 介绍一种基于超异构计算的通用处理器GP-HPU
介绍一种基于超异构计算的通用处理器GP-HPU
本文章主要介绍综合的、融合的基于超异构计算的通用处理器GP-HPU(General Purpose Hyper-heterogeneous Processing Unit)。
1 不同处理器类型的分类和协同
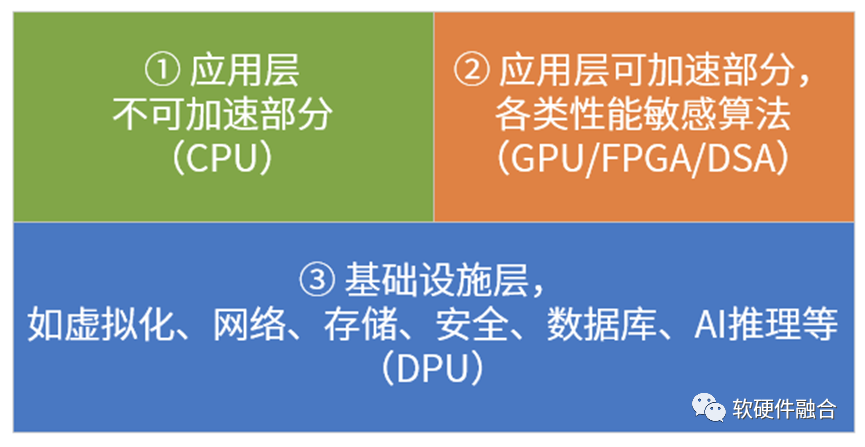
我目前有个基本的思考框架,来把各种PU进行划分:系统是由分层分块的模块组成的,这样我们可以大致上把系统分为三部分,如上图所示。
各类PU分析如下:
CPU,中央处理器,是最核心的处理器。目前其他各种处理器,号称取代CPU的核心地位,这些表述是不对的:你只是代替CPU干脏活累活,一切的控制和管理依然是CPU来完成。
各类加速器芯片。通过CPU+xPU的异构计算架构,如GPU、FPGA加速器、各类AI芯片(谷歌TPU、graphcore IPU、NPU、BPU等)以及其他各种加速芯片,这类芯片没法单独运行,需要有CPU的协作,构成CPU+xPU的异构计算的方式运行。
DPU。目前,大家对DPU的理解是,DPU主要负责系统I/O的处理。不管是网络I/O还是远程存储I/O,都需要走网络,因为DPU被不少人认为是I/O加速的处理器。更深一层的理解,是DPU是作为基础设施处理器的存在,负责整个系统底层工作的处理。
SOC,系统级芯片。把整个系统的所有处理放在一个芯片里,有各种加速引擎负责性能敏感的工作任务,CPU负责一些基本任务的处理和整个系统的控制和管理。
不管叫什么PU,逃不开这四个类型。
2 场景特点:综合、通用以及资源预备
许多AI芯片或系统落地面临的一个主要问题是“我好不容易做了一盘饺子,可用户需要的是一桌菜肴”。也即是说,客户需要的是综合性的系统解决方案,而AI只是其中的一部分,甚至非常小的一部分。
具体的终端应用场景包罗万象,但云端和边缘端,却都是清一色的服务器来提供服务端的运行以及和终端的协同。这些服务器,可以服务各行各业、各种不同类型的场景的服务端工作任务的处理。云和边缘服务器场景,需要考虑服务端系统的特点(微服务化功能持续解构,并且还和多租户、多系统共存),对系统的灵活性的要求远高于对性能的要求,需要提供的是综合性的通用解决方案。
在云和边缘数据中心,当CSP投入数以亿计资金,上架数以万计的各种型号、各种配置的服务器的时候,严格来说,它并不知道,具体的某台服务器最终会售卖给哪个用户,这个用户到底会在服务器上面跑什么应用。并且,未来,这个用户的服务器资源回收之后再卖个下一个用户,下一个用户又用来干什么,也是不知道的。
因此,对CSP来说,最理想的状态是,存在一种服务器,足够通用,即不管是哪种用户哪种应用运行其上,都足够高效快捷并且低成本。只有这样,系统才够简单而稳定,运维才能简单并且高效。然后要做的,就是把这种服务器大规模复制(大规模复制意味着单服务器成本的更快速下降)。
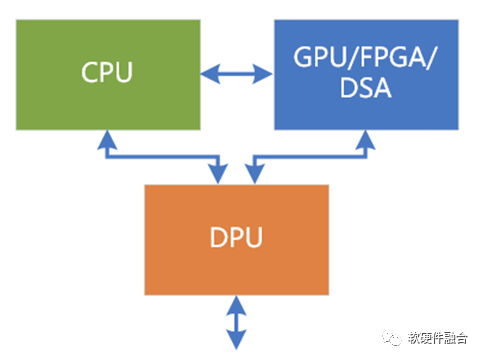
服务器都是相对通用,服务器上目前大芯片就三个位置,也就是我们通常所说的数据中心三大芯片的位置:CPU、业务加速的GPU以及基础设施加速的DPU。大家要做的,就是自己芯片的定位,以及同其他各种厂家的各种芯片来竞争这三个位置。
有些专用的芯片,用在特定领域,需要设计专门的服务器,这种方案都流离在整个云和边缘计算主流体系之外的,落地门槛很高,也很难大规模落地。
3 超异构处理器是什么?
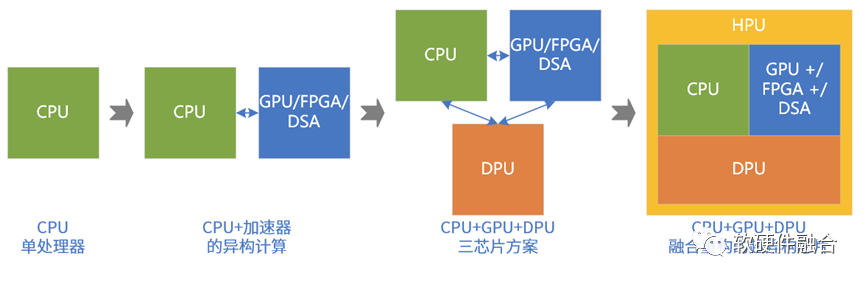
系统持续演进:
第一阶段,性能要求不高,CPU能够满足要求。目前数据中心大量服务器依然是只有CPU处理器。
第二阶段,性能敏感类任务大量出现,不得不进行异构加速。如AI训练、视频图像处理,HPC等场景。这类场景,目前的状况主要:NVIDIA GPU+CUDA为主流,FPGA FaaS非主流,AI类的DSA落地较少(包括谷歌TPU,也不算成功)。
第三阶段。DPU的出现,CPU、GPU和DPU共同构成数据中心的三大处理芯片。
第四阶段,再融合。
为什么不是独立多芯片?为什么需要融合单芯片?融合单芯片是有诸多优势的:
融合有利于计算的充分整合,进一步提升数据计算效率;
系统成本跟主要芯片的数量是直接相关的,融合型单芯片可以进一步降低成本;
融合系统,内部功能划分和交互统一构建,相比三芯片方案,可以显著降低彼此功能和交互的各种掣肘(相互拖累);
大部分(80%-90%)场景是相对轻量级场景,通过超异构的单芯片可以覆盖其复杂度和系统规模;
Chiplet加持,可以通过多DIE单芯片的方式,实现重量级场景的覆盖。
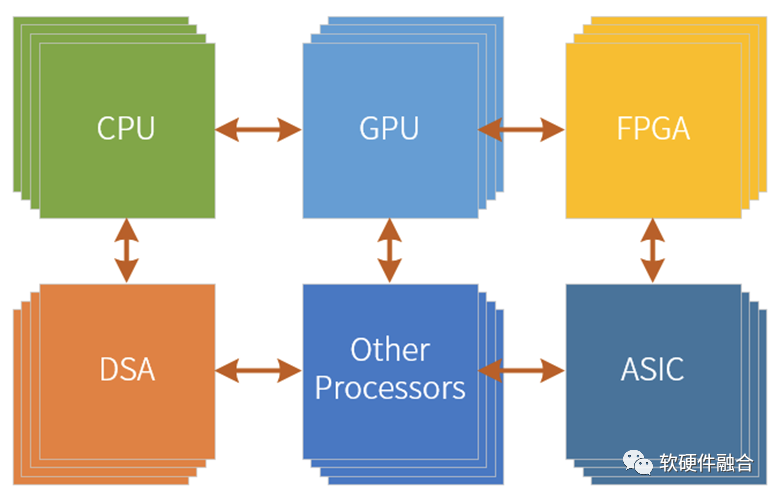
超异构处理器,可以认为是由CPU、GPU、各类DSA以及其他各类处理器引擎共同组成的,CPU、GPU和DPU整合重构的一种全系统功能融合的单芯片解决方案。
3.1 为什么叫超异构处理器?
首先,不能叫超融合处理器。超融合的概念是云计算领域一个非常重要的概念,大致意思是说在小规模集群能够把云计算的IaaS层的服务以及云堆栈OS完整部署,可以提供给企业和私有云场景的云计算解决方案,并且因为和公用云堆栈OS是同一的体系,可以实现混合云的充分协同。
超异构处理器和超融合没有必然联系,可以支持小集群的超融合,也可以支持大集群的不“融合”。
NVIDIA对DPU的未来愿景:数据量越来越大,而数据在网络中流动,计算节点也是靠数据的流动来驱动计算,计算的架构从以计算为中心转向了以数据为中心。
所有的系统本质上就是数据处理,那么所有的设备就都可以是Data Processing Unit。所以,未来以DPU为基础,不断地融合CPU和GPU的功能,DPU会逐渐演化成数据中心统一的处理器(只是,目前没有叫超异构HPU这个名字罢了)。
不管名称具体叫什么,这个处理器,一定是基于多种处理引擎混合的(超异构计算)、面向宏系统场景的(MSOC,Micro-SOC)、数据驱动的(DPU,Data Processing),一个全新的处理器类型。
4 超异构处理器和传统SOC的区别
严格来说,超异构处理器也是属于SOC的范畴。但如果只是称之为SOC,那无法体现超异构处理器和传统SOC的本质区别。这样,不利于我们深刻认识超异构处理器的创新价值所在,以及在支撑超异构处理器需要的创新技术和架构方面积极投入。
如下表格为超异构处理器和传统SOC的对比:
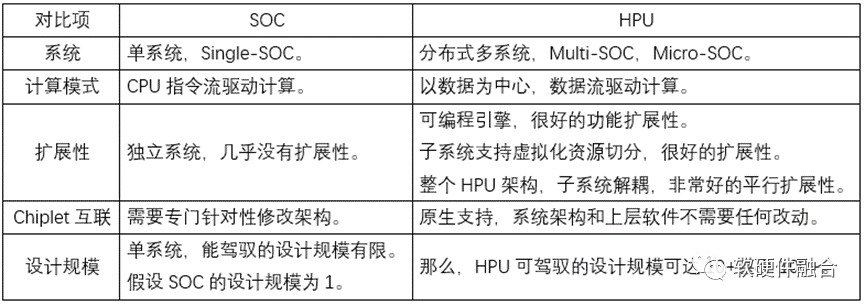
5 超异构处理器,是否可以极致性能的同时,还足够“通用”?
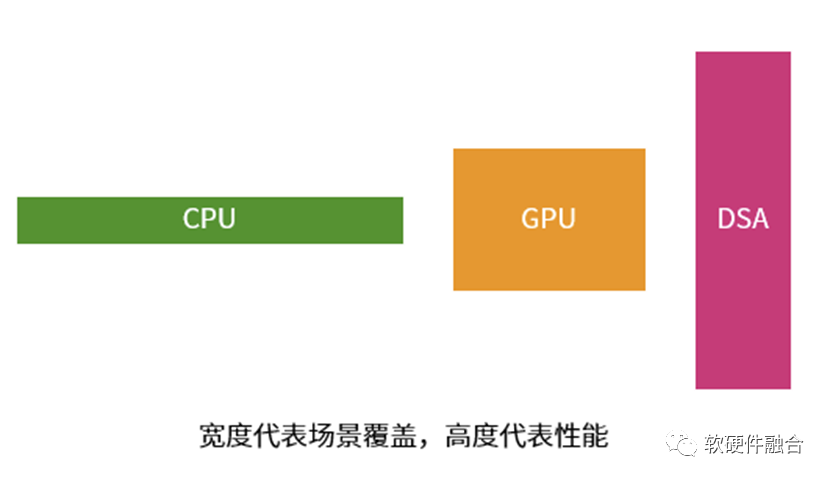
每一种处理器(引擎)都有其优势,也都有其劣势:
CPU非常通用,能够干几乎所有事情。但劣势在于,其性能效率是最低的。
DSA的性能足够好,劣势在于只能覆盖特定的领域场景,其它领域场景完全没法用。
GPU,介于两者之间。能够覆盖的领域场景比DSA多、比CPU少,性能比CPU好但比DSA差。
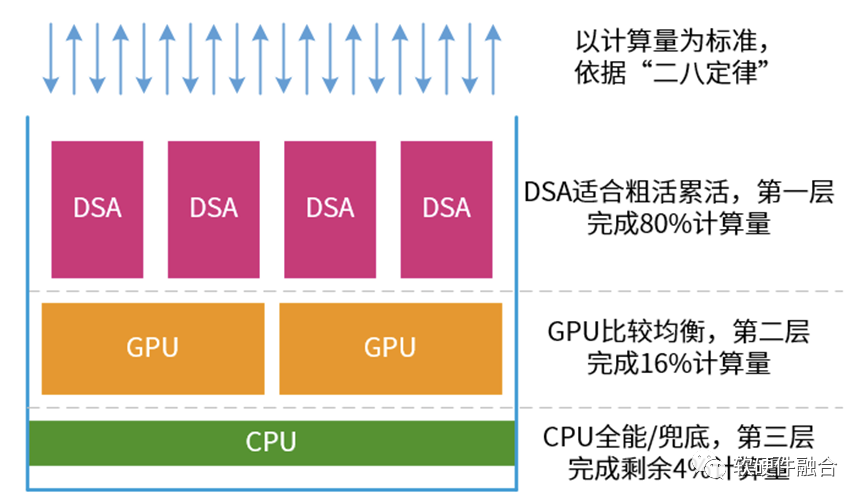
复杂的宏系统,存在“二八定律”。比如,在服务器上,永远少不了的虚拟化、网络、存储、安全类的任务,以及很多服务器都需要的文件系统、数据库、AI推理等。
因此,我们可以把系统计算当做一个塔防游戏:
在最前端,主要是各类DSA。他们的性能很好,负责处理算力需求强劲的任务。这些任务占整个计算量的80%。
中间是GPU,性能也不错,覆盖面也不错。则负责处理剩余20%中的80%的计算量。
而CPU的任务,就是兜底。所有“漏网之鱼”都由CPU负责处理。
这个思路,也对应我们第一部分介绍的系统的三类任务划分。
按照这个思路,我们再通过一些软硬件融合的系统设计,提供更多的通用性、灵活性、可编程性、易用性等能力,然后再不断的集成新的性能敏感任务的加速。
基本上,这样的通用超异构处理器,可以在提供极致性能兼极致灵活性的同时,可以覆盖大部分云、边缘和超级终端的场景。
6 超异构处理器可以用在哪里?
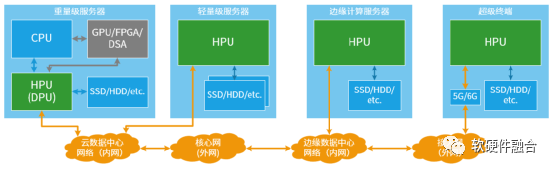
超异构处理器HPU相比传统SOC,最核心的特点是宏系统,需要支持虚拟化和多租户多系统共存,需要支持资源、数据和性能隔离。
因此,超异构处理器主要用在云计算、边缘计算以及自动驾驶超级终端等复杂计算场景:
云端重量级服务器。首先,HPU可以当做DPU来使用;更长远的,可以通过Chiplet方式实现HPU对重量级场景的覆盖。
云端轻量级服务器。可以实现HPU单芯片对目前以CPU为主的多个芯片的集成,并且性能显著提升。
边缘计算服务器。类似云端轻量服务器,可以通过单芯片集成的HPU实现所有计算的全覆盖。
超级终端。以自动驾驶为典型场景,目前也是逐渐地从分布式的ECU、DCU向集中式的超级终端单芯片转变。这将是HPU在终端场景的典型应用。
总结一下,超异构处理器的核心价值在于确保整个系统如CPU一样极致灵活性的同时,还可以提供相比目前主流芯片数量级的算力提升。可以用在云计算、边缘计算、超级终端等各类复杂计算场景。
系统越复杂,超异构处理器的价值越凸显!
审核编辑:编辑:刘清
-
处理器
+关注
关注
68文章
19404浏览量
230925 -
FPGA
+关注
关注
1630文章
21796浏览量
605452 -
加速器
+关注
关注
2文章
806浏览量
38037 -
NPU
+关注
关注
2文章
290浏览量
18725
原文标题:一种新的处理器类型:通用超异构处理器
文章出处:【微信号:阿宝1990,微信公众号:阿宝1990】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
中国首个异构计算处理器IP核实现 可用于机器学习
【一文看懂】什么是异构计算?

异构计算的前世今生
异构计算在人工智能什么作用?
基于FPGA的异构计算是趋势
异构计算的两大派别 为什么需要异构计算?
异构计算:架构与技术
异构计算,你准备好了么?

异构计算真就完美无缺吗
基于超异构计算的通用处理器GP-HPU介绍
新一代计算架构超异构计算技术是什么 异构走向超异构案例分析






 工商网监
工商网监
评论