 用于3D激光雷达SLAM回环检测的实时词袋模型BoW3D
用于3D激光雷达SLAM回环检测的实时词袋模型BoW3D

0. 笔者个人体会
回环检测对于SLAM系统的全局一致性有着至关重要的影响。现有的视觉SLAM回环检测大多是基于词袋模型,也就是2012年推出的BoW2库和2017年推出的改进版本BoW3,例如ORB-SLAM2和VINS-Mono。2021年ORB-SLAM3的横空出世更是将基于词袋的回环检测/重定位推上了新高度。
但激光雷达SLAM呢?相比视觉SLAM就稍显尴尬了。Lego-LOAM是基于轨迹位姿方法的回环检测,使用KDtree寻找当前位姿的历史最近位姿,之后把历史位姿作为候选,用ICP算法修正位姿。Cartographer采用scanMatch将scan和submaps匹配,通过分支定界加快搜索,然后降低位姿残差。
当然也有一些深度学习回环方法,比如波恩大学开源的OverlapNet。但不管怎么说,激光雷达SLAM的回环检测目前还是非常简单,并且假设位姿优化结果偏移小,无法应对大尺度漂移。另一方面,现有的雷达SLAM回环方法很难去修正6自由度位姿。
中科院沈自所的崔芸阁博士近期开源的BoW3D似乎解决了这个痛点。崔博同时开源了新的点云特征描述方式Link3D以及基于Link3D的BoW3D词袋库。
2. 摘要
回环是自主移动系统同步定位与地图创建(SLAM)的一个基本部分。在视觉SLAM领域,词袋(BoW)在回环方面取得了巨大的成功。用于回环搜索的BoW特征也可用于后续的6-DoF回环校正。然而,对于3D LiDAR SLAM,现有方法可能无法实时有效地识别回环,且通常无法校正完整的6-DoF回环位姿。
为了解决这个问题,我们提出了一种用于3D LiDAR SLAM中实时闭环的词袋模型BoW3D。我们的方法不仅有效地识别了重访的回环位置,而且实时地修正了完整的6-DoF回环位姿。BoW3D基于三维LiDAR特征LinK3D构建词袋,该词袋高效、姿态不变,可用于精确的点对点匹配。
我们进一步将提出的方法嵌入到3D LiDAR里程计系统中评估闭环性能。我们在公共数据集上测试了我们的方法,并与其他先进的算法进行了比较。BoW3D在大多数场景下的F1 max和扩展精度分数表现出更好的性能。值得注意的是,BoW3D在酷睿i7@2.2 GHz处理器的笔记本上执行时,识别和纠正KITTI 00 (包括4K+64线LiDAR扫描)上的回环平均需要48 ms。
3. 视觉BoW回顾
由于崔博设计的BoW3D和视觉词袋模型BoW2/3有异曲同工之妙,因此在介绍BoW3D之前,我们先来回顾一下用于视觉回环的BoW2词袋。 视觉图像匹配往往涉及到关键点+描述子的表达方式,如果把描述子看做单词,那么就可以构建相应的词袋模型。
BoW2库是2012年由西班牙萨拉戈萨大学的López等人提出的开源软件库,它首先是通过K-means聚类得到一个深度为d的k叉树(作者设置的k=6,d=10)。在训练过程中,作者选取了1万张图片,每张图片提取100个特征,利用这100万个特征训练得到字典模型。
在实际使用时,首先计算图像的特征点和描述子。然后将描述子利用DBoW库计算得到词袋向量,向量中要么为0,表示没有这个单词,要么为单词权重,最终可以得到一个稀疏向量。比较两个图像各自的稀疏向量,可以得到相似性得分,进而确定是否检测到了回环。
视觉词袋模型有什么优点呢?
首先它场景识别速度快,可以加速特征匹配。其次它扩展性好,对多种图像特征都实用,比如ORB、SIFT。同时它依赖少,仅依赖OpenCV和Boost库。
那么它有什么缺点呢?
首先字典占用空间大,在SLAM系统运行时需要先加载一个几百兆的大字典。同时词袋模型对于重复纹理可能不是那么鲁棒。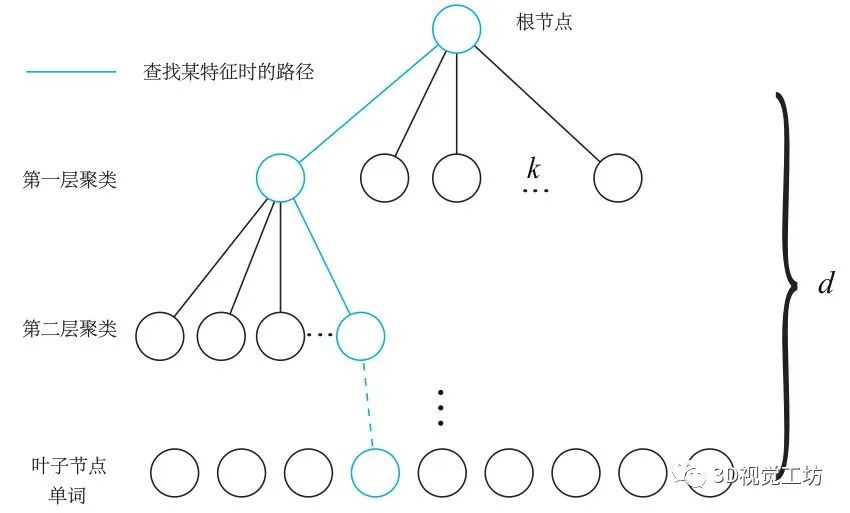
前面说到,词袋向量中存储的是单词权重。
那么这个权重值具体如何计算呢?
这里用到的就是TF-IDF。TF指的是词频,也就是说一个单词在图像中出现的频率越高,那么它区分度也就越高。这个很容易理解,比如我们在说话时如果反复提到某个词,那么这个词就是我们说话的关键词,也就越重要。词频TF是在计算图像词袋向量时实时得到的。
IDF指的是逆向文本频率,也就是说一个单词在字典中出现的频率越低,那么它区分度也就越高。逆向文本频率IDF是在字典训练阶段就已经确定。
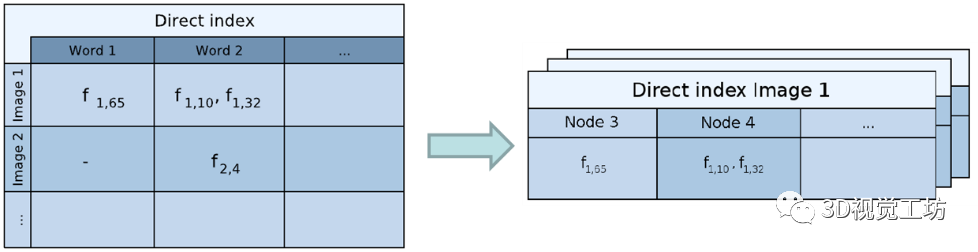
前面都是视觉词袋的知识,下面的知识就比较重要了。尤其是逆向索引,是BoW3D的核心思想之一。 词袋模型定义了正向索引(直接索引)与逆向索引。逆向索引记录单词在哪些图像中出现,以及单词的权重。如果当前帧的一个单词在以前帧中出现,那么通过逆向索引可以直接知道这个单词在哪些帧中出现过。
所以逆向索引主要进行位置识别。正向索引主要记录节点ID,以及对应特征在图像中的编号。所以正向索引主要进行加速匹配,比如ORB-SLAM的SearchByBoW函数就是利用正向索引来加速匹配。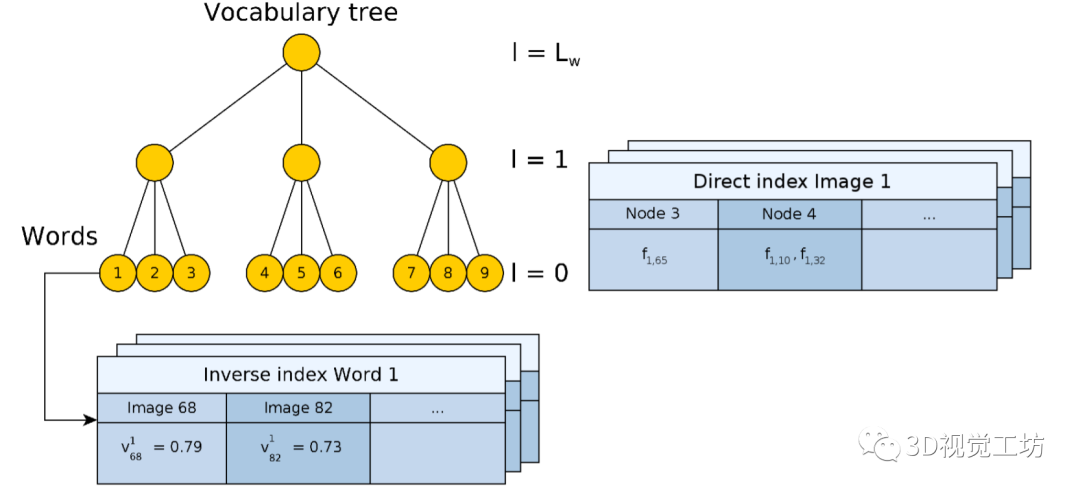
4. LinK3D
到这里就涉及到DBoW3D的核心内容了!DBoW3D是基于LinK3D特征来实现词袋模型的,所以我们首先介绍LinK3D特征。 首先放弃繁琐的公式推导与数学描述,崔博士绘制了一张生动形象的漫画来介绍LinK3D的具体原理!非常通俗易懂!
假如现在我们正处于一个街道的十字路口,如何对我们所处环境进行描述呢? 可以这样表达,我们的三点钟方向是一家医院,五点钟方向是一辆车,八点钟方向是一家超市,九点钟方向是一个红绿灯。所以,如果别人也有这样一个描述,那么我们大概率可以推断是位于同一位置!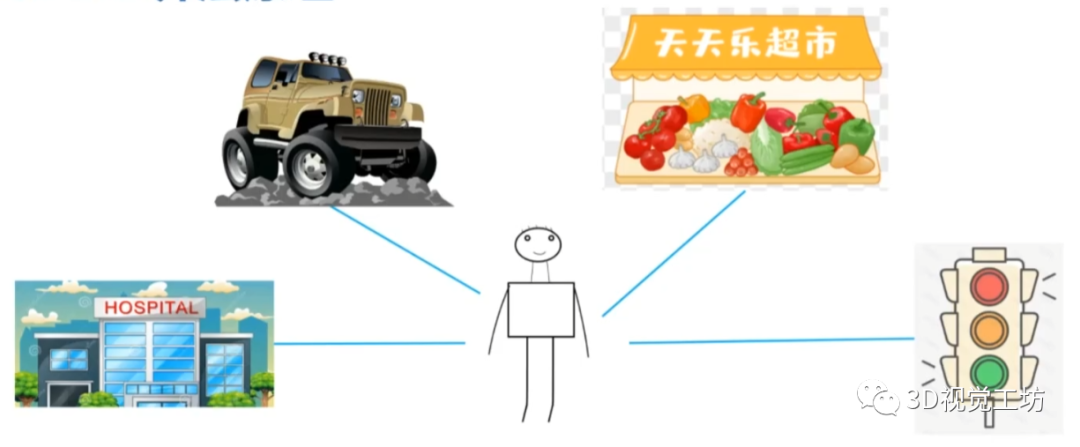
显然,计算机无法轻易理解单纯的文字描述。所以我们可以将上述位置信息进行向量化表达:
注意,实际应用过程中,很有可能会出现一种情况。也就是两个人位于同一位置,但是朝向不同。如果这时不加以任何处理的话,得到的位置向量就完全不同!而最合适的想法是,通过某种算法,将所有朝向都对齐到一个主方向!这个思想有点类似ORB特征的旋转不变性。
那么具体如何实现呢?
现在转到3D点云空间,我们希望对图中的黑色点进行描述。首先需要对黑色点所处空间进行划分,分成一个个小区域,然后利用区域中的点进行描述。对所有关键点都进行类似的描述,就可以实现精确的点到点匹配!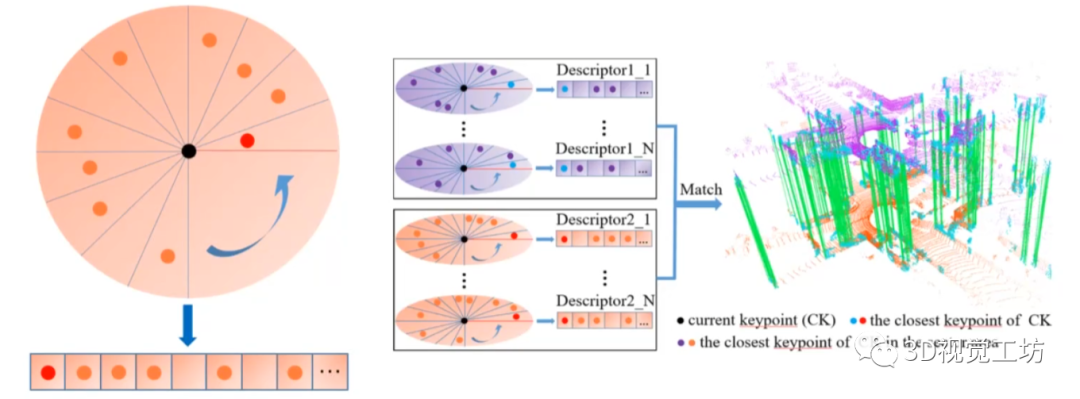
思想理解了,具体如何提取呢? 首先提取显著的边缘点,并进一步提取更鲁棒的聚合关键点。然后构建聚合关键点之间的距离表和方向表,通过查表的方式加速描述子的生成。随后,特征被有序地表示为一个向量,每一维都具有特定的含义。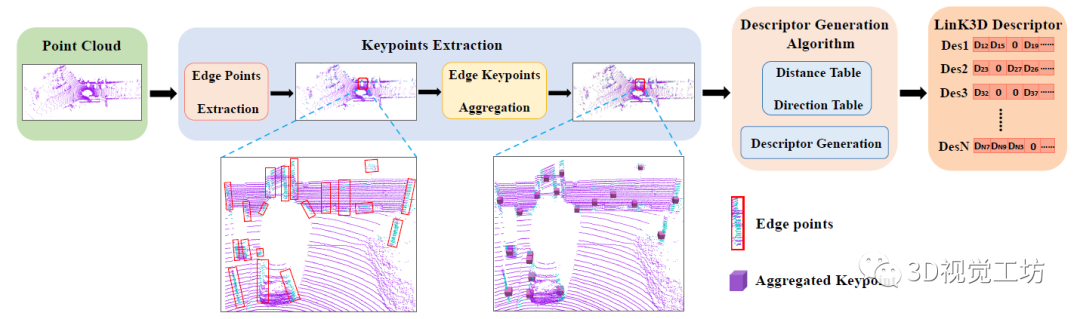
在具体提取过程中,提取到的边缘点会有两类:一类是红框中的散点,一类是蓝框中成簇状的点。显然,用散点进行描述效果较差。因为他们可能只是在这一帧出现,在下一帧可能就会消失。
如果使用散点进行描述的话会降低系统的鲁棒性。因此需要对提取到的点云进行进一步的分类,得到成簇分布的鲁棒的聚合关键点。对于任何的聚合关键点,它附近的聚合关键点就类似漫画中的超市、车这些特征。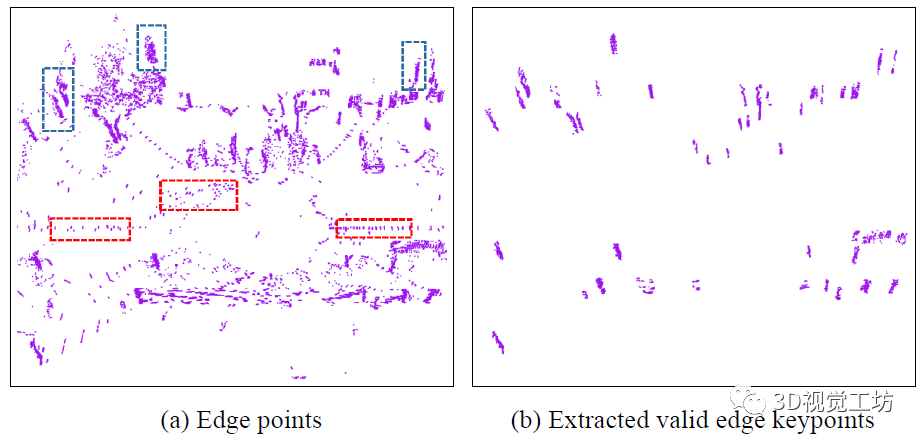
因此,LinK3D的核心思想就很明显了,就是用关键点来表征关键点! 在具体表示过程中,首先计算这些聚合关键点的均值点,并将他们投影到水平面。首先对这个平面进行划分,作者是划分成了180个区域,也就是说最后的描述子是180维的向量。然后,选择当前点到最近点的方向为主方向,也就是图中的k0到k1。
此外,还将主方向所在的区域划定为第一个区域,其他区域逆时针排列。并在每个区域中选择最近点进行描述。具体的向量值如何确定呢?每个向量的值,也就是当前点在区域中和最近点的距离,如果区域中没有最近点的话就设置为0。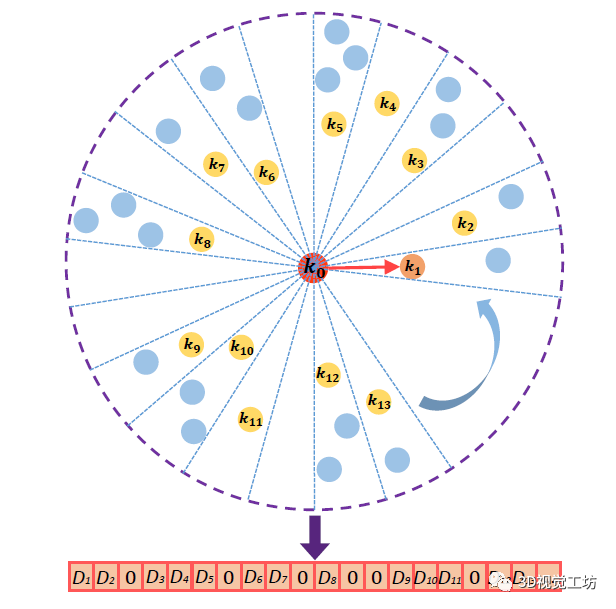
也就是说,最后得到的描述子同时包含距离信息和方向信息: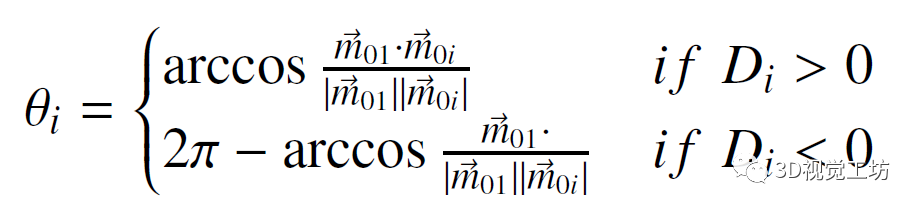
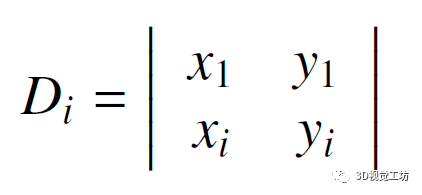
但这么做还有一个问题,就是它对最近点较为敏感。 那么怎么做呢。作者实际上是选择了3个最近点,并得到了三个描述子,根据三个点的远近确定优先级。
最终描述子是优先级最高的非零维向量。这么做还有一个好处,就是它对于动态物体非常的鲁棒!比如其中一个是动态点,另外两个就可以弥补这一方面。这个巧妙的设计实际上实现了非常大的性能提升。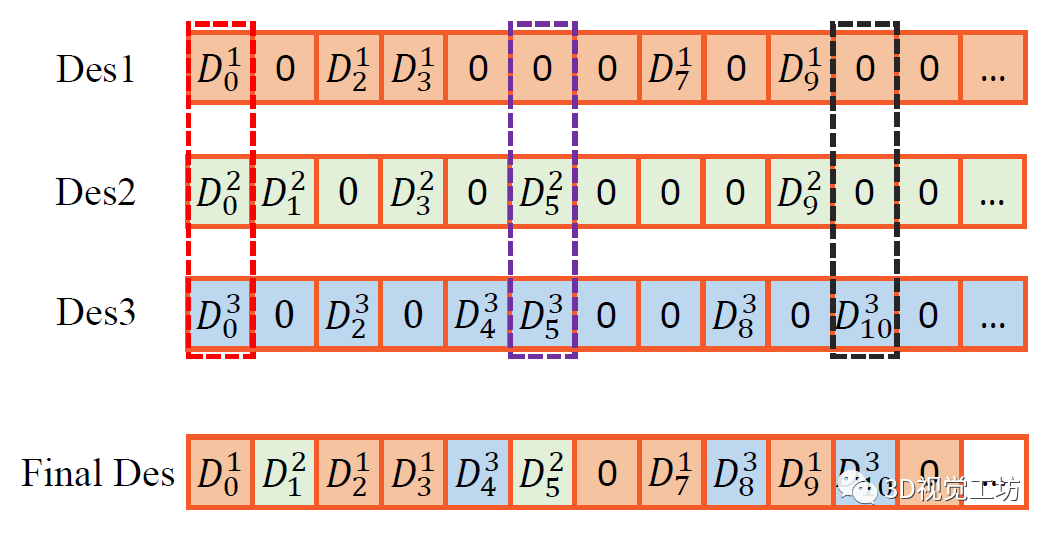
在特征匹配阶段,作者提出了一个由粗(聚合关键点)到精(边缘关键点)的匹配算法,并将其与RANSAC算法结合得到两帧之间精确的点到点的匹配。
在下图中可以看出,初始的匹配是存在大量误匹配的,但是经过RANSAC过滤后匹配得到了很好的优化。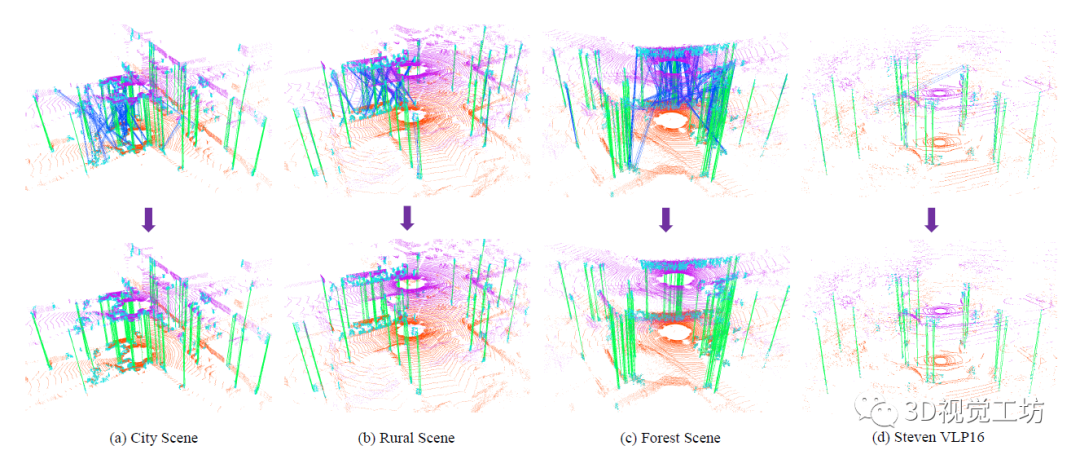
在定量对比阶段,作者对比了同类的点云特征表示方法,并提供与LinK3D相近的关键点。KITTI数据集上的实验结果显示,LinK3D在大多场景上的内点数量和内点百分率都取得了非常好的效果。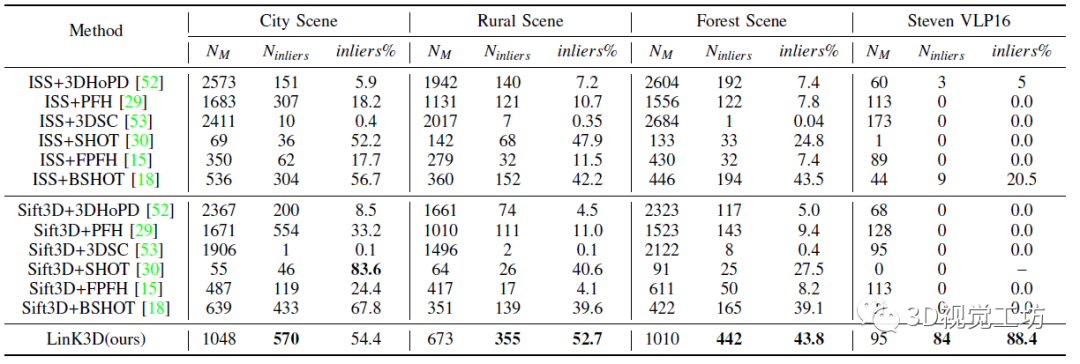
特征提取和特征匹配的耗时也展示了LinK3D良好的实时性。LinK3D的特征提取和匹配时间远小于所需的100毫秒,总时间平均只需要40毫秒左右。
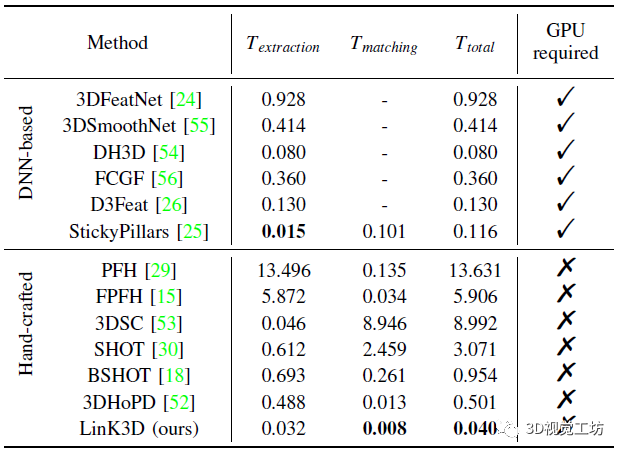
同时,基于DNN的方法的总运行时间非常大,并且需要GPU。而手工比对方法通常需要更多的运行时间来提取特征和匹配两个LiDAR扫描。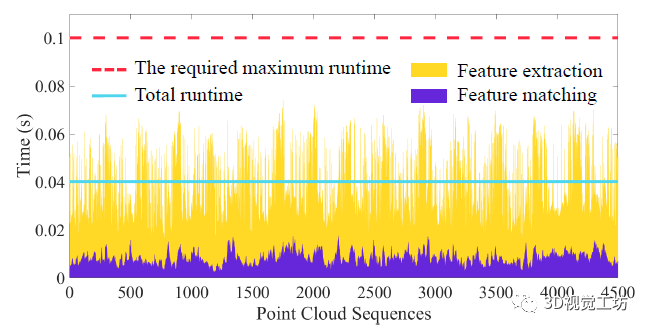
点云配准实验也展示了LinK3D的应用价值。LinK3D与一些传统方法和深度学习的方法相比,在取得可比较的配准性能的同时,还有卓越的实时性能,同时在大多数序列上都能取得较高的估计精度。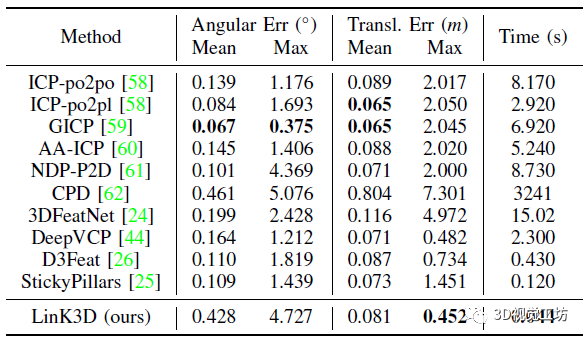
5. DBoW3D
说完LinK3D以后,终于到了我们今天的主角DBoW3D! DBoW3D的总体结构是采用哈希表构建单词与位置的一对一直接关联。选用哈希表的重要原因是它的计算复杂度理论为O(1),可以很好的提高实时性。字典中的单词由LinK3D特征中的非零维度值和所在维度的ID组成。每个单词对应一个位置信息,是单词对应的位置集合,即该单词所在帧的ID以及该单词所在描述子的ID。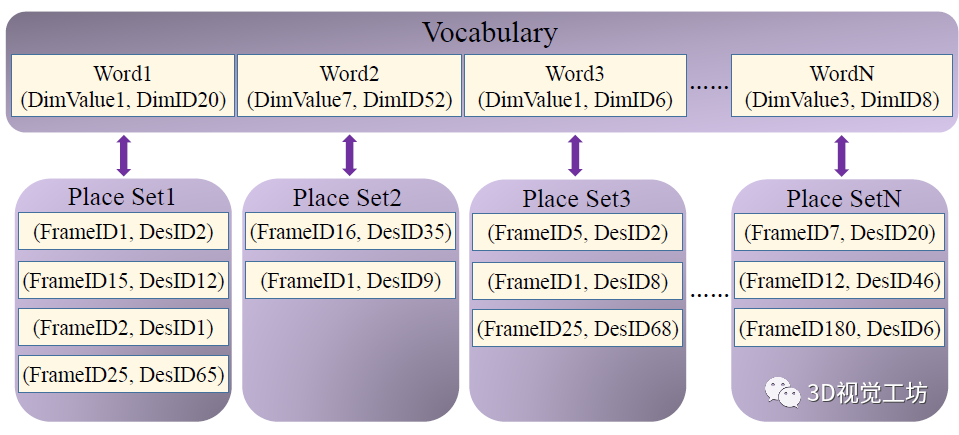
还记得我们刚开始提到的逆向索引吗?到这一步整体的知识就串起来了! DBoW3D的核心原理就是逆向索引!忘了没关系,我们重新表达一下:逆向索引记录单词在哪些帧中出现,以及单词的权重。如果当前帧的一个单词在以前帧中出现,那么通过逆向索引可以直接知道这个单词在哪些帧中出现过。
所以DBoW3D通过逆向索引可以很好得进行位置识别!此外,由于LinK3D本身已经可以很好得表达位置信息。所以这里也没有必要将其转化为更抽象的向量表达。 不知道读者有没有注意到一个很重要的信息,就是DBoW3D中的单词是实时构建的! 这样有什么好处呢?也就是说DBoW3D相较于DBoW2/3,再也不用提前加载那几百兆的字典文件了! 到这里DBoW3D的原理部分其实就结束了(有没有意犹未尽)。
下面我们来看看DBoW3D的具体实验效果。 崔博将DBoW3D嵌入了著名雷达算法A-LOAM中。首先提取边缘点和平面,并进一步的提取LinK3D特征。然后利用雷达里程计算法进行由粗到精的位姿估计,并维护了一个局部地图。最后,BoW3D被嵌入到闭环检测线程中用于实时地识别及闭环校正。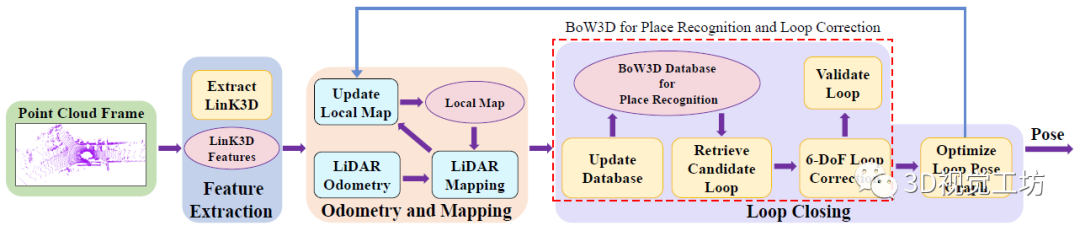
在检索算法中,作者定义了一个类似逆向文本频率的指标,用来判断当前单词区分度。它的值越高,就说明区分度越低,也就越应该舍弃,以提高算法的鲁棒性。
实际检索也是首先进行粗检索,随后选择最好的候选帧进行进一步的验证。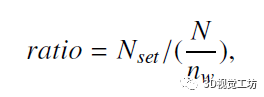

具体的闭环校正,是基于SVD分解的快速配准算法,随后进行因子图优化。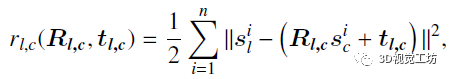
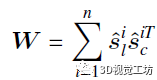
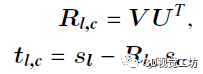
笔者感觉,设计特征和词袋,最重要的就是位姿不变性!这个就类似上面那个漫画描述的问题:两个人站在同一位置,但是朝向不同,如何确定两个人位于同一位置?
而DBoW3D显然很好得处理了这个问题,可以发现在一些视角变化的场景,DBoW3D可以很好得进行闭环识别,并基于LinK3D构建当前帧与闭环帧的匹配。崔博表示,回环的最大容差可以达到45°。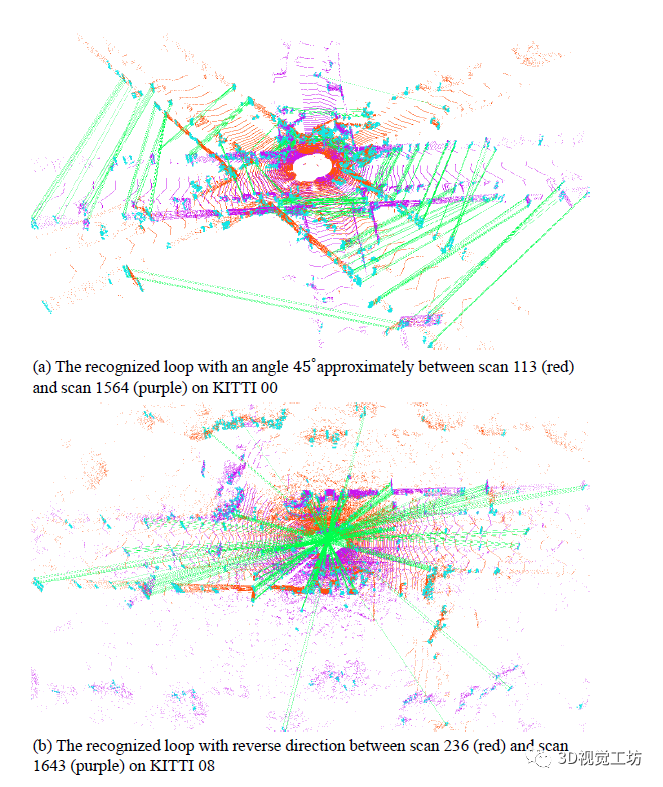
同时,可以发现DBoW3D实现了很好的F1 max和extended precision指标,同时DBoW3D是唯一一个实现六自由度位姿修正的方案,这个在很大程度上弥补了激光雷达回环方案的痛点。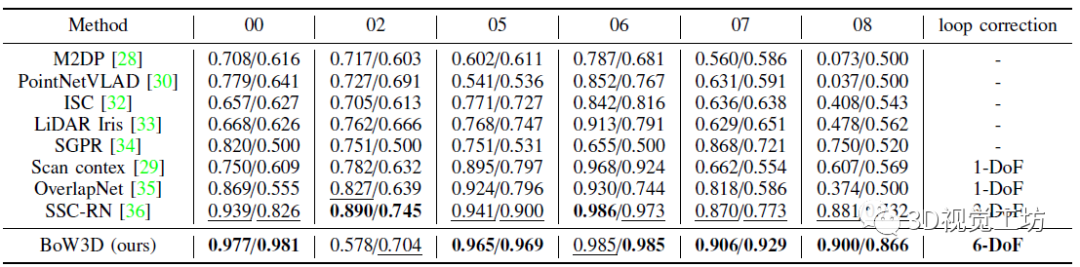
闭环矫正精度和累计误差的降低值也显示了DBoW3D具有很好的精度,说明DBoW3D可以很好得降低累计误差。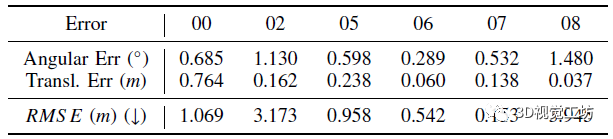
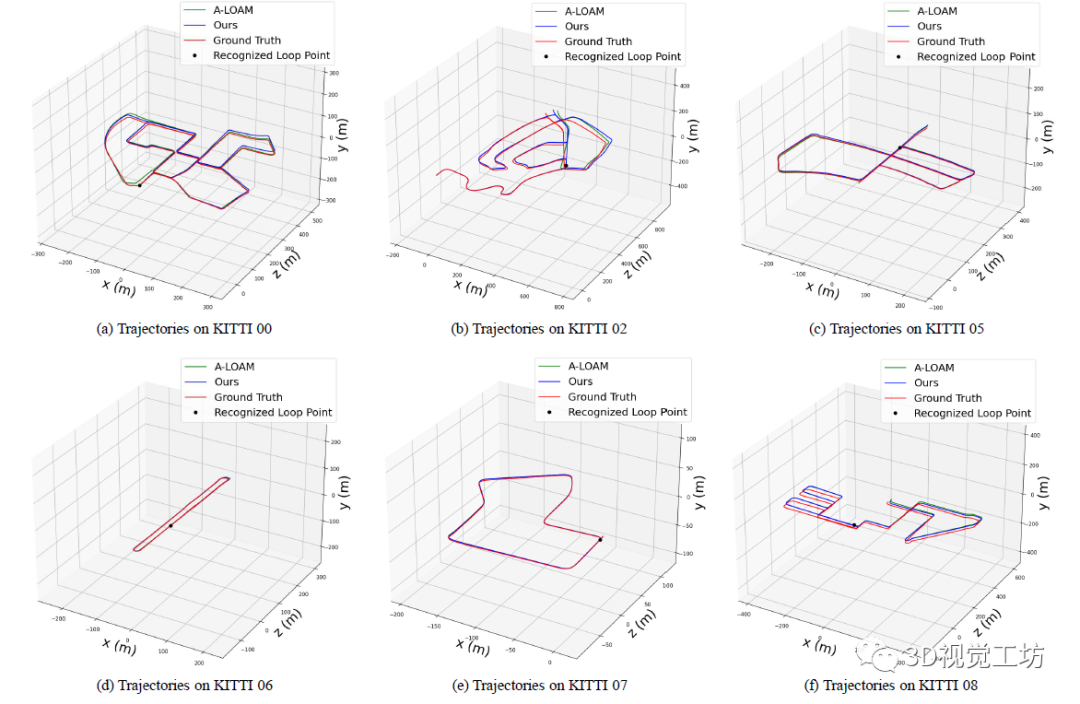
同时,引入DBoW3D以后,可以发现相较于原始的A-LOAM,回环轨迹实现了很好的修正。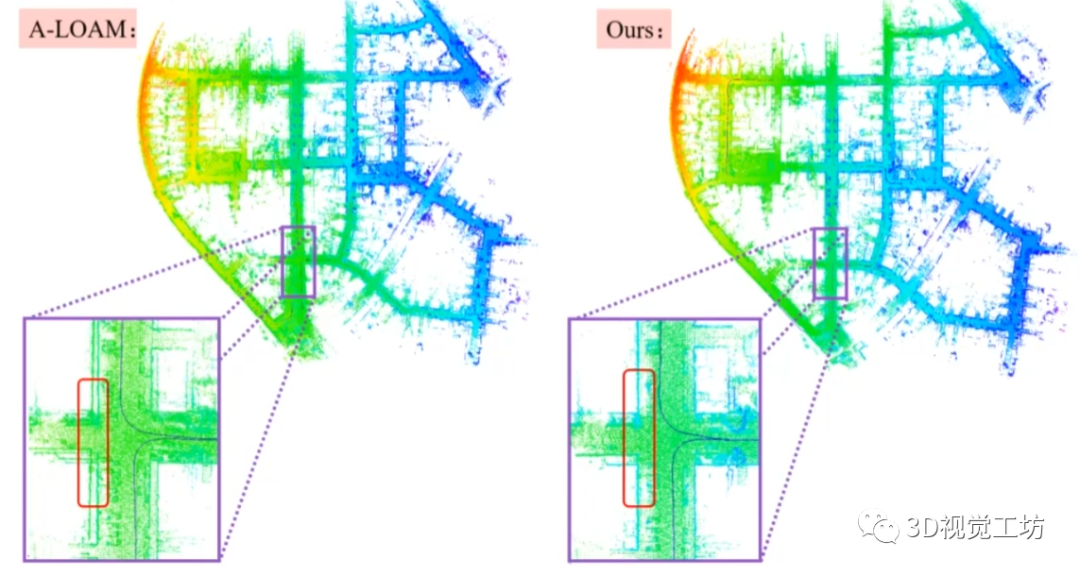
想必读者一定非常关心运行耗时问题。作者对处理一次LiDAR扫描的回环进行积分后,评估SLAM系统中每个模块的平均运行时间。要注意的是,系统的每个模块在不同的线程中分别运行。虽然建图线程和位姿图优化( PGO )的运行时间超过100 ms,但由于其使用频率较低,可以实时执行。重要的是,BoW3D处理一帧图像的时间整体小于100 ms,保证了BoW3D应用于3D LiDAR SLAM系统的实时性。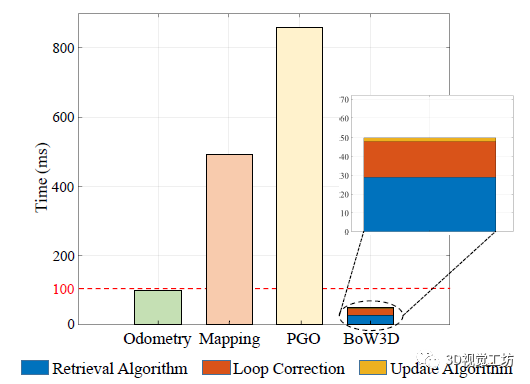
6. 笔者总结
笔者认为BoW3D这篇文章是具有非常重要的意义的,它模仿视觉SLAM词袋模型,设计了激光雷达SLAM的词袋模型,很大程度上提高了激光雷达SLAM回环的精度和鲁棒性,重要的是它可以实现6自由度的位姿修正,这些在以前的方案中都是没有实现的。LinK3D和BoW3D算法已经开源,笔者认为未来基于BoW3D可能会产生很多新的工作。 笔者在这里也大胆猜想,基于BoW3D可能有如下的可以进行改进的点:
1、在Lego-LOAM、LIO-SAM、LIV-SAM、R3Live等雷达SLAM方案中引入BoW3D,优化回环精度和鲁棒性;
2、BoW3D是基于逆向索引的,那么是否可以基于正向索引设计新的雷达SLAM词袋方案;
3、利用平面点代替边缘点;
4、在LinK3D和BoW3D中引入语义信息,或者基于其他特征设计新的LinK3D和BoW3D算法;
5、利用DBoW3D实现全局定位,比如建好一个地图后,进行仅定位。
审核编辑:刘清
-
Sift
+关注
关注
1文章
38浏览量
15618 -
SLAM
+关注
关注
24文章
459浏览量
33416 -
激光雷达
+关注
关注
982文章
4548浏览量
197081
原文标题:开源!用于3D激光雷达SLAM回环检测的实时词袋模型BoW3D
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
5 款激光雷达:iDAR、高清3D LiDARInnovizPro、S3、SLAM on Chip、VLS-128
浅谈SLAM的回环检测技术
AGV激光雷达SLAM定位导航技术
Teledyne激光雷达新应用 为《权力的游戏》提供3D数据采集和视觉效果
Lumentum推出VCSEL用于汽车激光雷达和3D传感应用
3D激光雷达和相机校准是如何考虑传感器之间误差的?
3D激光雷达SLAM技术的应用趋势
什么是激光雷达3D SLAM技术?

激光雷达在SLAM算法中的应用综述



评论