 新型的端到端弱监督篇幅级手写中文文本识别方法PageNet
新型的端到端弱监督篇幅级手写中文文本识别方法PageNet

本文简要介绍2022年8月发表于IJCV的论文“PageNet: Towards End-to-End Weakly Supervised Page-Level Handwritten Chinese Text Recognition”的主要工作。该工作针对篇幅级手写中文文本识别问题,提出了端到端弱监督的方法PageNet。该方法的主要优势在于:(1)从一个新的角度解决篇幅级中文文本识别问题——检测识别单字并预测单字间的阅读顺序。(2)模型可以弱监督地训练。对于真实数据仅需要标注文本,不需要任何边界框标注,极大地降低了数据的标注成本。(3)尽管只需要文本标注信息,模型却可以预测出单字级和文本行级的检测和识别结果。实验证明这种能力可以应用于对数据进行无需人工干预的高精度的自动标注。(4)该方法深入研究篇幅级文本识别中的阅读顺序问题,所提出的阅读顺序模块可以处理多方向文本、弯曲文本等复杂的阅读顺序。(5)实验证明该方法具有较强的泛化能力,适用于扫描、古籍、拍照和多语言等多种文档类型。
一、背景
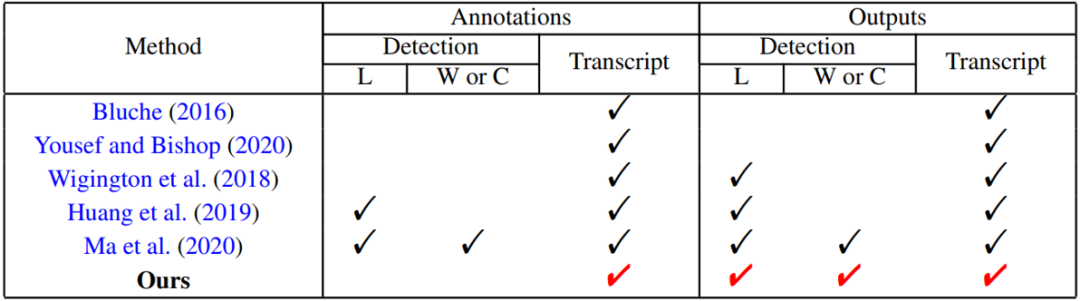
手写中文文本识别是一个具有广泛应用场景的研究方向。目前该领域的相关研究通常关注文本行级的手写中文识别,不考虑在实际应用中因为文本行检测带来的误差。近年来,也有部分研究关注篇幅级的文本识别,但是它们要么仅考虑简单的版面结构,要么需要极为细致的标注信息(文本行级甚至单字级的边界框)。同时,领域内对于阅读顺序的研究较少,而实际应用中会出现多方向文本、弯曲文本等复杂的阅读顺序。为了解决上述问题,这篇文章中提出一种新型的端到端弱监督篇幅级手写中文文本识别方法PageNet。该方法抛弃文本行检测+文本行识别的传统流程,先检测识别单字再预测单字间的阅读顺序,这使得PageNet可以轻松处理复杂的板式和阅读顺序。对于真实数据,PageNet仅需要文本标注,但是可以输出文本行级和单字级的检测和识别结果,省去了标注文本行级和单字级边界框的巨额成本(表1)。实验证明PageNet优于现有的弱监督和全监督篇幅级文本识别方法。
表1 现有方法需要的标注信息和模型输出结果的对比(L: 文本行级,W: 单词级,C:单字级)。PageNet仅需要文本标注即可得到文本行级和单字级的检测和识别结果。
二、方法
2.1算法框架
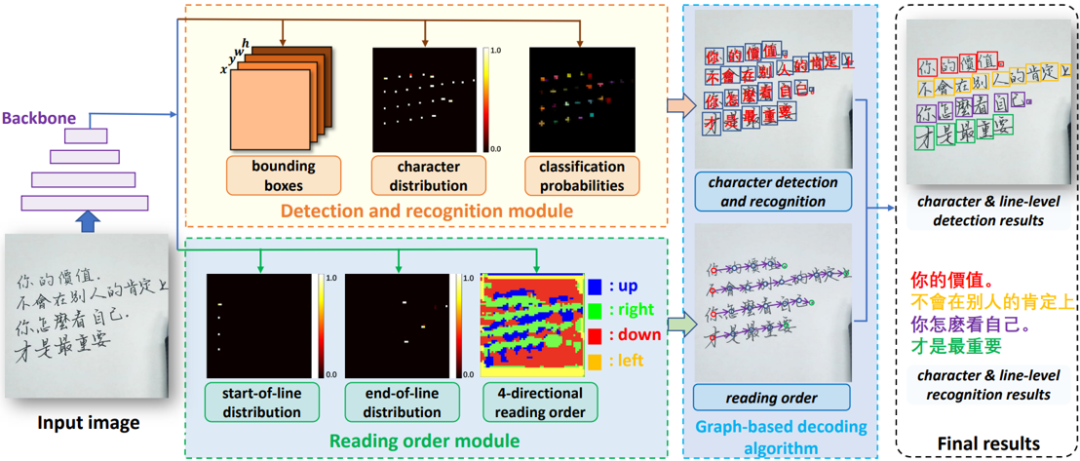
图1 PageNet方法整体框架
PageNet方法的整体框架如图1所示,包括四个部分:(1)主干网络提取输入图像的高维特征;(2)检测和识别模块完成单字的检测识别;(3)阅读顺序模块预测单字间的阅读顺序;(4)基于图的解码算法结合单字的检测识别结果和阅读顺序,得到最终的篇幅级结果。该结果包含文本行级和单字级的检测识别结果。
此外,为了省去人工标注单字和文本行边界框的成本,文章中提出了一种新型的弱监督学习方法 (图4)。借助该方法,仅需要对真实数据标注各行的文本信息即可训练PageNet。
2.2 主干网络
主干网络采用多个残差模块堆叠的结构。对于高为H、宽为W的输入图片,主干网络输出形状为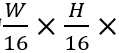 512的特征图。为了方便下文叙述,将
512的特征图。为了方便下文叙述,将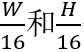 分别标记为
分别标记为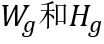 。
。
2.3 检测和识别模块
检测和识别模块参考文献[1]和[2],在主干网络提取的特征的基础上分为三个分支,分别为CharBox、CharDis和CharCls分支。首先将输入图片分为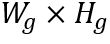 个网格并将第i列第j行的网格标记为
个网格并将第i列第j行的网格标记为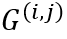 。CharBox分支输出形状为
。CharBox分支输出形状为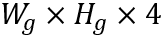 的单字边界框预测
的单字边界框预测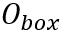 ,其中
,其中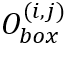 可转换为网格中的单字边界框坐标
可转换为网格中的单字边界框坐标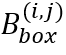 。CharDis分支预测形状为的字符分布
。CharDis分支预测形状为的字符分布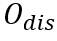 ,其中
,其中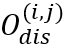 为网格中存在单字的置信度。CharCls分支预测形状为
为网格中存在单字的置信度。CharCls分支预测形状为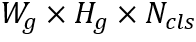 的字符分类结果
的字符分类结果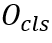 ,其中
,其中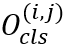 为网格中单字的
为网格中单字的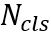 类分类概率。
类分类概率。
2.4 阅读顺序模块
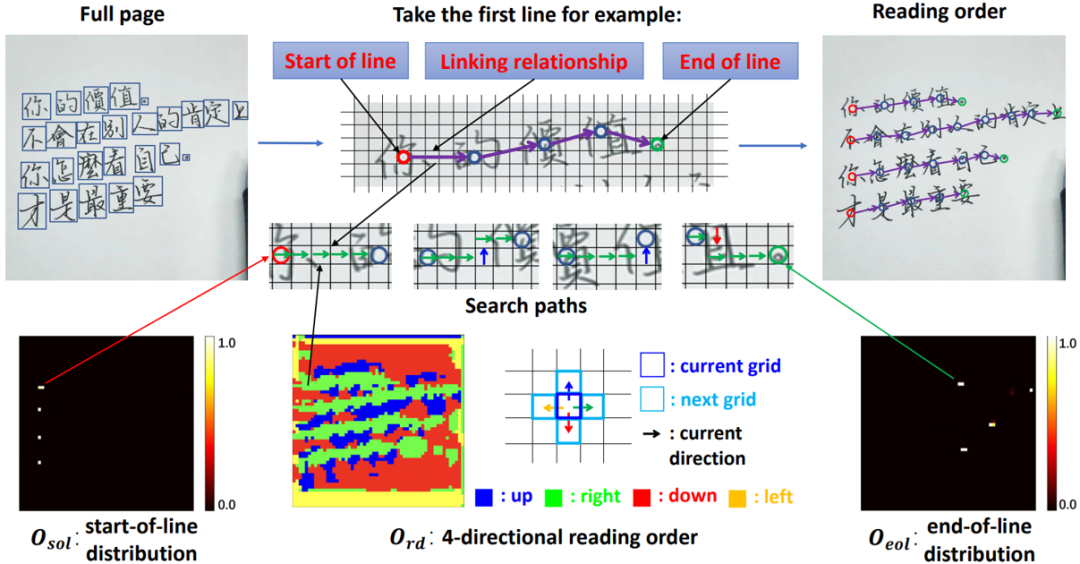
图2 阅读顺序模块框图
阅读顺序模块的整体流程如图2所示。该模块将阅读顺序预测问题分解为:(1)文本行开始字符预测;(2)根据字符间的连接关系逐步找到阅读顺序中的下一个字符;(3)行结束字符预测。其中,字符间的连接关系定义为字符间搜索路径上网格的转移方向(上下左右之一)。
对应地,该模块分别预测:(1)行开始分布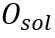 ,其中
,其中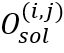 为网格中单字为行开始的置信度;(2)四方向阅读顺序
为网格中单字为行开始的置信度;(2)四方向阅读顺序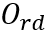 ,其中
,其中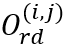 为网格在阅读顺序中向其四个相邻网格的转移方向;(3)行结束分布
为网格在阅读顺序中向其四个相邻网格的转移方向;(3)行结束分布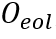 为网格中单字为行结束的置信度。
为网格中单字为行结束的置信度。
2.5 基于图的解码算法
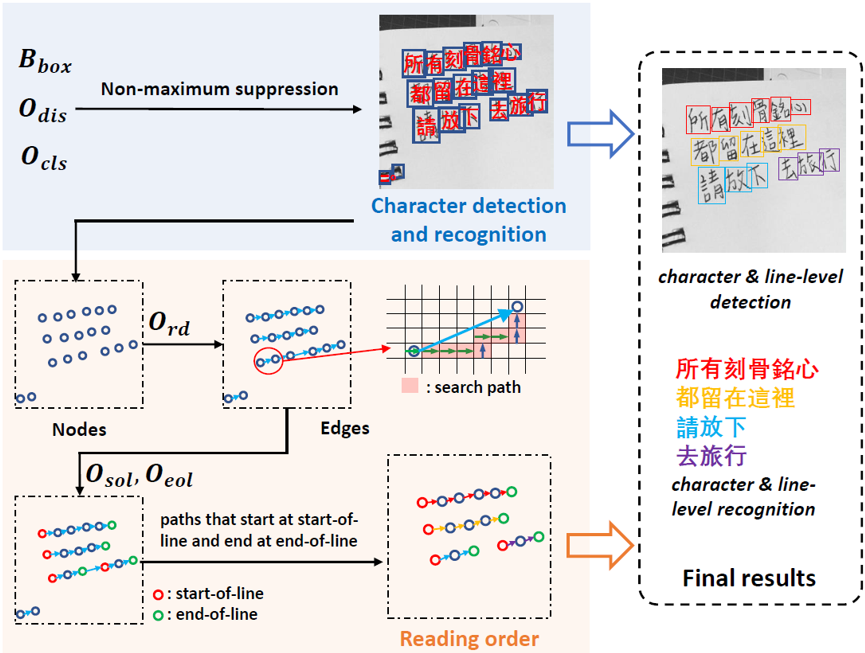
图3 基于图的解码算法流程
基于图的解码算法流程如图3所示。该算法结合检测识别模块和阅读顺序模块的输出,得到最终的单字级和文本行级的检测和识别结果。首先,检测识别模块中三个分支的输出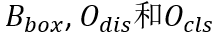 经过非极大值抑制(NMS)得到单字的检测和识别结果;然后,每个单字视为图结构中的一个节点。每个节点根据相应单字框中心点的坐标对应一个网格。接下来,基于四方向阅读顺序,可以逐步根据网格的转移方向找到每个节点在阅读顺序中的下一节点。这种连接关系构成图结构的边。下一步,根据行开始分布和行结束分布,判定行开始节点和行结束节点。最后,保留开始于行开始节点并且结束于行结束节点的路径,得到每个文本行的阅读顺序图。将图中的节点替换为对应的单字检测和识别结果,即可得到单字级和文本行级的检测识别结果。
经过非极大值抑制(NMS)得到单字的检测和识别结果;然后,每个单字视为图结构中的一个节点。每个节点根据相应单字框中心点的坐标对应一个网格。接下来,基于四方向阅读顺序,可以逐步根据网格的转移方向找到每个节点在阅读顺序中的下一节点。这种连接关系构成图结构的边。下一步,根据行开始分布和行结束分布,判定行开始节点和行结束节点。最后,保留开始于行开始节点并且结束于行结束节点的路径,得到每个文本行的阅读顺序图。将图中的节点替换为对应的单字检测和识别结果,即可得到单字级和文本行级的检测识别结果。
2.6 弱监督学习方法
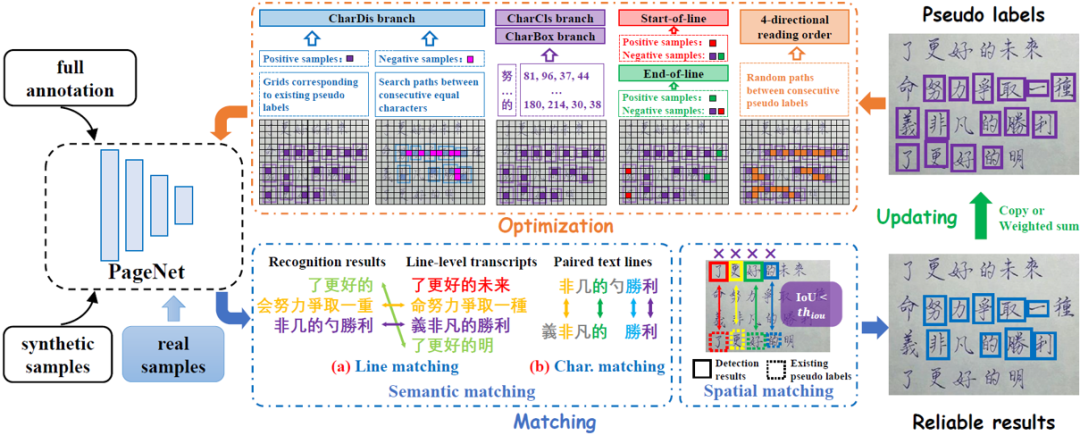
图4 弱监督学习方法整体流程图
弱监督学习方法的整体流程图如图4所示。输入数据包括仅有各行文本标注的真实数据和有完整标注的合成数据。为了验证弱监督学习方法的泛化性,合成数据采用将字体文件生成的汉字贴到简单背景上的方法,因此与真实数据存在较大的差异。弱监督学习方法需要将合成数据中学习到的检测识别能力迁移到多种多样的真实场景中。
对于仅有各行文本标注的真实数据,弱监督学习方法借助伪标注,通过匹配、更新和优化三个步骤完成对模型的训练。(1)匹配分为语义匹配和空间匹配两大类。语义匹配通过行匹配和单字匹配得到模型预测正确的单字。空间匹配是为了解决一张图中存在多行相似或相同的文本造成的匹配模糊问题。(2)通过匹配可以得到识别正确的单字。文章中认为这些单字的边界框是相对准确的。更新过程中使用这些边界框通过复制或加权和的方式更新伪标注。(3)使用更新后的伪标注计算损失优化模型。因为伪标注一般不完全包含所有单字的边界框,模型损失的计算需要进行特殊的设计。特别是对于检测识别模块的CharDis分支,根据伪标注仅知某些网格中存在单字,无法完全判定不存在单字的网格(即负样本)。因此,文章中借助在单字匹配中连续匹配结果为相同的字符。这些字符间根据阅读顺序模块得到的搜索路径中的网格可以以较高置信度判定为不存在单字,如此一来即可优化CharDis分支。其余分支和模块的损失计算方法可参考原文。
三、 实验
3.1 实验数据集
(1)CASIA-HWDB手写中文数据集,包括篇幅级数据集CASIA-HWDB2.0-2.2(5091张图片)和单字数据集CASIA-HWDB1.0-1.2(389万个单字)。
(2)ICDAR2013手写中文比赛测试集,包括篇幅级数据集ICDAR13(300张图片)和单字数据集ICDAR13-SC(22万个单字)。
(3)MTHv2中文古籍数据集,包括3199张古籍图片,分为2399张训练集和800张测试集。
(4)SCUT-HCCDoc拍照手写数据集,包括12253张图片,分为9801张训练集和2452张测试集。
(5)JS-SCUT PrintCC中英文印刷文档数据集,包括398张图片,分为348张训练集和50张测试集。
(6)合成数据集采用真实单字数据或字体生成的单字数据和网络获取的简单纸张背景进行合成。首先将单字组成文本行,再将文本行以一定倾斜度贴在背景上。数据合成不涉及任何语料和其他复杂的光照、视角和扭曲变换等处理。合成数据的示例如图5所示。

图5 合成数据示例
3.2 模型结构
模型结构如图6所示。
图6 模型具体结构图
3.3 评测指标
针对仅标注各行文本内容的弱监督情况,提出了AR*和CR*指标。这两种指标首先将模型预测文本行和标注文本行根据AR进行匹配。对已经匹配的文本行对,计算插入错误、删除错误和替换错误并累积。对于没有被匹配的预测文本行,其中所有单字均视为插入错误。对于没有被匹配的标注文本行,其中所有单字均视为删除错误。最后,采用类似于AR和CR的计算方式,得到AR*和CR*指标。
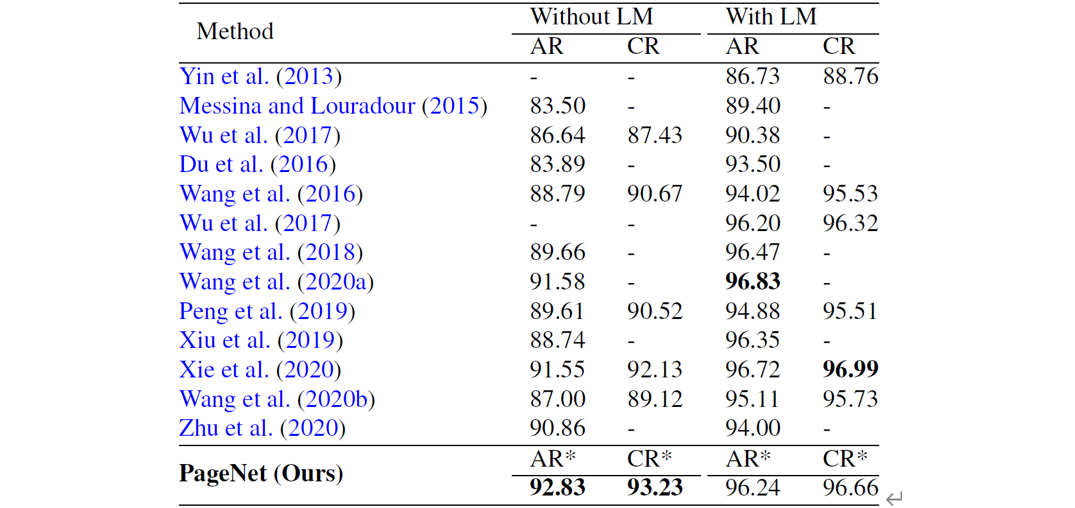
3.4 ICDAR13数据集
PageNet在ICDAR13篇幅级手写中文数据集上的端到端识别指标和文本行检测指标及其与现有方法的对比如下表所示。可以看出,PageNet超过了现有的全监督和弱监督方法,取得SoTA的端到端篇幅级识别指标。
表2 PageNet与现有方法在ICDAR13数据集上的对比

3.5 MTHv2、SCUT-HCCDoc和JS-SCUT PrintCC数据集
PageNet与现有方法在MTHv2、SCUT-HCCDoc和JS-SCUT PrintCC数据集上的端到端识别指标对比如下表所示。可以看出,在MTHv2数据集上,PageNet取得了与最佳的全监督模型相近的端到端识别指标。在SCUT-HCCDoc数据集上,因为该数据集涉及复杂的版面和光照、拍照角度等干扰,这对无真实场景文本位置信息监督的PageNet提出了很大挑战。但是借助合理设计的弱监督学习方法,PageNet大幅度超过了其他弱监督方法且与最佳的全监督模型指标较为接近。在JS-SCUT PrintCC数据集上,PageNet取得了最高的端到端识别指标,证明该方法可以处理中英文混合的文档场景。
表3 PageNet与现有方法在MTHv2、SCUT-HCCDoc和JS-SCUT PrintCC数据集上的对比

3.6 ICDAR13文本行级数据
PageNet与现有方法在ICDAR13文本行数据集(根据标注切出文本行)上的识别指标对比如下表所示。可以看出,虽然PageNet是在篇幅级进行识别且AR*和CR*需要考虑到文本行检测的准确度,但是PageNet的指标仍然超过了现有的文本行级识别方法。这一结果证明了基于单字检测和识别的方法相较于流行的基于CTC/Attention方法更加适合于中文文本识别。
表4 PageNet与现有方法在ICDAR13文本行数据集上的对比
3.7 单字检测识别指标
PageNet与经典检测方法Faster R-CNN和YOLOv3在ICDAR13数据集上的单字检测识别指标如下表所示。可以看到弱监督的PageNet在同时考虑单字检测和识别时(7356C)取得了远超全监督的Faster R-CNN & YOLOv3的指标。
表5 PageNet与Faster R-CNN和YOLOv3在ICDAR13数据集上的单字检测识别指标对比

3.8 实验结果可视化
部分可视化结果如下图所示,图中左侧为单字检测识别结果,右侧为阅读顺序预测结果。更多可视化结果请参见原文。



图6 可视化结果
3.9 其他实验
文章进一步用实验证明了PageNet方法在多方向文本、任意弯曲文本上的有效性。同时,弱监督学习得到的伪标注可以无需人工干预直接用作数据标注,训练出与原始人工标注指标相近的模型。此外,实验证明了PageNet对合成数据与真实场景的相似程度不敏感,保证了PageNet的泛化性。具体实验结果请参见原文。
四、 总结及讨论
该文章中提出一种新型的端到端弱监督篇幅级手写中文文本识别方法PageNet。PageNet从一个全新的角度解决篇幅级文本识别任务,即检测识别单字和预测单字间的阅读顺序。文章提出的弱监督学习方法使得仅需要人工标注各行的文本信息,无需标注文本位置信息,即可训练PageNet得到单字级和文本行级的检测识别结果。在多个不同场景的文档数据集上的实验结果证明了PageNet可以取得超过全监督方法的端到端识别指标。同时,PageNet的篇幅级识别指标也可以超过现有的不考虑文本检测的文本行级识别方法。此外,实验也证明了PageNet可以很好地处理多方向文本和弯曲文本。弱监督学习生成的伪标注可以无需人工干预直接用作标注,训练出与人工标注指标相近的模型。相较于其他方法,PageNet对合成数据与真实场景的相似程度不敏感,可以更好地泛化至多种多样的场景。该文章希望为端到端弱监督篇幅级文本识别领域提供一种新的思路。
五、 相关资源
论文地址1:https://arxiv.org/abs/2207.14807
论文地址2:https://link.springer.com/article/10.1007/s11263-022-01654-0
代码地址:https://github.com/shannanyinxiang/PageNet
参考文献
[1] Dezhi Peng, et al. “A fast and accurate fully convolutional network for end-to-end handwritten Chinese text segmentation and recognition.” Proceedings of International Conference on Document Analysis and Recognition. 2019.
[2] Dezhi Peng, et al. “Recognition of handwritten Chinese text by segmentation: A segment-annotation-free approach.” IEEE Transactions on Multimedia. 2022.
[3] Dezhi Peng, et al. “PageNet: Towards end-to-end weakly supervised page-level handwritten Chinese text recognition” International Journal of Computer Vision. 2022.
原文作者:Dezhi Peng, Lianwen Jin, Yuliang Liu, Canjie Luo, Songxuan Lai
编辑:黄飞
-
Ar
+关注
关注
25文章
5292浏览量
176679 -
数据集
+关注
关注
4文章
1240浏览量
26261 -
半监督学习
+关注
关注
0文章
20浏览量
2766
原文标题:顶刊IJCV 2022!PageNet:面向端到端弱监督篇幅级手写中文文本识别
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
如何在java中去除中文文本的停用词
基于流形学习与SVM的手写字符识别方法
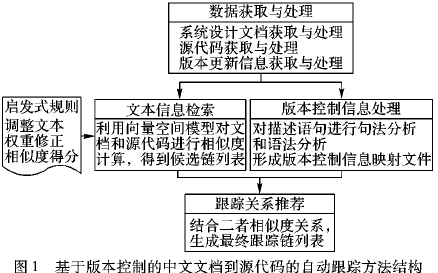
基于版本控制的中文文档到源代码的自动跟踪方法
如何设计一个有限状态转换器的端到端中文语音识别系统
中山大学提出新型行人重识别方法和史上最大最新评测基准

基于神经网络的中文文本蕴含识别模型




评论