 深度学习背景下的图像三维重建技术进展综述
深度学习背景下的图像三维重建技术进展综述
三维重建是指从单张二维图像或多张二维图像中重建出物体的三维模型,并对三维模型进行纹理映射的过程。三维重建可获取从任意视角观测并具有色彩纹理的三维模型,是计算机视觉领域的一个重要研究方向。传统的三维重建方法通常需要输入大量图像,并进行相机参数估计、密集点云重建、表面重建和纹理映射等多个步骤。近年来,深度学习背景下的图像三维重建受到了广泛关注,并表现出了优越的性能和发展前景。
本文对深度学习背景下的图像三维重建的技术方法、评测方法和数据集进行了全面的综述。首先对三维重建进行分类,根据三维模型的表示形式可将图像三维重建方法分类为基于体素的三维重建、基于点云的三维重建和基于网格的三维重建,由输入图像的类型可将图像三维重建分类为单张图像三维重建和多张图像三维重建,随后介绍了不同类别的三维重建方法,从三维重建方法的输入、三维模型表示形式、模型纹理颜色、重建网络的基准值类型和特点等方面进行了总结,描述了深度学习背景下的图像三维重建方法的常用数据集和实验对比,最后总结了当前图像三维重建领域的待解决的问题以及未来的研究方向。
00 引言
三维重建的目标是从单张二维图像或多张二维图像中重建出物体和场景的三维模型,并对三维模型进行纹理映射。三维重建是计算机视觉领域的一个重要研究方向,利用计算机重建出物体的三维模型,已经成为众多领域进行深入研究前不可或缺的一部分。在医疗领域中,利用三维模型诊断身体状况;在历史文化领域中,将文物进行立体重建,供科学研究及游客参观。除此之外,在游戏开发、工业设计、航天航海等领域,三维重建技术具有重要的应用前景。
目前,研究人员主要利用三类方法来重建三维模型:
一是直接操作的人工几何建模技术;
二是利用三维扫描设备对目标进行扫描,然后重建目标的三维模型;
三是图像三维重建,采集单张或多张的图像,运用计算机视觉技术来重建三维模型。
在上述三种方法中,图像三维重建成本低、操作简单,可以对不规则的自然或人工合成物体进行建模,重建真实物体的三维模型。
传统的图像三维重建是从多视图几何(Andrew等, 2001)的角度进行处理,从几何上理解和分析从三维到二维的投影过程,设计从二维到三维的逆问题解决方案进行三维重建。传统的三维重建通常需要大量已知相机参数的图像,并进行相机参数估计、密集点云重建和表面重建等多个步骤。随着卷积神经网络(CNN)的发展,深度学习广泛应用于计算机视觉中的各种领域,基于深度学习的技术方法利用先验知识来解决各种复杂问题。人们通常能够对物体和场景建立丰富的先验知识,便于从单一视角重建物体的立体模型,推断物体的大小和其他视角的形状。
深度学习背景下的图像三维重建方法利用大量数据建立先验知识,将三维重建转变为编码与解码问题,从而对物体进行三维重建。随着三维数据集的数量不断增加,计算机的计算能力不断提升,深度学习背景下的图像三维重建方法能够在无需复杂的相机校准的情况下从单张或多张二维图像中重建物体的三维模型。
三维模型的表示形式有三种:体素模型、网格模型和点云模型。体素是三维空间中的正方体,相当于三维空间中的像素;网格是由多个三角形组成的多面体结构,可以表示复杂物体的表面形状;点云是坐标系中的点的集合,包含了三维坐标、颜色、分类值等信息。三维模型的表示形式如图1所示。
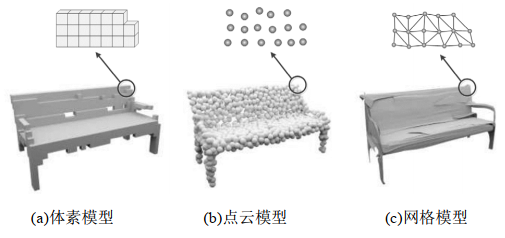
图 1 三维模型的表示形式
根据三维模型的表示形式可以将图像三维重建方法分类为基于体素的三维重建、基于点云的三维重建和基于网格的三维重建,其中基于网格的三维重建方法包含单一颜色的网格三维重建和具有色彩纹理的网格三维重建,由输入图像的类型可将图像三维重建分类为单张图像三维重建和多张图像三维重建。图像三维重建方法分类如图2所示。
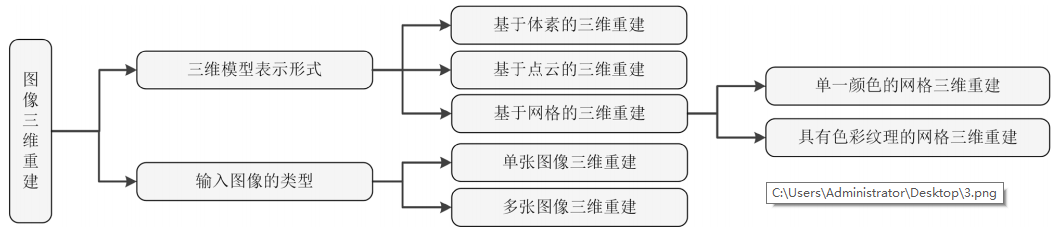
图2 图像三维重建方法的分类
典型的三维重建算法时间顺序概述如图3所示。
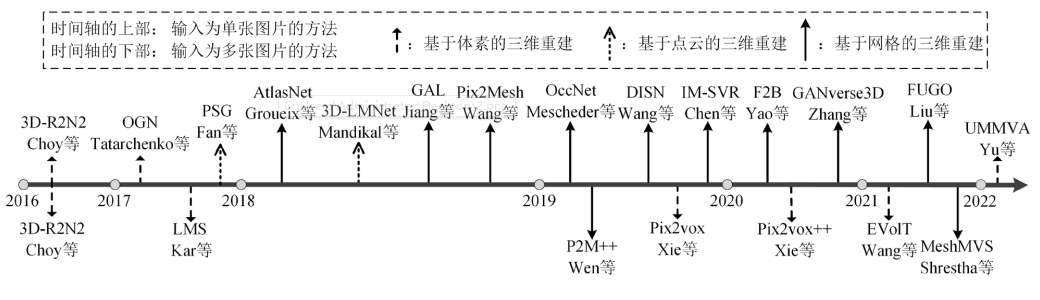
图3 典型的三维重建算法按时间顺序的概述
尽管目前已有一些三维重建相关综述文献(郑太雄等,2020;吴博剑等,2020;龙霄潇等,2021),但已有的综述文献主要介绍传统方法或特殊物体的三维重建,介绍深度学习背景下的图像三维重建技术的文献相对偏少。本文立足于三维重建领域,对图像三维重建研究进行分析总结,从输入图像类型的角度分别对单张图像三维重建和多张图像三维重建进行了介绍,并对三维重建的评测方法、数据集、实验对比方法以及三维重建领域的问题与未来研究方向进行了总结。
01 单张图像三维重建
单张图像三维重建使用卷积神经网络,从大量的训练数据中学习图像中的特征来重建物体的三维模型。在的单张图像三维重建方法中,早期的方法通常使用端到端网络得到体素模型或点云模型形式表示的三维模型,另外一些方法首先获取深度图、点云或隐式函数,得到三维模型的中间表示,随后再将三维模型的中间表示转化为网格模型。
1.1 基于体素的单张图像三维重建
基于体素模型的方法法使用体素模型对三维形状进行表示,体素模型是在深度学习背景下的图像三维重建技术最早应用的一种表示方法。通过使用体素模型,在图像分析中使用的二维卷积可以很容易地扩展到三维。基于体素的单张图像三维重建通常利用编码器解码器结构的网络重建三维模型。
2016年,Choy等人(2016)在长短期记忆网络(LSTM)基础上设计了三维(3D)LSTM网络处理单张图像的编码信息,网络由三部分组成:CNN、3D-LSTM和3D-CNN,CNN将图像编码为低维特征,并送入3D-LSTM更新潜在编码,最后利用3D-CNN解码,使用体素交叉熵的和作为损失函数训练网络,重建体素模型,实现了从单张图像端到端重建三维模型。Yang等人(2019)利用生成对抗网络(GAN)(Goodfellow等, 2014)对体素模型重建网络进行改进,但需要同时输入深度图,增大了获取输入信息的难度。对于输入为单张图像的体素重建网络,可以从编码器、解码器和损失函数等方面进行优化改进。Liu等人(2018)使用三维卷积神经网络进行编码,将三维卷积代替解码器中的二维卷积,可以适应三维模型,将学习到的潜在特征解码为三维占用概率从而重建体素模型。Tulsiani等人(2017; 2018)使用多视角二维图像和相应的掩膜图像作为基准使用视图一致性损失训练网络,减小了数据获取的难度,利用单张图像来预测体素占用概率并重建物体的体素模型。
为了提升体素分辨率,一些方法用八叉树来表示体素空间,八叉树是具有自适应单元大小的三维结构,在传统的深度图融合方式的三维重建等方面有着广泛的应用,与常规体素网格相比,减少了内存的消耗。在体素上定义的函数可以转换为在八分树上定义的函数,首先以八个子空间代表整个空间,随后递归地划分每个空间为八个子空间,直至达到最大树深度。Tatarchenko等人(2017)使用3DCNN输出特征图,特征图解码为八叉树,然后低分辨率结构逐渐细化到高分辨率。Wang等人(2018)等从八叉树的不同叶节点进行计算,将节点标记为空状态、准确状态和不准确状态,结合八叉树结构交叉熵和叶节点平面参数差作为损失函数生成八叉树,最终根据八叉树结构重建体素模型。Yu等人(2022)利用潜在空间中的特定类别的多模态先验分布训练变分自编码器,利用潜在空间的子集就可以找到先验分布的目标模态,获取类别的先验信息,随后将先验信息和图像特征共同送入解码器重建三维模型。
在基于体素的三维重建网络中,处理体素的方式与处理图像中的像素的方式类似,二维卷积能够较简单地转变为三维卷积。基于体素模型的三维重建网络的解码器通常由三维卷积构成,利用三维体素模型进行训练,但重建体素模型通常需要较大的内存,所需内存和计算要求与体素模型的分辨率大小成立方比例,因此重建的体素模型分辨率较低,基于体素模型的方法无法重建物体的细节部位。
1.2 基于点云的单张图像三维重建
点云是利用三维坐标、颜色等信息表示物体表面的点的集合,为三维重建网络提供了更好的表示形式。基于点云的方法重建的形状更加平滑,相较于体素模型运算所占用的内存更少。基于点云的单张图像三维重建通常利用编码器-解码器结构的网络重建点云模型。Fan等人(2017)在图像编码后使用全连接和反卷积作为解码器,使用倒角距离和搬土距离作为损失函数的指标,重建点云形式的三维模型。Mandikal等人(2019)使用全连接作为解码器,利用搬土距离建立损失函数重建稀疏点云,然后使用多层感知机(MLP)提取点云特征,使用倒角距离作为损失函数的指标对初始的稀疏点云进行密集重建来获取物体的点云模型。另外一些研究者联合不同损失函数设计单张图像点云模型重建的网络。Mandikal等人(2019)使用点云自编码器来学习三维点云的潜在空间。图像编码器将二维图像以概率的方式映射潜在空间,推断出多个三维重建模型,联合匹配损失和多样性损失重建点云模型。Jiang等人(2018)联合生成对抗损失和多视图一致损失,使用GAN网络重建点云模型。
由于点云的无序性,二维卷积无法直接应用在基于点云的三维重建方法的解码器中,基于点云的三维重建方法通常使用全连接层组成MLP解码点云信息,计算量随点云增多而增大,为减少计算量,通常侧重于重建表面的点,由于点云的离散性,重建的点云模型表面不完整,分辨率较低。
1.3 基于网格的单张图像三维重建
1.3.1 基于多阶段网络的单张图像三维重建
相比于体素模型和点云模型,网格模型能够更加完整地表示物体表面形状,一些方法利用深度估计、点云重建等多个阶段构建深度学习网络重建网格形式的三维模型。Groueix等人(2018)使用Resnet(He等, 2016)作为图像的编码器,随后使用MLP进行解码,将二维点映射为三维点,以点的倒角损失作为损失函数重建点云模型,使用泊松重建算法重建网格模型。
深度图和表面法向表示物体部分视角的立体结构,深度估计和表面法向估计可作为网格重建的中间步骤。深度图的像素表示物体到相机所在平面的距离,表面法向表示物体表面的点的切线方向。基于深度学习的深度估计方法(宋巍等, 2022)已发展较长时间,Eigen等人(2014)提出单张图像深度估计的卷积神经网络框架,使用两个卷积神经网络分别从全局和局部范围对图像对应的深度图进行粗略估计和细化,Hu等人(2019)提出多尺度特征融合策略的网络结构,提高了深度估计的效果,Chen等人(2019)设计了基于感知结构的残差金字塔网络结构,在深度估计网络中更高效地进行特征融合。传统的表面法向估计方法使用光度立体算法(Woodham, 1980; Shi等,2014)进行表面法向估计,为提高性能,一些研究者(Chen等,2018; Ju等,2021)将深度学习与光度立体算法相结合,更高效地回归表面法向,举雅琨等人(2022)提出了一种多层聚合和权值共享回归结构的光度立体网络,利用不同尺度的特征回归出高分辨的表面法向。Yao等人(2020)将深度估计和表面法向估计作为中间步骤来重建网格模型,首先估计物体前方的深度和表面法向,随后利用GAN网络估计物体后方的深度和表面法向,利用深度图和表面法向重建点云,使用泊松重建算法将点云模型转换为网格模型。Liu等人(2021)在空间占有的基础上提出类别自适应的联合占有,将类别特征添加到潜在编码中,估计表面法向重建形状,提高三维重建网络重建不同类别的物体的性能,联合反照率重建具有颜色纹理的网格模型。
基于深度和表面法向的网格模型重建对不可见部位的重建效果较差,而人脸图像中的不可见部位较少,Sengupta等人(2018)提取图像特征后使用残差块将图像特征分离为表面法向特征和反照率特征,并估计光照特征,重建具有纹理的人脸三维模型。Abrevaya等人(2020)设计了图像编码器和表面法向解码器之间的跳连接,进行人脸图像到人脸表面法向的转换。Zhang等人(2021)的网络学习人脸身份一致性,估计反照率、深度、姿态、光照和置信度,从图像中重建人脸三维模型。
1.3.2 基于模板的单张图像三维重建
由于网格模型的顶点相互连接,将网格的顶点作为图结构进行处理,使用图卷积神经网络处理网格模型的顶点,从而对初始的网格模型进行变形优化,重建更加精细的网格形式的三维模型。Wang等人(2018)根据编码器提取的图像特征使用图卷积神经网络对初始椭球体形状的网格模型进行多个阶段的变形,联合倒角损失和表面法向损失重建网格模型。Tang等人(2019)综合多种方法设计了骨架桥接网络,该网络分为三个阶段分别重建物体的骨架模型、体素模型和网格模型,使用MLP提取骨架点,根据图像特征和骨架点重建粗糙的体素模型,随后使用3D-CNN处理体素模型并将体素模型网格化,联合倒角距离损失和拉普拉斯平滑度的正则化构建损失函数,利用图卷积神经网络重建网格模型。
不同的人体和人脸之间存在相似性,因此可用参数化模型表示人体和人脸三维模型。人体三维重建方法通常使用蒙皮多人线性模型(SMPL)作为人体参数化模型,Kanazawa等人(2018)设计了人体模型重建网络将CNN作为编码器获得图像特征,由图像特征回归相机参数以及SMPL模型的形状参数和姿态参数,由参数生成SMPL模型。Kolotouros等人(2019)将输入图像编码为低维特征向量,附加到网格模型的三维坐标,随后使用图卷积神经网络对网格进行处理,回归网格模型顶点的三维坐标。Lin等人(2021)提取图像特征向量,并将图像特征与三维坐标连接,学习图像和网格顶点之间的相关性,使用Transformer回归网格顶点的三维坐标。人脸三维重建方法使用可变形人脸模型(3DMM)作为人脸参数化模型,Richardson等人(2017)的网络由CoarseNet和FineNet两部分组成,CoarseNet基于ResNet网络生成由几何和姿态参数表示的粗糙模型,Finenet对粗糙模型的参数进行优化,获取3DMM人脸参数化模型的细节。Zhu等人(2019)通过级联卷积神经网络对图像进行拟合,预测参数更新,并作为3DMM人脸参数化模型的参数生成模型。
基于模板的单张图像三维重建通过变形初始网格模型或回归参数化模型的方式对三维模型进行重建,通常只能重建特定顶点数量的网格模型,对三维模型细节部位的重建效果较差。
1.3.3 基于隐式函数的单张图像三维重建
为减少训练期间的内存并进一步提高重建效果,一些研究者提出可表示三维形状的隐式函数,通过学习重建目标的隐式函数来重建网格形式的三维模型。常用的隐式函数有符号距离函数、空间占有率和点标签。在神经网络构建表示三维形状的隐式函数后,使用提取算法从学习到的三维表示中提取信息,重建网格三维模型。
Wang等人(2019)首先估计相机姿态并投影,随后使用MLP构建符号距离函数,使用符号距离函数隐式函数表示物体形状并重建网格模型。Mescheder等人(2019)使用标记立方体算法设计了一种连续占用网络预测空间占有率,隐式表示三维形状,联合等位面损失和表面法向损失重建网格模型。Chen等人(2019)使用点相对形状的内外状态作为点标签建立隐式函数表示物体,编码器使用Resnet网络对图像进行编码,将特征编码和点坐标送入MLP,解码出点标签的值,将点标签的加权均方误差作为损失函数建立物体的隐式函数,随后使用提取算法从学习到的三维表示中提取网格信息,重建网格形式的三维模型。Popov等人(2020)通过构建网格顶点的概率分布函数隐式表示物体形状,使用跳连接来连接编码器和解码器,提高重建三维模型的性能。
基于隐式函数的三维重建方法可使用特定的数据集和图像编码器对人体等特定物体进行重建,Saito等人(2019)使用像素对齐的隐式函数预测人体模型的内外点标签。使用堆叠沙漏网络对图像进行编码,通过多层感知机解码隐式函数,预测三维点在人体模型的内部和外部的分布,构建点标签形式的隐式函数,重建人体模型。Saito等人(2020)使用两级别的像素对齐预测网络进行高分辨率的三维重建。粗糙级别的重建网络捕获图像的像素特征,高分辨率的网络通过预测的表面法向获取细节特征,随后与粗糙级别的三维特征共同送入多层感知机建立隐式函数,重建精细的人体三维模型。基于隐式函数的三维重建方法使用隐式函数表示物体形状,可重建具有完整表面和细节信息的三维模型。
1.3.4 基于可微渲染的单张图像三维重建
大多数单张图像三维重建的方法重建单一颜色的网格,一些方法通过可微渲染估计对三维模型进行纹理映射,重建具有颜色纹理的网格模型。Chen等人(2019)设计了可微渲染框架,通过可微渲染将初步重建的三维模型渲染为二维图像并与输入图像构建二维图像损失,通过估计形状、照明和纹理来重建具有颜色纹理的网格模型。Niemeyer等人(2020)将二维图像和深度图作为基准,利用可微渲染将网格模型渲染为二维图像并与输入图像对比,联合深度损失和空间占有损失重建网格模型,重建具有颜色纹理的网格模型。Zhang等人(2020)利用StyleGAN(Karras等, 2019)网络生成物体的其他视角的图像,随后将多视角图像作为基准,训练基于可微渲染框架的三维重建网络,估计物体的形状、照明和纹理,重建具有颜色纹理的网格模型。
基于可微渲染的单张图像三维重建使用仅包含图像的数据集进行训练,降低了数据集的获取难度,可重建三维模型的颜色纹理。
典型的单张图像三维重建网络结构如图4所示。
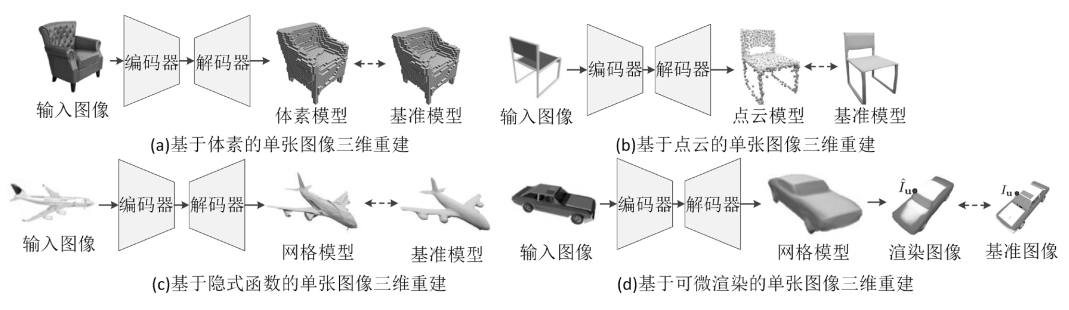
图4 典型的单张图像三维重建网络结构
02 多张图像三维重建
单张图像三维重建的输入为单一视角的单张图像,重建的三维模型的完整性较差,因此一些方法在单张图像方法的基础上进行多张图像三维重建,多张图像三维重建的方法结合多张图像的信息重建三维模型,提高三维重建网络的性能。
2.1 基于体素的多张图像三维重建
基于体素的多张图像三维重建网络结构与单张图像三维重建网络类似,为编码器-解码器结构,将编码器输出的多张图像特征进行融合,并根据图像特征对体素模型进行细化调整,实现多张图像三维重建。早期的方法基于循环神经网络对图像特征进行融合,Choy等人(2016)等依次处理多张图像,将图像的编码特征送入3D-LSTM,3D-LSTM单元根据特征编码更新潜在编码,选择性地更新之前的视图中的被遮挡部位,通过关闭输入门来保留可见部位的潜在编码,最后3D-CNN解码重建体素模型,基于图像特征融合进行多张图像三维重建,网络结构如图5(a)所示。Kar等人(2017)等通过特征编码器对多张图像进行处理,并根据图像相应的相机参数投影到三维特征中,以循环的方式匹配并生成融合的体积特征,由3D-CNN网络转换为体素模型。另外一些方法首先利用单视角图像初步估计形状,随后利用相机参数或姿态编码将形状特征进行融合。Spezialetti等人(2020)通过姿态估计、姿态优化、体素估计和体素细化重建体素模型。Xie等人(2019)使用VGG网络对不同视图分别进行编码,3D卷积解码获取相应的粗糙模型,然后使用上下文注意力模块进行特征融合,获取最终的体素模型,网络结构如图5(b)所示。之后的Pix2Vox++(Xie等, 2020)网络的结构与Pix2Vox类似,其中图像编码器使用Resnet网络,提高了图像编码的性能。Wang等人(2021)使用二维Transformer作为编码器,三维Transformer作为解码器,同时进行特征提取和视图融合,提高了输入图像较多的情况下的体素三维重建方法的性能。
基于循环神经网络的重建方法依次处理多张图像,重建结果与图像的输入顺序相关,运行速度较慢。基于形状特征融合的方法对多张图像分别进行编码、解码,重建粗糙的形状模型并进行融合,运行速度较快,在图像较少的情况下重建效果较好,基于图像特征融合的方法的重建效果随着图像数量增加而提高,在图像较多的情况下重建效果较好。多张图像三维重建的网络结构如图5所示。
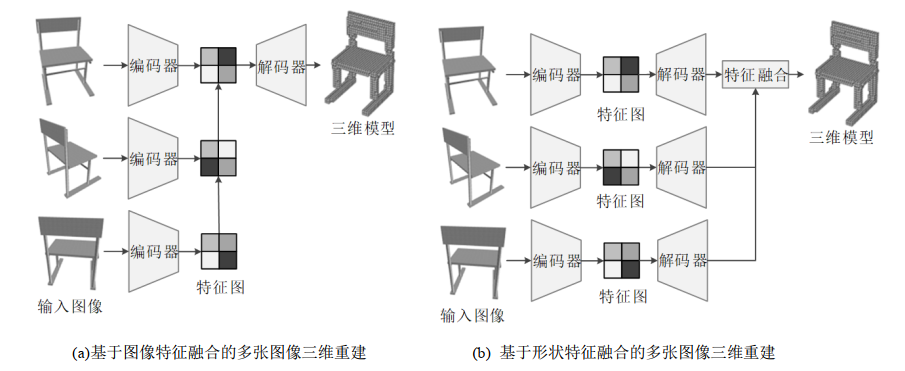
图5 多张图像三维重建网络结构
2.2 基于网格的多张图像三维重建
基于网格的多张图像三维重建的输入通常为已知相机参数的多张图像,通过结合多视图中每张图像所对应的相机参数,能够获取图像之间的对应关系,从而提高重建三维模型的效果。Bautista等人(2021)由U型网络编码器生成特征图,然后根据相机参数将特征图连接,通过MLP生成特征点,随后使用类似空间占用网络的方法,预测空间占有率并通过隐式函数重建三维模型。Shrestha等人(2021)先估计物体的体素模型,然后利用体素模型渲染出深度图,再将渲染出的深度图与多视角立体估计的深度图进行对比,以从粗到细的方式利用对比特征将三维模型进一步细化,最后获取网格形式的三维模型。Wen等人(2019)在单张图像三维重建Pixel2mesh(Wang等, 2018)的输出之后建立多视图变形网络,利用图卷积神经网络对粗糙模型进行迭代细化。多视图变形网络由多张输入图像的特征生成每个顶点周围区域的假设位置,并估计最优变形,网络结构与基于形状特征融合的多张图像三维重建方法的网络结构相似。Yuan等人(2021)将具有权重的辅助视图特征添加到主视图特征中,使用图卷积神经网络对初步重建三维模型进行变形,结合多张图像特征逐步细化网格模型。
大多数重建室内场景的方法属于基于图像特征融合的多张图像三维重建,重建室内场景的网络利用截断符号距离函数表示场景的三维形状,利用行进立方体算法提取网格模型。Murez等人(2020)等使用CNN网络提取多张图像特征并转化为三维特征,将三维特征融合并送入3DCNN回归截断符号距离函数。Sun等人(2021)将特征金字塔网络作为编码器,利用门控循环神经网络网络进行特征融合,解码器使用MLP,提高了运行速度,可对室内场景进行实时三维重建,网络结构如图5(a)所示。
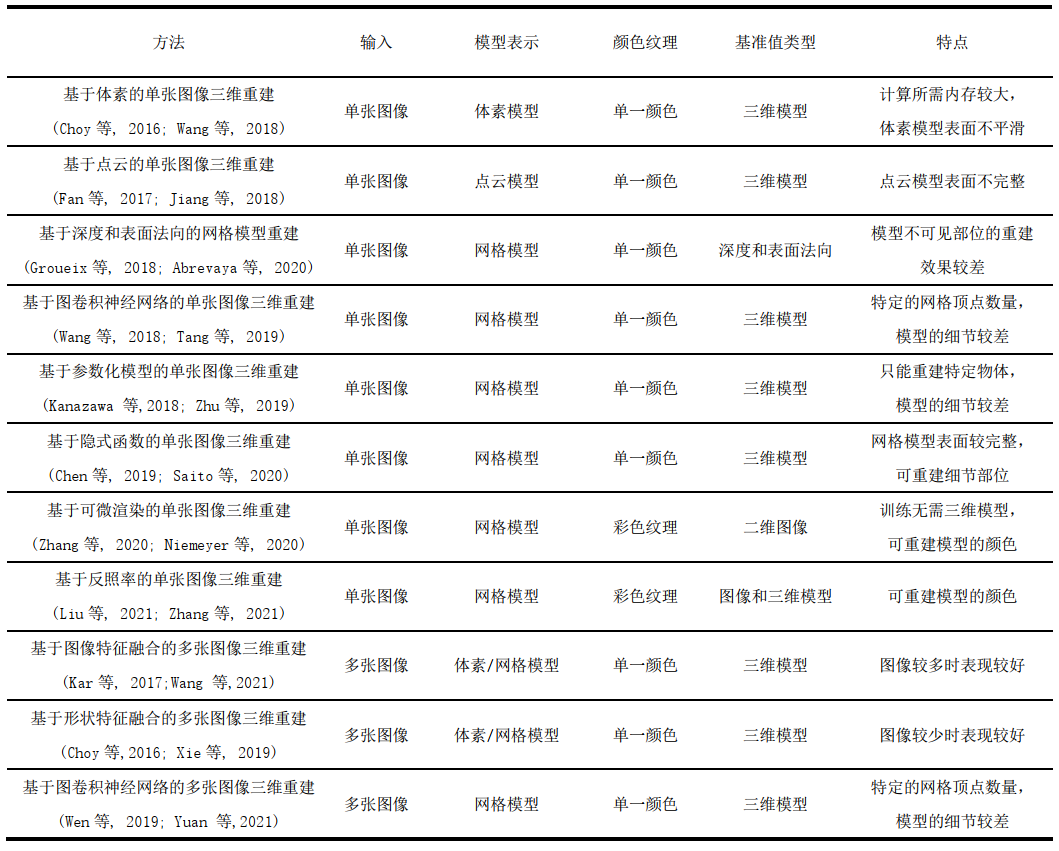
表1 总结了本文介绍的图像三维重建方法。
表1 图像三维重建方法总结
03 数据集与实验对比
在本节中,主要针对深度学习背景下的图像三维重建中的常用数据集以及不同方法在ShapeNet数据集上的实验对比进行相应的介绍。
3.1 数据集介绍
目前,在图像三维重建任务中可用的数据集有ShapeNet、ModelNet、Pix3D、PASCAL 3D+、ObjectNet3D、DTU、NYU depth和KITTI等,这些数据集包含了三维模型或注释信息,其中Shapenet数据集和ModelNet数据集中的图像为三维模型渲染合成,不同视角渲染的多视角图像可用于多张图像三维重建,Pix3D、PASCAL 3D+和ObjectNet3D数据集中的图像为真实图像,三维模型与二维图像相互匹配,PASCAL 3D+和ObjectNet3D数据集中的三维模型匹配相同类别的模型,不能与图像精准对齐,Pix3D数据集中的图像与三维模型进行像素对齐,DTU数据集包含场景的二维图像、深度图及点云模型,NYU depth数据集和KITTI数据集包含二维图像和深度图,数据集的具体信息如表2所示。
表2 图像三维重建数据集总结
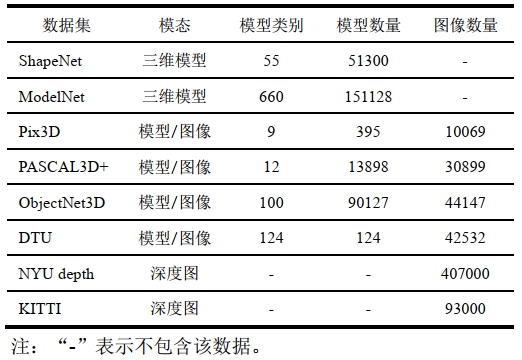
ShapeNet数据集是三维重建领域的常用数据集,由Chang等人(2015)构建,收集了大量三维模型并对三维模型添加相应的对齐、部位分割和尺寸等注释。ShapeNet数据集包含55个类别的51300个三维模型。大多数三维重建方法使用由13个类别的44000个模型组成的ShapeNet数据集的子集,数据集中的二维图像由三维模型渲染合成。ModelNet数据集由Wu等人(2015)创建,收集了660个类别的151128个三维模型。Pix3D数据集由Sun等人(2018)构建,包含9个类别的395个三维模型和10069张真实图像,每个三维模型都与一组真实图像相关联,三维模型和图像中的轮廓进行了像素对齐,具有精确的三维注释信息。DTU数据集由Aanæs等人(2016)构建,包含124个不同场景,每个场景具有相应的点云模型和49个视角的7种亮度的二维图像及对应的深度图。PASCAL 3D+数据集和ObjectNet3D数据集为三维物体识别数据集,也可应用于三维重建领域。PASCAL 3D+数据集(Xiang等, 2014)采用PascalVOC2012数据集中的12个类别的刚性物体。数据集中的基准三维模型使用二维图像中同类物体的三维模型进行配准,并从ImageNe数据集中为每个类别的三维模型匹配更多的图像。ObjectNet3D数据集由Xiang等人(2016)构建,通过对齐将ImageNet数据集中的二维图像和ShapeNet数据集中的三维模型进行匹配,为二维图像提供三维姿态标注和三维形状标注ObjectNet3D数据集共包含100个类别的90127个图像和44147个三维模型。
NYU Depth数据集由Silberman等人(2012)构建,包含464个室内场景中的407000张图像及对应深度图。KITTI数据集由Geiger等人(2012)构建,包含室外场景的93000张二维图像及对应深度图。
3.2 三维重建的实验对比
为了验证不同算法在ShapeNet数据集上的性能,本文总结了8种单张图像三维重建算法和8种多张图像三维重建算法,使用倒角距离(CD)、F1分数(F1-score,F1)、交并比(IoU)作为评测指标进行对比。CD是三维模型之间的平均最短距离,具体为
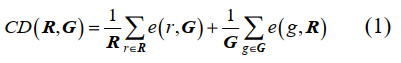
式中, R和G表示重建模型和基准模型, r和g分别表示R和G中的任意一点,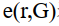 表示r到G的最短距离,
表示r到G的最短距离,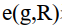 表示g到R的最短距离。
表示g到R的最短距离。
F1分数考虑精确率和召回率的标准,具体为

式中, P和R分别表示精确率和召回率。
IoU是重建模型R和基准模型G之间的交集区域与并集区域的比值,具体为
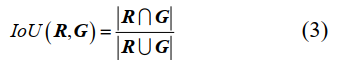
单张图像三维重建方法在ShapeNet数据集上的具体结果如表3所示。
表3 ShapeNet 数据集上单张图像实验对比
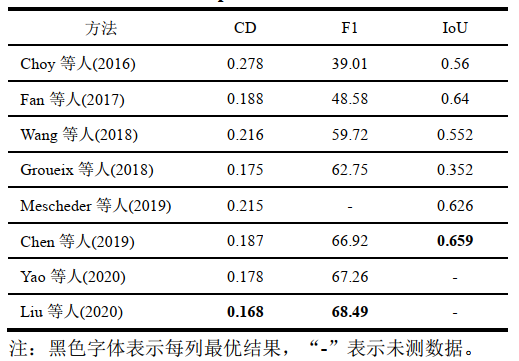
由表3可知,在CD和F1分数指标上,Choy等人(2016)方法表现最差,之后的算法的性能逐步提升,Chen等人(2019)方法和Yao等人(2020)方法的性能表现相当,Liu等人(2020)方法表现最佳。Choy等人(2016)方法和Fan等人(2017)方法的表现主要受输出形式的影响,Choy等人(2016)方法的输出为体素模型,重建体素模型的内存需求较大,因此输出的分辨率较低,性能表现不佳,Fan等人(2017)方法的输出为点云模型,点云模型中的点是离散的,不能完整地表示三维模型,因此在F1分数指标上的性能较差。Wang等人(2018)方法通过对椭球体进行变形来获取网格模型,网格模型可以完整地表示物体表面,因此在CD指标上的数值大于之前的方法在CD指标上的数值,但对物体的孔洞和细小部位的重建效果较差,在IoU指标上的性能较差。Chen等人(2019)方法和Yao等人(2020)方法分别通过构建隐式函数和估计深度、表面法向的方式提升了网格模型重建的性能,Liu等人(2020)方法通过同时预测分类、形状和光照的方式达到了最佳性能。多张图像实验在ShapeNet数据集上的结果如表4所示。
表4 ShapeNet 数据集上多张图像实验对比
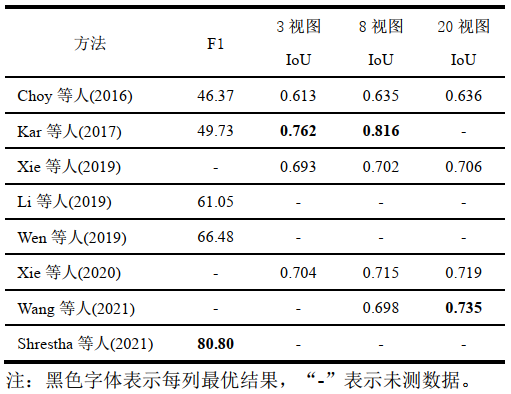
由表4可知,Choy等人(2016)方法的性能表现最差,在F1指标上Shrestha等人(2021)方法表现最佳,在IoU指标上Kar等人(2017)方法表现最佳。Choy等人(2016)方法基于RNN网络依次处理图像,不能充分利用多张输入图像之间的特征来细化三维模型,因此在F1指标上表现最差,Shrestha等人(2021)方法较之前的方法提高了21.5%~74.2%,主要是因为利用多视角立体网络估计多张图像的深度图并使用图神经网络对粗糙网格模型进行优化。Kar等人(2017)方法在IoU指标上表现最好,主要是因为该方法将多张图像和相机参数作为输入,利用相机参数确定多张图像之间的相对位置,更加充分地利用了多张图像的特征。在无需相机参数的方法中,Xie等人(2020)方法利用上下文感知模块融合多张图像重建的三维模型,提升了性能,Wang等人(2021)方法利用Transformer处理长距离依赖关系,在图像较多时达到了最佳性能。
04 讨论与展望
随着技术的发展,使用深度学习技术的图像三维重建取得了一定的成果,但图像三维重建领域仍面临着许多的问题与挑战。本节介绍当前图像三维重建领域中的待解决的问题以及未来的研究方向。
1)三维重建方法的泛化能力
三维重建的目标是从任意图像重建物体的三维模型,但目前的大多数方法只在与数据集中图像类似的图像上表现良好,在数据集中未包含类别的物体或图像较少的物体的表现不佳,人体和人脸等特定对象的三维重建方法在未训练的数据集上的重建效果相对较差,因此三维重建方法的泛化能力是一个亟待解决的问题。
2)三维重建的精细度
当前的三维重建方法重建的三维模型较粗糙,对细节的重建效果较差,三维重建方法的精细度有待进一步提高,继续提高三维重建方法的精细度是图像三维重建领域的重点研究方向。
3)三维重建与分割识别任务相结合
目前的数据集的图像大多数是无背景的单个物体图像,而真实的图像往往更加复杂,因此三维重建需要与分割识别进一步相结合,对复杂图像中待重建物体进行语义分割或识别,更加高效地进行重建。在特定物体的重建方法中,人体三维重建方法首先进行语义分割或人体姿态识别,人脸三维重建方法可与人脸属性识别相结合。三维重建与分割识别相结合是深度学习背景下的图像三维重建技术发展中的一个重要方向,同时也是提高图像三维重建的精细度的重要方法。
4)三维模型的纹理映射
早期的图像三维重建方法只能重建物体的三维形状,近期的图像三维重建方法可在重建物体形状后进行纹理映射,通过预测三维模型网格顶点的颜色或建立纹理贴图来获取具有颜色纹理的三维模型,但目前的方法对细节部位的纹理映射的效果较差,三维模型的纹理映射方法有待进一步发展。
5)三维重建的评测体系
三维重建的评测体系需进行进一步完善,一些三维重建的评测指标仅适用于特定任务,如IoU适用于体素模型的评测,而F1分数在不同方法所使用的距离阈值不同的情况下无法进行比较。此外,目前的大多数三维重建算法只对物体重建的形状进行评测而忽略了纹理信息,三维重建中纹理的评测指标也限制了三维模型的纹理映射的发展,因此未来需要继续探索统一高效的三维重建的评测体系。
05 总结
三维重建技术受到广泛关注,成为当前的研究热点,得益于三维模型的大量出现以及计算机视觉技术的广泛应用。人工建立三维模型的时间成本较高,深度学习背景下的图像三维重建技术具有较高的研究价值。
本文主要对近年来深度学习背景下的图像三维重建的分类和研究现状进行总结,整体分为六个部分:引言、单张图像三维重建、多张图像三维重建、数据集与实验对比、讨论与展望、总结。本文旨在为三维重建领域的研究人员提供有价值的参考,促进三维重建领域的进一步发展。
审核编辑 :李倩
-
三维模型
+关注
关注
0文章
52浏览量
13177 -
深度学习
+关注
关注
73文章
5526浏览量
121824
原文标题:深度学习背景下的图像三维重建技术进展综述
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
使用DLP LightCrafter4500投影结构光进行三维重建遇到的疑问求解
请问DLP LightCrafter 3000在hdmi模式下如何关闭gamma?
TIDA-00254设计demo中的三维重建的深度值是平行于投影仪光轴还是基线?
三维测量在医疗领域的应用
CASAIM与东北大学达成合作,三维扫描技术助力异形建材模型重建及尺寸精准分析

CASAIM与迈普医学达成合作,三维扫描技术助力医疗辅具实现高精度三维建模和偏差比对
建筑物边缘感知和边缘融合的多视图立体三维重建方法

三维可视化技术的应用现状和发展前景
留形科技借助NVIDIA平台提供高效精确的三维重建解决方案
基于大模型的仿真系统研究一——三维重建大模型
激光距离选通三维成像技术研究进展综述

三维扫描与3D打印在法医头骨重建中的突破性应用
常用的RGB-D SLAM解决方案
泰来三维|文物三维扫描,文物三维模型怎样制作






 工商网监
工商网监
评论