 谷歌新作Muse:通过掩码生成Transformer进行文本到图像生成
谷歌新作Muse:通过掩码生成Transformer进行文本到图像生成
图像生成领域越来越卷了!
文本到图像生成是 2022 年最火的 AIGC 方向之一,被《science》评选为 2022 年度十大科学突破。最近,谷歌的一篇文本到图像生成新论文《Muse: Text-To-Image Generation via Masked Generative Transformers》又引起高度关注。

Muse: Text-To-Image Generation via Masked Generative Transformers
论文地址:https://arxiv.org/abs/2301.00704
项目地址:https://muse-model.github.io/
该研究提出了一种使用掩码图像建模方法进行文本到图像合成的新模型,其中的图像解码器架构以来自预训练和 frozen T5-XXL 大型语言模型 (LLM) 编码器的嵌入为条件。
与谷歌先前的 Imagen 模型类似,该研究发现基于预训练 LLM 进行调整对于逼真、高质量的图像生成至关重要。Muse 模型是建立在 Transformer (Vaswani et al., 2017) 架构之上。
与建立在级联像素空间(pixel-space)扩散模型上的 Imagen (Saharia et al., 2022) 或 Dall-E2 (Ramesh et al., 2022) 相比,Muse 由于使用了离散 token,效率显著提升。与 SOTA 自回归模型 Parti (Yu et al., 2022) 相比,Muse 因使用并行解码而效率更高。
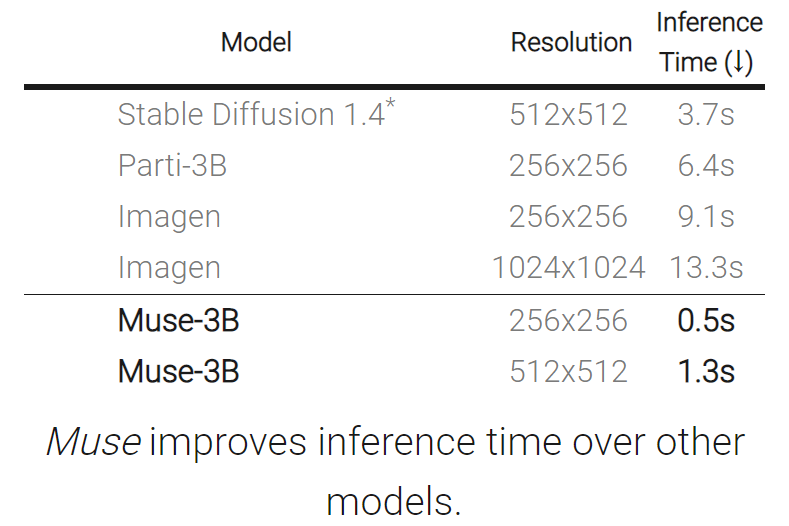
基于在 TPU-v4 上的实验结果,研究者估计 Muse 在推理速度上比 Imagen-3B 或 Parti-3B 模型快 10 倍以上,比 Stable Diffusion v1.4 (Rombach et al., 2022) 快 2 倍。研究者认为:Muse 比 Stable Diffusion 推理速度更快是因为 Stable Diffusion v1.4 中使用了扩散模型,在推理时明显需要更多次迭代。
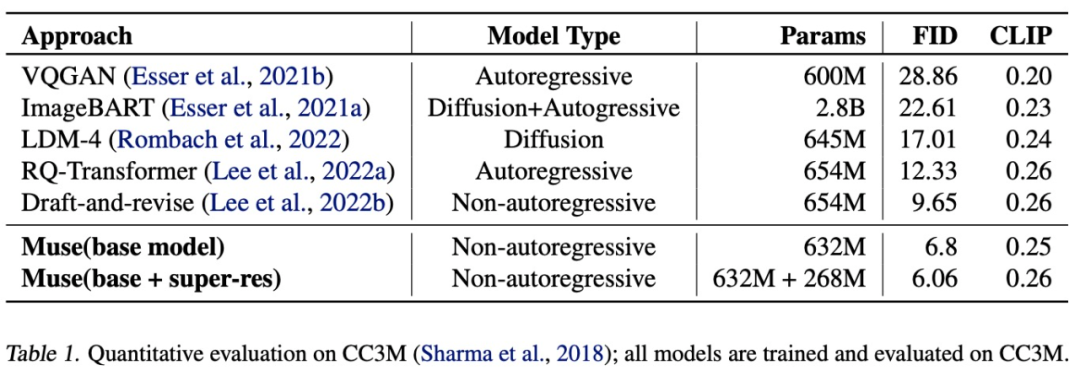
另一方面,Muse 效率的提升没有造成生成图像质量下降、模型对输入文本 prompt 的语义理解能力降低的问题。该研究根据多个标准评估了 Muse 的生成结果,包括 CLIP 评分 (Radford et al., 2021) 和 FID (Heusel et al., 2017)。Muse-3B 模型在 COCO (Lin et al., 2014) 零样本验证基准上取得了 0.32 的 CLIP 分数和 7.88 的 FID 分数。
下面我们看看 Muse 生成效果:
文本 - 图像生成:Muse 模型从文本提示快速生成高质量的图像(在 TPUv4 上,对于 512x512 分辨率的图像需要时间为 1.3 秒,生成 256x256 分辨率的图像需要时间为 0.5 秒)。例如生成「一只熊骑着自行车,一只鸟栖息在车把上」:
Muse 模型通过对文本提示条件下的图像 token 进行迭代重新采样,为用户提供了零样本、无掩码编辑(mask-free editing)。

Muse 还提供了基于掩码的编辑,例如「在美丽的秋叶映照下,有一座凉亭在湖上」。

模型简介
Muse 建立在许多组件之上,图 3 提供了模型体系架构概述。
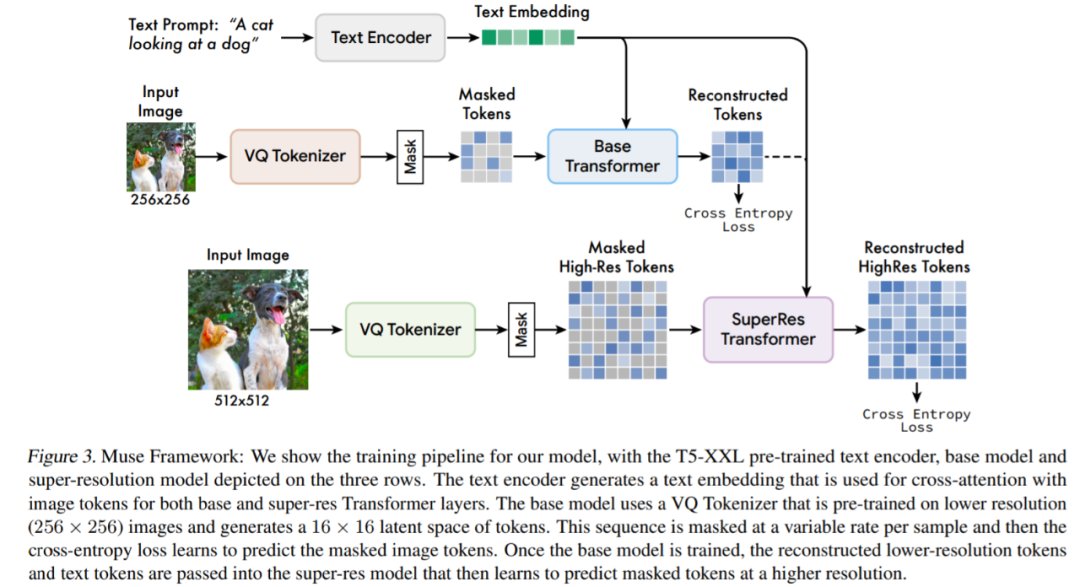
具体而言所包含的组件有:
预训练文本编码器:该研究发现利用预训练大型语言模型(LLM)可以提高图像生成质量。他们假设,Muse 模型学会了将 LLM 嵌入中的丰富视觉和语义概念映射到生成的图像。给定一个输入文本字幕,该研究将其通过冻结的 T5-XXL 编码器,得到一个 4096 维语言嵌入向量序列。这些嵌入向量线性投影到 Transformer 模型。
使用 VQGAN 进行语义 Tokenization:该模型的核心组件是使用从 VQGAN 模型获得的语义 token。其中,VQGAN 由一个编码器和一个解码器组成,一个量化层将输入图像映射到一个学习码本中的 token 序列。该研究全部使用卷积层构建编码器和解码器,以支持对不同分辨率图像进行编码。
基础模型:基础模型是一个掩码 transformer,其中输入是投影到 T5 的嵌入和图像 token。该研究保留所有的文本嵌入(unmasked),随机掩码不同比例的图像 token,并用一个特殊的 [mask] token 替换它们。
超分辨率模型:该研究发现使用级联模型是有益的:首先是生成 16 × 16 潜在映射(对应于 256 × 256 图像)的基础模型,然后是将基础的潜在映射上采样到的超分辨率模型,也就是 64 × 64 的潜在映射(对应于一个 512 × 512 的图像)。
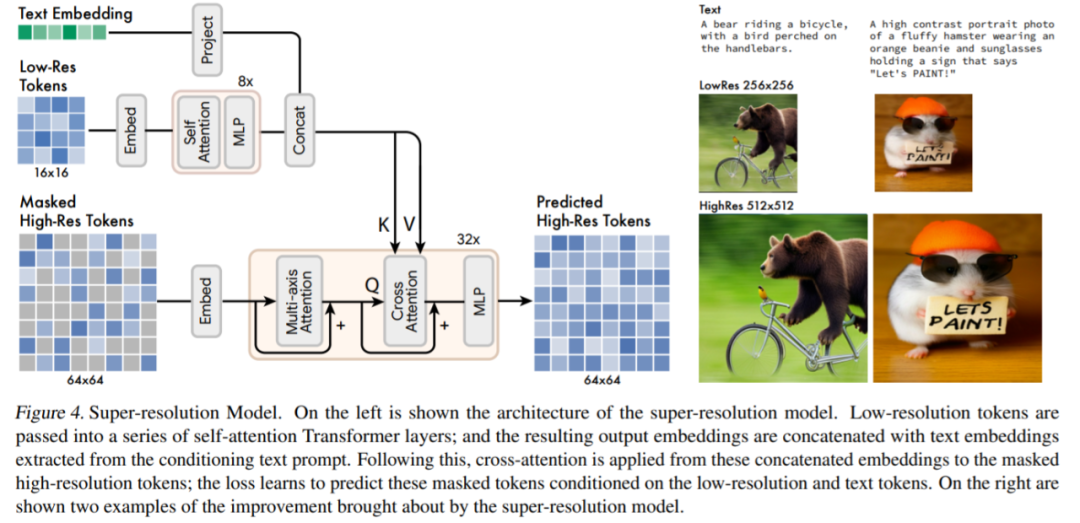
解码器微调:为了进一步提高模型生成精细细节的能力,该研究通过添加更多的残差层和通道来增加 VQGAN 解码器的容量,同时保持编码器容量不变。然后微调新的解码器层,同时冻结 VQGAN 编码器权重、码本和 transformer(即基础模型和超分辨率模型)。
除了以上组件外,Muse 还包含可变掩码比率组件、在推理时迭代并行解码组件等。
实验及结果
如下表所示,与其他模型相比,Muse 缩短了推理时间。
下表为不同模型在 zero-shot COCO 上测量的 FID 和 CLIP 得分:

如下表所示,Muse(632M (base)+268M (super-res) 参数模型)在 CC3M 数据集上训练和评估时得到了 6.06 的 SOTA FID 分数。
下图是 Muse 与 Imagen、DALL-E 2 在相同 prompt 下生成结果的例子。

审核编辑 :李倩
-
模型
+关注
关注
1文章
3413浏览量
49471 -
图像生成
+关注
关注
0文章
22浏览量
6933 -
Transformer
+关注
关注
0文章
147浏览量
6155
原文标题:比Imagen更高效!谷歌新作Muse:通过掩码生成Transformer进行文本到图像生成
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
借助谷歌Gemini和Imagen模型生成高质量图像

RNN在图片描述生成中的应用
生成式AI工具作用
如何使用 Llama 3 进行文本生成
AIGC生成内容的优势与挑战
AIGC与传统内容生成的区别
labview怎么生成可执行文件
Freepik携手Magnific AI推出AI图像生成器
Transformer语言模型简介与实现过程
如何用C++创建简单的生成式AI模型
生成式AI的基本原理和应用领域
Transformer模型在语音识别和语音生成中的应用优势
谷歌发布Imagen 3,提升图像文本生成技术
微信大模型扩容并开源,推出首个中英双语文生图模型,参数规模达15亿
深度学习生成对抗网络(GAN)全解析





 工商网监
工商网监
评论