 在需要隔离式SPI的应用中最大限度地提高性能和集成度
在需要隔离式SPI的应用中最大限度地提高性能和集成度
SPI是一种非常有用且灵活的标准,但其灵活性源于其简单性。四个单向中速隔离通道将处理SPI至几MHz的时钟速率。设计人员放弃的是中断服务支持和直接通信通道(如复位功能)或来自未启用SPI功能的警报等功能。结果是,使用 SPI 的实际接口经常有额外的 GPIO 线路并行运行来处理这些功能。当SPI被隔离时,所有这些线路都需要隔离。在许多情况下,额外的通信不需要高速,因此设计人员会选择批准的器件清单,将几个光耦合器放在SPI所需的高速数字隔离器旁边。但光耦合器的设计并不像数字隔离器那么简单,尤其是简单的低速光耦合器。可能需要一门关于光耦合器CTR(电流传输比)如何随时间和温度变化以及它如何影响应用中速度的速成课程。如果额外的通信在多个方向上,则需要多个封装,因为如果是多通道器件,光耦合器通道必须在同一方向上传输数据。随着设计的制定,尺寸、成本和投入的时间会迅速增加。
采用基于i耦合器的数字隔离器的隔离式SPI®
SPI总线使用四个高速数字或光隔离通道可轻松隔离。四通道数字隔离器能够以紧凑的外形实现隔离,同时通常支持5 MHz至10 MHz SPI时钟速率。无论是基于集成微变压器、电容器还是光耦合器,信号都需要跨越隔离栅传输。在当前的隔离技术中,存在两种主要的编码方案来耦合输入信号:边沿编码和电平编码。电平编码方案允许较低的传播延迟隔离器,并且通常消耗较高的空闲功率,并且具有较差的时序性能(抖动和PWD)。另一方面,边缘编码方案具有更低的功耗和更好的时序性能。但是,许多基于边缘的实现具有更长的传播延迟,这会限制SPI总线中的时钟速度。我们将探索消除这种限制并允许隔离非常高性能SPI总线的技术。
在边沿编码方案中,输入数字转换跨越隔离栅进行编码。然后通过解码这些转换在输出侧再现数字输入。图1中的示例波形(A型)显示了如何对输入边沿进行差分编码。上升和下降输入转换分别编码为窄正脉冲和负脉冲。
只要数字输入在切换,这种信号传输就可以正常工作,但如果发生输入到输出的直流电平不匹配,除非得到纠正,否则它们可能会持续存在。这在上电期间数据通道空闲时最为明显;没有任何东西跨越隔离栅传输输入引脚的直流状态,在传输边沿之前,启动状态可能与输入数据不匹配。为了解决这个问题,边缘编码方案采用某种形式的“刷新”电路来确保输出端的直流正确性。刷新通过在预设持续时间(T刷新) 的输入不活动。图1还显示了边缘编码方案示例(B型波形)中的刷新。

图1.跨越隔离栅的编码波形示例。A型和B型分别是带有和不带刷新信号的编码波形。
在波形中,即使输入信号没有在上升沿和下降沿之间转换,也会跨越势垒传输多个编码的上升转换,以刷新接收器状态并确保其处于高电平状态。很容易看出,除了确保上电时正确的输出状态外,刷新电路还有助于在输出状态损坏并与输入状态不同步时纠正输出状态。该方案消耗空闲功率,因为编码数据不断传输。
由于边缘编码方案中需要刷新,因此了解此方案中固有的时序影响非常有用。从图1中的波形可以看出,输入转换和刷新信号都通过同一隔离通道传输,但在时间上是分开的。由于输入信号与内部刷新发生电路完全异步;输入转换可能会在传输上一个转换的刷新的同时发生。这可能导致接收器的定时问题,从而导致逻辑错误。为了避免这种时序冲突误差,刷新电路需要在信号路径中添加一些“前瞻”延迟。延迟可确保跨越屏障的编码信号之间的最小间隔,因此允许接收器明确解码任何编码传输序列。缺点是这种延迟会显著增加隔离器的传播延迟,从而限制其随着速度的增加满足SPI时序约束的能力。
幸运的是,可以解决此限制。如果输入转换和刷新状态在不同的隔离元件上传输,然后在输出端合并,则无需任何前瞻延迟及其伴随的时序损失。将这一想法扩展到多通道隔离器,所有通道的刷新状态可以在单个隔离通道上进行时间复用,然后解复用并与各自的输出合并。基本上,输入状态被采样、打包并跨越隔离栅串行传输。接收器跟踪输入直流状态,然后根据输入保持非活动状态的时间,在使用直流状态或上次输入转换之间进行仲裁以更新输出。只需一个额外的数字隔离器通道即可承载所有刷新状态,我们可以将所有输入通道从前瞻延迟中解放出来,让它们只携带输入开关信息,从而显著改善传播延迟。图 2 说明了这一想法。
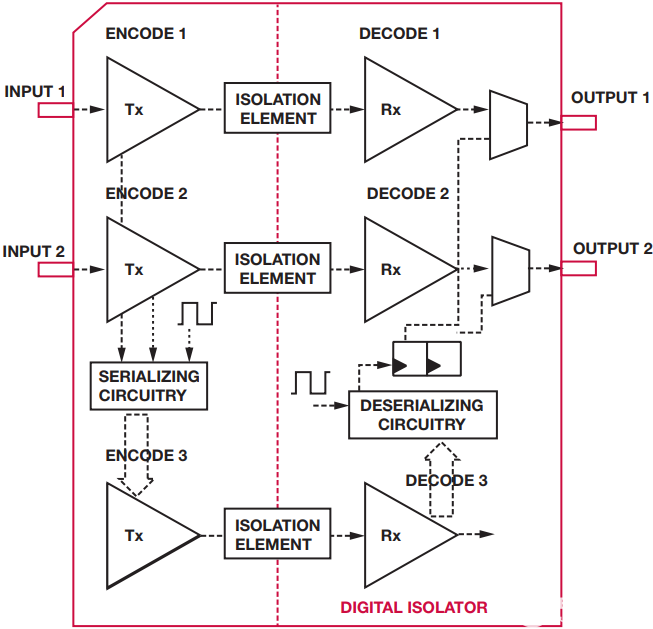
图2.带有专用第三隔离通道的框图,承载输入1和2的时间复用刷新。
ADI公司的SPIsolator系列高速数字隔离器采用该方案在SPI通道上实现极低的传播延迟,从而实现高达17 MHz的高带宽隔离SPI总线实现。额外的隔离器通道携带刷新信息,并用于传输各种其他低吞吐量信号,方法是将数据复用为在隔离中来回传输的数据包。这实现了除SPI串行数据位之外的其他通信,从而实现了多功能但高度集成的隔离式SPI总线。®
带辅助数据通道的 SPI
某些版本的SPIsolator产品系列在多路复用刷新通道上捆绑了三个250 kbps辅助(AUX)数字通道。三种不同的产品变体允许为这些辅助通道进行多通道方向配置。即使辅助通道是异步的,它们也会在通过单个隔离通道传输之前进行采样和分组。根据通道输入相对于内部采样时钟的切换时间,这些辅助通道的传播延迟最多可以变化2.6 μs。异步辅助信号的采样和序列化也会将它们同步到内部采样时钟。如果慢速信号之间的精确时序很重要,这可能会导致时序问题,特别是对于1.2 μs或更短时间窗口内的精度。幸运的是,典型SPI总线周围的辅助信号很少需要彼此之间如此精确的时序关系。更重要的是,这种低速数据系统经过精心设计,只要边沿之间至少间隔最小偏斜(V伊克斯库).换言之,如果一个边沿在输入端领先于另一个边沿,则隔离器不会颠倒顺序。
通用 SPI 接口示例
在图3中,我们可以看到一个典型的SPI应用,需要一个1 MHz SCLK、4线SPI和三个额外的信号,用于中断、电源良好和复位。低速通道可能只需要40 μs的prop延迟。选择这些参数是为了允许检查所有组件选项。时序完全在所有主要隔离器类型的能力范围内,因此我们可以比较集成对解决方案尺寸和成本的影响,而与性能无关。以下是一些实现选项:
使用所有光耦合器
SPI使用数字隔离器,慢信号通道使用光耦合器
使用完全集成的数字隔离器,如ADI SPI隔离器
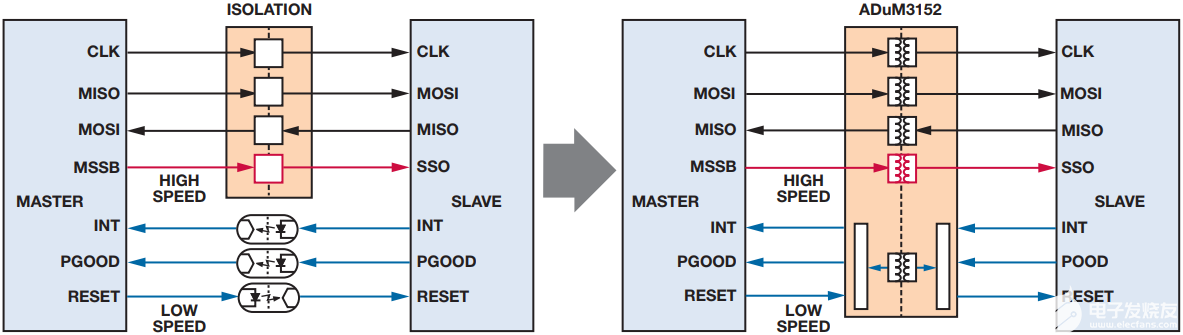
图3.典型的SPI应用,具有通过多种技术实现的补充功能。
示意性地,解决方案看起来并没有太大的不同。但是,如果我们看一下图4,我们可以看到IC在PCB上的布局。红框大致表示隔离元件所需的面积,并为所需的无源元件留出空间。
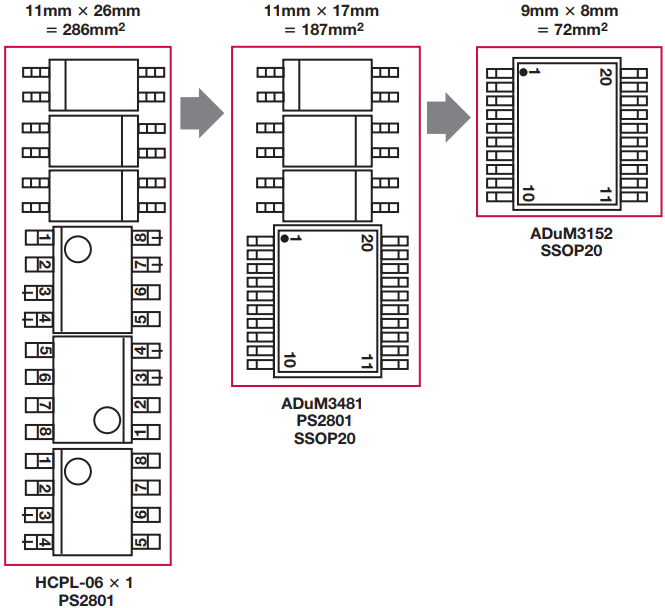
图4.典型的SPI应用,具有光耦合器实现的补充功能。
从混合速度光耦合器解决方案作为基准开始,许多设计人员将考虑将标准数字隔离器与非常便宜的光耦合器相结合,认为这是实现低速信号的最经济有效的方法。解决方案之间的面积差异很大程度上是因为数字隔离器允许在单个封装内混合通道方向,从而避免了大量的封装开销。混合技术解决方案可能具有成本效益,但会给设计带来额外的损失和稳定性问题。廉价的光耦合器速度慢,而且由于简单,需要一些思考和研究才能构建成功的设计。必须注意确保它们在时间和温度下保持稳定,同时最大限度地降低功耗。
从光耦合器解决方案到完全集成的解决方案(如ADI ADuM3152 SPI隔离器)的面积减少了近75%。
SPI隔离器中的集成解决方案具有通道间速度差和脉冲阶反转的内置保护功能,无设计开销,也无需额外的电路板空间。集成解决方案中提供的低速通道还支持明显高于单晶体管光耦合器的数据速率。该集成解决方案的成本远低于光耦合器解决方案的一半,并且以比分立式光耦合器更低的单位通道成本提供低速通道。考虑到SPI性能,ADuM3152数字隔离解决方案可以支持时钟速率高达17 MHz的SPI,因为传播延迟非常短,而光耦合器“快速”通道可以以合理的成本工作到3 MHz。
解复用SSB以控制多达4个从站
在ADuM3154产品变体中,使用250 kbps、低速、2通道地址总线来控制隔离式从机选择地址线(SSx),允许在短短2.6 μs内更改目标从器件。图6显示了使用通用隔离器和ADuM3154的实现方案。图 5 显示了如何更改地址位 (SSAx) 时的 SSx 转换。
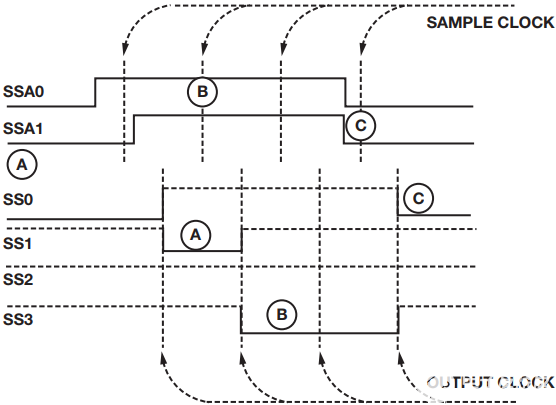
图6.典型的多从SPI应用。
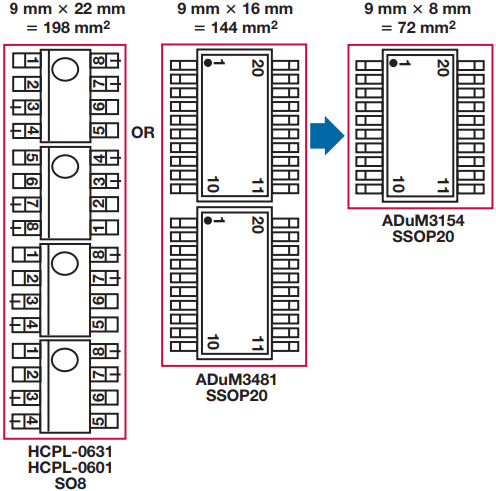
图7.典型的SPI应用,具有光耦合器实现的补充功能。
ADuM3154使用2位地址总线将主从选择(MSS)路由至四个从机之一。这些地址总线位是低速信号,再次与常规四个高速SPI通道的刷新状态捆绑在一起。与刷新状态一样,地址位都经过采样、打包并通过隔离栅串行传输。在从机端,数据包被反序列化,地址位用于解复用MSS。 根据地址总线相对于内部采样时钟的切换时间,解复用器在2.6 μs内将MSS信号路由到所需的从机。地址位是总线的一部分,必须彼此同步。在采样和序列化过程中要特别注意,以确保这些地址位在输出端保持同步,特别是在从一个选定的从站转换到另一个从站期间。
多从SPI接口示例
常见的SPI设计要求是与共享同一SPI总线的多个从器件通信。这可以通过几种方式完成。如果数据将同时从所有次级侧设备采样,并且所有数据每帧传输一次,那么最简单的方法是将部件菊花链连接在一起,并通过单个隔离端口串行移出链的全部内容。但是,当数据采集顺序不固定时,必须单独对每个SPI从站进行寻址。这给隔离接口带来了特殊的挑战。
如果必须单独寻址每个从站,则每个设备必须具有单独的从站选择线。在许多情况下,从机选择不仅为SPI通信选择特定目标,而且还在ADC中启动转换,因此该线路还必须具有高精度的时序。在许多实现中,这需要一个与时钟通道速度相当的额外隔离通道,以保持时序。4通道隔离式SPI设计如图6所示,其中标准的4个高速隔离通道增加了3个额外的高速隔离通道。
另一种从站选择方法如图6的右侧所示。副边使用多路复用器,低速隔离选择线路可用于选择目的地。必须小心切换多路复用器控制线,以便在时序有点偏差时,它们不会跳到不正确的中间状态。该方案通过SPI隔离器器件中提供的低速通道实现,并且由于应用定义明确,因此可以内置不确定状态的保护措施,以防止小的时序误差产生瞬态输出状态。
归根结底,当任何技术都可以支持性能时,最佳设计选择归结为易于实施、尺寸和成本。图 7 显示了三种可能的实现方式。从左到右是使用七个隔离通道的简单光耦合器解决方案,接下来是使用数字隔离器的相同方案,最后是SPI隔离器的集成多路复用器功能。光耦合器解决方案是最大的,而数字隔离器是其72%,SPI隔离器仅占用36%的PCB空间。这三种解决方案的成本比例相似,SPIsolator方法明显低于替代方案。
结论
在设计高性能隔离式SPI解决方案时,SPI隔离器产品系列使用多路复用控制通道支持具有极低传播延迟的高速SPI,并最大限度地提高辅助功能的集成度。SPI通道与补充功能的组合可以方便地设计高度集成的隔离式SPI总线,同时减少设计时间、成本和电路板空间。
审核编辑:郭婷
-
SPI
+关注
关注
17文章
1706浏览量
91551 -
耦合器
+关注
关注
8文章
725浏览量
59705 -
隔离器
+关注
关注
4文章
773浏览量
38327
发布评论请先 登录
相关推荐
在要求隔离SPI的应用中最大化性能和集成度
反激式拓扑中最大限度降低空载待机功耗的参考设计
在需要隔离式SPI的应用中最大限度地提高性能和集成度

在需要隔离式SPI的应用中最大限度地提高性能和集成度
最大限度地提高数据库效率和性能VMware环境使用32G NVMe光纤渠道

最大限度地提高GSPS ADC中的SFDR性能:杂散源和Mitigat方法





 工商网监
工商网监
评论