 一种显著降低Transformer计算量的轻量化方法
一种显著降低Transformer计算量的轻量化方法
导读
这项工作旨在提高视觉Transformer(ViT)的效率。虽然ViT在每一层中使用计算代价高昂的自注意力操作,但我们发现这些操作在层之间高度相关——这会导致产生很多不必要计算的冗余信息。基于这一观察,我们提出了SKIPAT方法,该方法利用前面层的自注意力计算来近似在一个或多个后续层的注意力。为了确保在层之间重用自注意力块而不降低性能,我们引入了一个简单的参数函数,该函数在计算速度更快的情况下能表现出优于基准Transformer的性能。我们在图像分类和ImageNet-1K上的自我监督学习、ADE20K上的语义分割、SIDD上的图像去噪以及DAVIS上的视频去噪中展示了我们方法的有效性。我们在所有这些任务中都在相同或更高的准确度水平下实现了提高模型吞吐量。
背景

Performance of SKIPAT across 5 different tasks.
Transformer架构已经成为一个重要且影响深远的模型系列,因为它简单、可扩展,并且应用广泛。虽然最初来自自然语言处理(NLP)领域,但随着视觉transformer(ViT)的出现,这已成为计算机视觉领域的标准架构,在从表示学习、语义分割、目标检测到视频理解等任务中获得了各种最先进(SoTA)性能。
然而,transformer的原始公式在输入令牌(token)数量方面具有二次计算复杂度。鉴于这个数字通常从图像分类的14^2到图像去噪的128^2 = 16K不等,内存和计算的这一限制严重限制了它的适用性。目前有三组方法来解决这个问题:第一组利用输入令牌之间的冗余,并通过高效的抽样简单地减少计算,例如丢弃或合并冗余令牌。然而,这意味着ViT的最终输出不是空间连续的,因此不能超出图像级别(image-level)的应用,如语义分割或目标检测。第二组方法旨在以低成本计算近似注意力,但通常以性能降低为代价。最后,另一组工作旨在将卷积架构与transformer合并,产生混合架构。虽然这些方法提高了速度,但它们并没有解决二次复杂度的基本问题,并且通常会引入过多的设计选择(基本上是transformer和CNN的联合)。
在这项工作中,我们提出了一种新颖的、迄今为止未经探索的方法:利用计算速度快且简单的参数函数来逼近transformer的计算代价高的块。为了得出这个解决方案,我们首先详细地分析了ViT的关键多头自注意力(MSA)块。通过这项分析,我们发现CLS令牌对空间块的注意力在transformer的块之间具有非常高的相关性,从而导致许多不必要的计算。这启发了我们的方法利用模型早期的注意力,并将其简单地重用于更深的块——基本上是“跳过”后续的SA计算,而不是在每一层重新计算它们。
基于此,我们进一步探索是否可以通过重用前面层的表示来跳过整一层的MSA块。受ResneXt的深度卷积的启发,我们发现一个简单的参数函数可以优于基准模型性能——在吞吐量和FLOPs的计算速度方面更快。我们的方法是通用的,可以应用于任何上下文的ViT:上图显示,我们的跳过注意力(SKIPAT)的新型参数函数在各种任务、数据集和模型大小上都能实现与基准transformer相比更优的精度与效率。
综上所述,我们的贡献如下所示:
我们提出了一种新型的插件模块,可以放在任何ViT架构中,以减少昂贵的O(n^2)自注意力计算复杂度。
我们在ImageNet、Pascal-VOC2012、SIDD、DAVIS和ADE20K数据集上实现了在吞吐量指标上的最SOTA性能,并获得了同等或更高的准确度。
我们的方法在没有下游准确度损失的情况下,自监督预训练时间能减少26%,并且在移动设备上展示了优越的延迟,这都证明了我们方法的普适性。
我们分析了性能提升的来源,并对我们的方法进行了大量的实验分析,为提供可用于权衡准确度和吞吐量的模型系列提供了支持。
方法

SKIPAT framework.
引言
Vision Transformer
设x ∈ R^(h×w×c) 为一张输入图像,其中h × w是空间分辨率,c是通道数。首先将图像分成n = hw/p^2个不重叠的块,其中p × p是块大小。使用线性层将每个块投影到一个embedding zi ∈ R^d 中,从而得到分块的图像:

Transformer Layer
Transformer的每一层由多头自注意力(MSA)块和多层感知机(MLP)块组成。在MSA块中,Zl−1 ∈ R^(n×d),首先被投影到三个可学习embeddings {Q, K, V } ∈ R^(n×d)中。注意力矩阵A的计算公式如下:
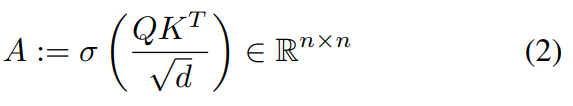
MSA中的“多头”是指考虑h个注意力头,其中每个头是一个n × d/h 矩阵的序列。使用线性层将注意头重新投影回n × d,并与值矩阵结合,公式如下所示:
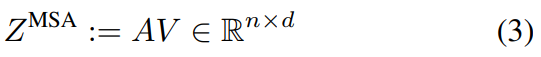
然后,将MSA块的输出表示输入到MLP块,该块包括两个由GeLU激活分隔的线性层。在给定层l处,表示通过transformer块的计算流程如下:

MSA和MLP块都具有带层正则化(LN)的残差连接。虽然transformer的每一层中的MSA块均是学习互不依赖的表示,但在下一小节中,我们将展示这些跨层间存在高度相关性。
启发: 层相关性分析
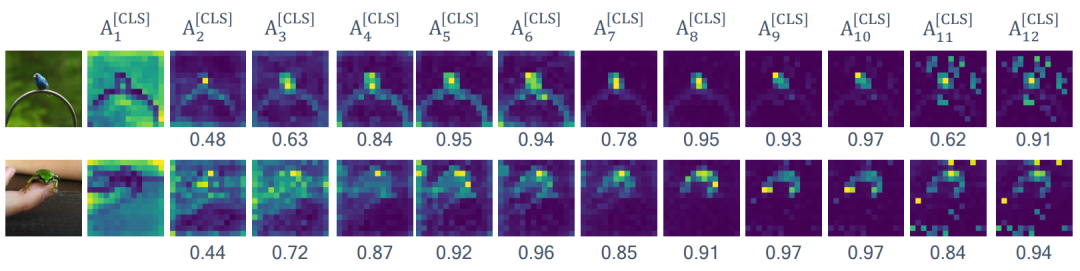
Attention correlation.
ViT中的MSA块将每个块与每个其他块的相似性编码为n × n注意力矩阵。这个运算符具有O(n^2)复杂度(公式2)的计算成本。随着ViT的扩展,即随着n的增加,计算复杂度呈二次增长,使得这个操作成为性能瓶颈。最近的NLP工作表明,SoTA语言模型中相邻层之间的自注意力具有非常高的相关性。这引发了一个问题 -在视觉transformer是否真的需要每一层都计算自注意力?

CKA analysis of A^[CLS] and Z^MSA across different layers of pretrained ViT-T/16.
为了回答这个问题,我们分析了ViT不同层之间自注意力图的相关性。如本节图1所示,来自类别token的自注意力图A^[CLS]在中间层特别具有高度相关性。A^[CLS]l−1和A^[CLS]l 之间的余弦相似度可以高达0.97。其他token embeddings 也表现出类似的行为。我们通过计算每对i,j∈L的A^[CLS]i和A^[CLS]j之间的Centered Kernel Alignment(CKA)来定量分析ImageNet-1K验证集的所有样本之间的相关性。CKA度量网络中间层获得的表示之间的相似性,其中CKA的值越高则表示它们之间的相关性越高。从本节图2中,我们发现ViT-T在A^[CLS]之间具有高度性,特别是第三层到第十层。
Feature correlation
在ViT中,高相关性不仅局限于A^[CLS],MSA块的表示Z^MSA也在整个模型中显示出高度相关性。为了分析这些表示之间的相似性,我们计算每对i,j∈L的Z^MSAi和Z^MSAj之间的CKA。我们从从本节图2中观察到,Z^MSA在模型的相邻层之间也具有很高的相似性,特别是在较早的层,即从第2层到第8层。
利用 Skipping Attention 提升效率
基于我们对transformer中MSA不同块之间具有高度相似性的观察,我们建议利用注意力矩阵和MSA块的表示之间的相关性来提高视觉transformer的效率。与在每层单独计算MSA操作(公式3)相反,我们探索了一种利用不同层之间依赖关系的简单且有效的策略。
我们建议通过重用其相邻层的特征表示来跳过transformer的一个或多个层中的MSA计算。我们将此操作称为Skip Attention(SKIPAT)。由于跳过整个MSA块的计算和内存效益大于仅跳过自注意力操作 O(n^2d+nd^2) vs. O(n^2d),因此在本文中我们主要关注前者。我们引入了一个参数函数,而不是直接重用特征,换句话说,就是将来源MSA块的特征复制到一个或多个相邻MSA块。参数函数确保直接重用特征不会影响这些MSA块中的平移不变性和等价性,并充当强大的正则化器以提高模型泛化性。
SKIPAT parametric function
设 Φ:R^(n×d) → R^(n×d)表示将l−1层的MSA块映射到l层的参数函数,作为Ẑ^MSA l:=Φ(Z^MSA l−1)。在这里,Ẑ^MSA l是Z^MSA l的近似值。参数函数可以是简单的单位函数,其中Z^MSA l−1能被直接重用。我们使用Z^MSA l−1作为l处的MLP块的输入,而不是在l处计算MSA操作。当使用单位函数时,由于l处没有MSA操作,因此在注意力矩阵中的token间关系不再被编码,这会影响表示学习。为了减轻这一点,我们引入了SKIPAT参数函数,用于对token之间的局部关系进行编码。SKIPAT参数函数由两个线性层和中间的深度卷积(DwC)组成,计算公式如下所示:

SKIPAT framework
SKIPAT 是一种可以被纳入任何 transformer 架构的框架,我们通过大量实验对比结果充分地证明了这一点。根据架构的不同,可以在 transformer 的一层或多层中跳过 MSA 操作。在 ViT 中,我们观察到来自 MSA 块(Z^MSA )的表示在第 2 层到第 7 层之间有很高的相关性,所以我们在这些层中使用 SKIPAT 参数函数。这意味着我们将 Z^MSA2 作为输入传递给 SKIPAT 参数函数,并在 3-8 层中跳过 MSA 操作。相反,来自 SKIPAT 参数函数输出的特征被用作 MLP 块的输入。表示的计算流现在被修改为:
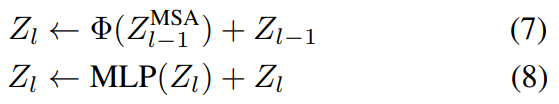
由于 MSA 和 MLP 块中存在残留连接,第 3 层到第 8 层的 MLP 块需要独立地学习表示,不能从计算图中删除。值得注意的是,使用 SKIPAT 后 ViT 的总层数不变,但 MSA 块的数量减少了。
Complexity: MSA vs. SKIPAT
自注意力操作包括三个步骤。首先,将token embeddings 投射到query、key和value embeddings,其次,计算注意力矩阵 A,它是 Q 和 K 的点积,最后,计算输出表示作为 A 和 V 的点积。这导致了计算复杂度为 O(4nd^2 + n^2d)。由于 d ≪ n,所以 MSA 块的复杂度可以降低到 O(n^2d)。
SKIPAT 参数函数由两个线性层和一个深度卷积操作组成,计算复杂度为 O(2nd^2 + r^2nd),其中 r × r 是 DwC 操作的内核大小。由于 r^2 ≪ d,所以 SKIPAT 的整体复杂度可以降低到 O(nd^2)。因此,当 n 随着 transformer 的扩大而增加时,SKIPAT 的 FLOPs值 比 MSA 块更少,即 O(nd^2) < O(n^2d)。
实验

上图展示的是分割mask的可视化效果:第一行和第二行分别是原始Vit-S模型和Vit-S + SKIPAT模型。显而易见,Vit-S + SKIPAT模型对图像中前景和背景的区分度显著高于原始Vit-S模型。
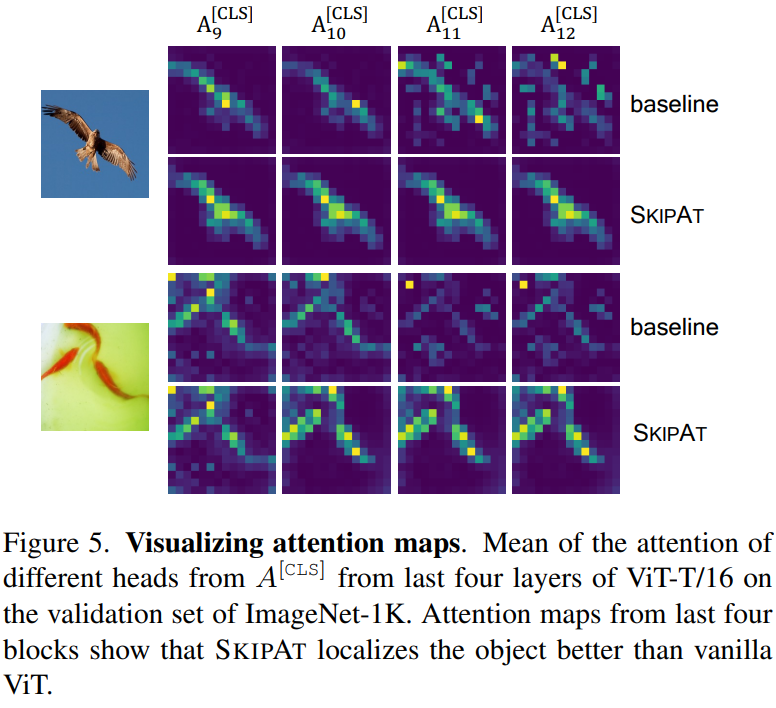
上图展示的是注意力图的可视化效果:对比原始Vit-S模型(baseline),Vit-S + SKIPAT模型对目标的定位能力有明显提升。
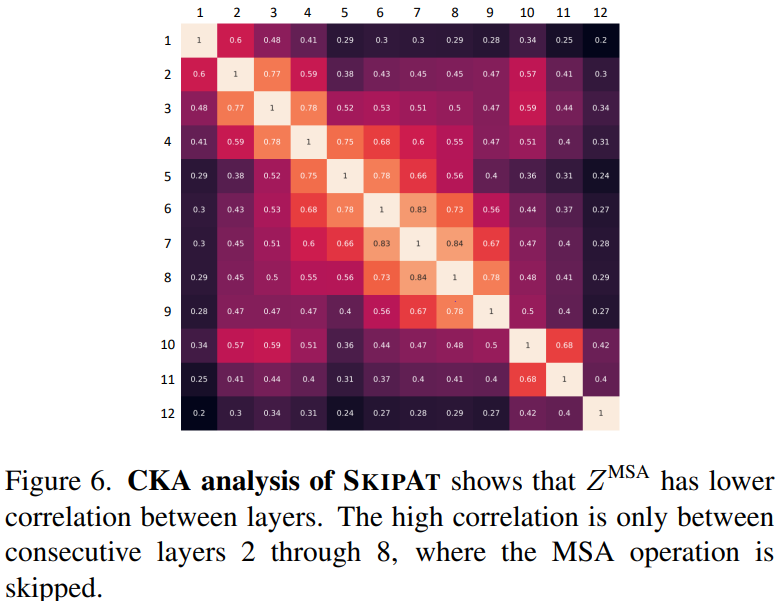
上图展示的是特征图和Z^MSA的相关性:从中可以清晰地观察到在大多数不同层之间Z^MSA仅有较低的相关性。
图象分类
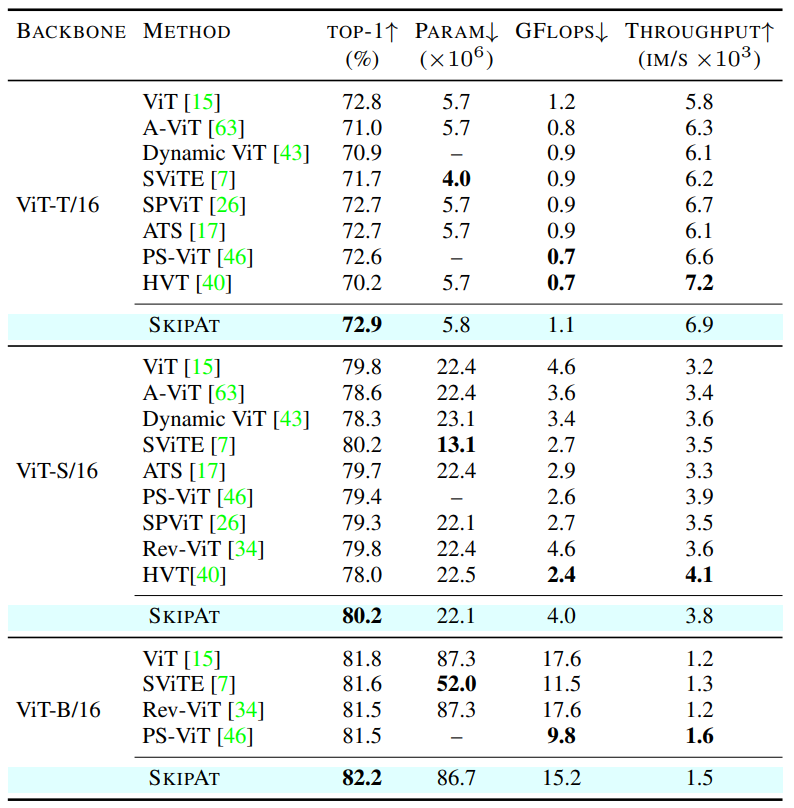
Image classification on ImageNet-1K.
自监督
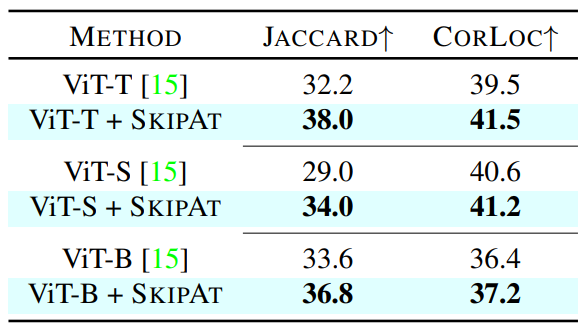
Unsupervised Segmentation and Object Localization on the validation set of Pascal VOC2012.
推理性能
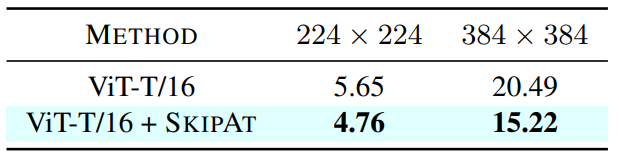
On-device latency (in msec) of vanilla ViT vs. SKIPAT.
语义分割
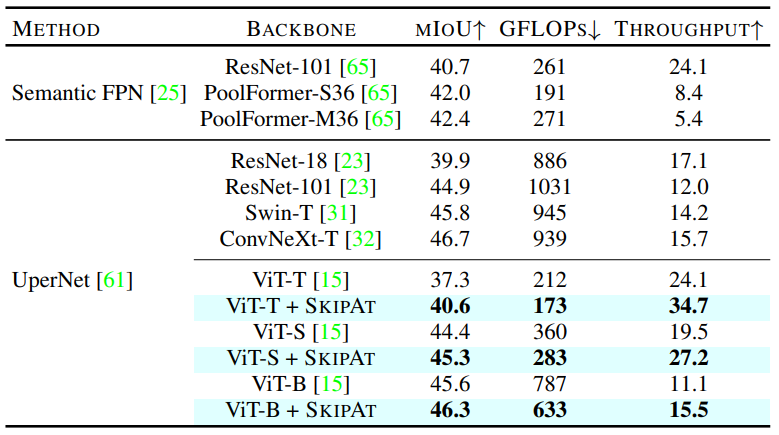
Semantic Segmentation results on ADE20K.
图像去噪
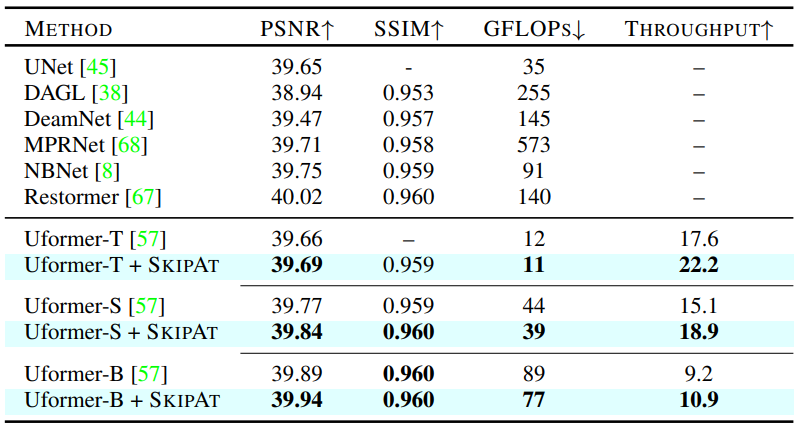
Image denoising on SIDD dataset using PSNR andSSIM as the evaluation metrics in the RGB space.
总结
我们提出了一种可以在任何 ViT 架构中即插即用的模块 SKIPAT,用于减少昂贵的自注意力计算。SKIPAT 利用 MSA 块之间的依赖性,并通过重用以前 MSA 块的注意力表示来绕过注意力计算。此外,我们引入了一个简单且轻量的参数函数,它不会影响 MSA 中编码的归纳偏见。SKIPAT 函数能够捕获跨token之间的关系,在吞吐量和 FLOPs 指标上优于基线模型,同时我们在7 种不同的任务中充分地表现出SKIPAT的有效性。
审核编辑 :李倩
-
编码
+关注
关注
6文章
942浏览量
54831 -
Transformer
+关注
关注
0文章
143浏览量
6007 -
自然语言处理
+关注
关注
1文章
618浏览量
13561
原文标题:即插即用!Skip-Attention:一种显著降低Transformer计算量的轻量化方法
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
引领轻量化趋势| 法法易轻量化充电枪通过2023版标准强检测试

守护公路安全! 中海达推出轻量化监测简易感知方案
一种信息引导的量化后LLM微调新算法IR-QLoRA

中海达推出轻量化监测简易感知解决方案
自动驾驶中一直说的BEV+Transformer到底是个啥?

5G RedCap:轻量化5G技术引领物联网新未来

5G轻量化网关是什么

轻量化IP制作与传输的变革之路-千视Judy专访

深度神经网络模型量化的基本方法
深度学习模型量化方法

Transformer能代替图神经网络吗
基于DOE的管道爬行机器人轻量化研究
基于助听器开发的一种高效的语音增强神经网络
基于esp32轻量化的PSA及Web3的组件,怎么向组件库提交component ?
RedCap轻量化5G提升生产效率,多领域应用






 工商网监
工商网监
评论