 无需实例或类级别3D模型的对新颖物体的6D姿态追踪
无需实例或类级别3D模型的对新颖物体的6D姿态追踪

摘要
大家好,今天为大家带来的文章是BundleTrack: 6D Pose Tracking for Novel Objectswithout Instance or Category-Level 3D Models 跟踪RGBD视频中物体的6D姿态对机器人操作很重要。然而,大多数先前的工作通常假设目标对象的CAD 模型,至少类别级别,可用于离线训练或在线测试阶段模板匹配。
这项工作提出BundleTrack,一个通用的新对象的 6D 姿态跟踪框架,它不依赖于实例或类别级别的 3D 模型。
它结合了最新视频分割和鲁棒特征提取的深度学习,以及具有记忆功能的姿势图优化实现时空一致性。
这使得它能进行长期、低漂移在各种具有挑战性的场景下的6D姿态跟踪,测试了包括重大遮挡和物体运动的场景。
在2个公开数据集上的大量实验表明,BundleTrack显着优于最先进的类别级别6D 跟踪或动态SLAM 方法。
比较时反对依赖于对象实例 CAD 的最新方法模型,尽管提出了可比的性能方法的信息需求减少。
一个高效的在 CUDA 中的实现提供了实时性能。整个框架运行速度达10Hz。


背景与贡献
本文有以下贡献:
1.一个全新的6D物体姿态算法,不需要实例或类级别的CAD模型用于训练或测试阶段。该算法可立即用于新颖物体的6D姿态跟踪
2.在NOCS数据集上的创下全新记录,将以往的表现从33.3%大幅度提升到87.4%。在YCBInEOAT数据集上也达到了跟目前基于CAD模型的领先方法se(3)-TrackNet相近的表现。特别值得注意的是,与以往state of art的6D物体姿态跟踪方法相比,BundleTrack并不需要类级别的物体进行训练,也不需要测试阶段物体的CAD模型作模板匹配,减少了很多假设。
3.首次将具有记忆功能的位姿图优化引入6D物体姿态跟踪。除了相邻帧的匹配还能够借助带记忆功能的历史帧解决特征匹配不足和跟踪漂移问题。以MaskFusion为例的tracking-via-reconstruction方法经常因为任何一帧微小错误的姿态估计进行错误的全局模型构建融合,进而继续影响接下来的全局模型到观测点云的匹配,造成不可逆转的跟踪漂移。而BundleTrack则不存在此类问题。
4.高效的CUDA编码,使得本来计算量庞大的位姿优化图能在线实时运行,达到10Hz。足够用于AR/VR,视觉反馈控制操纵,物体级SLAM或动态场景下的 SLAM等
问题设置
对于需要6D跟踪的物体,该方法不需要任何类级别的CAD模型或者当前物体的CAD模型。所需要的输入只有(1)RGBD视频;(2)初始掩码,用于指定需要跟踪的物体。该掩码可以通过多种途径获得,例如语义分割,3D点云分割聚类,平面移除等等。该方法就能输出跟踪物体在相机前相对初始的 6D姿态变换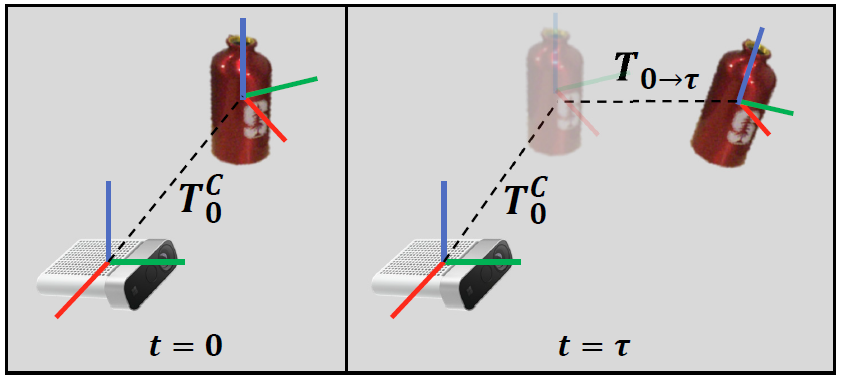
算法流程
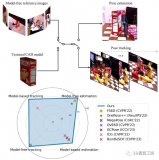
A. 方法总览
当前观察到的 RGB-D视频流首先送到视频分割模块对目标物体提取ROI。分割后的图片被裁剪、调整大小并发送到关键点检测网络来计算关键点和特征描述符。
一种数据关联过程包括特征匹配和以 RANSAC 的方式进行修剪识别特征对应。基于这些特征匹配,当前帧与前一相邻帧之间进行初步粗略匹配。
该比配可以用闭式求解,然后用于提供粗略两个帧之间的转换估计Tt~。在接下来的位姿图优化中,Tt~讲用于初始化当前节点。为了确定位姿图中的其余节点,我们从历史保留的关键帧内存池中选择不超过K个关键帧参与位姿图优化。选择 K 而不用所有历史帧是为了平衡效率与准确性权衡。
姿态图边包括稀疏特征和稠密点到平面的投影残差,所有这些在 GPU 上并行计算。姿势图优化步骤在线输出当前时间戳优化后姿态。通过检查当前帧优化后的姿态的视角,如果它来自新的视角,那么它将会存储在内存池中,以备将来用作关键帧参与位姿图优化。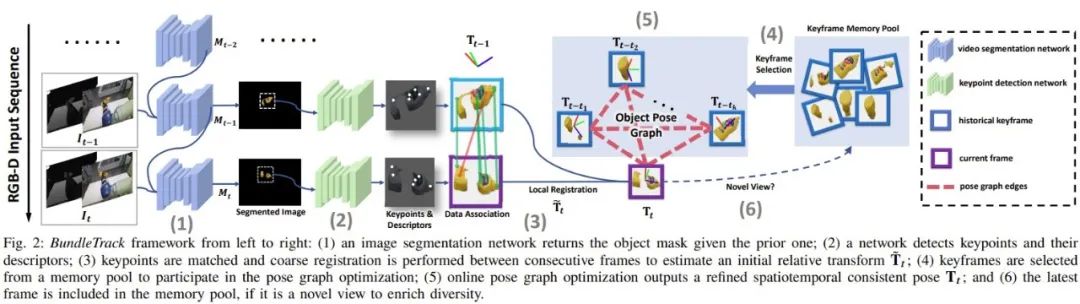
B.视频分割
第一步是将对象的图像区域从背景分割。先前的工作 MaskFusion 使用 Mask-RCNN 计算视频每一帧中的对象掩码。它对每个新帧独立处理,效率较低并导致不连贯性。
为了避免这些限制,这项工作采用了现成的用于视频对象分割的 transductive-VOS 网络,只需要在Davis 2017和Youtube-VOS 数据集上预训练,泛化到我们的测试场景,而不需要任何物体的CAD模型进行训练。虽然当前的实现使用 transductive-VOS,本文所提出的整个框架不依赖于这个特定的网络。
如果可以通过更简单的方法计算对象掩码意味着,例如在机械臂操纵场景下,利用前向运动学,计算机械臂的位置进行点云过滤操作场景,便可以替代视频分割网络模块,更为简单。
C. 特征点检测,匹配和局部配准 局部匹配是在连续的当前帧和前一帧之间来计算初始粗略姿态估计 。
为此,在每个图像上检测到的关键点之间进行匹配用于6D姿态配准。不同于先前的工作 6PACK,6PACK依赖于在类别级别的 3D 模型上离线续联,学习固定数量的类别级语义关键点。
相反,本文中BundleTrack旨在提高泛化能力,而不是局限于某些实例或者类别。选择 LF-Net进行特征点检测是因为它令人满意性能和推理速度之间的平衡。
它只需要对一般 2D 图像进行训练,例如此处使用的 ScanNet 数据集 ,并推广到新的场景。该训练过程不需要收集任何CAD模型,并且一旦训练完成,在所有实验中都不需要finetune。


主要结果
实验在2个公开数据集上展现了优越表现。NOCS是类级别的静态桌面物体场景。YCBInEOAT是机器人操纵场景下的动态场景。值得注意的是,即使BundleTrack不需要任何CAD模型,反而远超此前的state of art方法6PACK:从33.3%提升到87.4%。与实例级别的state of art方法se(3)-TrackNet相比,仅有微小的差距。
以下曲线图反映了跟踪漂移。BundleTrack的6D姿态跟踪错误从视频开始到结束几乎不变。(左)旋转错误随时间变化。(右)平移错误随时间变化。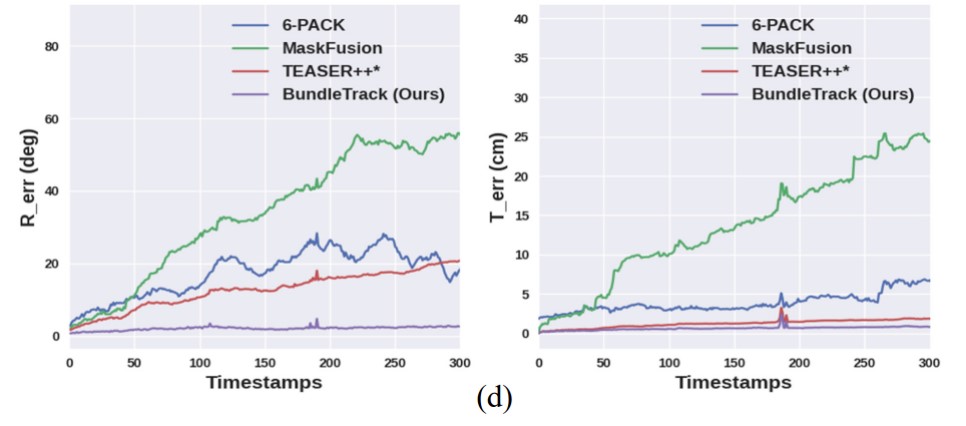
审核编辑:刘清
-
CAD
+关注
关注
18文章
1144浏览量
76931 -
SLAM
+关注
关注
24文章
460浏览量
33425 -
CUDA
+关注
关注
0文章
128浏览量
14551
原文标题:论文精读|BundleTrack:无需实例或类级别3D模型的对新颖物体的6D姿态追踪
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
玩转 KiCad 3D模型的使用

Altium designer 6(AD6)建立器件简易 3D 模型的方法
AD的3D模型绘制功能介绍
细数世界最新颖的几大3D打印技术
一种基于深度神经网络的迭代6D姿态匹配的新方法
英伟达提出了同时对未知物体进行6D追踪和3D重建的方法


一个用于6D姿态估计和跟踪的统一基础模型



评论