 图像处理技术面临哪些挑战?
图像处理技术面临哪些挑战?
当人类观看图像时,会感知物体、人物或景观。当机器“查看”图像时,他们看到的只是代表单个像素的数字。假设一个灰度图像,每个像素由一个通常在0到255之间的数字表示,其中0表示黑色(无颜色),255表示白色(全强度)。0到255之间的任何一个都是灰色阴影,如下图所示。
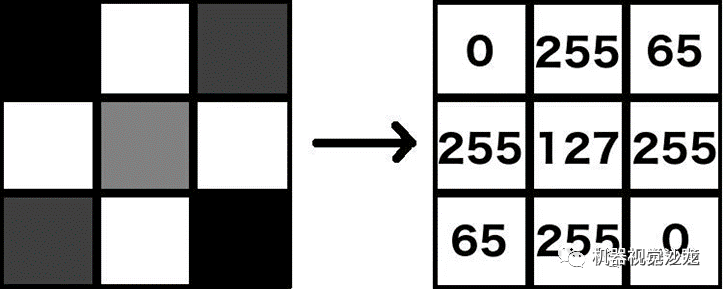
因此,对于任何要获取图像内容的机器来说,它必须以某种方式处理这些数字。
数据量大
正如上面所说,当涉及到图像时,计算机得到的是很多数字,意味着需要大量的处理才能被理解。举一个例子来说明图像的数据量究竟有多大。如果是具有1920x1080分辨率的灰度(黑白)图像,则表示该图像由200万个数字(1920*1080=2073600像素)描述,如果切换到彩色图像,则一般需要三倍的数字。如果试图分析来自视频/摄像机流的图像,假设帧率为30帧/秒(标准帧率),则每秒需要处理1.8亿个数字(3*2073600*30=1.8亿像素)。即使如今我们拥有强大的处理器和相对较大的内存,也是一个巨大的挑战。更何况如今几千万甚至上亿像素的Sensor越来越普及,且其帧率更是高达上百帧/秒。
信息丢失
数字化过程中的信息丢失是造成计算机视觉难度的另一个主要因素。图像处理的本质是从3D世界(如果处理视频流中的数据则是4D)投影到2D平面(即平面图像)上获取信息。这意味着在此过程中会丢失大量信息。人类的大脑可以非常出色的推断出丢失的数据是什么,但是对于计算机来说却是极其困难的挑战。下图显示的是一个凌乱的房间。
人类可以很容易地看出,绿色健身球比桌子上的黑色平底锅更大更远。但是如果黑色平底锅比绿色球占据更多的像素,机器应该如何推断呢?这不是一件容易的事。当然,可以尝试通过同时拍摄两张照片并从中提取3D信息来模拟用两只眼睛看到的方式,这被称为立体视觉。然而,将图像拼接在一起也不是一项微不足道的任务,因为同样是一个开放的研究领域。
伴随噪声
数字化过程中经常伴随着噪音。例如,没有相机会拍摄出一个完美的不含噪声的现实图片,特别是当用手机上的相机进行拍照时,他们会通过调整强度等级,色彩饱和度等去尝试捕捉美丽的世界。同时在图像拍摄过程中肯能会出现“镜头光晕”的现象,人类可以轻松的判断光晕后面是什么场景,而对于计算机来说确实非常困难。 虽然已经有很多去除光晕的算法,但是去除光晕的算法本身也是开放的领域。另外,在图像压缩的过程中会对图像降低像素或者变换操作,而这样的图片对于人来说可以轻松的识别,而对于计算机,如果不告诉它压缩变换的操作,它会当作压缩后的图像为原图像进行识别,从而产生错误。

理解图像含义困难
最后也是最重要的是就是对图像内容的理解。对于机器来说,这绝对是计算机视觉环境中最难处理的事情。当人类观看图像时,会用累积的学习和记忆(称为先验知识)来分析它。例如,人类知道,可以坐在健身球上,而平底锅通常用在厨房里,因为这些东西过去已经了解过。如果有一些东西看起来像天空中的平底锅,很可能它不是平底锅,因此可以进一步仔细检查,以确定对象可能是什么。或者如果有人围着绿球踢球,很可能是小孩子的球而不是健身球。但机器没有这种知识。他们不了解的世界,不了解其中固有的复杂性,以及在数千年的进化中创造的众多工具、商品、设备等。也许有一天机器将能够获得网络并从那里了解有关对象的信息,但目前离这种情况很远。
编辑:黄飞
-
图像处理
+关注
关注
27文章
1280浏览量
56627 -
计算机视觉
+关注
关注
8文章
1696浏览量
45923
原文标题:图像处理技术难点
文章出处:【微信号:机器视觉沙龙,微信公众号:机器视觉沙龙】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论