 什么是机器学习?ML 基础知识简介
什么是机器学习?ML 基础知识简介

本文旨在为硬件和嵌入式工程师提供机器学习 (ML)、它是什么、它是如何工作的、为什么它很重要以及 TinyML 如何适应。
机器学习是一个一直存在且经常被误解的技术概念。几十年来,这种实践是一门使用复杂处理和数学技术使计算机能够找到大量输入和输出数据之间相关性的科学,这在我们的集体技术意识中已经存在了几十年。近年来,科学已经爆炸式增长,这得益于以下方面的改进:
计算能力
图形处理单元 (GPU) 架构支持的并行处理
适用于大规模工作负载的云计算
事实上,该领域一直专注于桌面和基于云的使用,以至于许多嵌入式工程师并没有过多考虑ML如何影响他们。在大多数情况下,它没有。
然而,随着提尼毫升或微型机器学习(在微控制器和单板计算机等受限设备上的机器学习),ML已与所有类型的工程师相关,包括那些从事嵌入式应用程序的工程师。除此之外,即使您熟悉TinyML,对机器学习有一个具体的了解也很重要。
在本文中,我将概述机器学习、其工作原理以及为什么它对嵌入式工程师很重要。
什么是机器学习?
作为人工智能 (AI)领域的一个子集,机器学习是一门专注于使用数学技术和大规模数据处理来构建可以找到输入和输出数据之间关系的程序的学科。作为一个总称,人工智能涵盖了计算机科学的一个广泛领域,专注于使机器能够在没有人为干预的情况下“思考”和行动。它涵盖了从“通用智能”或机器以与人类相同的方式思考和行动的能力,到专门的、面向任务的智能,这是ML所属的地方。
我过去听到的最强大的ML定义方式之一是与经典计算机编程中使用的传统算法方法进行比较。在经典计算中,工程师向计算机提供输入数据(例如,数字 2 和4)以及将它们转换为所需输出的算法(例如,将 x 和 y 相乘得到 z)。当程序运行时,提供输入,并应用算法来生成输出。如图 1 所示。

图1. 在经典方法中,我们为计算机提供输入数据和算法,并要求答案。
另一方面,ML是向计算机提供一组输入和输出并要求计算机识别“算法”(或模型,使用ML术语)的过程,每次都将这些输入转换为输出。通常,这需要大量输入,以确保模型每次都能正确识别正确的输出。
例如,在图 2 中,如果我向 ML 系统提供数字 2 和 2,以及预期的输出 4,它可能会决定算法始终将这两个数字相加。但是,如果我随后提供数字 2和 4 以及预期的输出 8,则模型将从两个示例中了解到,正确的方法是将提供的两个数字相乘。
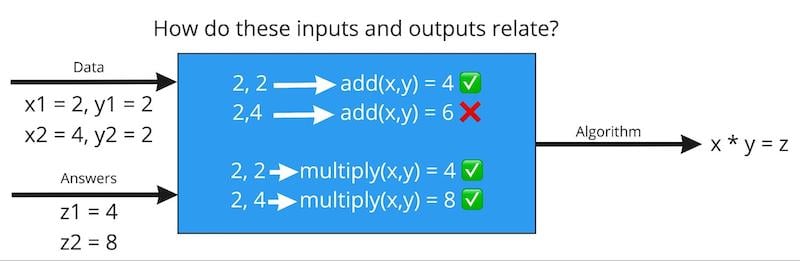
图2. 使用ML,我们拥有数据(输入)和答案(输出),并且需要计算机通过确定输入和输出如何以适用于整个数据集的方式关联来得出各种算法。
鉴于我使用一个简单的例子来定义一个复杂的字段,你可能会问:为什么人们会费心使简单的复杂化?为什么不坚持我们的经典算法计算方法呢?
答案是,倾向于机器学习的问题类别通常不能通过纯粹的算法方法来表达。没有简单的算法可以给计算机一张图片,并要求它确定它是否包含猫或人脸。相反,我们利用ML并给它数千张图片(作为像素集合),其中有猫,也有人脸,两者都没有,并且通过学习如何将这些像素和像素组与预期输出相关联来开发模型。当机器看到新数据时,它会根据之前看到的所有示例推断输出。这个过程的这一部分,通常称为预测或推理,是ML的魔力。
这听起来很复杂,因为它确实如此。在嵌入式和物联网 (IoT) 系统领域,ML越来越多地被用于帮助机器视觉、异常检测和预测性维护等领域。在这些领域中,我们收集大量数据(图像和视频、加速度计读数、声音、热量和温度),用于监控设施、环境或机器。然而,我们经常难以将数据转化为我们可以采取行动的洞察力。条形图很好,但是当我们真正想要的是能够在机器中断和离线之前预测机器需要服务时,简单的算法方法就行不通了。
机器学习开发循环
进入机器学习。在有能力的数据科学家和ML工程师的指导下,这个过程从数据开始。也就是说,我们的嵌入式系统创建的大量数据。ML开发过程的第一步是在将数据输入模型之前收集数据并对其进行标记。标记是一个关键的分类步骤,也是我们将一组输入与预期输出相关联的方式。
ML 中的标记和数据收集
例如,一组加速度计 x、y 和 z 值可能对应于计算机处于空闲状态,另一组可能表示计算机运行良好,第三组可能对应于问题。图 3中可以看到高级描述。
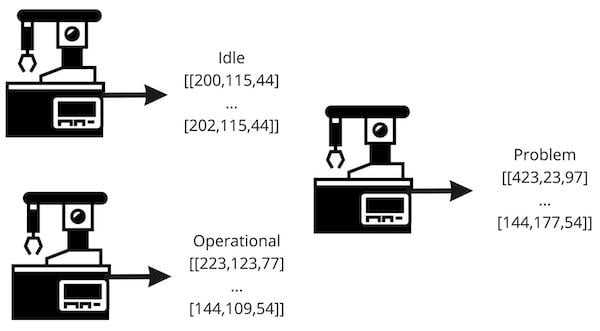
图3. ML 工程师在数据收集过程中使用标签对数据集进行分类。
数据收集和标记是一个耗时的过程,但对于正确处理至关重要。虽然 ML领域有一些创新,利用预先训练的模型来抵消一些工作和新兴工具来简化来自真实系统的数据收集,但这是一个不容错过的步骤。世界上没有ML模型可以可靠地告诉您您的机器或设备是否运行良好或即将崩溃,而无需看到该机器或其他类似机器的实际数据。
机器学习模型开发、训练、测试、优化
数据收集后,接下来的步骤是模型开发、训练、测试和优化。在此阶段,数据科学家或工程师创建一个程序,该程序引入收集的大量输入数据,并使用一种或多种方法将其转换为预期的输出。解释这些方法可以填满体积,但足以说明大多数模型对其输入执行一组转换(例如,向量和矩阵乘法)。此外,它们将相互调整每个输入的权重,以找到一组与预期输出可靠相关的权重和函数。
该过程的这一阶段通常是迭代的。工程师将调整模型、使用的工具和方法,以及在模型训练期间运行的迭代次数和其他参数,以构建能够可靠地将输入数据与正确的输出(也称为标签)相关联的东西。一旦工程师对这种相关性感到满意,他们就会使用训练中未使用的输入来测试模型,以查看模型在未知数据上的表现。如果模型在此新数据上表现不佳,工程师将重复该循环(如图4 所示),并进一步优化模型。

图4. 模型开发是一个包含许多步骤的迭代过程,但它始于数据收集。
模型准备就绪后,将部署该模型并可用于针对新数据的实时预测。在传统 ML中,模型部署到云服务,以便正在运行的应用程序可以调用它,该应用程序提供所需的输入并从模型接收输出。应用程序可能会提供一张图片并询问是否有人在场,或者一组加速度计读数,并询问模型这组读数是否与空闲、正在运行或损坏的计算机相对应。
正是在这个过程的这一部分,TinyML是如此重要和具有开创性。
那么TinyML适合在哪里呢?
如果还不清楚,机器学习是一个数据密集型过程。当您尝试通过关联派生模型时,您需要大量数据来提供该模型。数百张图像或数千个传感器读数。事实上,模型训练的过程是如此密集,如此专业化,以至于几乎对任何人来说都是资源消耗者。
中央处理器 (CPU),无论多么强大。相反,ML 中常见的矢量和矩阵数学运算与图形处理应用程序没有什么不同,这就是为什么 GPU
已成为模型开发如此受欢迎的选择。
鉴于对强大计算的需求,云已成为减轻训练模型工作并托管它们以进行实时预测的事实上的地方。虽然模型训练现在是,并且仍然是云的领域,特别是对于嵌入式和物联网应用程序,但我们越接近将实时预测的能力转移到捕获数据的地方,我们的系统就会越好。在微控制器上运行模型时,我们受益于内置安全性和低延迟,以及在本地环境中做出决策和采取行动的能力,而无需依赖互联网连接。
这是TinyML的领域,平台公司喜欢 边缘脉冲 正在构建基于云的传感器数据收集和 ML 架构工具,以输出专为 微控制器单元
(MCU)。其中越来越多的硅供应商,从 意法半导体 自 阿里夫半导体 正在构建具有类似 GPU 的计算功能的芯片,使其非常适合在收集数据的位置与传感器一起运行
ML 工作负载。
对于嵌入式和物联网工程师来说,现在是探索机器学习世界的最佳时机,从云到最小的设备。我们的系统只会比以往任何时候都更加复杂,处理的数据也越来越多。将ML带到边缘意味着我们可以处理这些数据并更快地做出决策。
-
人工智能
+关注
关注
1821文章
50471浏览量
267612 -
数据收集
+关注
关注
0文章
73浏览量
11778 -
模型
+关注
关注
1文章
3861浏览量
52322 -
ML
+关注
关注
0文章
154浏览量
35553 -
机器学习
+关注
关注
67文章
8570浏览量
137381
发布评论请先 登录
DAQ基础知识简介
PCB基础知识简介
PLC基础知识简介


什么是单片机怎样学习?单片机基础知识及Proteus应用简介资料概述
液压基础知识的学习课件免费下载





评论