 使用 NVIDIA DOCA GPUNetIO 进行内联 GPU 数据包处理
使用 NVIDIA DOCA GPUNetIO 进行内联 GPU 数据包处理

越来越多的网络应用程序需要进行 GPU 实时数据包处理,以实现高数据率解决方案:数据过滤、数据放置、网络分析、传感器信号处理等。
一个主要动机是 GPU 可以实现并行处理多个数据包的高度并行性,同时提供可扩展性和可编程性。
有关这些技术的基本概念以及基于 DPDK gpudev 库的初始解决方案的概述,请扫描下方二维码参见文章《通过 GPU 使用 DPDK 和 GPUdev 增强内联数据包处理 》。

这篇文章解释了新的 NVIDIA DOCA GPUNetIO 库如何克服以前 DPDK 解决方案中的一些限制,向以 GPU 为中心的数据包处理应用程序迈进了一步。
介绍
网络数据包的实时 GPU 处理是一种适用于几个不同应用领域的技术,包括信号处理、网络安全、信息收集和输入重建。这些应用程序的目标是实现一个内联数据包处理管线(Pipeline),以在 GPU 内存中接收数据包(无需通过 CPU 内存暂存副本);与一个或多个 CUDA 内核并行地处理它们;然后运行推断、评估或通过网络发送计算结果。
通常,在这个管线中,CPU 是协调人,因为它必须使网卡(NIC)接收活动与 GPU 处理同步。一旦 GPU 内存中接收到新的数据包,这将唤醒 CUDA 内核。类似的方法也可以应用于管线的发送侧。
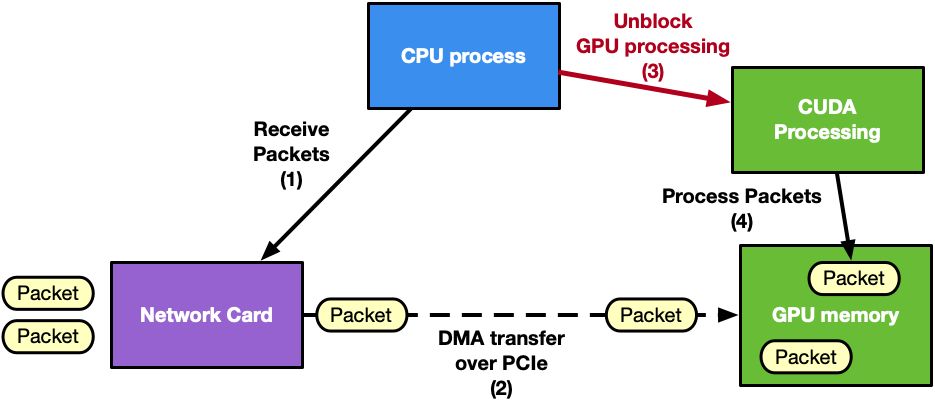
图 1 . 以 CPU 为中心的应用程序, CPU 协调 GPU 和网卡工作
数据平面开发套件(DPDK)框架引入了 goudev 库来为此类应用提供解决方案:使用 GPU 内存(GPUDirect RDMA 技术)结合低延迟 CPU 同步进行接收或发送。
GPU 发起的通信
从图 1 中可以看出,CPU 是主要瓶颈。它在同步 NIC 和 GPU 任务以及管理多个网络队列方面承担了太多的责任。例如,考虑一个具有多个接收队列和 100 Gbps 传入流量的应用程序。以 CPU 为中心的解决方案将具有:
-
CPU 调用每个接收队列上的网络功能,以使用一个或多个 CPU 核心接收 GPU 存储器中的数据包
-
CPU 收集数据包信息(数据包地址、编号)
-
CPU 向 GPU 通知新接收的数据包
-
GPU 处理数据包
这种以 CPU 为中心的方法是:
-
资源消耗:为了处理高速率网络吞吐量(100 Gbps 或更高),应用程序可能需要专用整个 CPU 物理核心来接收(和/或发送)数据包
-
不可扩展:为了与不同的队列并行接收(或发送),应用程序可能需要使用多个 CPU 核心,即使在 CPU 核心的总数可能被限制在较低数量(取决于平台)的系统上也是如此
-
平台依赖性:低功耗 CPU 上的同一应用程序将降低性能
GPU 内联分组处理应用程序的下一个自然步骤是从关键路径中删除 CPU 。移动到以 GPU 为中心的解决方案,GPU 可以直接与 NIC 交互以接收数据包,因此数据包一到达 GPU 内存,处理就可以开始。同样的方法也适用于发送操作。
GPU 从 CUDA 内核控制 NIC 活动的能力称为 GPU 发起的通信。假设使用 NVIDIA GPU 和 NVIDIA NIC ,则可以将 NIC 寄存器暴露给 GPU 的直接访问。这样,CUDA 内核可以直接配置和更新这些寄存器,以协调发送或接收网络操作,而无需 CPU 的干预。
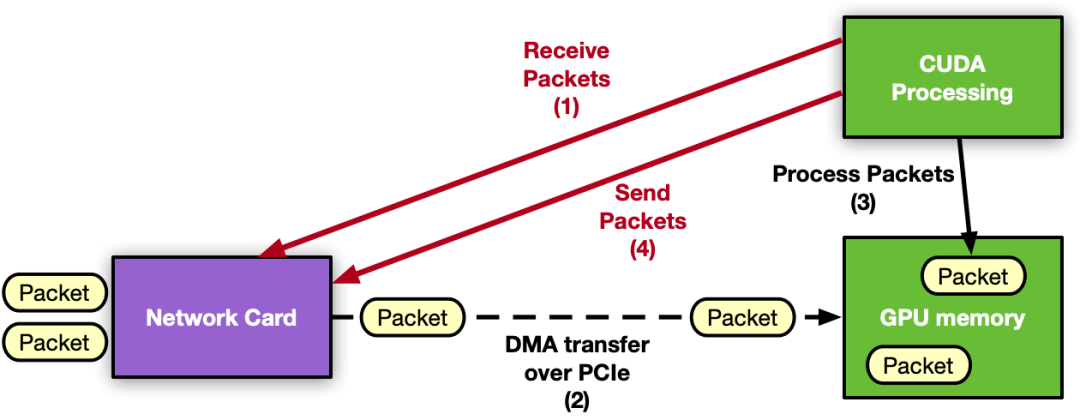
图 2 . 以 GPU 为中心的应用程序,GPU 控制网卡和数据包处理,无需 CPU
根据定义,DPDK 是 CPU 框架。要启用 GPU 发起的通信,需要在 GPU 上移动整个控制路径,这是不适用的。因此,通过创建新的 NVIDIA DOCA 库来启用此功能。
NVIDIA DOCA GPUNetIO 库
NVIDIA DOCA SDK 是新的 NVIDIA 框架,由驱动程序、库、工具、文档和示例应用程序组成。需要这些资源通过利用 NVIDIA 硬件可以在主机系统和 DPU 上可用的网络、安全性和计算功能来支持应用程序。
NVIDIA DOCA GPUNetIO 是在 NVIDIA DOCA 1.5 版本的基础上开发的一个新库,用于在 DOCA 生态系统中引入 GPU 设备的概念(图 3)。为了促进创建以 DOCA GPU 为中心的实时数据包处理应用程序,DOCA GPUNetIO 结合了 GPUDirect RDMA 用于数据路径加速、智能 GPU 内存管理、CPU 和 GPU 之间的低延迟消息传递技术(通过 GDRCopy 功能)和 GPU 发起的通信。
这使 CUDA 内核能够直接控制 NVIDIA ConnectX 网卡。为了最大化性能, DOCA GPUNetIO 库必须用于 GPUDirect 友好的平台,其中 GPU 和网卡通过专用 PCIe 网桥直接连接。DPU 融合卡就是一个示例,但同样的拓扑也可以在主机系统上实现。
DOCA GPUNetIO 目标是 GPU 数据包处理网络应用程序,使用以太网协议在网络中交换数据包。对于这些应用程序,不需要像基于 RDMA 的应用程序那样,通过 OOB 机制跨对等端进行预同步阶段。也无需假设其他对等端将使用 DOCA GPUNetIO 进行通信,也无需了解拓扑。在未来的版本中,RDMA 选项将被启用以覆盖更多的用例。
DOCA 当前版本中启用的 GPUNetIO 功能包括:
-
GPU 发起的通信: CUDA 内核可以调用 DOCA GPUNetIO 库中的 CUDA device 函数,以指示网卡发送或接收数据包
-
精确的发送调度:通过 GPU 发起的通信,可以根据用户提供的时间戳来调度未来的数据包传输
-
GPU Direct RDMA :以连续固定大小 GPU 内存步幅接收或发送数据包,无需 CPU 内存暂存副本
-
信号量:在 CPU 和 GPU 之间或不同 GPU CUDA 内核之间提供标准化的低延迟消息传递协议
-
CPU 对 CUDA 内存的直接访问:CPU 可以在不使用 GPU 内存 API 的情况下修改 GPU 内存缓冲区
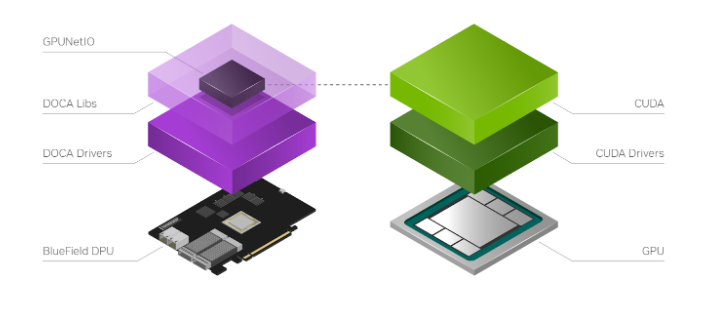
图 3 . NVIDIA DOCA GPUNetIO 是一个新的 DOCA 库,需要在同一平台上安装 GPU 和 CUDA 驱动程序和库
如图 4 所示,典型的 DOCA GPUNetIO 应用程序步骤如下:
CPU 上的初始配置阶段:
-
使用 DOCA 识别和初始化 GPU 设备和网络设备
-
使用 DOCA GPUNetIO 创建可从 CUDA 内核管理的接收或发送队列
-
使用DOCA Flow确定应在每个接收队列中放置哪种类型的数据包(例如,IP 地址的子集、TCP 或 UDP 协议等)
-
启动一个或多个 CUDA 内核(执行数据包处理/过滤/分析)
CUDA 内核内 GPU 上的运行时控制和数据路径:
-
使用 DOCA GPUNetIO CUDA 设备函数发送或接收数据包
-
使用 DOCA GPUNetIO CUDA 设备函数与信号量交互,以使工作与其他 CUDA 内核或 CPU 同步
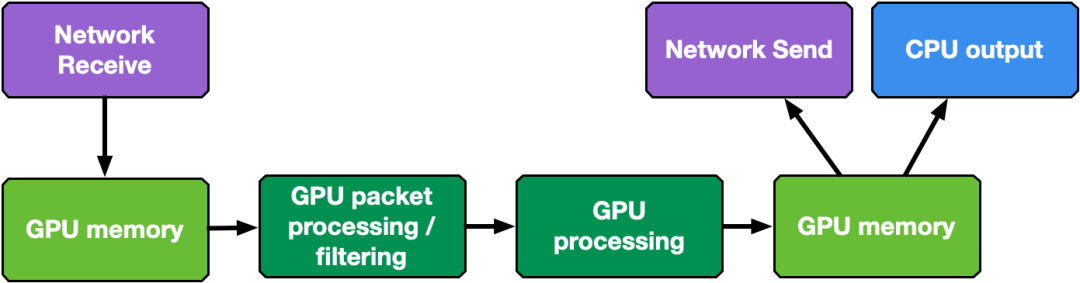
图 4 . 由多个构建块组成的通用 GPU 数据包处理管线数据流
以下各节概述了结合 DOCA GPUNetIO 构建块的可能 GPU 数据包处理管线应用程序布局。
CPU 接收和 GPU 处理
第一个示例以 CPU 为中心,不使用 GPU 发起的通信功能。它可以被视为以下章节的基线。CPU 创建可从 CPU 自身管理的接收队列,以接收 GPU 存储器中的数据包,并为每个队列分配流量控制规则。
在运行时,CPU 接收 GPU 存储器中的数据包。它通过 DOCA GPUNetIO 信号量向一个或多个 CUDA 内核通知每个队列新一组数据包的到达,提供 GPU 内存地址和数据包数量等信息。在 GPU 上,CUDA 内核轮询信号量,检测更新并开始处理数据包。
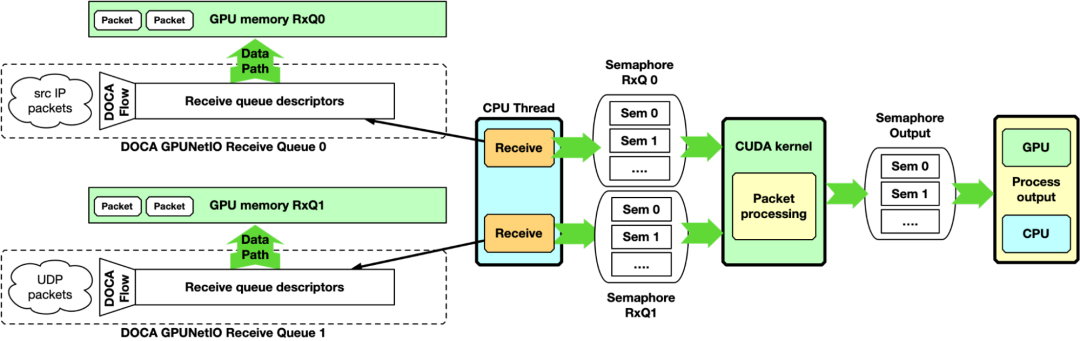
图 5 . GPU 数据包处理管道,CPU 在 GPU 内存中接收数据包,并使用 NVIDIA DOCA GPUNetIO 信号量通知数据包处理 CUDA 内核有关传入数据包
这里,DOCA GPUNetIO 信号量具有类似于 DPDK gpudev communication list 的功能,使得 CPU 接收数据包和 GPU 在处理这些数据包之前等待接收这些数据包之间能够实现低延迟通信机制。信号量还可用于 GPU 在包处理完成时通知 CPU ,或在两个 GPU CUDA 内核之间共享关于已处理包的信息。
该方法可作为性能评估的基准。由于它以 CPU 为中心,因此严重依赖 CPU 型号、功率和内核数量。
GPU 接收和 GPU 处理
上一节中描述的以 CPU 为中心的管线可以通过以 GPU 为中心的方法进行改进,该方法使用 GPU 发起的通信,使用 CUDA 内核管理接收队列。以下部分提供了两个示例:多 CUDA 内核和单 CUDA 内核。
多 CUDA 内核
使用这种方法,至少涉及两个 CUDA 内核,一个专用于接收数据包,另一个专用用于数据包处理。接收器 CUDA 内核可以通过信号量向第二 CUDA 内核提供数据包信息。
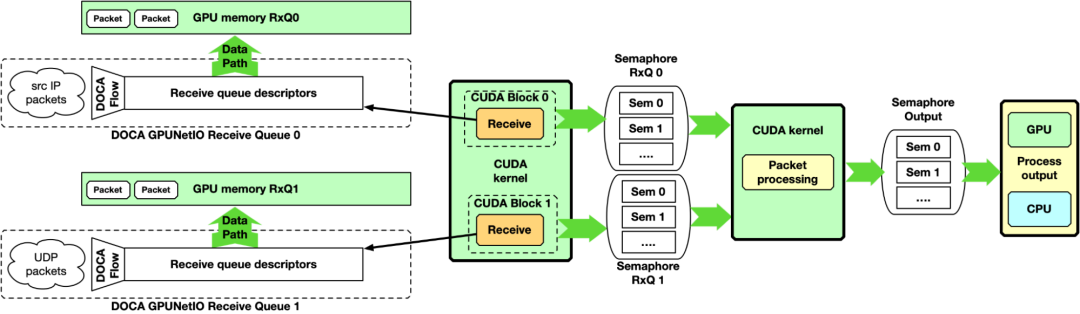
图 6 . GPU 数据包处理管线,CPU 在 GPU 内存中接收数据包,并使用 DOCA GPUNetIO 信号量通知数据包处理 CUDA 内核有关传入数据包
这种方法适用于高速网络和延迟敏感的应用程序,因为两个接收操作之间的延迟不会被其他任务延迟。期望将接收器 CUDA 内核的每个 CUDA 块关联到不同的队列,并行地接收来自所有队列的所有数据包。
单 – CUDA 内核
通过使单个 CUDA 内核负责接收和处理数据包,仍然为每个队列专用一个 CUDA 块,可以简化先前的实现。
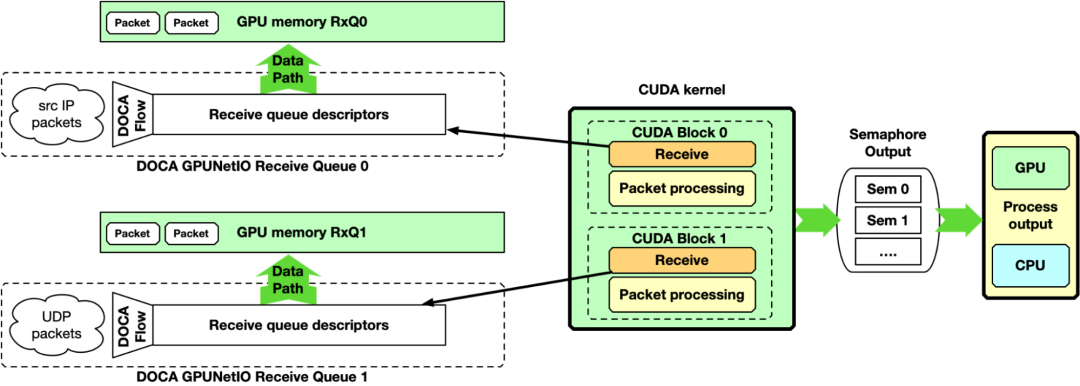
图 7 . GPU 数据包处理管线,单个 GPU CUDA 内核接收 GPU 内存中的数据包并进行数据包处理
这种方法的一个缺点是每个 CUDA 块两个接收操作之间的延迟。如果数据包处理需要很长时间,应用程序可能无法跟上在高速网络中接收新数据包的速度。
GPU 接收、 GPU 处理和 GPU 发送
到目前为止,大多数关注点都集中在管线的“接收和处理”部分。然而,DOCA GPUNetIO 还可以在 GPU 上生成一些数据,制作数据包并从 CUDA 内核发送,而无需 CPU 干预。图 8 描述了一个完整的接收、处理和发送管线的示例。
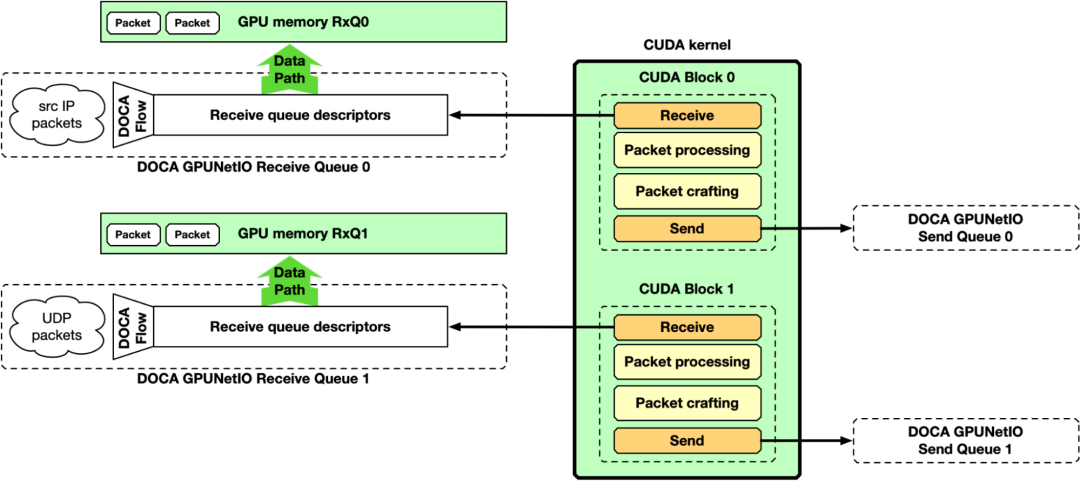
图 8 . 具有 GPU CUDA 内核的 GPU 数据包处理管线在 GPU 内存中接收数据包,进行数据包处理,最后制作新数据包
NVIDIA DOCA GPUNetIO 示例应用程序
与任何其他 NVIDIA DOCA 库一样,DOCA GPUNetIO 有一个专用应用程序,用于 API 使用参考和测试系统配置和性能。该应用程序实现了前面描述的管线,提供了不同类型的数据包处理,如 IP 校验和、HTTP 数据包过滤和流量转发。
以下部分概述了应用程序的不同操作模式。报告了一些性能数据,将其视为可能在未来版本中更改和改进的初步结果。使用两个基准系统,一个用于接收数据包,另一个用于发送数据包,背靠背连接(图 9)。
运行 DOCA GPUNetIO 应用程序的接收器是带有 NVIDIA BlueField-2X DPU 融合卡的 Dell PowerEdge R750 。该配置为嵌入式 CPU 模式,因此应用程序使用 DPU 上的 NVIDIA ConnectX-6 Dx 网卡和 GPU A100X 在主机系统 CPU 上运行。软件配置为 Ubuntu 20.04 、MOFED 5.8 和 CUDA 11.8 。
发送器是 Gigabyte Intel Xeon Gold 6240R ,其通过 PCIe Gen 3 与 NVIDIA ConnectX-6 Dx 连接。此计算机不需要任何 GPU ,因为它运行 T-Rex DPDK packet generator v2.99 。软件配置为 Ubuntu 20.04 和 MOFED 5.8 。
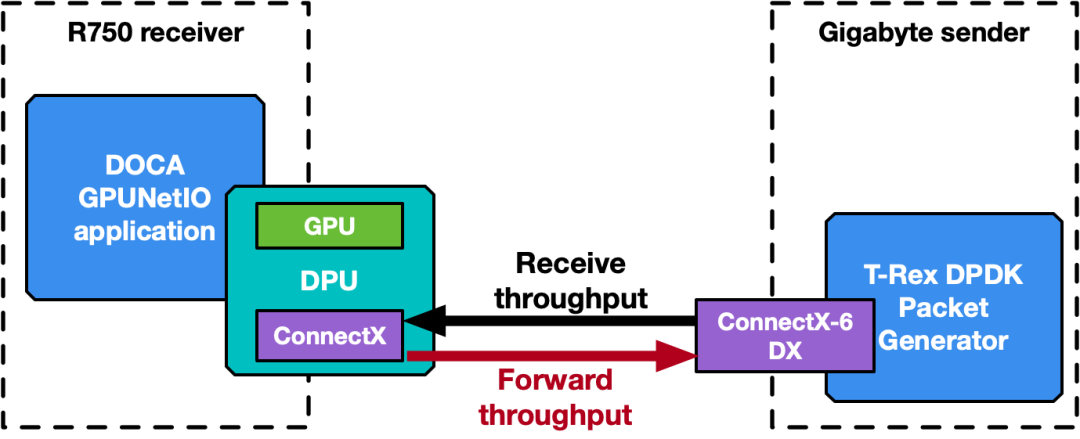
图 9 . 接收器(Dell R750)和发送器(Gigabyte)系统背靠背连接到基准 NVIDIA DOCA GPUNetIO 应用程序
该应用程序也已在 DPU Arm 内核上执行,导致了相同的性能结果,并证明了以 GPU 为中心的解决方案与 CPU 无关。
请注意,DOCA GPUNetIO 最低要求是具有 GPU 和具有直接 PCIe 连接的 NIC 的系统。DPU 并不是严格要求。
IP 校验和, GPU 仅接收
应用程序使用 GPU 发起的通信来创建一个或多个接收队列以接收分数据包。可以使用单 CUDA 内核或多 CUDA 内核模式。

图 10 . NVIDIA DOCA GPUNetIO 应用程序中的第一个管线模式:GPU 接收、计算 IP 校验和并向 CPU 报告
每个数据包都通过简单的 IP 校验和验证进行处理,只有通过此测试的数据包才算作“好数据包”。通过信号量,好数据包的数量被报告给 CPU ,CPU 可以在控制台上打印报告。
通过使用 T-Rex 数据包生成器以约 100 Gbps(约 11.97 Mpps)的速度发送 30 亿个 1 KB 大小的数据包,并在 DOCA GPUNetIO 应用程序侧报告相同数量的数据包以及正确的 IP 校验和,实现了单队列零数据包丢失。相同的配置在 BlueField-2 融合卡上进行了测试,结果相同,证明了 GPU 发起的通信是一个独立于平台的解决方案。
由于数据包大小为 512 字节,T-Rex 数据包生成器无法发送超过 86 Gbps(约 20.9 Mpps)的数据包。即使每秒数据包的数量几乎是两倍,DOCA GPUNetIO 也没有报告任何数据包丢失。
HTTP 过滤, GPU 仅接收
假设一个更复杂的场景,数据包处理 CUDA 内核只过滤具有特定特征的 HTTP 数据包。它将“好数据包”信息复制到第二个 GPU 内存 HTTP 数据包列表中。一旦此 HTTP 数据包列表中的下一个项目充满了数据包,通过专用信号量,过滤 CUDA 内核就会解除第二个 CUDA 内核的阻止,从而对累积的 HTTP 数据包进行一些推断。信号量还可用于向 CPU 线程报告统计信息。
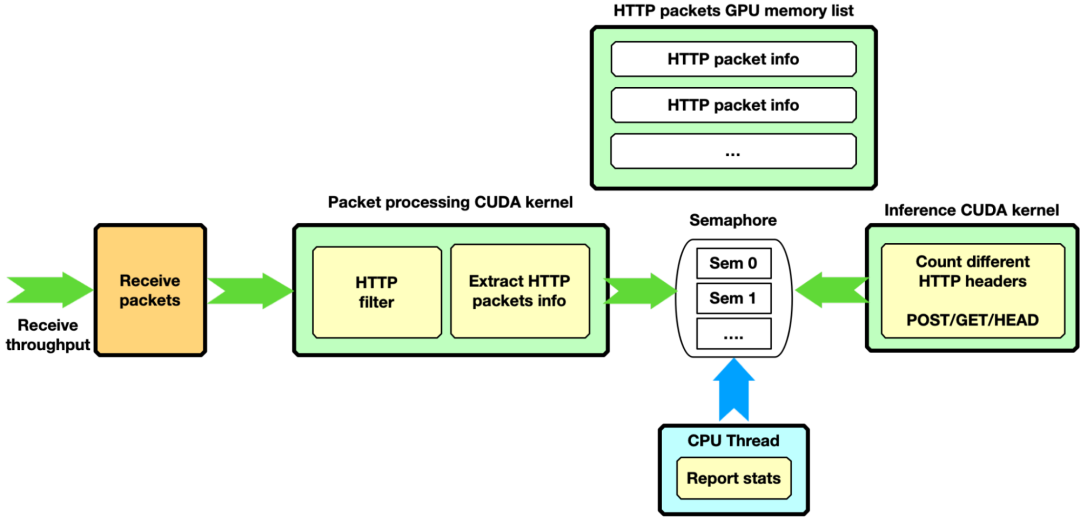
图 11 . NVIDIA DOCA GPUNetIO 应用程序中的第二种管线模式。GPU 只接收、过滤 HTTP 数据包,并通过专用信号量解除阻止 CUDA 内核对这些数据包进行分析
该管线配置提供了复杂流水线的示例,该复杂管线包括多个数据处理和过滤阶段以及诸如 AI 管线之类的推理功能。
流量转发
本节介绍如何通过 GPU 发起的通信使用 DOCA GPUNetIO 启用流量转发。在每个接收到的数据包中,在通过网络发送回数据包之前,交换 MAC 和 IP 源地址和目的地址。
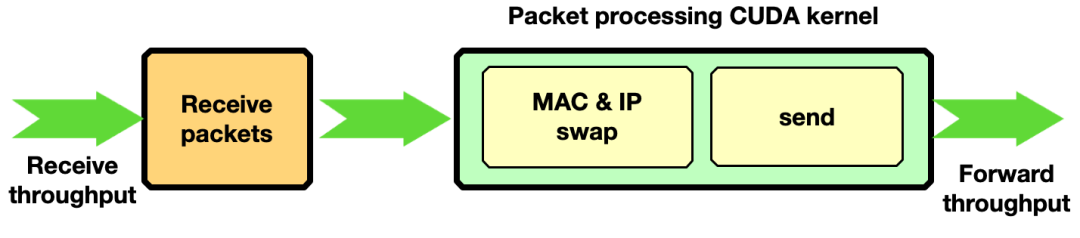
图 12 . NVIDIA DOCA GPUNetIO 应用程序中的第三种管线模式。GPU 接收、交换每个数据包的 MAC 和 IP 地址,并发送回修改后的数据包。
通过使用 T-Rex 数据包生成器以 ~90 Gbps 的速度发送 30 亿个 1KB 大小的数据包,实现了只有一个接收队列和一个发送队列的零数据包丢失。
用于 5G 的 NVIDIA Aerial SDK
决定采用以 GPU 为中心的解决方案的动机可能是性能和低延迟要求,但也可能是为了提高系统容量。CPU 在处理连接到接收器应用程序的越来越多的对等端时可能成为瓶颈。GPU 提供的高度并行化可以提供可扩展的实现,以并行处理大量对等端,而不会影响性能。
NVIDIA Aerial 是一个用于构建高性能、软件定义的 5G L1 堆栈的 SDK,该堆栈通过 GPU 上的并行处理进行了优化。具体而言,NVIDIA Aero SDK 可用于构建基带单元(BBU)软件,该软件负责通过无线电单元(RU)发送(下行链路)或接收(上行链路)无线客户端数据帧,该数据帧被拆分为多个以太网数据包。
在上行链路中,BBU 接收数据包,验证数据包,并在触发信号处理之前重建每个 RU 的原始数据帧。使用 NVIDIA Aerial SDK ,这在 GPU 中发生:CUDA 内核专用于每个时隙的每个 RU ,以重建帧并触发 GPU 信号处理的 CUDA 内核序列。
通过 DPDK gpudev 库实现了网卡接收数据包以及 GPU 重新排序和处理数据包的编排(图 13)。
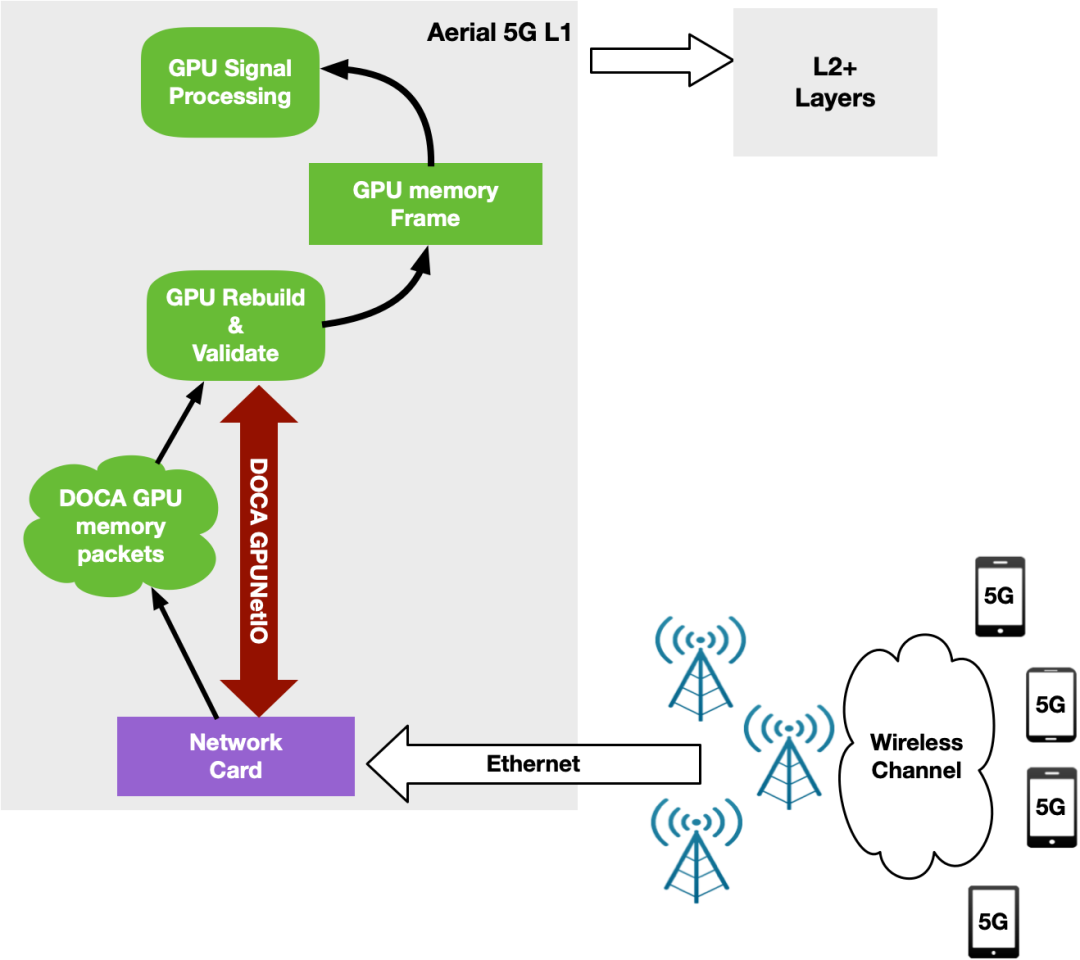
图 13 .NVIDIA Aerial 5G L1 以 CPU 为中心的架构,带有 DPDK gpudev 库
第一个实现在现代 Intel x86 系统上仅使用一个 CPU 内核,就能够以 25 Gbps 的速度保持 4 个 RU 的工作速度。然而,随着基站数量的增加,网卡和 GPU 之间的 CPU 功能成为瓶颈。
CPU 按顺序工作。随着单个 CPU 核心接收和管理越来越多的 RU 流量,同一 RU 的两次接收之间的时间取决于 RU 的数量。对于 2 个 CPU 核,每个核在 RU 的子集上工作,相同 RU 的两次接收之间的时间减半。然而,这种方法对于越来越多的客户端是不可扩展的。此外,PCIe 事务的数量从 NIC 增加到 CPU ,然后从 CPU 增加到 GPU (图 14)。
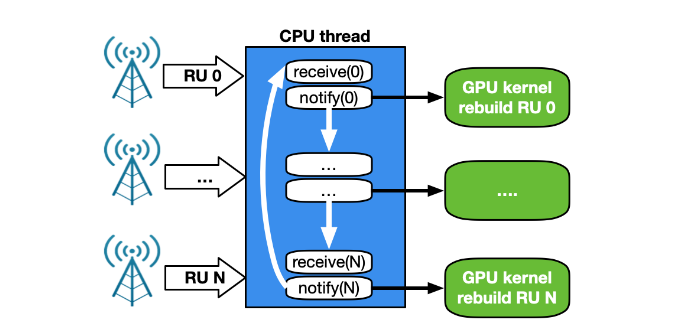
图 14 . NVIDIA Aerial 5G 应用程序以 CPU 为中心的控制流程,连接了多个 RU 。CPU 内核顺序地接收并通知每个连接的 RU 的 GPU 重建内核。这不是一种可扩展的方法。
为了克服所有这些问题,NVIDIA Aerial SDK 的以 GPU 为中心的新版本已通过 DOCA GPUNetIO 库实现。每个 CUDA 内核负责在每个时隙重建来自特定 RU 的数据包,并通过接收能力进行了改进(图 15)。
图 15 . 以 GPU 为中心的 NVIDIA Aerial SDK 5G 架构,采用 NVIDIA DOCA GPUNetIO
此时,关键路径中不需要 CPU ,因为每个 CUDA 内核都是完全独立的,能够并行和实时处理越来越多的 RU 。这增加了系统容量,并减少了每个时隙处理数据包的延迟和 PCIe 事务的数量。CPU 不必与 GPU 通信以提供数据包信息。
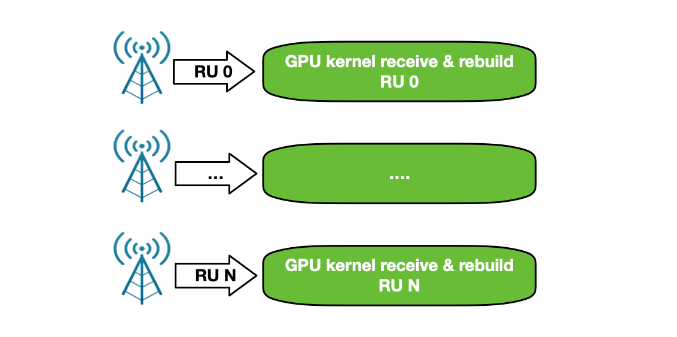
图 16 . NVIDIA Aerial 5G SDK 以 GPU 为中心的控制流程,连接了多个 RU 。这是一种可扩展的方法,它保证了对所有连接的平等和公平服务。
根据标准,5G 网络必须根据特定模式交换数据包。每个时隙(例如 500 微秒),数据包应该以 14 个所谓的符号发送。每个符号由若干个数据包组成(取决于使用情况),这些数据包将在较小的时间窗口(例如,36 微秒)内发送。为了在下行链路侧支持这种定时传输模式,NVIDIA Aerial SDK 通过 DOCA GPUNetIO API 将 GPU 发起的通信与精确发送调度相结合。
一旦 GPU 信号处理准备好要在未来时隙中发送的数据,每个 RU 的专用 CUDA 内核将该数据分割成每个 RU 的以太网数据包,并在未来的特定时间调度它们的未来传输。然后,同一 CUDA 内核将数据包推送到 NIC ,NIC 将负责在正确的时间发送每个数据包(图 17)。
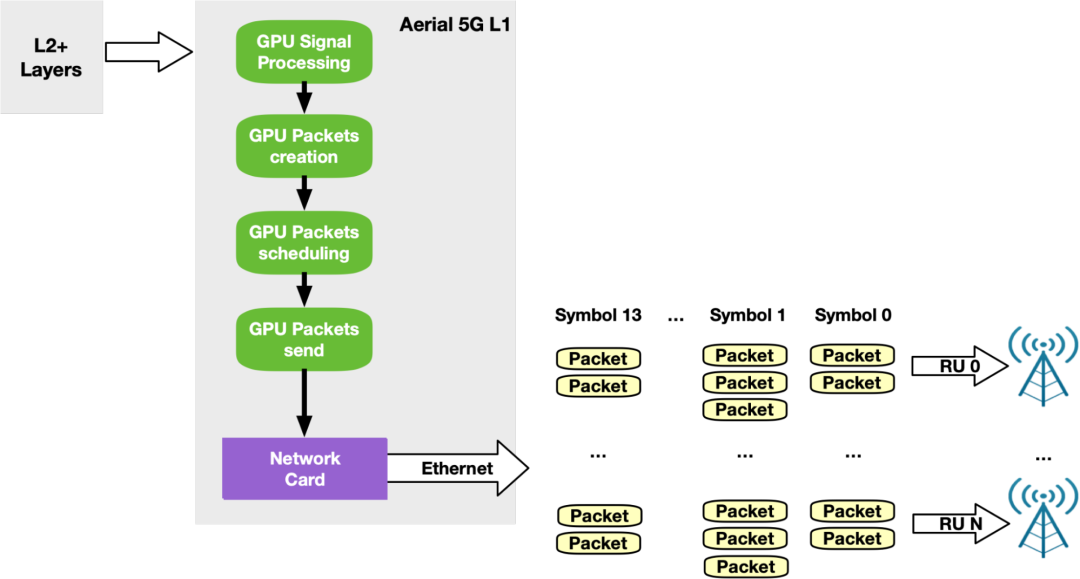
图 17 . NVIDIA Aerial 5G SDK 定时传输模式使用 GPU 发起的通信和精确发送调度功能,通过 NVIDIA DOCA GPUNetIO 实现
尽早访问 NVIDIA DOCA GPUNetIO
作为研究项目的一部分,DOCA GPUNetIO 包处于实验状态。它可以早期访问,是最新 DOCA 版本的扩展。它可以安装在主机系统或 DPU 融合卡上,包括:
-
应用程序初始设置阶段的一组 CPU 函数,用于准备环境并创建队列和其他对象
-
您可以在 CUDA 内核中调用一组特定于 GPU 的函数,以发送或接收数据包,并与 DOCA GPUNetIO 信号量交互
-
您可以构建和运行应用程序源代码来测试功能,并了解如何使用 DOCA GPUNetIO API
硬件要求是 ConnectX-6 Dx 或更新的网卡和 GPU Volta 或更新的。强烈建议在两者之间使用专用 PCIe 网桥。软件要求为 Ubuntu 20.04 或更新版本、CUDA 11.7 或更新版本以及 MOFED 5.8 或更新版本。
如果您有兴趣了解更多信息并获得 NVIDIA DOCA GPUNetIO 的实践经验,以帮助您开发下一个关键应用程序,请联系 NVIDIA 技术支持获取早期访问权限。请注意,DOCA GPUNetIO 库目前仅在 NVIDIA 的 NDA 下可用。

查看以下精彩内容,了解更多关于 NVIDIA BlueField DPU 和 DOCA 的信息
NVIDIA BlueField DPU 和 DOCA 连获三奖,大放光彩
NVIDIA DOCA 推出基于主机的网络(HBN)1.2.0 版本
NVIDIA DOCA 1.5 长期支持版本发布
免费学 DOCA 软件开发入门课程 释放 DPU 潜力
原文标题:使用 NVIDIA DOCA GPUNetIO 进行内联 GPU 数据包处理
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
23文章
4115浏览量
99613
原文标题:使用 NVIDIA DOCA GPUNetIO 进行内联 GPU 数据包处理
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Oracle和NVIDIA合作加速向量搜索和企业数据处理
CW32R030可以兼容BLE及XN297L数据包,请问这个XN297L数据包是什么?
如何使用wireshark进行远程抓包
NVIDIA RTX PRO 5000 Blackwell GPU的深度评测

在Python中借助NVIDIA CUDA Tile简化GPU编程

NVIDIA推出全新BlueField-4 DPU
简单的内联汇编介绍
串口DMA接收数据包丢失怎么解决?
利用NVIDIA DOCA GPUNetIO技术提升MoE模型推理性能
NVIDIA RTX PRO 4500 Blackwell GPU测试分析

NVIDIA桌面GPU系列扩展新产品
NVIDIA DOCA 3.0版本的亮点解析



评论