 Transformer的兴起:提高实时视觉处理的准确度
Transformer的兴起:提高实时视觉处理的准确度
2017 年在 Google的一篇研究论文中首次提出了Transformer模型,它最初是为自然语言处理 (NLP) 任务而设计的。最近,研究人员将Transformer应用在了视觉应用领域(在过去十年中由卷积神经网络 (CNNs) 占据主导地位),并获得了有趣的结果。事实证明,Transformer对图像分类和物体检测等视觉任务的适应性令人惊讶。这些结果为Transformer赢得了在视觉任务中与 CNN 比肩的地位。这些任务旨在提高机器对环境的理解,以用于情境感知视频推理等未来应用。
2012 年,名为 AlexNet 的卷积神经网络(CNN)赢得了 ImageNet 大规模视觉识别挑战赛 (ILSVRC),这是一项年度计算机视觉竞赛。任务是让您的机器学习并“分类”1000 个不同的图像(基于 ImageNet 数据集)。AlexNet 实现了 15.3% 的 top-5 错误率。往届的获胜者是基于传统编程模型,实现的 top-5 错误率大约是 26%(见图 1)。在这之后,CNN 一直占据统治地位。2016 年和 2017 年,获胜的 CNN 实现了比人类更高的准确度。大多数参与者实现了超过 95% 的准确度,促使 ImageNet 在 2018 年推出一项难度更高的全新挑战。CNN 在 ILSVRC 挑战赛中的统治地位推动了人们大量研究如何将 CNN 应用于实时视觉应用。在准确度不断提高的同时,ResNet 和 EfficientNet 分别于 2015 年和 2020 年将效率提升了 10 倍。实时视觉应用不仅需要准确度,还需要更高的性能(推理/秒或每秒帧数 (fps))、缩小模型尺寸(提高带宽),以及功率和面积效率。
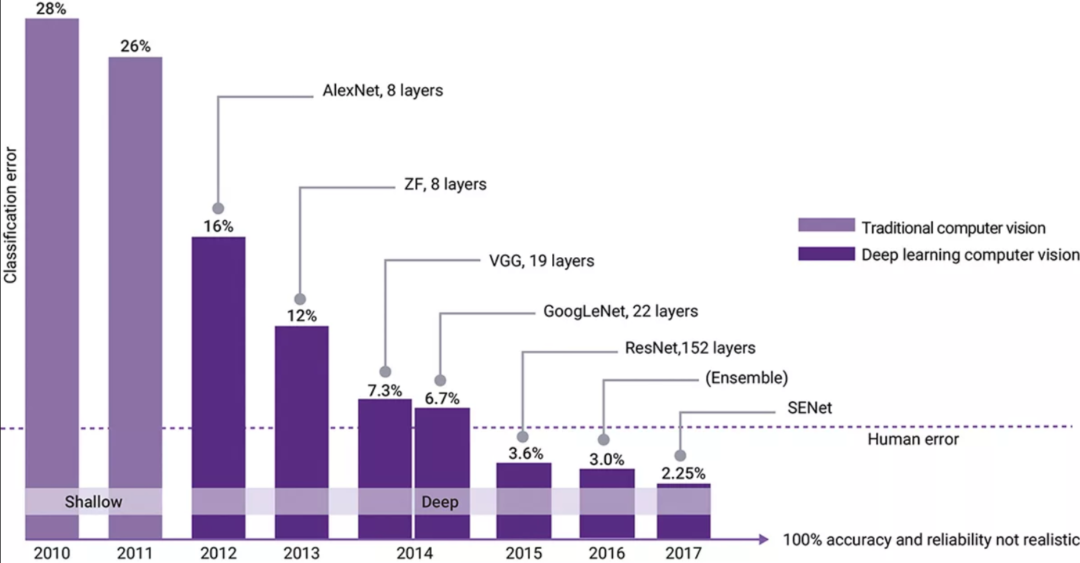
图 1:ILSVRC 结果凸显了 AlexNet(一种卷积神经网络)带来了显著提高的视觉分类准确度。
分类是更复杂、更有用的视觉应用的基石。这些视觉应用包括对象检测(在二维图像中找到对象的位置)、语义分割(对图像中的每个像素进行分组/标记)和全景分割(识别对象位置以及对每个对象中的每个像素进行标记/分组)。2017 年 Google Brain 的论文中首次介绍的Transformer旨在改进递归神经网络 (RNN) 和长短时记忆 (LSTM),用于翻译、问答和对话式 AI 等 NLP 任务。RNN 和 LSTM 已用于处理顺序数据(即数字化语言和语音),但其架构不易并行化,因此通常具有非常有限的带宽,难以训练。Transformer的结构与 RNN 和 LSTM 相比具有几个优势。与必须按顺序读取一串文本的 RNN 和 LSTM 不同,Transformer明显更易并行化,并且可以同时以完整的单词顺序读取,从而更好地学习文本字符串中单词之间的上下文关系。
2018年底,谷歌提出了预训练模型双向编码表征Transformer(BERT),其在多项NLP任务上均取得了突破性的进展,大受欢迎,以至于被纳入 MLCommons 的 MLPerf 神经网络推理基准测试套件中。除了准确度高之外,Transformer还更容易被训练,使大型Transformer成为可能。MTM、GPT-3、T5、ALBERT、RoBERTa、T5、Switch AS 只是处理 NLP 任务的一些大型转换器。由 OpenAI 于 2020 年推出的生成预训练Transformer3 (GPT-3) 使用深度学习来生成类似人类的文本,准确度很高,以至于很难判定该文本是否由人类编写。
像 BERT 这样的Transformer可以成功地应用于其他应用领域,并具有极具前景的嵌入式使用效果。可以在广泛的数据上训练并应用于各种应用的 AI 模型被称为基础模型。在其中的视觉领域,Transformer取得了令人惊叹的成就。
应用于视觉的Transformer
2021 年发生了一些非凡的事情。Google Brain 团队将其Transformer模型应用于图像分类。一连串单词和二维图像之间存在很大差异,但 Google Brain 团队将图像切成小块,将这些小块图像中的像素放入矢量中,并将矢量馈送到Transformer中。结果令人惊讶。在不对模型进行任何修改的情况下,Transformer在分类方面的准确度优于最先进的 CNN。虽然准确度不是实时视觉应用的唯一指标(功率、成本、面积)和推理/秒也很重要),但这在视觉领域中堪称一项重大成果。
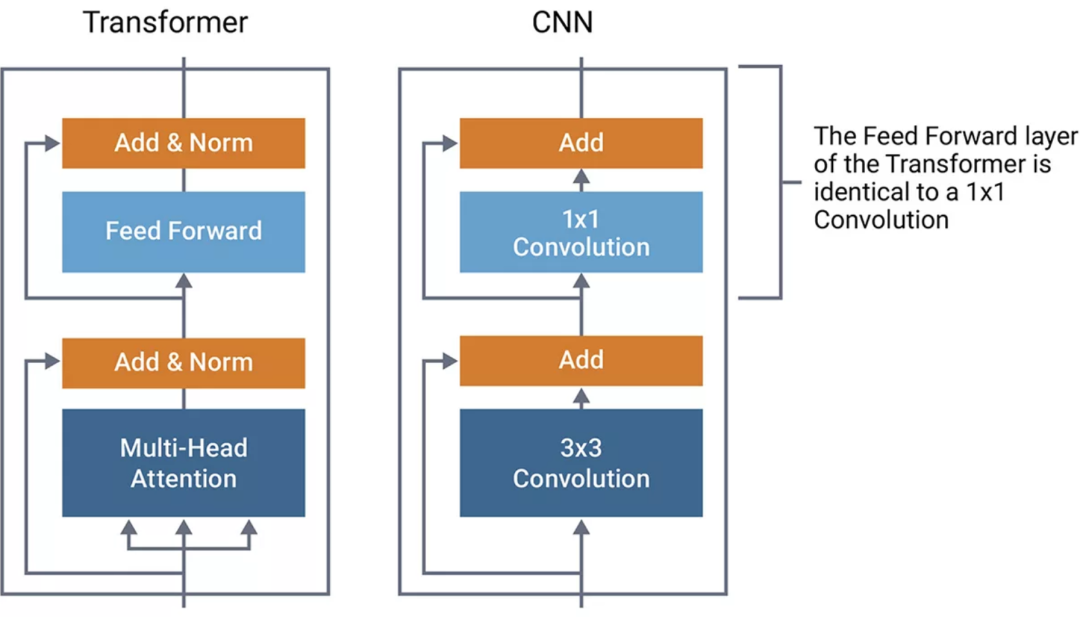
图 2:Transformer和 CNN 结构对比
比较 CNN 和Transformer对了解其类似结构很有帮助。在图 2 中,Transformer的结构由图像左侧的方框组成。为了进行比较,我们使用与 ResNet 中发现的结构类似的典型 CNN 结构来绘制 CNN 的类似结构。ResNet 是具有逐元素加法的 1x1 卷积。我们发现Transformer的前馈部分在功能上与 CNN 的 1x1 卷积相同。这些是矩阵乘法运算,可在特征图中的每个点上应用线性转换。
Transformer和 CNN 之间的区别在于两者如何混合来自相邻像素的信息。这发生在Transformer的多头注意力和卷积网络的 3x3 卷积中。对于CNN,混合的信息基于每个像素的固定空间位置,如图 3 中所示。对于 3x3 卷积,使用相邻像素(中心像素周围的九个像素)计算加权和。
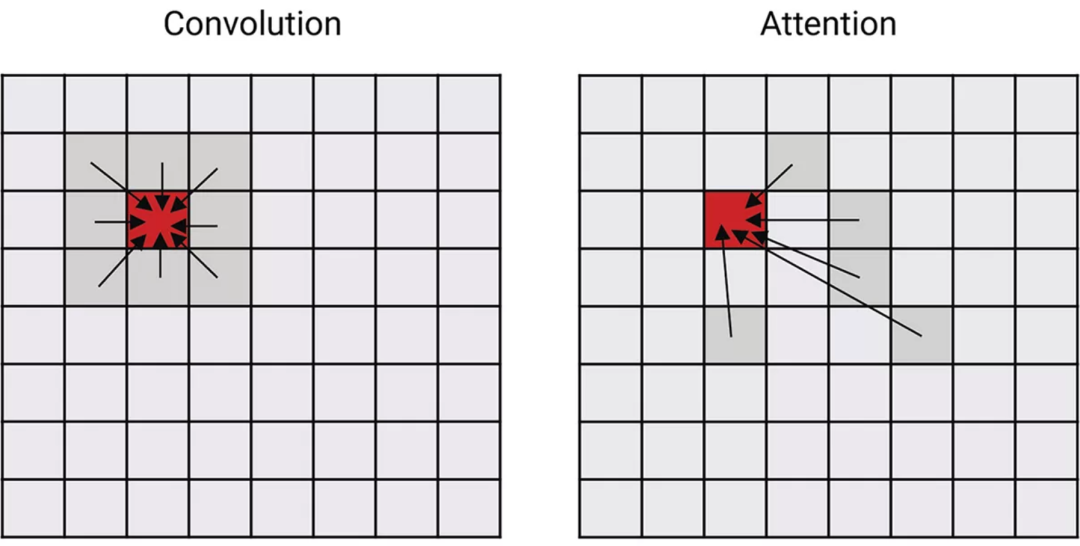
图 3:说明 CNN 的卷积和Transformer的注意力网络在混合其他令牌/像素的特征方面有何差异。
Transformer的注意力机制不仅基于位置,还基于学习属性来混合数据。在训练期间,Transformer可以学习关注其他像素。注意力网络具有更强的学习和表达更复杂关系的能力。
推出视觉Transformer转换器和偏移窗口Transformer
专门用于视觉任务的新型Transformer正在兴起。专门从事图像分类的视觉Transformer (ViT) 现在正在准确度方面击败 CNN(尽管要实现这种准确度,ViT需要用非常大的数据集进行训练)。ViT 还需要更多的计算,这会降低其 fps 性能。
Transformer也正在应用于对象检测和语义分割。Swin(偏移窗口)Transformer为对象检测 (COCO) 和语义分割 (ADE20K) 提供了最先进的准确度。虽然 CNN 通常应用于静态图像,但由于对以前或将来的帧不了解,转换器可以应用于视频帧。SWIN 的变体可直接应用于视频,用于动作分类等用途。将Transformer的注意力分别应用于时间和空间,为 Kinetics-400 和 Kinetics-600 动作分类基准测试提供了最先进的结果。
Apple 于 2022 年初推出的 MobileViT(图 4)提供了Transformer和CNN的有趣组合。MobileViT 结合了Transformer和 CNN 功能,为针对移动应用程序的视觉分类创建了轻量级模型。与仅使用 CNN 的 MobileNet 相比,这种Transformer和CNN的组合使相同尺寸的模型(6M 系数)的准确度提高了 3%。尽管 MobileViT 的性能优于 MobileNet,但它仍然慢于当今支持 CNN 但没有针对Transformer进行优化的手机上的 CNN 实现。要想利用Transformer的优势,未来的视觉 AI 加速器将需要更好的Transformer支持。
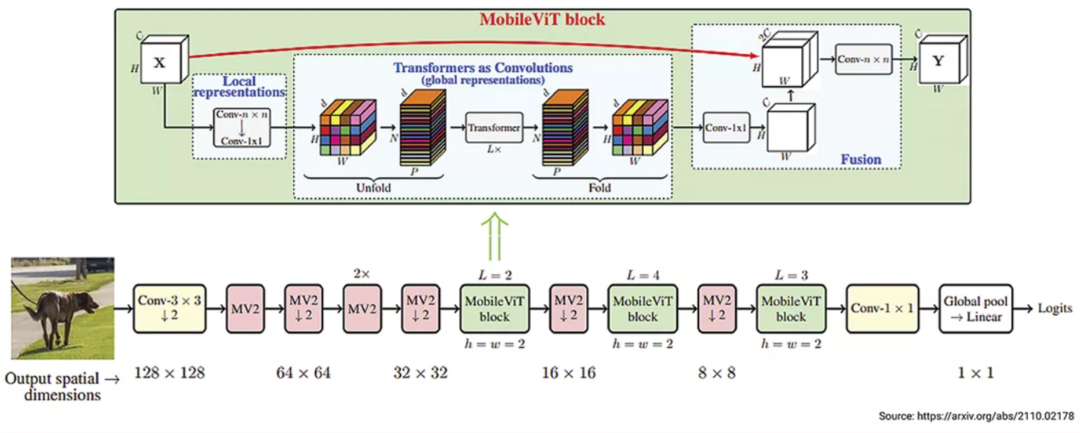
图 4:MobileViT:轻量、通用和移动友好型视觉Transformer(图片来源:https://arxiv.org/abs/2110.02178)
尽管Transformer在视觉任务方面取得了成功,但卷积网络不太可能很快消失。这两种方法之间仍然存在权衡,Transformer具有更高的准确度,但 fps 性能低得多,需要更多的计算和数据移动。为了规避两者的弱点,将Transformer和 CNN 相结合可以产生具有巨大前景的灵活解决方案。
Transformer的实现尽管在架构上存在相似之处,但无法让专门为 CNN 设计的加速器有效地执行Transformer。至少需要考虑架构增强,以处理注意力机制。
新思科技 的 ARC NPX6 NPU IP 是 AI 加速器的一个例子,该加速器旨在高效处理 CNN 和Transformer。NPX6 的计算单元(图 5)包括卷积加速器,该加速器旨在处理对 CNN 和Transformer都至关重要的矩阵乘法。张量加速器也至关重要,因为它旨在处理所有其他非卷积张量算子集架构 (TOSA) 运算,包括Transformer运算。
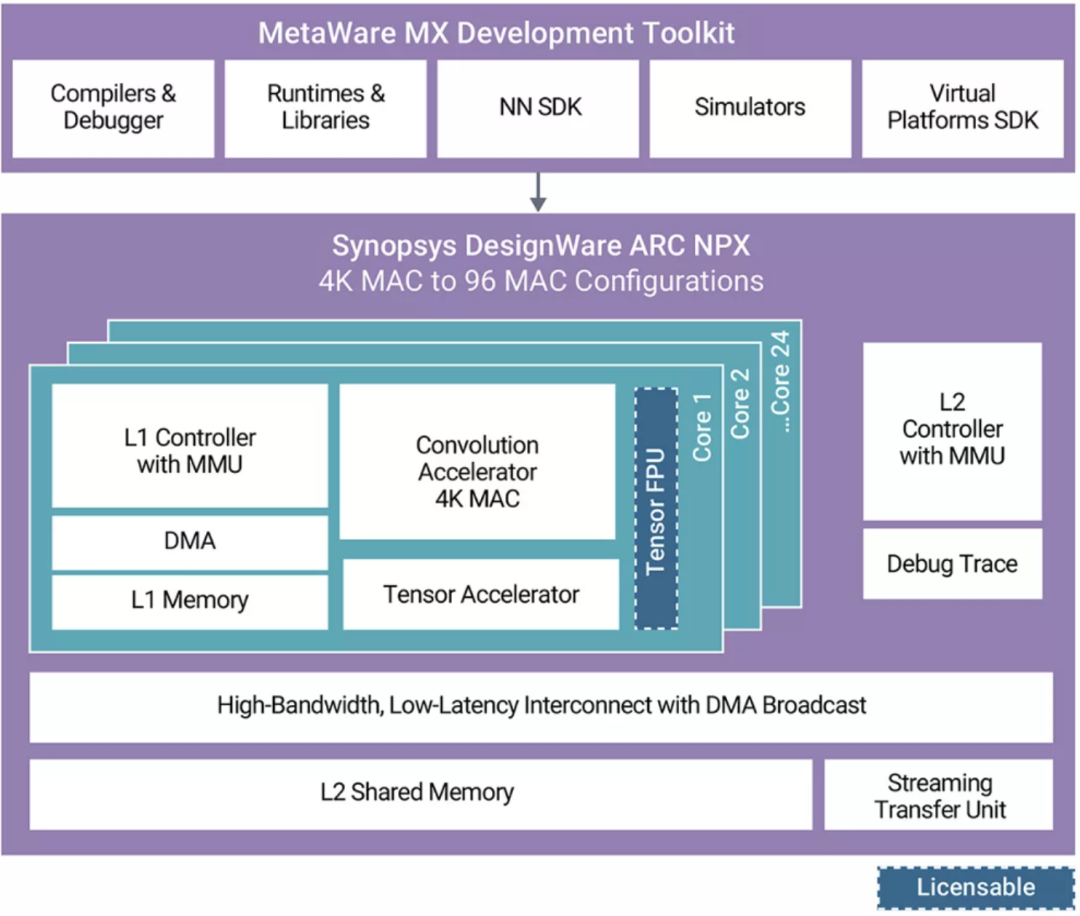
图 5:新思科技 ARC NPX6 NPU IP
总结
视觉Transformer已经取得了快速进步,并将继续保持。这些基于注意力的网络在准确度方面优于仅支持 CNN 的网络。将视觉Transformer与卷积相结合的模型在推理(如 MobileViT)方面更高效,并提高了性能效率。这种新型神经网络模型正在开启解决未来 AI 任务的大门,例如完全视觉感知,其需要的知识单靠视觉可能不易获取。Transformer与 CNN 相结合,引领着新一代 AI 的发展。选择同时支持 CNN 和Transformer的架构,对于新兴 AI 应用的 SoC 成功至关重要。
审核编辑 :李倩
-
神经网络
+关注
关注
42文章
4796浏览量
102178 -
计算机视觉
+关注
关注
8文章
1704浏览量
46449 -
数据集
+关注
关注
4文章
1220浏览量
25183
原文标题:Transformer的兴起:提高实时视觉处理的准确度
文章出处:【微信号:elecfans,微信公众号:电子发烧友网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
利用隔离式精密信号链保持数据采集的准确度
浅谈晶振的频率准确度和频率稳定度

如何使用MATLAB构建Transformer模型

地平线ViG基于视觉Mamba的通用视觉主干网络
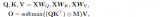
检测饲料发热量仪器|饲料总能量测定仪
高准确度信号链解决方案快速实现七位半DMM
如何实现七位半或更高准确度的DMM
数字压力表的准确度如何?是否适用于精密测量?






 工商网监
工商网监
评论