 也想造个ChatGPT?看你的算力跟得上吗?
也想造个ChatGPT?看你的算力跟得上吗?
近年来人工智能领域的发展可谓是日新月异主要突出个“大”“快”“准”
参数和算力规模越来越大、新模型的出现和迭代越来越快、预测结果越来越准。
回看刚刚过去的2022,好像每隔几个月就会有公司发布一个新的AI模型,让有史以来最大的AI模型这一称号反复易手,全球各大顶尖的科技公司在此展开“军备竞赛”并乐此不疲。
当然,模型的“大”也带来了性能的“强”,最近大火的ChatGPT已经能为你写出代码,甚至改变现有的搜索格局。就比如微软正在将ChatGPT加入到Bing中来对抗Google,可谓是火药味满满。
人工智能赛道的激烈交火
自从2018年谷歌推出3亿模型参数的BERT模型,大规模预训练模型逐渐进入人们的视野。随后OpenAI推出了15亿参数的GPT-2,这场军备竞赛便已开始了“低烈度”交火。
到了2020年,GPT-3的出现将这场军备竞赛直接拉升到千亿级别。现在,万亿级别的Switch Transformer模型已经出现。在未来这场“军备竞赛”也许会更加激烈。
人工智能模型已然成长为一个“巨无霸”,就目前来看,大型语言模型的参数量依然保持增长势头,你几乎看不到低于1亿参数量的AI模型。
当然,这并不代表小模型是没有潜力或是不好的。相较于大型AI模型,小型模型的投入更低,落地更加简单,能够更快更好的解决现实问题。只不过,大模型的泛用性及其强大的性能代表了未来人工智能发展的方向,因此也就更加容易被我们注意到。
“大”和“强”的背后是更多的挑战
然而,强悍的性能与巨大的规模背后则是无数的资本投入,这些日渐庞大的AI模型也为现有的AI基础设施和开发流程带来了更多的挑战。
众所周知,一个强大的AI模型从诞生到商业化落地,需要大量的数据投喂、精巧的算法优化以及强大的算力支持。
现如今大模型的权重可达100GB以上,但我们的开发工具却滞后于规模,使用起来十分费力,部署时往往要等上好几小时,编译时间长达两分钟,降低了AI工程师的工作效率,研发与迭代速度也会受到影响。
同时,训练数据量也在以惊人的速度上涨,高质量的数据往往能加快训练速度,而糟糕的数据可能会让算法的效用大大降低。根据Scale AI的《人工智能准备情况》调查发现,数据质量成为获取训练数据时面临的最大挑战。
而随着逐渐变大的体量,其参数量和算力要求给整个团队和工程环节带来极大的压力。
戴尔科技集团助力AI持续前行
算力、算法、数据作为人工智能的三大要素缺一不可,强大的基础设施总是能够让您更好地把握成功的机遇。
戴尔科技集团作为全球领先的数字化解决方案供应商,在AI和HPC领域深耕多年,致力于将算力转化为业务创新能力,以科技赋能各行各业。
戴尔PowerEdge XE8545拥有强大的GPU加速器优化性能,专为高性能AI计算设计,使用业界领先的NVLink GPU直连设计,帮助您突破数据流和计算能力的界限,应对当下严苛的算力需求。
面向未来,戴尔科技集团用于AI的下一代PowerEdge产品组合也即将到来:PowerEdge XE9680、PowerEdge XE9640和PowerEdge XE8640,它们均为提供更高性能和更强大的计算结果而构建,帮助企业从容应对未来AI发展。
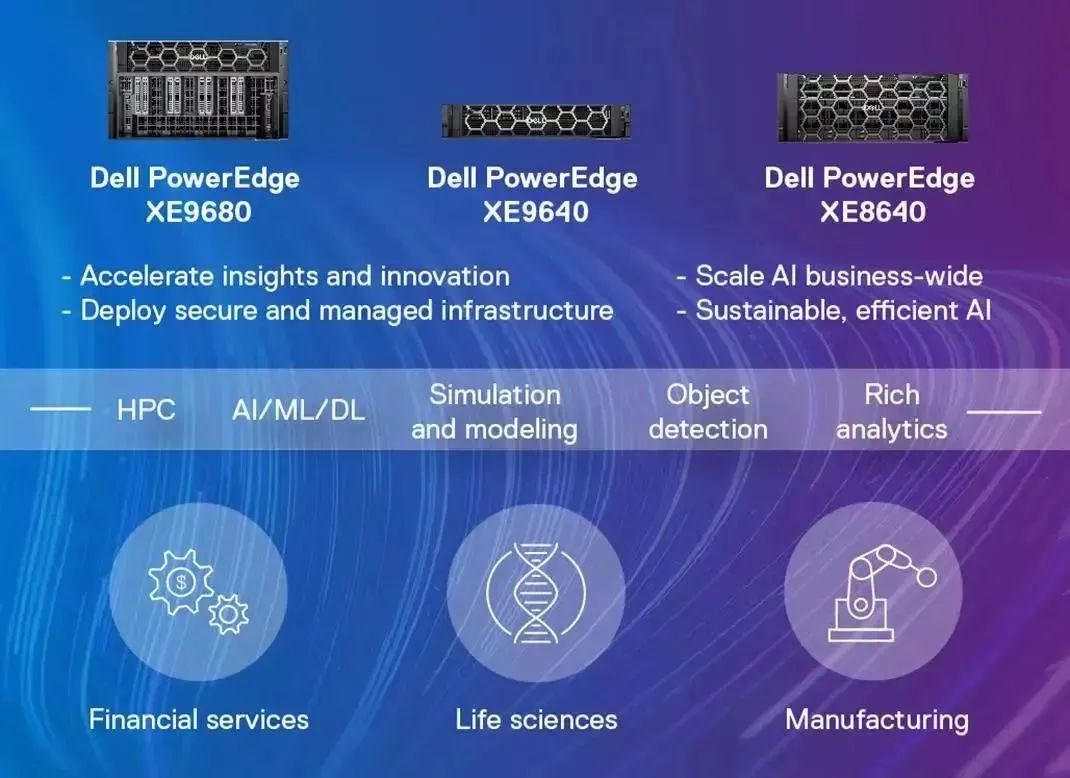
目前,非结构化数据用于AI的占比持续扩大,面对日益庞大且复杂的训练数据量,高效的存储系统对于工程师团队的帮助则愈发显著。在这方面,戴尔PowerScale横向扩展NAS存储能够进一步消除I/O瓶颈,加快您的AI模型训练和验证速度,释放非结构化数据的价值。
无论是大模型的军备竞赛,还是小模型的实用为先,AI正在以前所未有的速度持续发展,每一次突破都将为行业带来颠覆性的变革。
戴尔科技集团将以全面的解决方案,助力越来越多的AI落地,持续以科技推动人工智能行业的发展。
审核编辑 :李倩
-
人工智能
+关注
关注
1792文章
47446浏览量
239061 -
模型
+关注
关注
1文章
3268浏览量
48944 -
ChatGPT
+关注
关注
29文章
1564浏览量
7831
原文标题:也想造个ChatGPT?看你的算力跟得上吗?
文章出处:【微信号:戴尔企业级解决方案,微信公众号:戴尔企业级解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
杰和课堂|带你认识算力

算力基础篇:从零开始了解算力
浅析三大算力之异同

大模型时代的算力需求
中科曙光入选2024算力服务产业图谱及算力服务产品名录
AI智算中心算力服务商探索智造完成A轮融资
急!OpenAI再推王炸GPT-4o,算力跟得上吗?
算力系列基础篇——算力101:从零开始了解算力

算力十问:超算智算,通算及算存比
智能算力规模超通用算力,大模型对智能算力提出高要求






 工商网监
工商网监
评论