 10个超级实用的数据可视化图表
10个超级实用的数据可视化图表
可视化是一种方便的观察数据的方式,可以一目了然地了解数据块。我们经常使用柱状图、直方图、饼图、箱图、热图、散点图、线状图等。这些典型的图对于数据可视化是必不可少的。除了这些被广泛使用的图表外,还有许多很好的却很少被使用的可视化方法,这些图有助于完成我们的工作,下面我们看看有那些图可以进行。
1、平行坐标图
Parallel Coordinate
我们最多可以可视化 3 维数据。但是我们有时需要可视化超过3维的数据才能获得更多的信息。我们经常使用PCA或t-SNE来降维并绘制它。在降维的情况下,可能会丢失大量信息。在某些情况下,我们需要考虑所有特征,平行坐标图有助于做到这一点。
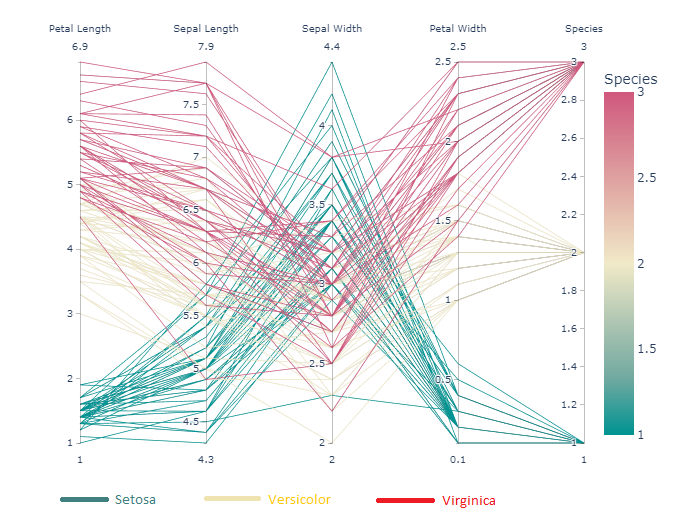
鸢尾花数据集的平行坐标图
上面的图片。横线(平行轴)表示鸢尾花的特征(花瓣长、萼片长、萼片宽、花瓣宽)。分类是Setosa, Versicolor和Virginica。上图将该物种编码为Setosa→1,Versicolor→2,Virginica→3。每个平行轴包含最小值到最大值(例如,花瓣长度从1到6.9,萼片长度从4.3到7.9,等等)。例如,考虑花瓣长度轴。这表明与其他两种植物相比,濑蝶属植物的花瓣长度较小,其中维珍属植物的花瓣长度最高。
有了这个图,我们可以很容易地获得数据集的总体信息。数据集是什么样子的?让我们来看看。
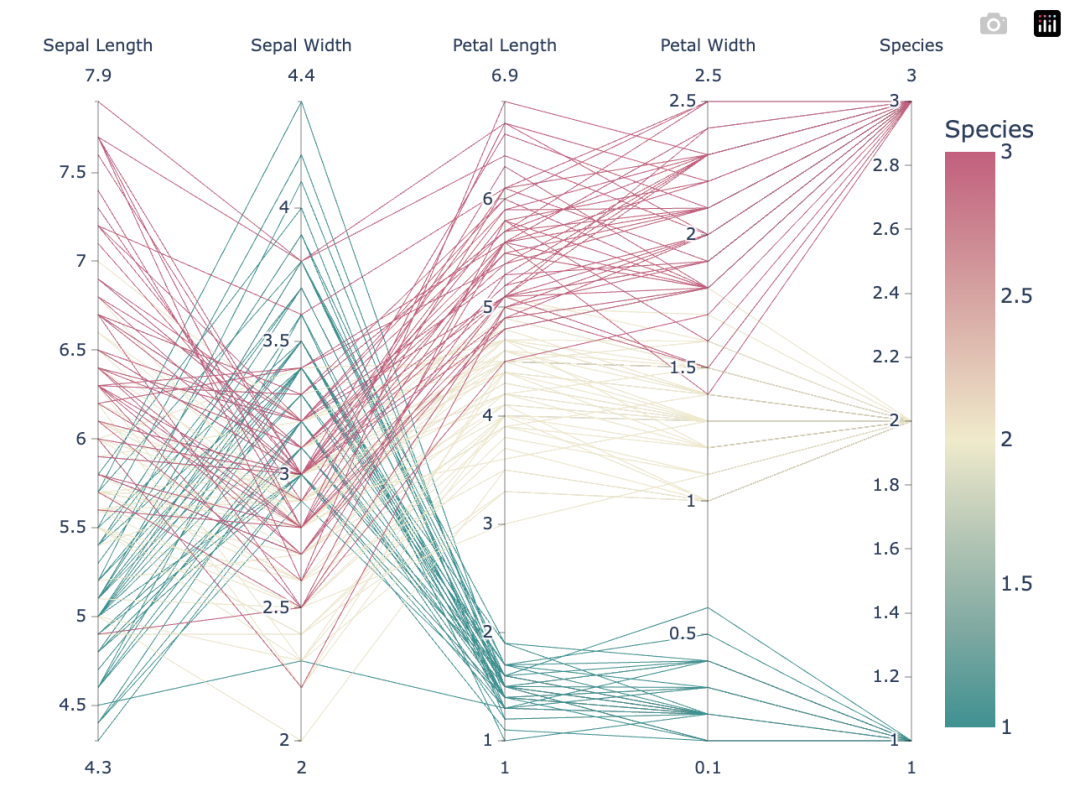
让我们用Plotly Express库[1]可视化数据。Plotly库提供了一个交互式绘图工具。
importplotly.expressaspx df=px.data.iris() fig=px.parallel_coordinates(df,color="species_id",labels={"species_id":"Species", "sepal_width":"SepalWidth","sepal_length":"SepalLength", "petal_width":"PetalWidth","petal_length":"PetalLength",}, color_continuous_scale=px.colors.diverging.Tealrose, color_continuous_midpoint=2) fig.show()
output
除了上图以外我们还可以使用其他库,如pandas、scikit-learn和matplotlib来绘制并行坐标。
2、六边形分箱图
Hexagonal Binning
六边形分箱图是一种用六边形直观表示二维数值数据点密度的方法。
ax=df.plot.hexbin(x='sepal_width',y='sepal_length', gridsize=20,color='#BDE320')
output
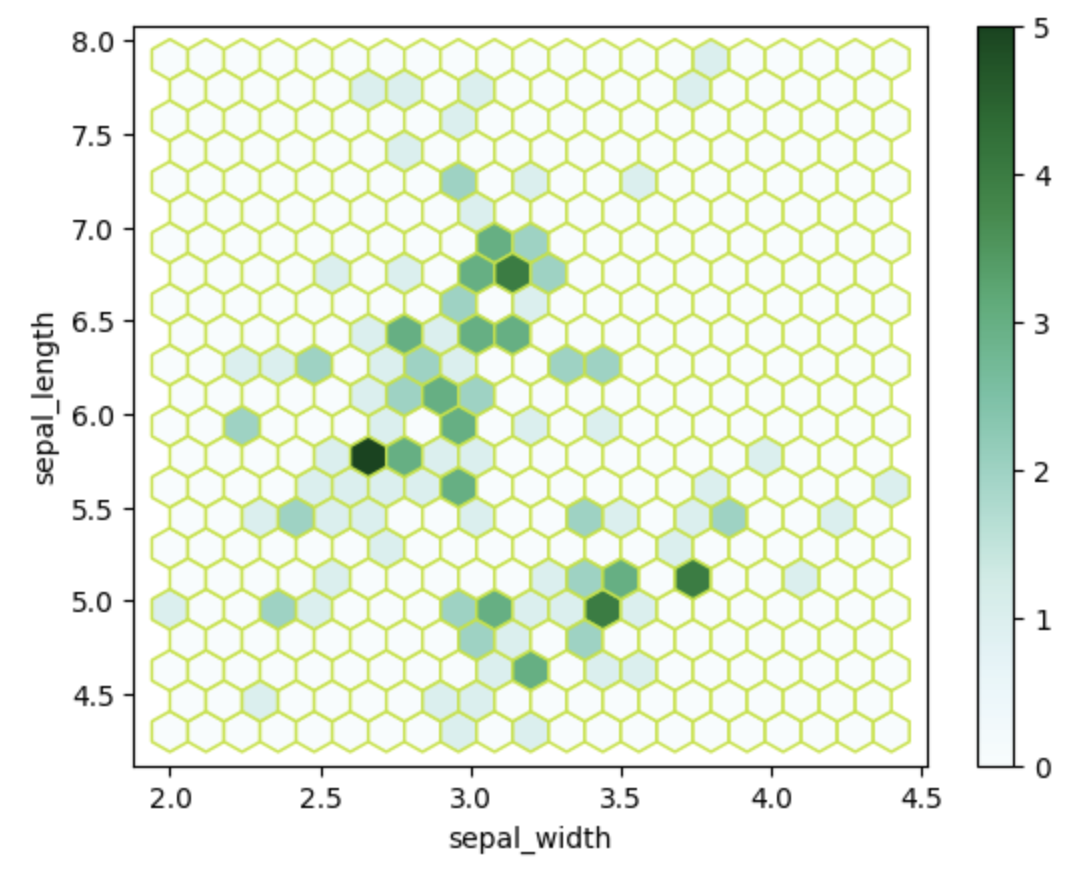
Pandas允许我们绘制六边形binning [2]。我已经展示了用于查找sepal_width和sepal_length列的密度的图。
其他库,如matplotlib、seaborn、bokeh(交互式绘图)也可用于绘制它。
3、等高线密度图
Countour
二维等高线密度图是可视化特定区域内数据点密度的另一种方法。这是为了找到两个数值变量的密度。例如,下面的图显示了在每个阴影区域有多少数据点。
importplotly.expressaspx fig=px.density_contour(df,x="sepal_width",y="sepal_length") fig.update_traces(contours_coloring="fill",contours_showlabels=True) fig.show()
output
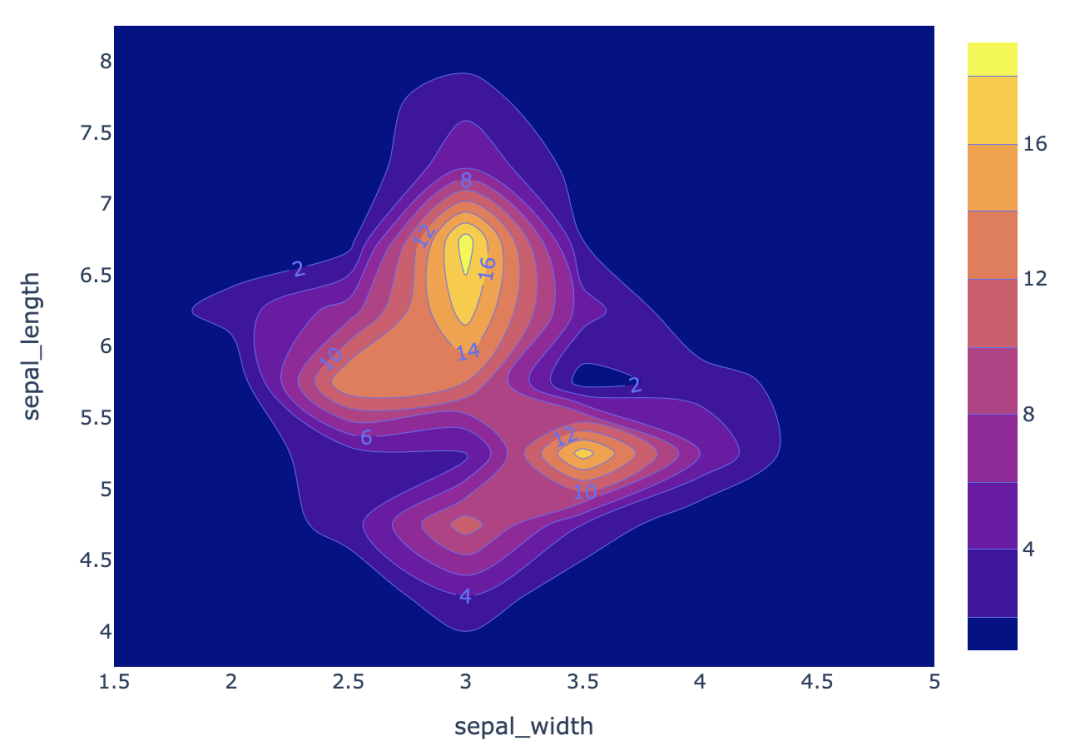
plotly库,因为它可以方便地绘制交互式的图表。我们这里绘制了两个变量sepal_width和sepal_length的密度。
当然,也可以使用其他库,如seaborn、matplotlib等。4、QQ-plot
QQ plot是另一个有趣的图。QQ是Quantile - Quantile plot的缩写(Quantile/percentile是一个范围,在这个范围内数据下降了指定百分比。例如,第10个quantile/percentile表示在该范围下,找到了10%的数据,90% 超出范围)。这是一种直观地检查数值变量是否服从正态分布的方法。让我解释一下它是如何工作的。
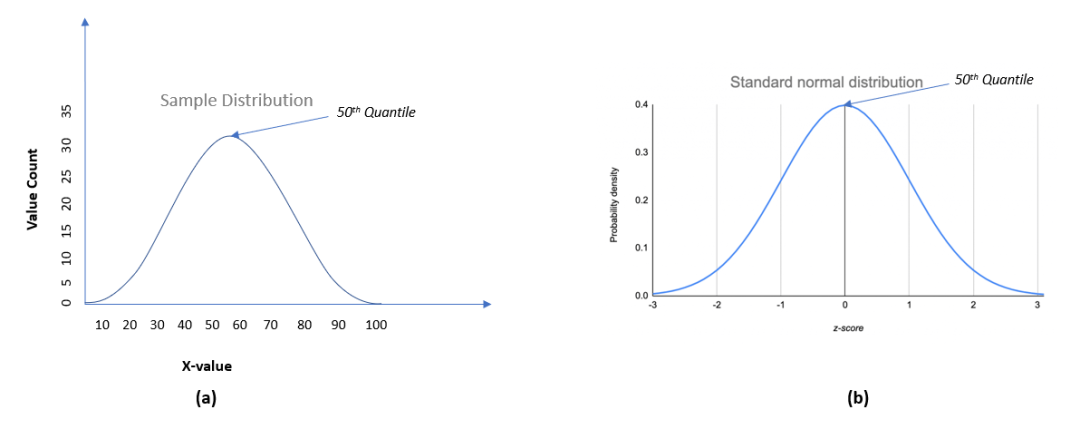
(a)样本分布(b)标准正态分布
图(a)是样本分布;(b)是标准正态分布。对于样本分布,数据范围从10到100(100% 数据在 10 到 100 之间)。但对于标准正态分布,100%的数据在-3 到3(z 分数)的范围内。在QQ图中,两个x轴值均分为 100个相等的部分(称为分位数)。如果我们针对x和y轴绘制这两个值,我们将得到一个散点图。
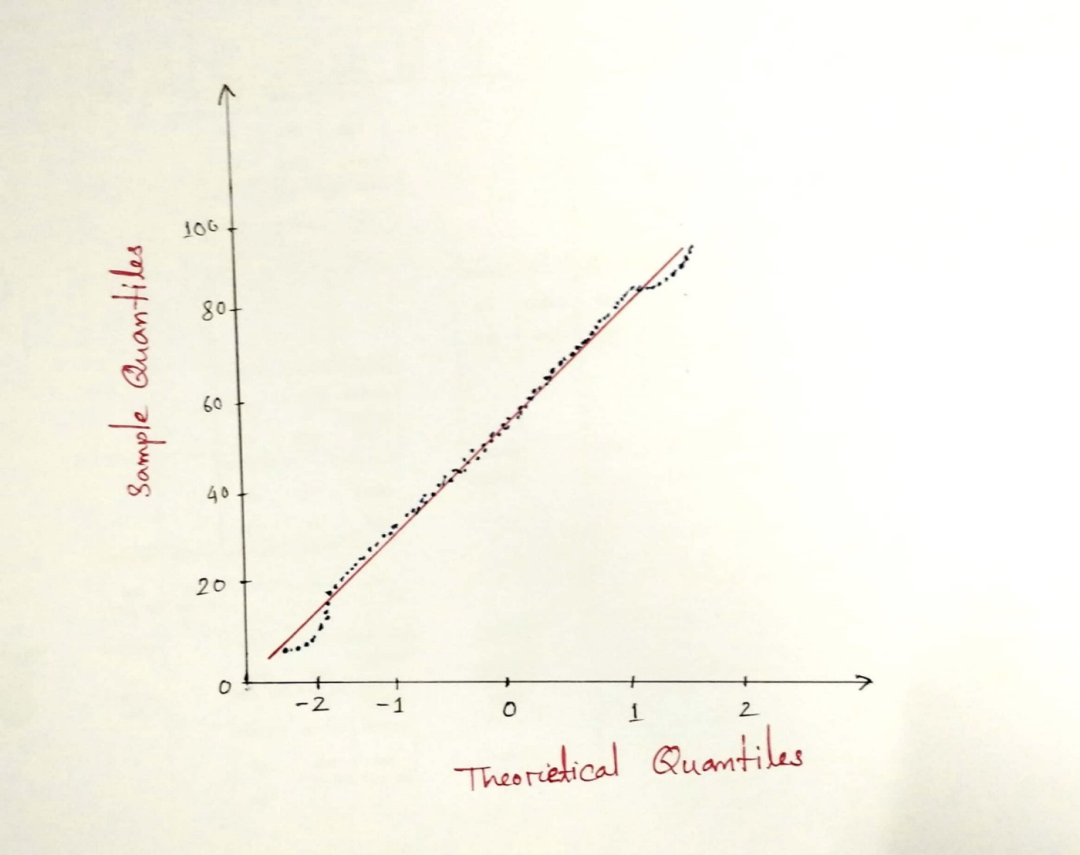
QQ-plot
散点图位于对角线上。这意味着样本分布是正态分布。如果散点图位于左边或右边而不是对角线,这意味着样本不是正态分布的。
导入必要的库
importpandasaspd importnumpyasnp importmatplotlib.pyplotasplt importseabornassns
生成正态分布数据。
np.random.seed(10) #GenerateUnivariateObservations gauss_data=5*np.random.randn(100)+50
绘制数据点的分布。
sns.histplot(data=gauss_data,kde=True)
output
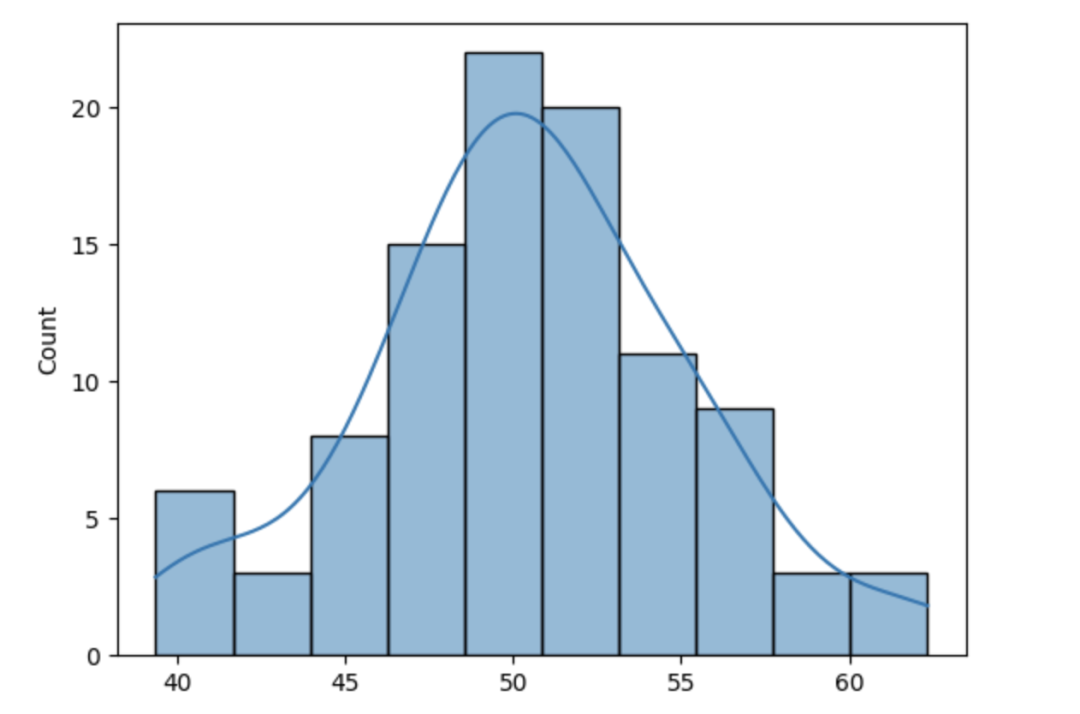
该图显示数据是正态分布的。我们用数据点做qq-plot来检验它是否正态分布。
importstatsmodels.apiassm #q-qplot sm.qqplot(gauss_data,line='s') plt.show()
output
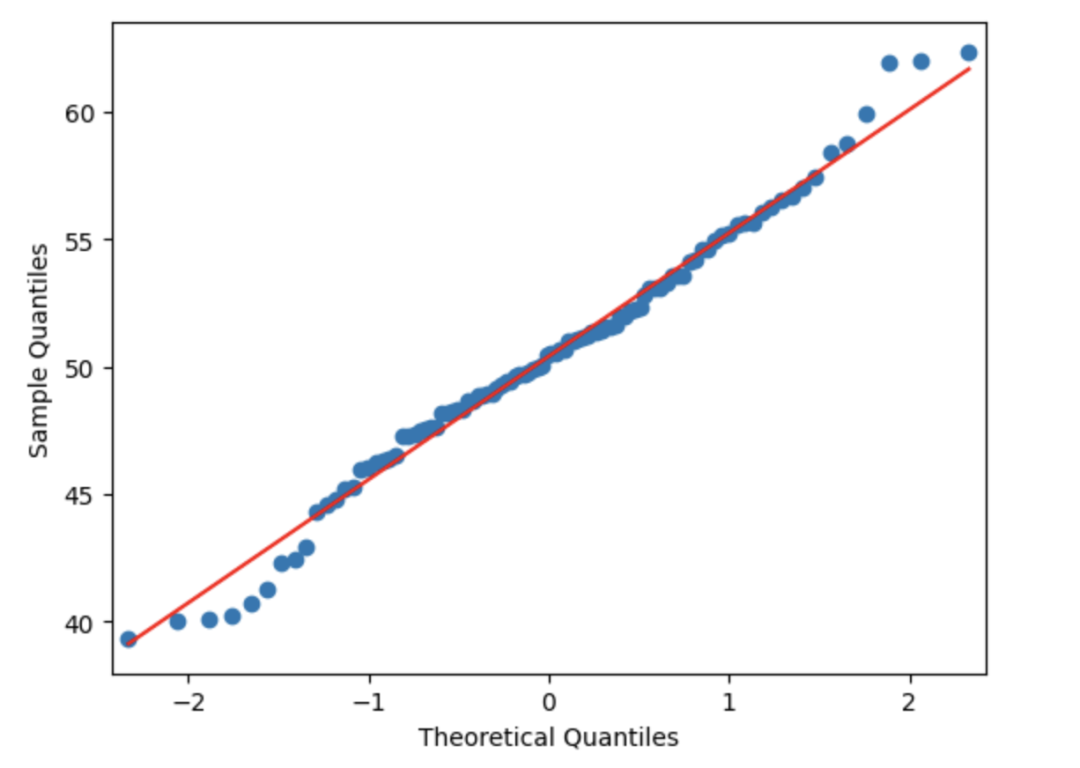
该图显示散点位于对角线上。所以它是正态分布的。
小提琴图
Violin Plot
小提琴图与箱线图相关。我们能从小提琴图中获得的另一个信息是密度分布。简单来说就是一个结合了密度分布的箱线图。我们将其与箱线图进行比较。 在小提琴图中,小提琴中间的白点表示中点。实心框表示四分位数间距 (IQR)。上下相邻值是异常值的围栏。超出范围,一切都是异常值。下图显示了比较。
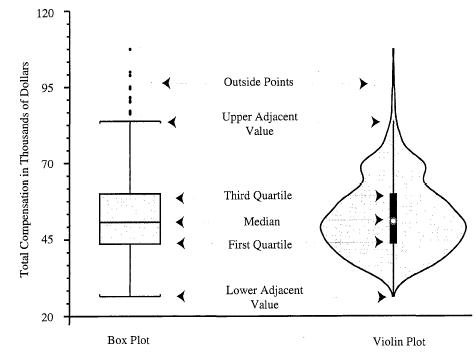
盒状图和小提琴状图的常见组成。所有学术级别的薪酬总额
让我们看看小提琴图的可视化。
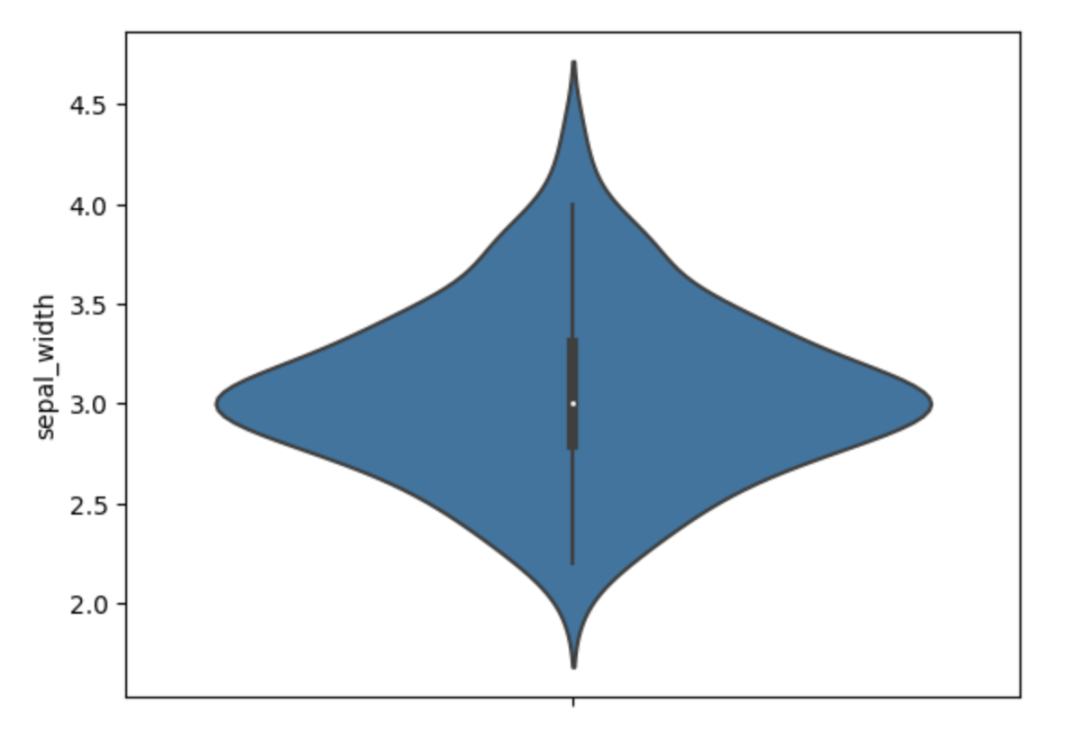
importseabornassns sns.violinplot(data=df,y="sepal_width")
output
我们还可以通过传递名称来绘制不同物种的小提琴图。
importseabornassns sns.violinplot(data=df,x='species',y="sepal_width")
output

还可以使用其他库,如plotly、matplotlib等来绘制小提琴图。
箱线图的改进版
Boxen plot
Boxenplot是seaborn库引入的一种新型箱线图。对于箱线图,框是在四分位数上创建的。但在Boxenplot中,数据被分成更多的分位数。它提供了对数据的更多内存。
鸢尾花数据集的Boxenplot显示了sepal_width的数据分布。
sns.boxenplot(x=df["sepal_width"])
output
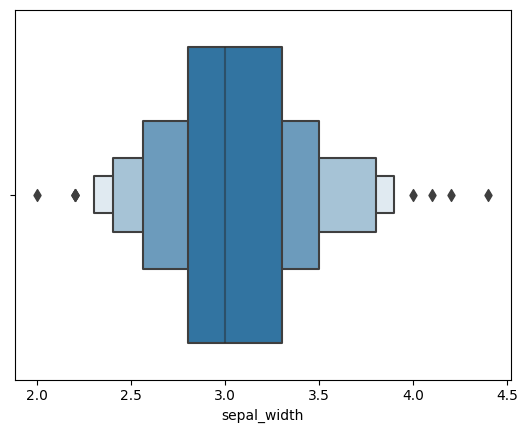
上图显示了比箱线图更多的盒。这是因为每个框代表一个特定的分位数。
sns.boxenplot(data=df,x="species",y='sepal_width')
output
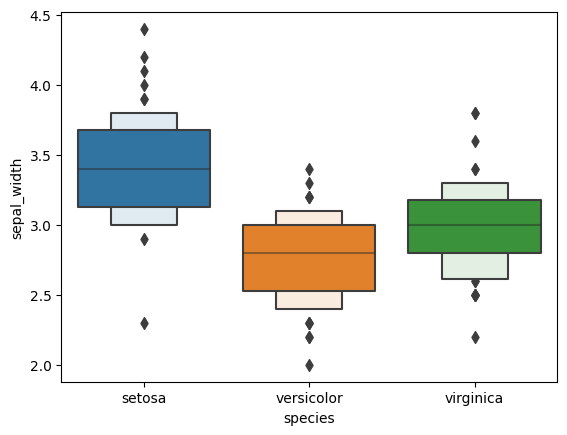
不同物种sepal_width的Boxenplot图。
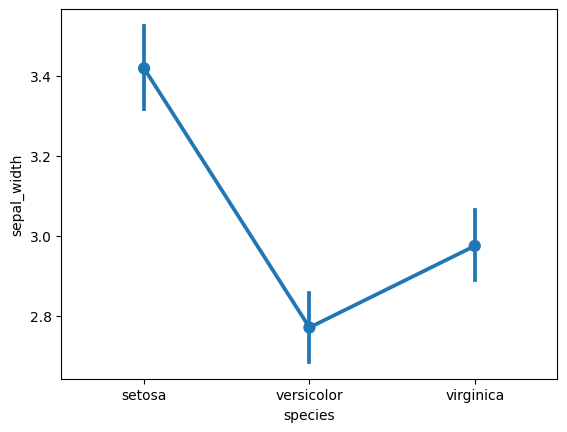
点图
下图中有一些名为误差线的垂直线和其他一些连接这些垂直线的线。让我们看看它的确切含义。
点图是一种通过上图中显示的点的位置来表示数值变量集中趋势的方法,误差条表示变量的不确定性(置信区间)[4]。绘制线图是为了比较不同分类值的数值变量的变异性 [4]。
让我们举一个实际的例子—-我们继续使用seaborn库和iris数据集(在平行坐标部分中提到)。
importseabornassns sns.pointplot(data=df,x="species",y="sepal_width")
output
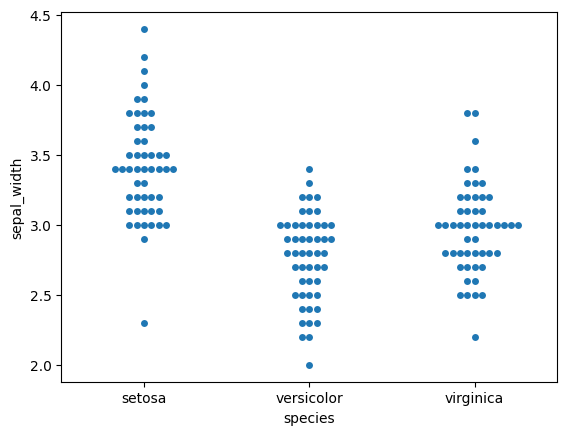
分簇散点图
Swarm plot
Swarm plot是另一个受“beeswarm”启发的有趣图表。通过此图我们可以轻松了解不同的分类值如何沿数值轴分布[5]。它在不重叠数据点的情况下绘制数据。但它不适用于大型数据集。
importseabornassns sns.swarmplot(data=df,x="species",y="sepal_width")
output
旭日图
Sunburst Chart
它是圆环图或饼图的定制版本,将一些额外的层次信息集成到图中 [7]。
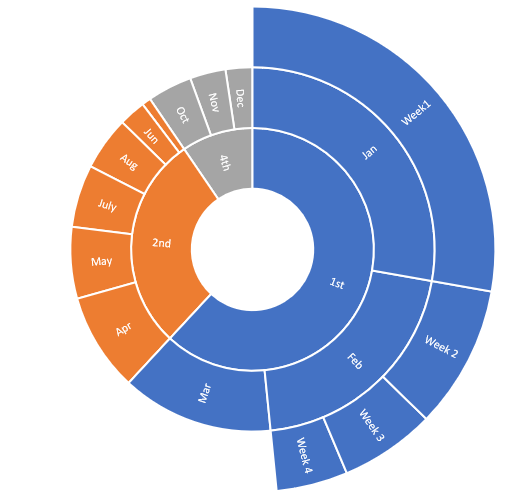
Sunburst Chart
整个图表被分成几个环(从内到外)。它保存层次结构信息,其中内环位于层次结构的顶部,外环位于较低的[7]阶。
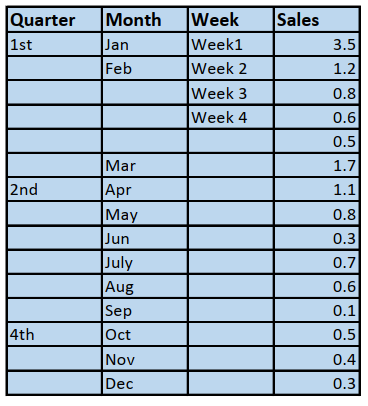
importplotly.expressaspx df=px.data.tips()
output
绘制旭日图
fig=px.sunburst(df,path=['sex','day','time'], values='total_bill',color='time') fig.show()
output
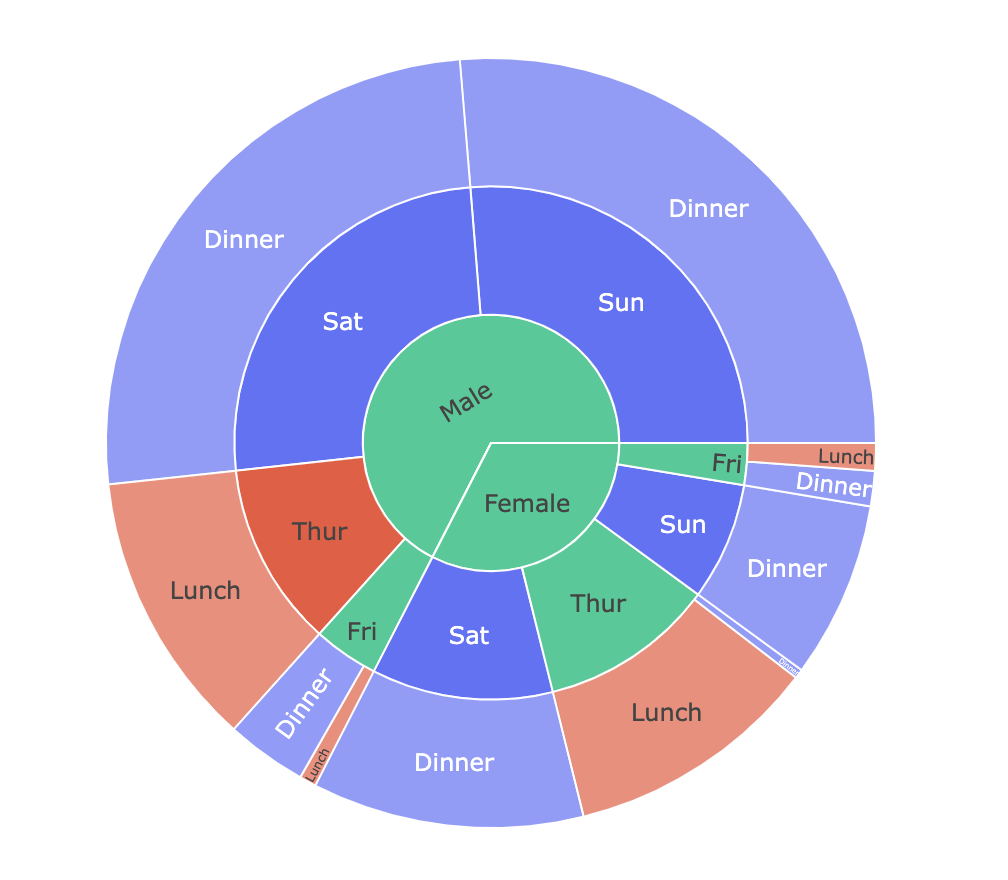
sunburst类的path属性提供了层次结构,其中性别位于层次结构的顶部,然后是日期和时间。
词云
Word Cloud
词云图的想法非常简单。假设我们有一组文本文档。单词有很多,有些是经常出现的,有些是很少出现的。在词云图中,所有单词都被绘制在特定的区域中,频繁出现的单词被高亮显示(用较大的字体显示)。有了这个词云,我们可以很容易地找到重要的客户反馈,热门的政治议程话题等。
数据集 https://opendatacommons.org/licenses/odbl/1-0/
导入数据集
importpandasaspd
data=pd.read_csv('/work/android-games.csv')
data.head()
output
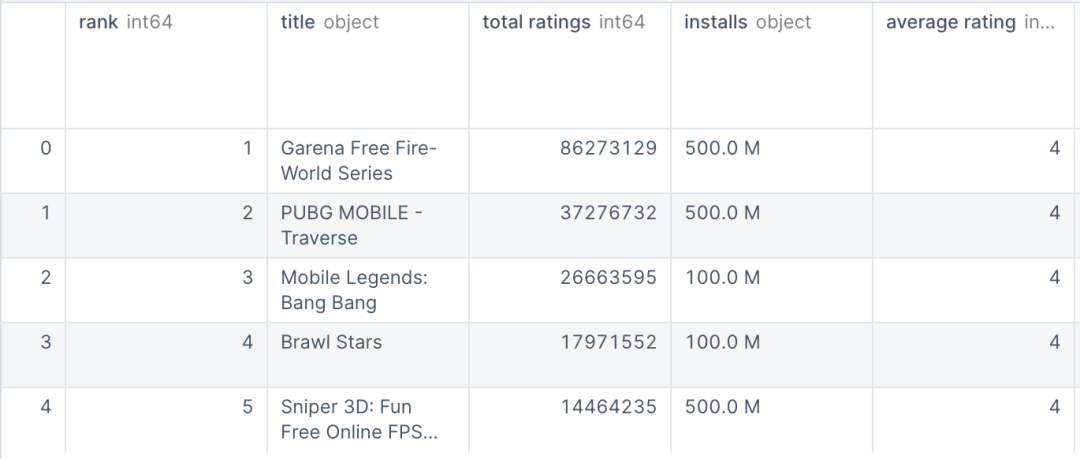
我们统计每个类别的数据数量
data.category.value_counts() GAMECARD126 GAMEWORD104 GAMEACTION100 GAMEADVENTURE100 GAMESTRATEGY100 GAMEPUZZLE100 GAMESIMULATION100 GAMECASUAL100 GAMEARCADE100 GAMEROLEPLAYING100 GAMETRIVIA100 GAMEBOARD100 GAMECASINO100 GAMERACING100 GAMEEDUCATIONAL100 GAMESPORTS100 GAMEMUSIC100 Name:category,dtype:int64
然后我们来进行可视化。
#importingthemodulefromwordcloudlibrary fromwordcloudimportWordCloud importmatplotlib.pyplotasplt #creatingatextfromthecategorycolumnbytakingonlythe2ndpartofthecategory. text="".join(cat.split()[1]forcatindata.category) #generatingthecloud word_cloud=WordCloud(collocations=False,background_color='black').generate(text) plt.imshow(word_cloud,interpolation='bilinear') plt.axis("off") plt.show()
output
该图表显示了频率最高的所有类别。我们也可以用这个图从文本中找到经常出现的单词。
总结
数据可视化是数据科学中不可缺少的一部分。在数据科学中,我们与数据打交道。手工分析少量数据是可以的,但当我们处理数千个数据时它就变得非常麻烦。如果我们不能发现数据集的趋势和洞察力,我们可能无法使用这些数据。希望上面介绍的的图可以帮助你深入了解数据。
以下是本文的引用
https://plotly.com/python/parallel-coordinates-plot/https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.plot.hexbin.html
Hintze, V. P. A Box Plot-Density Trace Synergism. Am. Sat, (52), 181 (Open Access Journal).
seaborn.pointplot — seaborn 0.12.1 documentation (pydata.org)
seaborn.swarmplot—seaborn0.12.1documentation(pydata.org)CreateasunburstchartinOffice—MicrosoftSupport
审核编辑 :李倩
-
数据
+关注
关注
8文章
7209浏览量
89867 -
可视化
+关注
关注
1文章
1203浏览量
21081 -
数据集
+关注
关注
4文章
1211浏览量
24890
原文标题:总结归纳了10个超级实用的数据可视化图表
文章出处:【微信号:DBDevs,微信公众号:数据分析与开发】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
七款经久不衰的数据可视化工具!
什么是大屏数据可视化?特点有哪些?

智慧能源可视化监管平台——助力可视化能源数据管理

智慧楼宇可视化的优点
智慧园区数据可视化优势体现在哪些地方
大屏数据可视化 开源
物联网时代,为什么需要可视化数据大屏

态势数据可视化技术有哪些
智慧大屏是如何实现数据可视化的?

数据可视化:企业数字化建设效果的呈现






 工商网监
工商网监
评论