 应用示例-基于百度BCC GR1实例部署Elastic Stack
应用示例-基于百度BCC GR1实例部署Elastic Stack

简 介
百度智能云正式发布了新型 BCC 实例产品 Gr1。不同于其他云服务器,Gr1 所搭载的 Ampere Altra 云原生处理器基于 Arm 指令集架构,采用单线程内核设计,云实例的每一个 vCPU 都是独立的物理核,独享 ALU(逻辑计算单元),缓存等关键物理资源,可以实现稳定可预测的性能。
目前 Gr1 实例已经已支持 CentOS7.9、CentOS7.6、Ubuntu22.04、Ubuntu20.04 等常用 Linux 公共镜像。Gr1 实例产品主要面向常见的云原生应用负载,如开源数据库、Java 应用程序、视频编解码、AI 推理(数据治理)、大数据分析、DevOps、Web 服务应用等。为了让客户更轻松地部署云原生的工作负载,作为百度智能云容器化工作负载的关键基础设施 Cloud Container Engine(CCE)目前已提供对 Gr1 实例的支持。
在本示例中,我们将演示如何在基于百度智能云 Gr1 实例的 CCE 集群上部署 ELK 软件栈,以从 Kubernetes 集群内的 Pod 收集日志。
传统的 ELK 软件栈由 Elasticsearch、Logstash 和 Kibana 组成。从 2015 年起,轻量级的数据传输器 Beats 家族开始非正式的成为 ELK 中的一个组件。ELK 软件栈为开发人员提供了端到端的能力来聚合应用程序和系统日志、分析这些日志以及可视化洞察以进行监控、故障排除和分析。
准备工作...
在开始前, 我们假设您已做了如下准备
您已经有一个百度智能云账户
您的百度智能云账户具有创建 Arm Kubernetes CCE 容器引擎的权限。
您本地操作终端已安装 kubectl 工具。
如果上列准备已经就绪,我们就可以进行下个步骤 —— 在部署 ELK 之前,先创建基于百度 Gr1 实例的 Arm 架构容器引擎。
首先创建基于 Gr1 的容器引擎
除了在 BCC 上发布 Arm 实例外,百度智能云还提供使用基于 Ampere Altra 的 Gr1 实例在 CCE上运行容器化的 Arm 工作负载。数个百度智能云地区和可用区现在可使用于基于 Gr1 实例创建的 CCE 集群:北京(D 区域, E 区域), 广州(C 区域)和苏州(D 区域)。
在本文中,我们将在百度智能云的北京可用区 D 创建一个由 3 个 master 节点,以及 3 个 worker节点组成的集群。
首先,从控制台进入 CCE 容器引擎服务页面,点击“创建集群”按钮
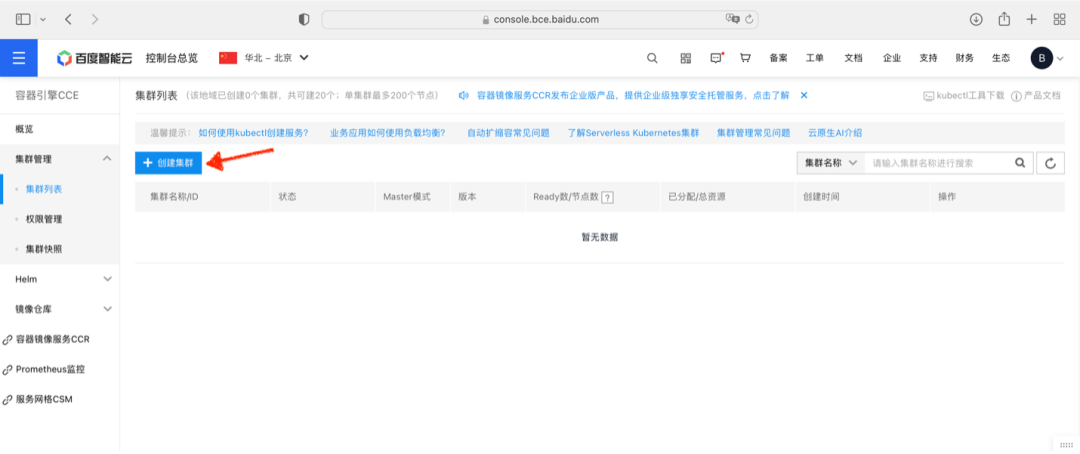
在集群创建导览页面中,选择创建 Arm Kubernetes 集群
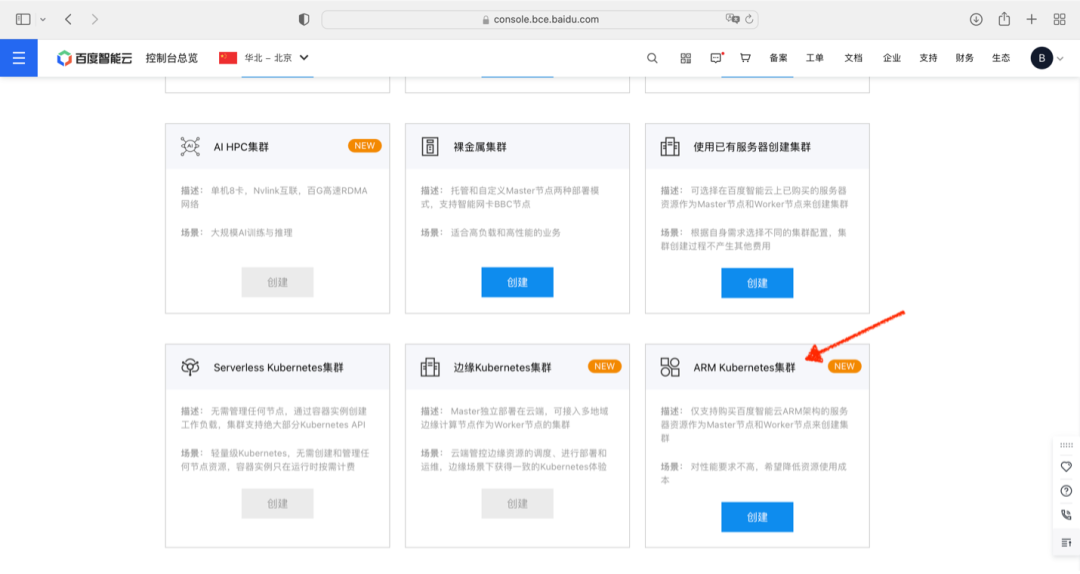
按集群创建向导选择 3 副本 Master 配置
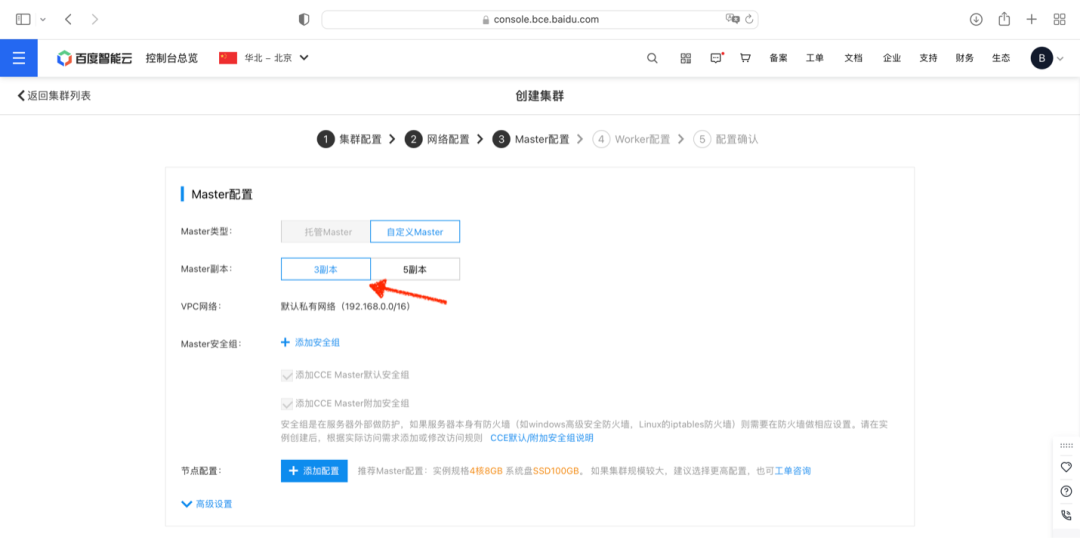
并添加 3 台 Gr1.c4m16 实例作为 Master 节点:
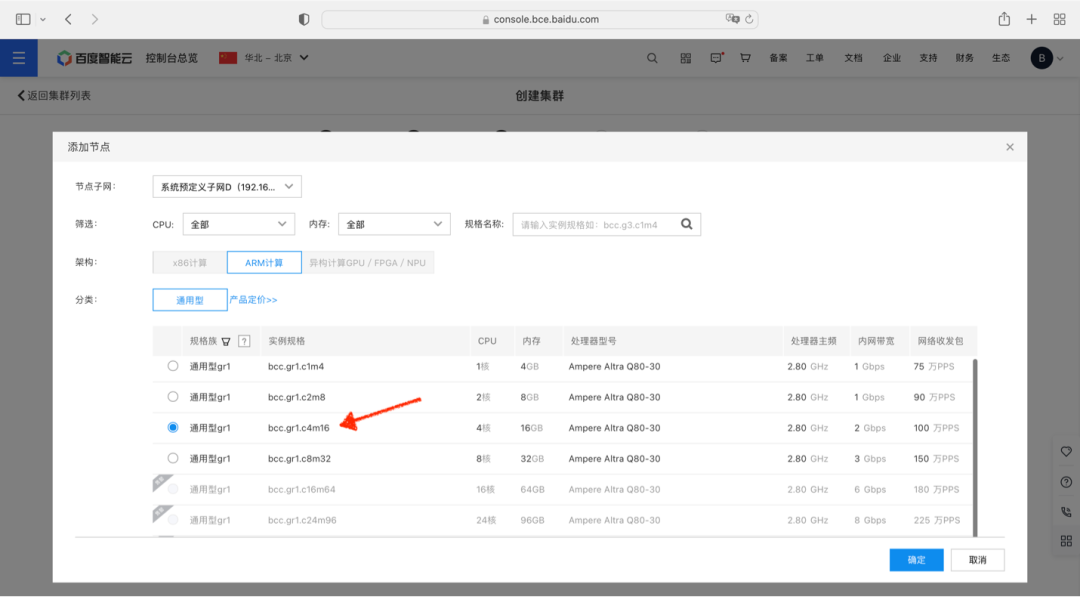
类似的,在添加 Worker 节点的步骤中,选择添加 3 台 Gr1.c8m32 实例作为 Worker 节点:
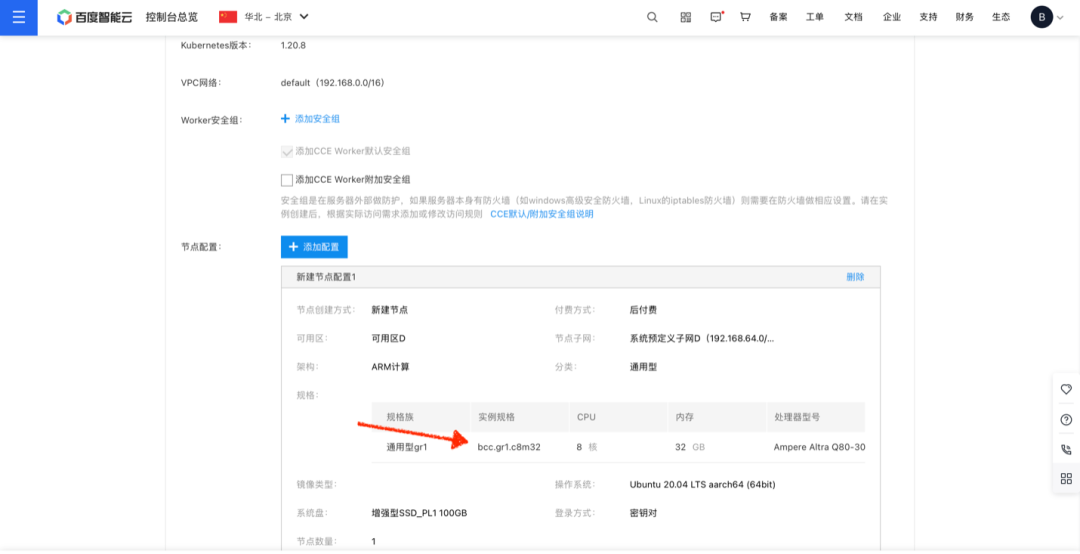
点击确认完成,CCE 开始启动集群创建。整个过程需要数分钟时间。待集群状态变成运行中后,即可下载集群凭证:
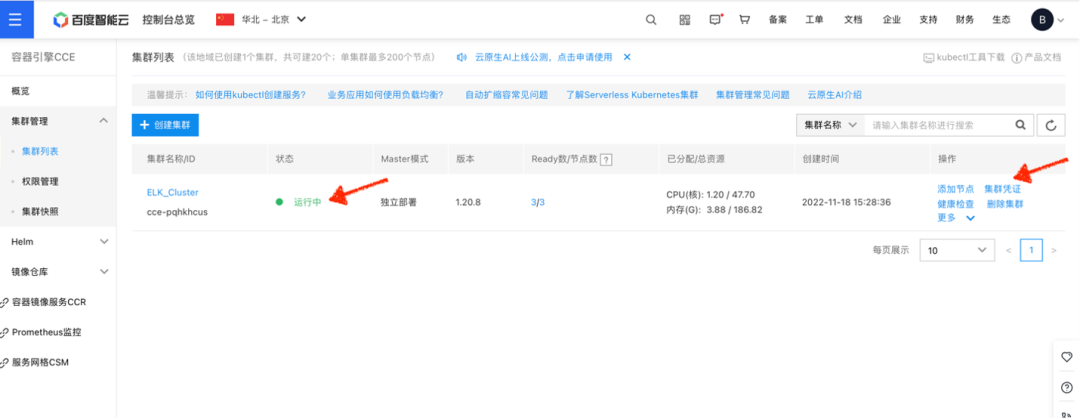
将下载后的凭证存放在 kubectl 的默认配置路径:
$ mv kubectl.conf ~/.kube/config
使用 kubectl 查询集群状态,当集群的 Master 和 worker 节点都显示 Ready 状态时,说明您的 Arm 集群已经准备就绪,并且可以通过 kubectl 进行管理:
$ kubectl get nodes NAME STATUS ROLES AGE VERSION 192.168.64.10 Ready master 1d1h v1.20.8 192.168.64.11 Ready1d1h v1.20.8 192.168.64.12 Ready 1d1h v1.20.8 192.168.64.13 Ready 1d1h v1.20.8 192.168.64.8 Ready master 1d1h v1.20.8 192.168.64.9 Ready master 1d1h v1.20.8
开始部署 ELK!
1预拉取容器镜像
为了加速部署过程中容器镜像拉取的速度,我们先通过镜像的容器仓库将部署过程中使用到的容器镜像拉取到 Worker 节点上并重新打上 tag:
$ docker pull ampdemo/eck-operator:2.4.0 $ docker tag ampdemo/eck-operator:2.4.0 docker.elastic.co/eck/eck-operator:2.4.0 $ docker pull ampdemo/elasticsearch:8.4.1 $ docker tag ampdemo/elasticsearch:8.4.1 docker.elastic.co/elasticsearch/elasticsearch:8.4.1 $ docker pull ampdemo/filebeat:8.4.1 $ docker tag ampdemo/filebeat:8.4.1 docker.elastic.co/beats/filebeat:8.4.1 $ docker pull ampdemo/kibana:8.4.1 $ docker tag ampdemo/kibana:8.4.1 docker.elastic.co/kibana/kibana:8.4.1
2Operator 的部署
从 Elastic 网站下载定制并安装资源定义和 RBAC规则:
$ kubectl create -f https://download.elastic.co/downloads/eck/2.4.0/crds.yaml $ kubectl apply -f https://download.elastic.co/downloads/eck/2.4.0/operator.yaml
稍等片刻后可以看到 elastic-operator Pod 已经拉起并进入运行状态:
$ kubectl get pods -n elastic-system NAME READY STATUS RESTARTS AGE elastic-operator-0 1/1 Running 0 2m
3创建持久卷
在本例中,ELK 集群将会申请 1GiB 的持久卷空间用作数据存储。因此,我们制备了 20G 的持久卷供 ELK 集群及将来的扩容使用。
$ cat <
检查持久卷已成功创建:
$ kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE elasticsearch-data 20Gi RWO Delete Available 5s
4Elasticsearch 节点的部署
当 Operator 和持久卷已经就绪,我们可以通过如下命令开始 Elasticsearch 的部署:
$ cat <
Elasticsearch 节点会在数分钟内进入 green 和 Ready 状态:
$ kubectl get elasticsearch NAME HEALTH NODES VERSION PHASE AGE quickstart green 1 8.4.1 Ready 1m
5Filebeat 的部署
当提到 ELK,被广泛熟知的是 Elasticsearch, Logstash 和 Kibana 的集合。Beat 是 ELK 家族的新成员,它是一个轻量级的开源数据传送器。在本范例中,我们将使用 filebeat 来收集每个 Kubernetes 节点上的容器日志。执行如下命令将 Filebeat 以 DaemonSet 部署在每台节点,并将日志以数据流的形式送往 Elasticsearch:
$ cat <
同样的, 稍作等待 beat 将进入 green 的健康状态:
$ kubectl get beat NAME HEALTH AVAILABLE EXPECTED TYPE VERSION AGE quickstart green 3 3 filebeat 8.4.1 2m
6Kibana 的部署
在完成 Elasticsearch 的部署后,我们需要 Kibana 来搜索,观察和分析数据。使用如下命令部署与当前 Elasticsearch 集群关联的 Kibana 实例:
$ cat <
等待数分钟后,Kibana 进入 green 健康状态:
$ kubectl get kibana NAME HEALTH NODES VERSION AGE quickstart green 1 8.4.1 2m
分配一个公网 IP 以便从集群外访问 Kibana:
$ kubectl expose deployment quickstart-kb --type=LoadBalancer --port 5601 --target-port 5601 service/quickstart-kb exposed
CCE 将会准备一个 LoadBalancer 服务对象并将 Kubernetes 集群外部的访问重定向到后端 Kibana 的 Pod:
$ kubectl get services NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.255.0.1443/TCP 1d3h quickstart-es-default ClusterIP None 9200/TCP 12h quickstart-es-http ClusterIP 10.255.177.25 9200/TCP 12h quickstart-es-internal-http ClusterIP 10.255.156.180 9200/TCP 12h quickstart-es-transport ClusterIP None 9300/TCP 12h quickstart-kb LoadBalancer 10.255.223.4 120.48.90.143,192.168.0.3 5601:32716/TCP 12h quickstart-kb-http ClusterIP 10.255.55.93 5601/TCP 12h
在本示例中,公网 IP 120.48.90.143 被分配给了 Kibana 实例。
Kibana 登录密码可通过如下命令获取:
$ kubectl get secret quickstart-es-elastic-user -o=jsonpath='{.data.elastic}' | base64 --decode; echo
搭配用户名 elastic, 我们可以通过 https://:5601 来尝试访问 Kibana, 登录后在主页点击 “Explore on my own”.
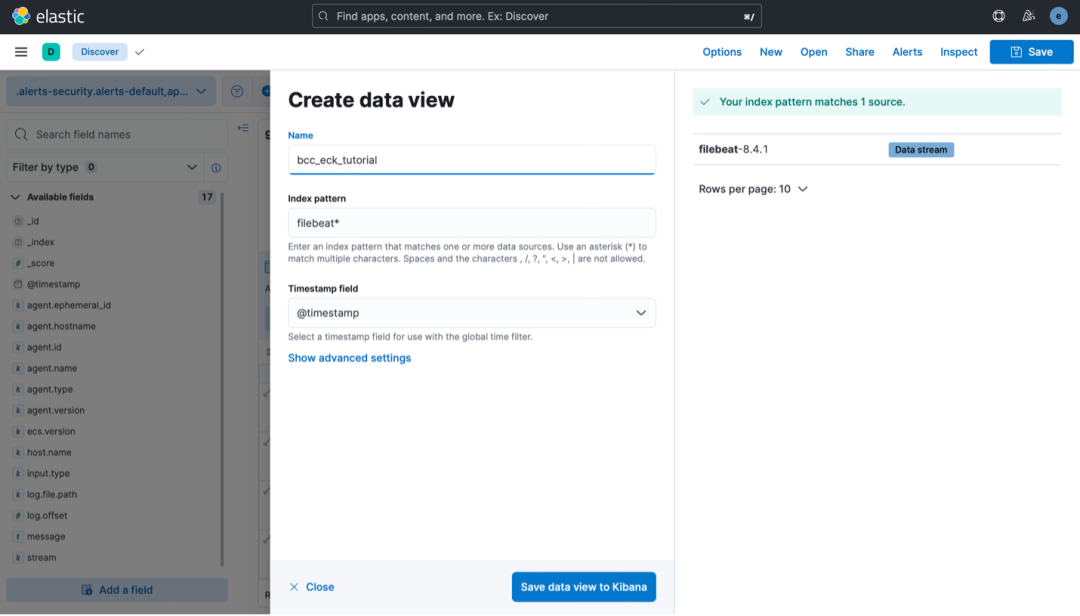
7数据流导入
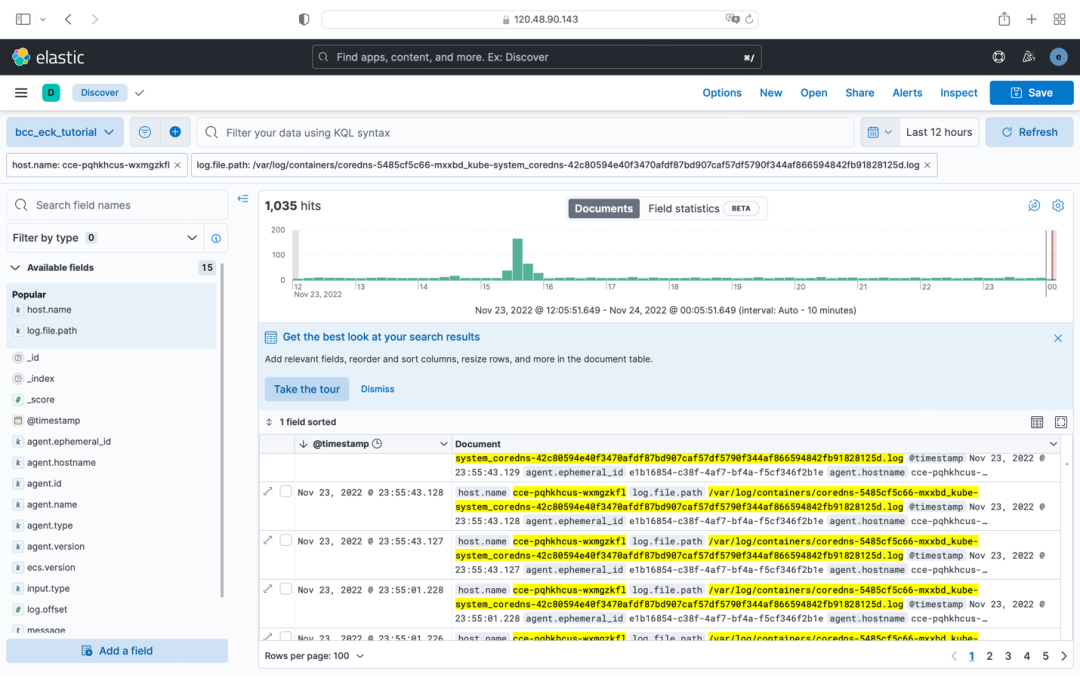
在 Discover 中选择“Create data view”,并在弹出窗口中给数据视图命名,如“bcc-eck-tutorial”,并在“filebeat-8.4.1”数据流中导入索引模式。
最终,我们可以在 Kibana 中查看 Kubernetes 集群每个节点上 Pod 的日志。
正如本示例所展示的,来自于 CNCF Cloud Native 的主流云原生项目如 Elastic 等,已提供对 Arm64 架构的支持。用户可以在基于 Ampere Altra 处理器的 Arm64 实例上感受到顺畅的部署体验。敬请访问 Ampere Blog 进一步了解 Ampere Altra 处理家族的强大之处。
审核编辑:汤梓红
-
处理器
+关注
关注
68文章
20339浏览量
255356 -
ARM
+关注
关注
135文章
9589浏览量
393834 -
百度
+关注
关注
9文章
2389浏览量
95249 -
BCC
+关注
关注
0文章
10浏览量
7775 -
Ampere
+关注
关注
1文章
81浏览量
4915
原文标题:安博士讲堂|应用示例 - 基于百度 BCC GR1 实例部署 Elastic Stack
文章出处:【微信号:AmpereComputing,微信公众号:安晟培半导体】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
小米副总裁跳槽百度 出任百度资本CFO
百度地图离线API调用教程
百度总裁:百度在人工智能领域已有重大突破
百度API调用(三)——语音识别 精选资料推荐
百度“天智平台”发布 开放百度大脑能力
百度大数据怎么使用
百度王海峰:自研云端AI通用芯片百度昆仑1已实现量产
百度与吉利合作,百度造车优势何在?
百度Create AI开发者大会:百度大脑位居中国市场第一



你们要的AMD来了,云服务器BCC发布5款Milan架构新实例
GTC 2023:百度智能云DPU落地实践



评论