 Jina AI到底是做什么的?为什么要做这些
Jina AI到底是做什么的?为什么要做这些
我们正处于人工智能新时代的风口浪尖,正从单模态大步迈向多模态 AI 时代。在 Jina AI,我们的 MLOps 平台帮助企业和开发者加速整个应用开发的过程,在这一范式变革中抢占先机,构建起着眼于未来的应用程序。
如果别人问到我们 Jina AI 是做什么的,我会有以下两种回答。1. 面对 AI 研究员时,我会说:Jina AI 是一个跨模态和多模态数据的 MLOps 平台;2. 面向从业者和合作伙伴时,我会说:Jina AI 是用于神经搜索和生成式 AI 应用的 MLOps 平台。
但无论用哪种方式来介绍 Jina AI,大多数人对于这几个词语都是比较陌生的。
跨模态、多模态
神经搜索、生成式 AI
你可能听说过”非结构化数据“,但什么是“多模态数据”呢?你可能也听说过“语义搜索”,那“神经搜索”是什么新鲜玩意儿呢?可能更加令你困惑的是,Jina AI 为什么要将这四个概念混在一起,开发一个 MLOps 框架来囊括所有这些概念呢?
这篇文章就是为了帮助大家更好地理解 Jina AI 到底是做什么的,以及我们为什么要做这些。首先,“人工智能已从单模态 AI 转向了多模态 AI”,这一点已成为行业共识,如下图所示:
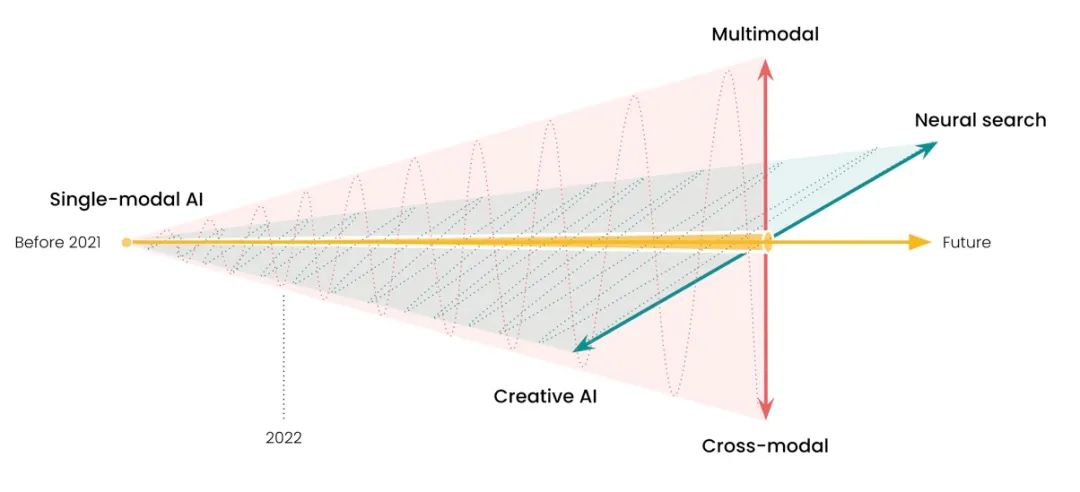
Jina AI 愿景中的未来 AI 应用
在 Jina AI,我们的产品囊括了跨模态、多模态、神经搜索和生成式 AI,涵盖了未来 AI 应用的很大一部分。我们的 MLOps 平台帮助企业和开发者加速整个应用开发的过程,在这一范式转变中抢占先机,构建起着眼于未来的应用程序。
在接下来的文章里,我们将回顾单模态 AI 的发展历程,看看这种范式转变是如何在我们眼下悄然发生的。
单模态人工智能
在计算机科学中,“模态”大致意思是“数据类型”。所谓的单模态 AI,就是将 AI 应用于一种特定类型的数据。这在早期的机器学习领域非常普遍。直至今日,你在看机器学习相关的论文时,单模态 AI 依然占据着半壁江山。
自然语言处理
我们从自然语言处理(NLP)开始回顾。早在 2010 年,我就发表了一篇关于 Latent Dirichlet Allocation(LDA)模型的改进 Gibbs sampling(吉布斯抽样)算法的论文。

Efficient Collapsed Gibbs Sampling For Latent Dirichlet Allocation, 2010
一些资深的机器学习研究人员可能还记得 LDA,这是一种用于建模文本语料库的参数贝叶斯模型。它将单词“聚类”成主题,并将每个文档表示为主题的组合。因此有人称其为“主题模型”
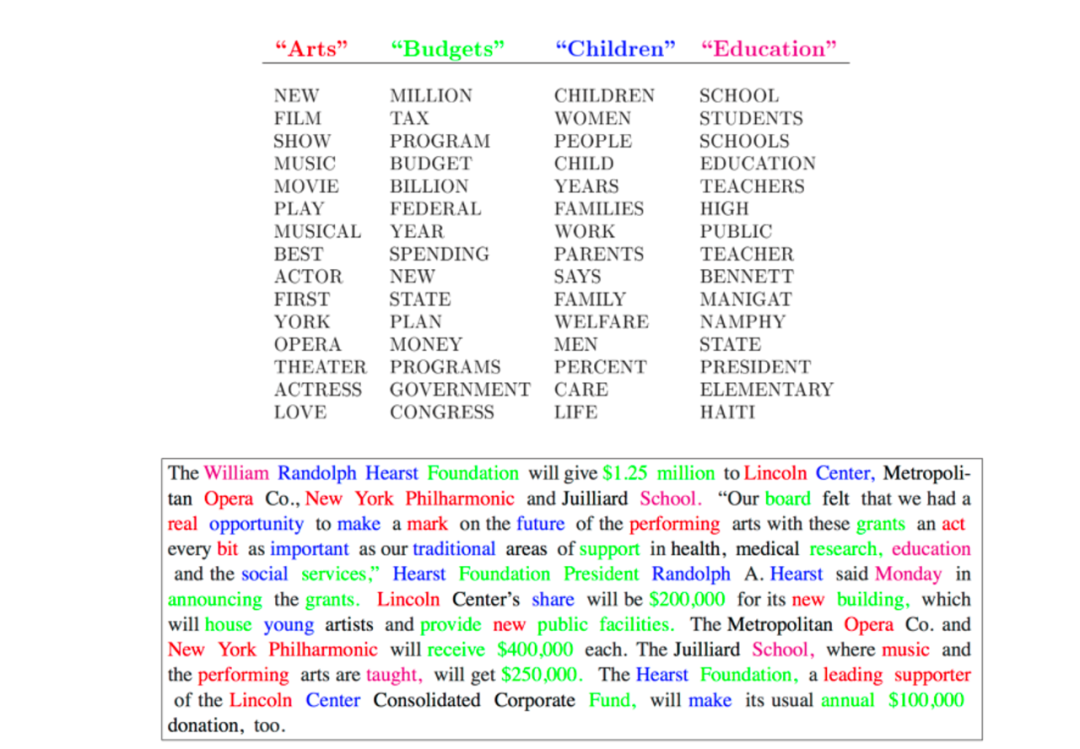
从 2008 年到 2012 年,主题模型一直是 NLP 社区中最有效和最受欢迎的模型之一——它的火热程度相当于当时的 BERT/Transformer。每年在顶级 ML/NLP 会议上,许多论文都会扩展或改进原始模型。但今天回过头来看,它是一个相当 "浅层学习"的模型,采用的是一次性的语言建模方法。它假定单词是由多叉分布的混合物生成的。这对某些特定的任务来说是有意义的,但对其他任务、领域或模式来说却不够通用。
早在 2010-2020 年,像这样的一次性方法是 NLP 研究的常态。研究人员和工程师开发了专门的算法,每种算法虽然都擅长解决一项任务,但是也仅仅只能解决一项任务:
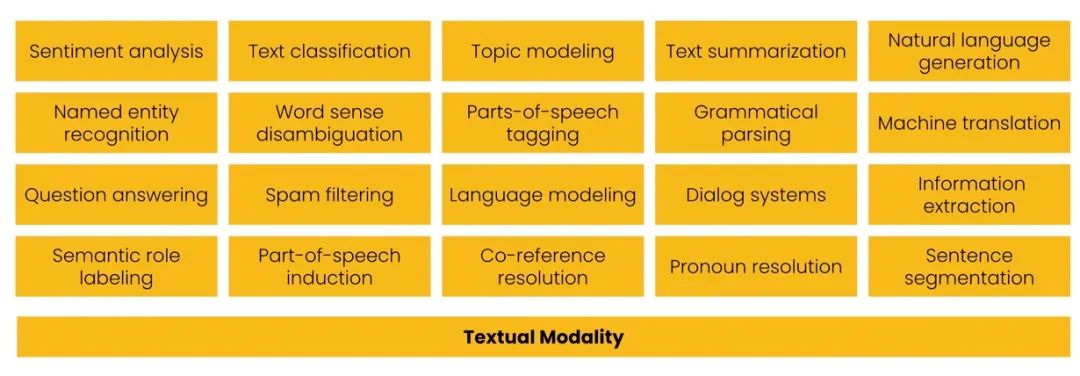
最常见的20种NLP任务
相较于 NLP 领域,我进入计算机视觉 (CV) 领域要晚一些。2017 年在 Zalando 时,我发表了一篇关于 Fashion-MNIST 数据集 的论文。该数据集是 Yann LeCun 1990 年原始 MNIST 数据集(一组简单的手写数字,用于对计算机视觉算法进行基准测试)的直接替代品。原始 MNIST 数据集对于许多算法来说过于简单 —— 逻辑回归、决策树等浅层学习算法树和支持向量机可以轻松达到 90% 的准确率,留给深度学习算法发挥的空间很小。

Fashion-mnist:用于基准机器学习算法的新型图像数据集示例,2017

Fashion-mnist:用于基准机器学习算法的新型图像数据集论文,2017
Fashion-MNIST 提供了一个更具挑战性的数据集,使研究人员能够探索、测试和衡量其算法。时至今日,超过 5,000 篇学术论文在分类、回归、去噪、生成等方面的研究中都还引用了 Fashion-MNIST,可见其价值所在。
但正如主题模型只适用于 NLP,Fashion-MNIST 也只适用于计算机视觉。它的缺陷在于,数据集中几乎没有任何信息可以用来研究其他模式。如果梳理2010-2020年间最常见的20个CV任务,你会发现,几乎所有任务都是单一模式的。同样的,它们每一个都涵盖了一个特定的任务,但也仅仅涉及一项任务:
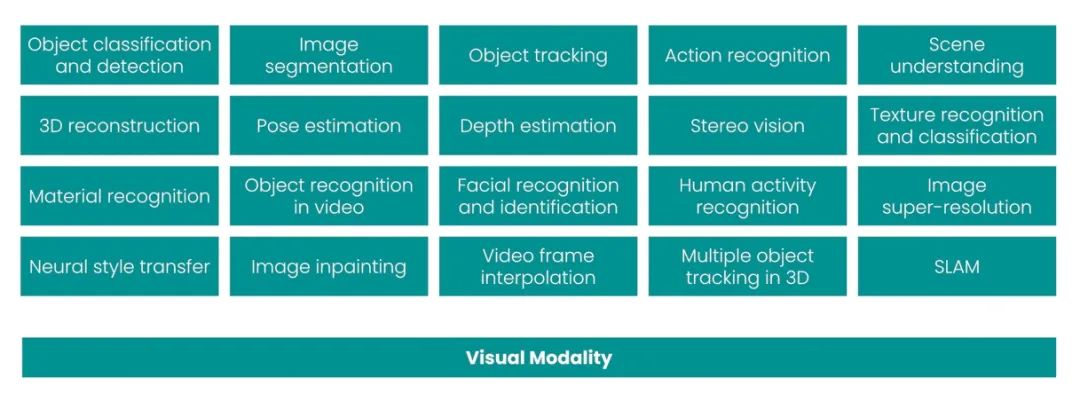
最常见的 20 个 CV 任务
语音和音频
针对语音和音频机器学习遵循相同的模式:算法是为围绕音频模态的临时任务而设计的。他们各自执行一项任务,而且只执行一项任务,但现在都在一起执行:
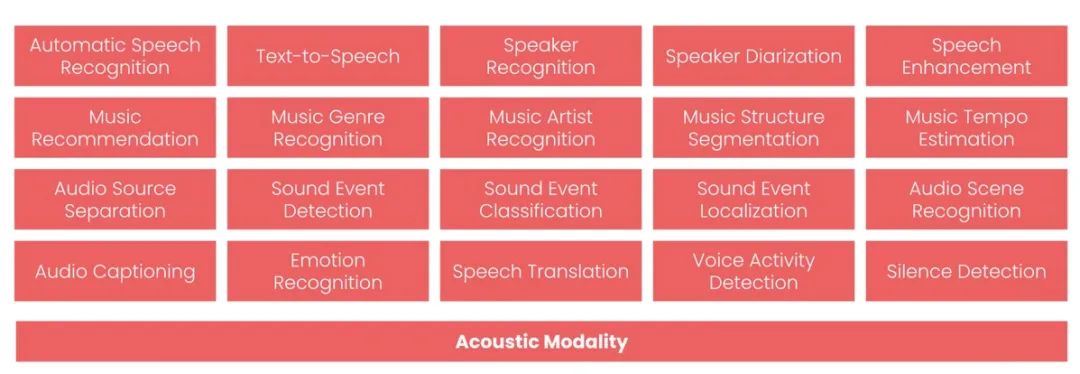
最常见的 20 项音频处理任务
我对多模态 AI 方面最早的尝试之一是我在 2010 年发表的一篇论文,当时我建立了一个贝叶斯模型,对视觉、文本和声音 3 种模态进行联合建模。经过训练后,它就能完成两项跨模式的检索任务:从声音片段中找到最匹配的图像,反之亦然。我给这两个任务起了一个很赛博朋克的名字:“Artificial Synesthesia,人机联觉”。

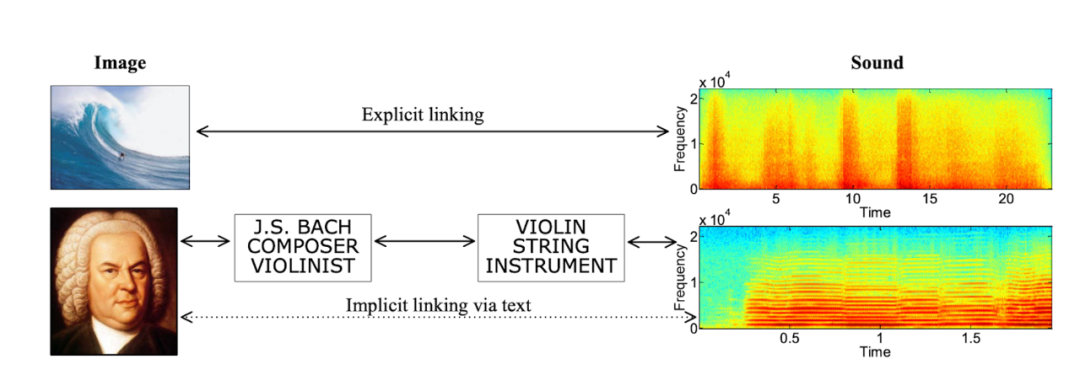
Toward Artificial Synesthesia: Linking Images and Sounds via Words, 2010
迈向多模态人工智能
从上面的例子中,我们可以看到所有的单模态 AI 算法都有两个共同的弊端:
任务只针对一种模态(例如文本、图像、音频等)。
知识只能从一种模态中学习,并应用在这一模式中(即视觉算法只能从图像中学习,并应用于图像)。
在上文中,我已经讨论了文本、图像、音频。还有其他模式,例如 3D、视频、时间序列,也应该被考虑在内。如果我们把来自不同模态的所有任务可视化,我们会得到一个下面立方体,其中各模态正交排列:
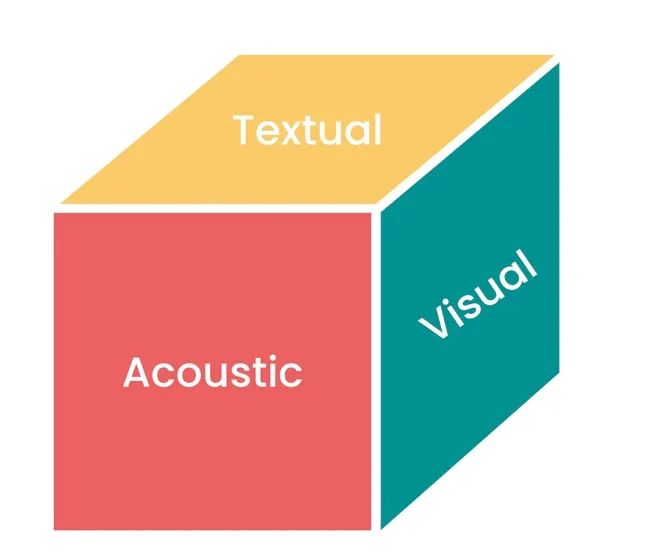
以一个立方体来表示单模态之间的关系,可以假定每个面代表一个单独模态的任务
然而,多模态 AI 就像将这个立方体重新粘合成一个球体,最重要的不同点在于它抹去了不同模态之间的界限,其中:
任务在多种模式之间共享和传输(因此一种算法可以处理图像,文本和音频)
知识是从多种模式中学习并应用于多种模式(因此一个算法可以从文本数据中学习并将其应用于视觉数据。
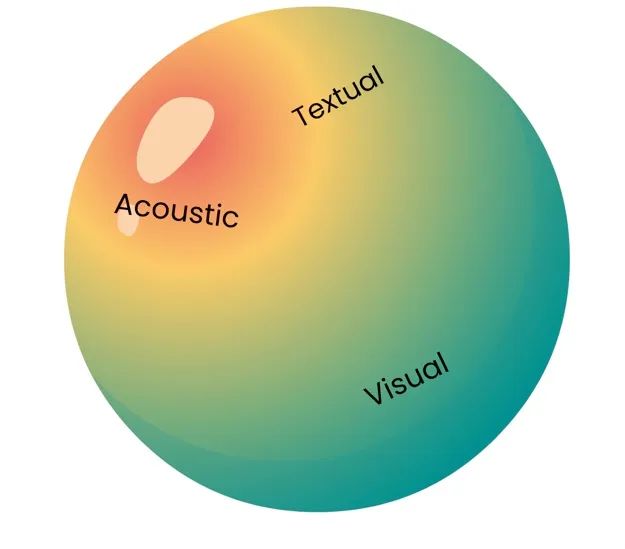
多模态人工智能
多模态 AI 的崛起可归功于两种机器学习技术的进步:表征学习和迁移学习。
表征学习:让模型为所有模态创建通用的表征。
迁移学习:让模型首先学习基础知识,然后在特定领域进行微调。
如果没有表征学习和迁移学习的进步,想在通用数据类型上实行多模态是非常难以落地的,就像我 2010 年的那篇关于声音-图像的论文一样,一切都是纸上谈兵。
2021 年,我们看到了 CLIP,这是一个关联图像和文本之间对应关系的模型;2022 年,我们看到 DALL·E 2 和 Stable Diffusion,根据 prompts 文本生成对应高质量的图像。
由此可见,范式的转变已然开启:未来我们必将看到越来越多的AI应用将超越单个模态,发展为多模态,并巧妙利用不同模态之间的关系。随着模态之间的界限变得模糊,一次性的方法也不再适用了。
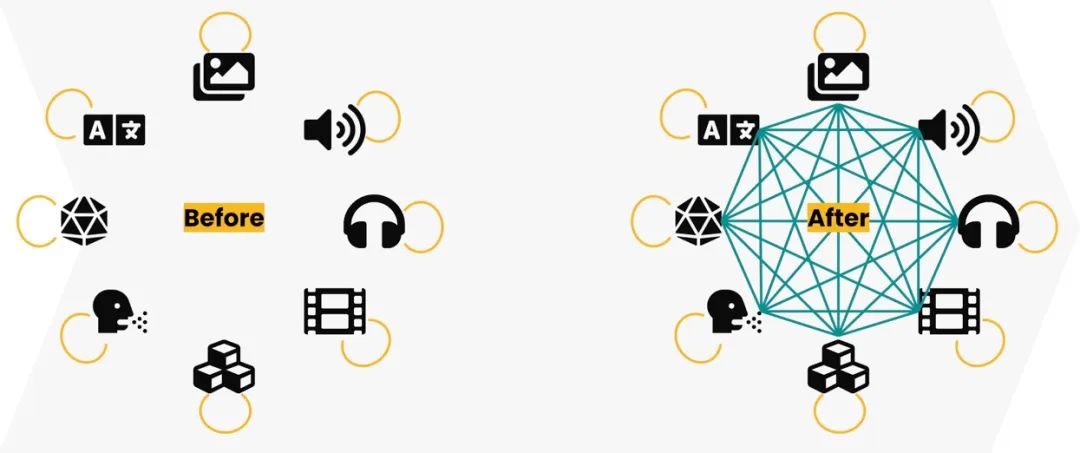
从单模态 AI 到多模态 AI 的范式转变
搜索和生成的二元性
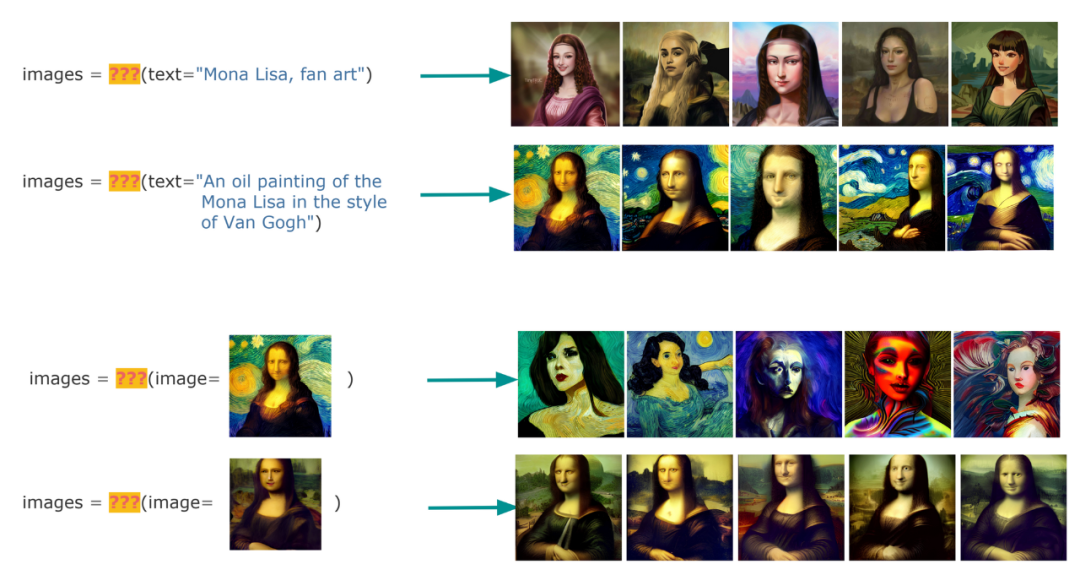
搜索和生成是多模态 AI 中的两项基本任务。在多模态 AI 领域,搜索是指神经搜索,即使用深度神经网络进行搜索。对于大多数人来说,这两个任务是完全孤立的,并且它们已经被分开研究了很多年。但是,搜索和生成是紧密相连的,并且具有共同的二元性。为了理解这一点,我们可以看看下面的例子。
有了多模态 AI,使用文本或图像来搜索图像数据集就非常简单:
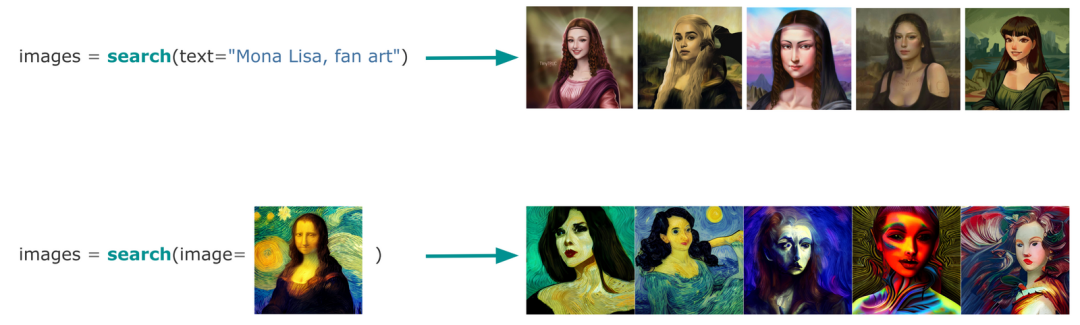
搜索:找到你需要的
创作是类似的。你从文本提示中创建一个新图像,或者通过丰富/修复现有图像来创建新图像:
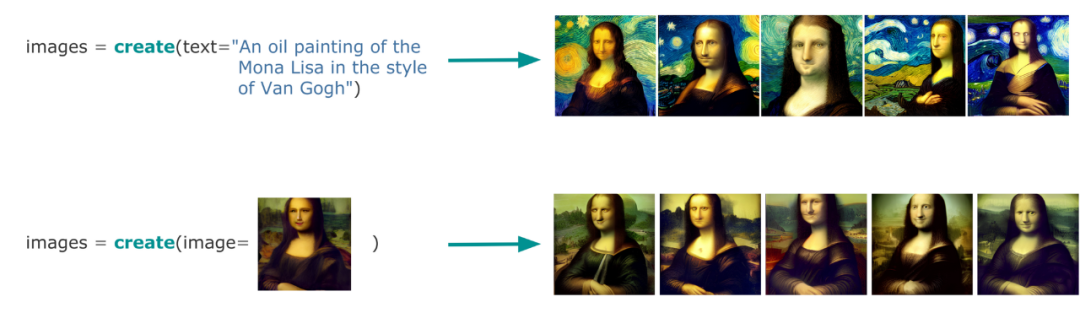
生成:制作你需要的
当把这两个任务组合在一起并屏蔽掉它们的函数名时,你可以看到这两个任务没有区别。两者都接收和输出相同的数据类型。唯一的区别是,搜索是找到你需要的东西,而生成是制造你需要的东西。
DNA 是一个很好的类比:一旦你有了一个生物体的 DNA,就可以构建系统发生树,并寻找已知最古老、最原始的源头。另一方面,你可以将 DNA 注入卵子并创造新的东西。
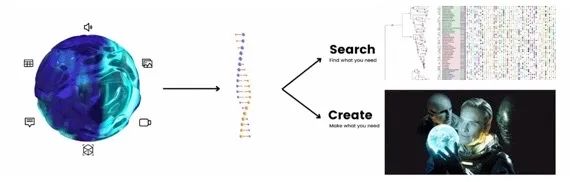
左:多模态人工智能框架下的搜索与创造的二元性
右:《异形:契约》电影海报
类似于哆啦A梦和瑞克,他们都拥有令人羡慕的超能力。但他们的不同在于哆啦A梦在他的口袋里寻找现有的物品,而瑞克则从他的车间创造了新东西。

哆啦A梦代表神经搜索,而瑞克代表生成式 AI
搜索和生成的二元性也带来了一个有趣的思想实验:想象一下,当生活在一个所有图像都由人工智能生成,而不是由人类构建的世界里。我们还需要(神经)搜索吗?或者说,我们还需要将图像嵌入到向量中,再使用向量数据库对其进行索引和排序吗?
答案是 NO。因为在观察图像之前,唯一代表图像的 seed 和 prompts 是已知的,后果现在变成了前因。与经典的表示法相比,学习图像是原因,表示法是结果。为了搜索图像,我们可以简单地存储 seed(一个整数)和 prompts(一个字符串),这不过是一个好的老式 BM25 或二分搜索。当然,我们作为人类还是更偏爱由人类自己创造的艺术品,所以平行宇宙暂时还不是真正的现实。至于为什么我们更应该关注生成式 AI 的进展 —— 因为处理多模态数据的老方法可能已经过时了。
总结
我们正处于人工智能新时代的前沿,多模态学习将很快占据主导地位。这种类型的学习结合了多种数据类型和模态的学习,有可能彻底改变我们与机器互动的方式。到目前为止,多模态 AI 已经在计算机视觉和自然语言处理等领域取得了巨大成功。在未来,毋庸置疑的是,多模态 AI 将产生更大的影响。例如,开发能够理解人类交流的细微差别的系统,或创造更逼真的虚拟助手。总而言之,未来拥有万种可能,而我们才只接触到冰山一角!
审核编辑:刘清
-
人工智能
+关注
关注
1797文章
47890浏览量
240907 -
机器学习
+关注
关注
66文章
8455浏览量
133181 -
LDA
+关注
关注
0文章
29浏览量
10668 -
nlp
+关注
关注
1文章
489浏览量
22130
原文标题:Jina AI创始人肖涵博士解读多模态AI的范式变革
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
芯片行业的IP是什么?芯片 IP 公司到底是做什么的?

stm32的这些时钟都是做什么的
嵌入式到底是干什么的
MIPI CSI D-PHY寄存器中HS-SETTLE参数到底是做什么?
半导体行业是做什么的_谁是中国半导体龙头
ip地址是做什么的
双面金属化聚丙烯膜电容到底是做什么用的?
芯片IP公司到底是做什么的?






 工商网监
工商网监
评论