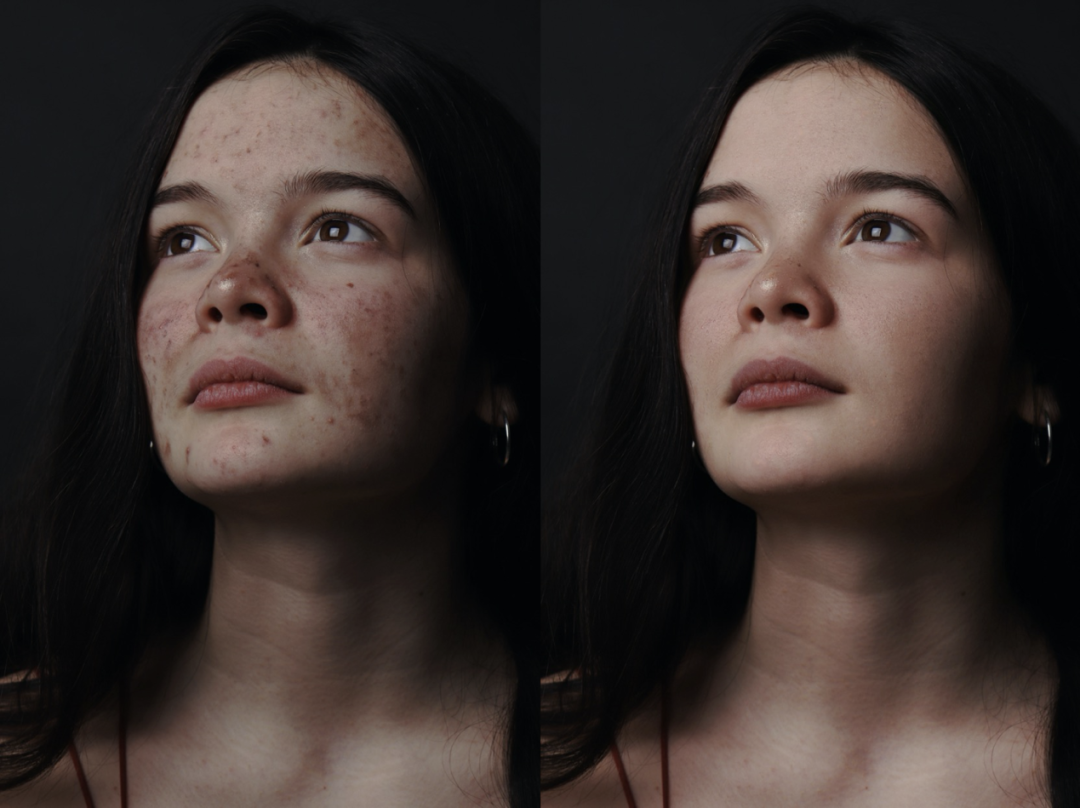
原图像来自 unsplash [31]

原图像来自人脸数据集 FFHQ [32]

原图像来自人脸数据集 FFHQ [32] 可以看到,相较于传统的美颜算法,我们提出的局部修图框架在去除皮肤瑕疵的同时,充分的保留了皮肤的纹理和质感,实现了精细、智能化的肤质优化。进一步,我们将该方法拓展到服饰去皱领域,也实现了不错的效果,如下:


审核编辑 :李倩
-
滤波器
+关注
关注
161文章
7751浏览量
177741 -
算法
+关注
关注
23文章
4601浏览量
92680 -
图像
+关注
关注
2文章
1083浏览量
40420
原文标题:CVPR 2022 | 阿里达摩院提出ABPN:高清人像美肤模型
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
亚马逊推新,阿里达摩院退出,融资规模大幅下滑后量子计算还是好生意吗?
阿里云开源推理大模型QwQ
阿里国际发布翻译大模型Marco
阿里达摩院发布玄铁R908 CPU
阿里云设备的物模型数据里面始终没有值是为什么?
阿里达摩院提出“知识链”框架,降低大模型幻觉
润开鸿荣膺达摩院“玄铁优选伙伴”奖
玄铁RISC-V生态大会深圳召开,达摩院引领RISC-V创新应用

达摩院院长张建锋:RISC-V迎来蝶变,进入应用爆发期
达摩院牵头成立“无剑联盟”,探索RISC-V产业合作新范式






 工商网监
工商网监
评论