 DPU发展的关键技术是什么
DPU发展的关键技术是什么
2023年1月7日,中国信息通信研究院联合开放数据中心委员会发布了《DPU发展分析报告(2022年)》。
DPU 将成为下一代芯片技术竞争的高地。作为数据中心继 CPU 和GPU之后的"第三颗主力芯片",DPU的演进也经历了从众核CPUNP、FPGA+CPU到ASIC+CPU的多个发展阶段或者技术演进。
基于CPU/NP、FPGA+CPU的硬件架构分别具备软件可编程和硬件可编程的灵活优势,在DPU发展的初期尤其受到互联网云厂商大厂自研方案的青睐,在快速迭代和灵活定制方面有比较明显的收益。
然而,随着网络带宽的快速增长,网络接入带宽迅速从10G、25G演进到了100G、200G之后,基于CPU/NP和FPGA+CPU这类硬件架构的DPU除了在性能上难以为继以外,在成本和功耗上则有更大的挑战。基于ASIC+CPU的硬件架构则是结合了ASIC和CPU二者的优势,即将通用处理器的可编程灵活性与专用的加速引擎相结合,正在成为最新的产品趋势。
业界的头部厂商NVIDIA、Intel和AMD(收购Pensando)的DPU架构都采用了这种架构路线。
从DPU 芯片的实现角度看,以 ASIC+CPU 的硬件架构为例,CPU的研发更多的是以系统级芯片的方式集成第三方成熟的CPU多核IP,不同DPU厂商的核心竞争壁垒在于专用加速引擎的硬件实现上。由于DPU是数据中心中所有服务器的流量入口,并以处理报文的方式处理数据,在网络芯片领域积累更多的厂商将更有优势。
(一)RDMA高速网络技术1、RDMA的技术背景
传统TCP/IP协议栈在处理报文转发的过程当中,从用户态到内核协议栈再经过网卡转发出去这个过程中,要触发多次CPU的上下文切换,发生多次的内存拷贝,由于多次数据拷贝,转发延时一直较高,随着网络带宽的提升,传统内核处理报文的方式已经无法满足更高带宽,更低延时的业务需求。
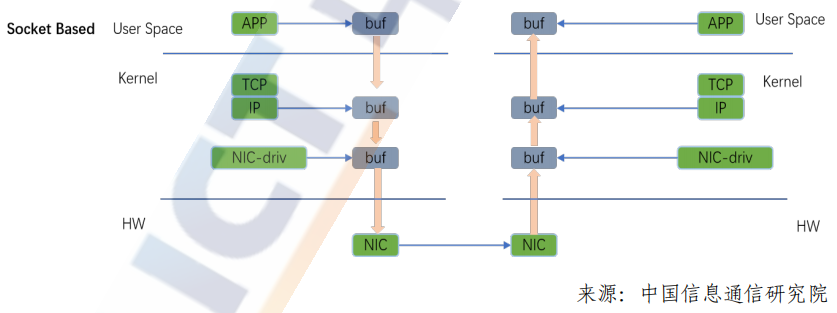
RDMA 是一种远程直接内存访问技术,它将数据直接从一台计算机的内存传输到另一台计算机的内存,数据从一端主机的内存通过DMA方式从网卡转发出去,到另一端通过网卡DMA直接写入另一端主机的内存,整个数据传输过程无须操作系统以及CPU参与,这种CPU/内核协议栈的bypass技术通过硬件网卡实现,可以满足未来网络对高带宽、低延时的需求,并进一步释放CPU的计算资源。 RDMA技术具有以下特点:
CPU卸载:用户态应用程序通过调用IB verbs接口直接访问远程主机的内存,可以对远程内存执行读取、写入、原子操作等多种操作,而且无须两端主机CPU参与。
内核旁路:RDMA采用基于verbs的编程方式,不同于socket编程方式,需要用户态与内核态的切换,应用程序可以直接在用户态调用RDMA的verbs接口,消除上下文切换带来的额外开销,并实现了额内核系统旁路。
零拷贝:本端应用程序内存数据通过网卡DMA直接发送到远端网卡,远端网卡通过DMA方式直接写入对端内存,整个过程中消除了传统TCP/IP传输方式的多次内存拷贝的过程,实现内存零拷贝,进一步降低整个网络延时。
为了达到RDMA在高性能和低延时上的技术优势,RDMA有高的技术门槛,需要端到端的拥塞控制来避免拥塞和降低网络延时。实现端到端的高性能RDMA网络需要考虑:
1)网络收敛比。进行数据中心网络架构设计时,从成本和收益两方面来考虑,多数会采取非对称带宽设计,即上下行链路带宽不一致,交换机的收敛比简单说就是总的输入带宽除以总的输出带宽;
2)ECMP等价哈希均衡。当前数据中心网络多采用Fabric架构,并采用ECMP来构建多条等价负载均衡的链路,通过设置扰动因子,采用 HASH 选择一条链路来转发是简单的,但这个过程中却没有考虑到所选链路本身是否有拥塞。ECMP并没有拥塞感知的机制,只是将流分散到不同的链路上转发,对于已经产生拥塞的链路来说,很可能加剧链路的拥塞;
3)Incast流量模型,Incast是多打一的通信模式,在数据中心云化的大趋势下这种通信模式常常发生,尤其是那些以Scale-Out方式实现的分布式存储和计算应用,包括EBS云存储、AI集群、高性能数据库、Hadoop、MapReduce、HDFS等;
4)无损网络交换机的流量控制、QoS和拥塞控制机制以及相应的水线设置,能够让RDMA得到规模部署且广泛应用的就需要RDMA的拥塞控制算法支撑。在Fabric网络复杂、多路径的场景下,伴随着多打一、突发等情况的出现,是拥塞控制算法让RDMA的高性能得以充分展现,为RDMA的高性能保驾护航。
端到端拥塞控制算法的基本原理是依托拥塞节点交换机对出向 报文的 ECN标记,目的端通过ECN标记处理反馈 CNP使得源端进行速率调节,从而达到解决拥塞的目的。
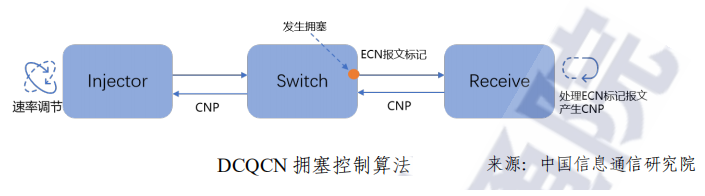
随着RDMA技术的普及,不同的云厂商用户结合不同的业务场景和网络环境提出了多种拥塞控制算法,比较有代表的算法有被业界 大规模验证过的DCOCN算法,阿里提出的HPCC算法,以及谷歌提 出的TIMELY和Swift算法等。不同的用户或者业务场景有不同拥塞控制算法的需求。因此,DPU芯片需要支持多种拥塞控制算法,或者能够一步到位支持拥塞控制算法的可编程能力。
2、RDMA的应用价值
RDMA对比传统TCP传输方式在提升吞吐,降低CPU占用、降低延时方面均有明显的优势。后摩尔时期尤其是在网络进入100G甚至200G以上的带宽情况下,传统TCP协议栈内核转发完全无法满足性能要求,随着网络技术的演进,高吞吐、低延时的RDMA技术将承担基础的网络传输功能,进一步提升数据中心整体算力。
RDMA 凭借其高吞吐、低延时、CPU旁路、适应性广、技术成熟等特点,已经成为数据中心基础服务的一个重要组成部分,承载着多种不同的业务类型,并且随着网络技术以及应用的发展,RDMA的应用将进一步扩大。
(二)数据面转发技术
随着网络流量的指数增长,基于硬件数据面转发技术越来越受到关注,在传统交换机和路由器上已经成熟应用的数据面转发技术也被应用到了DPU领域。在数据面硬件转发技术中,基本的硬件处理架构有两种:基于NP的run-to-completion(RTC)架构和pipeline架构。
1、基于NP的RTC转发架构
通用RTC(Real-Time Clock)处理器转发模型,报文进入后,经过调度分发器后,被分配到一个报文处理引擎上处理。RTC是一种非抢占机制,当报文进入该处理引擎后,根据转发需求进行处理,直到处理结束退出。
在RTC架构中,每个处理器上都是标准的冯诺依曼架构,包括:程序计数器(PC)、指令存储器、译码器、寄存器堆、逻辑运算单元(ALU),其中指令存储器多个核之间共享。通常报文处理流程通过C语言或微码编程后,会被编译成一系列的指令执行。由于转发需求和报文长度不同,每个报文在处理器内部的处理时间差异很大。
2、Pipeline转发架构
Pipeline架构中,整个处理流程被拆分成多个不同的处理阶段,对应到不同的步骤,每一级转发处理可以做成专用的硬件处理单元。当第一个报文执行完第一个步骤,进入第二个步骤时,第二个报文可以进入流水线中的第一个步骤进行处理。
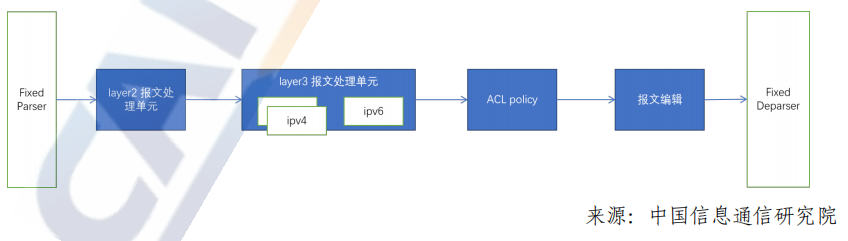
根据业务需求,将转发流程拆分成多个处理步骤,每个步骤中只执行特定的逻辑处理,主要应用在数据中心交换机上,比如:Broadcom TD系列。
Match-Action Pipeline架构也是一种业界常用的pipeline架构为,与固化Pipeline架构相比,每个步骤中可根据业务生成灵活的查表信息,根据查表结果,对报文进行相应的逻辑处理,如下图所示。
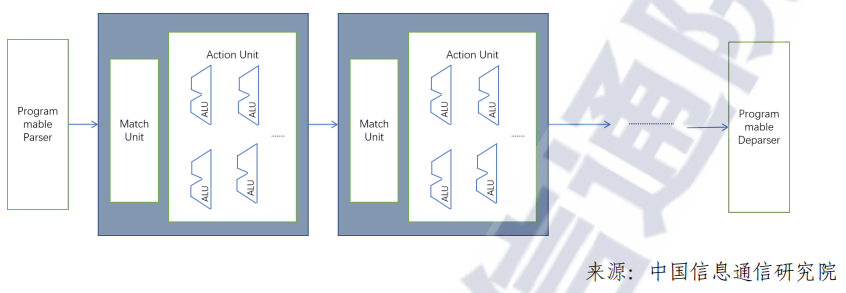
在性能上,固化Pipeline架构近乎定制化ASIC,相比于可编程Pipeline架构,吞吐更高,时延更低,逻辑处理单元复杂度更低 与可编程Pipeline相比,固化Pipeline,不支持可编程和新的业务添加。而可编程MA架构可以保留一部分灵活可拓展性,在资源允许的情况下,支持新业务拓展。
3、Pipeline vs RTC
Pipeline 和 RTC 作为两个主流转发架构,RTC架构在转发业务中表项出丰富的灵活性,但随着网络流量的不断增加,Pipeline架构表现出相对优势:
在性能方面,1)在相同处理性能下,RTC架构中通常采用多核多线程,来提高转发性能,由于多线程面积占比较高(每个线程独立维护相应的寄存器信息),报文进入处理器的调度和多核报文调度转发逻辑资源面积较大,导致芯片面积和功耗通常为Pipeline架构的数倍。2)由于多核处理器访问内存,导致带宽压力较大。为提高转发性能,内存会被复制多份,降低内存访问冲突,导致内存占用率很高。
时延方面,在Pipeline架构下,不同步骤中的memory资源静态分配,报文在转发过程中执行的指令信息提前预知。和 RTC 架构相比,能够大大降低由于读写/查表冲突带来的时延,通常 pipeline架构对报文的处理时延是 RTC 架构的数十分之一。
从功耗、性能、面积的角度考虑,DPU跟随网络流量需求变化(业务需求不断丰富、网络时延敏感、功耗要求更低),基于可编程Pipeline的硬件架构更符合DPU加速硬件报文转发的发展方向。
(三)网络可编程技术
在以算力为中心的时代,网络边缘设备已经从柜顶交换机延展到DPU,DPU已经成为数据中心内部网络连接计算、存储的新的接入节 点,面对不断变化的网络业务需求和自定义网络扩展能力的需要,支持网络可编程技术成为DPU应用于新一代数字基础设施的关键技术因素。
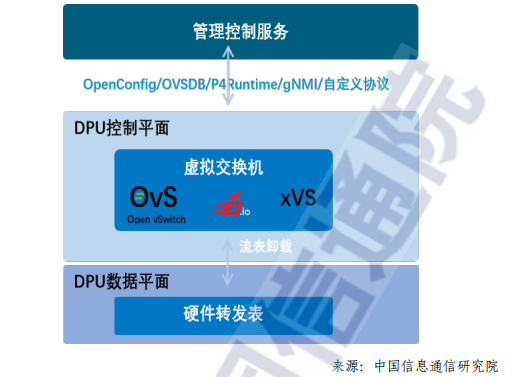
DPU上网络可编程技术主要包括控制平面网络可编程技术和数据平面网络可编程技术,其中控制平面网络可编程技术主要应用于DPU 内部的通用系统级芯片上,而数据平面网络可编程技术则主要应用在硬件加速器部分。
目前DPU数据平面网络可编程技术主要包括基于快速流表和基于P4流水线两种常见技术。
(四)开放网络及DPU软件生态
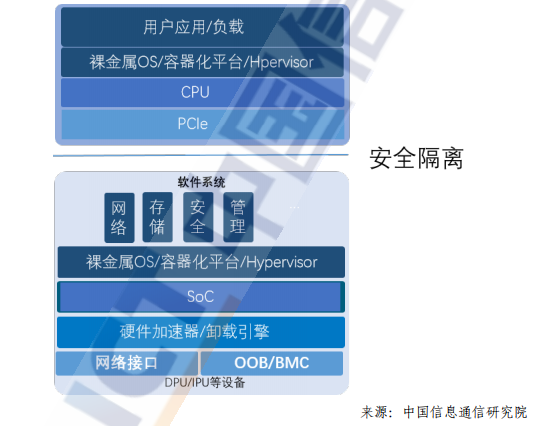
由于DPU芯片的发展还处于早期阶段,DPU的软件生态也处于萌芽状态。目前,市场上主流的开放网络及 DPU 软件生态主要有Linux 基金会宣布的开放可编程基础设施——OPI项目、由 Intel 驱动主导的 IPDK 框架、Nvidia DPU的开源软件开发框架 DOCA、开放数据中心委员会开展的无损网络项目等。
DPU 作为数据中心基础设施的一颗重要芯片,拥有一个社区驱动的、基于标准的开放生态系统,以开放的形式定义DPU标准可编程基础设施生态,对DPU的长期发展至关重要。
一个富有生命力的DPU的软件生态需要具备条件为提供一个基于开放社区的DPU软件堆栈以及用户驱动,且与供应商无关的软件框架和架构。支持既有的DPU开源应用程序生态系统,包括DPDK,OVS,SPDK 等已经在用户侧有广泛应用的开源应用软件。
基于以上标准我们对现有的DPU软件生态做比较,SONiC是由用户驱动的开放网络平台项目。SONiC是由微软于2016年发起,其所有软件功能模块都来自开源生态。如下图所示,SONiC通过将SAI 接口作为统一的硬件管理接口,由各厂商在SAI接口之下实现对应硬件驱动,通过这样的方式屏蔽不同厂商硬件之间的驱动差异,使 SONiC软件可以运行在各种硬件设备中,形成白盒交换机统一的软件生态。
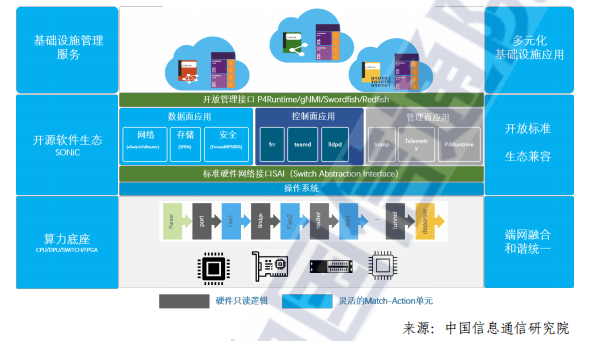
在P4 可编程和DPU的支持方面,SONiC先是通过PINS(P4 Integrated Network Stack)在 SDN 市场白盒交换机中落地了最佳实践,得到了产业界的广泛支持;之后又推出了 SONiC DASH (Disaggregated API for SONiC Hosts)版本,将SONiC在 SDN 交换机市场的最佳实践引入到主机侧,实现了主机端与网络白盒交换机统一的开放网络生态,为DPU顺利加入数字基础设施的SDN网络域打下了基础。
审核编辑:陈陈
-
芯片技术
+关注
关注
1文章
162浏览量
17684 -
DPU
+关注
关注
0文章
374浏览量
24342 -
RDMA
+关注
关注
0文章
78浏览量
9029
原文标题:引领DPU发展的关键技术
文章出处:【微信号:架构师技术联盟,微信公众号:架构师技术联盟】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论