 一个高可用的接口是该考虑哪些内容
一个高可用的接口是该考虑哪些内容
前言
作为一个后端研发人员,开发服务接口是我正常不过的工作了,这些接口不管是面向前端 HTTP 或者是供其他服务 RPC 远程调用的,都绕不开一个共同的话题就是 “高可用”,接口开发往往看似简单,但保证高可用这块实现起来却不并没有想想的那么容易,接下来我们就看一下,一个高可用的接口是该考虑哪些内容,同时文中有不足的欢迎批评指正。
到底啥是高可用
用一句简单的话来概就是我们的系统具不具备应对和规避风险的能力。
为啥做高可用
1. 程序都是有人开发的,在开发过程中会犯错从而导致线上事故的发生 2. 系统运行依赖各种运行环境:CPU、内存、硬盘、网络等等,而这些都有可能损坏 3. 业务拉新用户正在注册账号,结果注册接口挂了用户体验受影响 4. 双十一、618等大促大量用户下单,结果下单服务接口挂了GMV受影响等等 5. 其他未知因素等等 总之为了应对这些不可控因素的发生,我们必须要做高可用
高可用的关键点
我们说过高可用的本质是系统是否具备应对和规避风险的能力,那么从这个角度出发来设计高可用接口的有以下几个关键因素:Dependence(依赖)、Probability(概率)、Time(时长)、Scope(范围) 1. 依赖的资源相对少 2. 风险的概率足够低 3. 影响的范围足够小 4. 影响时长足够短
接口高可用设计的几个原则
结合这些关键点,我们来看一下具体具体注意事项
1、控制依赖
能少依赖就少依赖,能不强依赖就不强依赖
少依赖 例如:日常每分钟10个请求,查询Mysql数据即可满足,此时盲目引入Redis中间件,不仅浪费资源而且增加系统复杂性 弱依赖 例如:用户注册服务强依赖新用户优惠券发放服务,当优惠券发放服务故障后,整个注册不可用,好的方式是采用弱依赖,使用异步化的 方式,这样优惠券发送服务不可用时,不会影响注册链路。
2、避免单点
避免单点故障的核心是通过备份或者冗余快速的进行容错
1. 我们采用多机房多实力部署我们应用来保障故障风险分摊,一旦有一台服务器出现问题,其他服务仍然能够继续支撑我们的服务 2. 每次上线我们都会保留上一次上线发布版本,这样一旦上线的程序出现问题我们能够快速回滚到上一版本 3. 每个接口至少保障2人知道相关业务,一旦线上服务出现问题,其中任何一人一个能够快速处理相关线上问题 4. 不管是Mysql还是Redis等中间件都支持数据主备机群部署 类似的例子很多这里就不再一一列举了
3、负载均衡
将风险进行分摊避免分险扩散
例如:无论是Ngnix或者JSF的,其负载均衡目的就是尽量的将流量分散到不同的服务器节点上,这样可以有效的保障单节点因系统瓶颈 问题而引发一系列的风险。 像上面这个例子我想每个研发人员都知道也都会这么做,但是是不是所有的场景我们都考虑到均衡这个问题? 例如:通常为了提高读并发的能力,我们会把数据缓存到JIMDB中,但是因为缓存的key出现了热点数据导致JIMDB单分片负载过高,恰 好,这个分片上也缓存了其他数据,但是因为CPU负载过高,导致查询性能变差,大量的超时,影响了业务。所以,我们在接口设计 的时候,假如遇到类似场景,也要充分考虑数据存储的均衡性,同时针对热点数据做好监控,随时支持动态均衡。
4、资源隔离
隔离的目的将风险控制在可控范围内,避免风险扩散
例如:接口部署之间服务部署物理上是相互隔离的,避免单机房或者单服务器出现故障影响整个服务 例如:我们在存储业务数据的时候会将数据分库分表,数据通过不同分片存储,这样就不会导致某个服务器挂掉影响到整个服务
5、接口限流
限流是一种保护措施,目的是将风险控制在可控范围内
我们在开发接口的时候,一定要结合业务流量情况进行限流措施,限流一方面处于对自身服务资源的保护,同时也是对依赖资源的一种 保护措施。 目前集团JSF在流量控制这块已经有了对应的限流处理能力,同时我们也可以结合实际业务进行限流模块的开发。
6、服务熔断
熔断也是一种保护措施,目的是将风险控制在可控范围内,避免风险扩散
例如:经常我们服务A会同时调用B、C、D多个服务,当我们依赖的服务其中一个出现故障或者性能下降的时候,就是导致整体服务 可用率下降,所以我们在开发此类服务的时候,一定要注意接口之间的隔离。我们可以利用类似Hystrix组件实现,也可以借助DUCC 进行手动隔离。 其实熔断也是一种控制资源依赖的一种,将强依赖降级为弱依赖
7、异步处理
将同步操作转为异步操作
例如:用户页面领取一些权益,针对领取这个服务在大促期间因为用户流量较大,为了避免系统负载,此时采用MQ异步接收用户领取 请求然后进行优惠券发放,这样不仅极大的减少了事故的影响范围,也减少问题发生概率。
8、降级方案
服务降级属于一种问题发生后的补救措施,通过服务降级可以减少一部分风险影响范围
对于重要的服务接口我们都要具备完善的降级方案,这里需要说明的是,降级有损的,我们一定要在系统开发前就要考虑各种问题 发生的可能,降级的前提是通过降级非核心业务保证核心业务运行。 例如:大促峰值期间,一般会提前降级掉很多功能,同时限流,主要是为了保护峰值绝大部分人的交易支付体验。
9、灰度发布
通过灰度发布降低风险影响范围
例如:我们上线一个新服务,通过一定的灰度策略,让用户先行体验新版本的应用,通过收集这部分用户对新版本应用的反馈以及 对新版本功能、性能、稳定性等指标进行评论,进而决定继续放大新版本投放范围直至全量升级或回滚至老版本。根据线上反馈结果, 做到查漏补缺,发现重大问题,可回滚“旧版本”
10、混沌工程
通过提前对系统进行一些破坏性的手段,提前发现潜在问题
例如:一个复杂接口系统依赖了太多的服务和组件,这些组件随时随地都可能会发生故障,而一旦它们发生故障,会不会如蝴蝶效应 一般造成整体服务不可用呢,我们并不知道,因此我们可以借助泰山平台混沌工程进行演练,针对发生的场景制定各种预案,将风险 控制在可控范围内。
编辑:何安
-
接口
+关注
关注
33文章
8588浏览量
151100 -
服务
+关注
关注
0文章
75浏览量
18504 -
后端
+关注
关注
0文章
31浏览量
2236
原文标题:浅谈服务接口的高可用设计
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
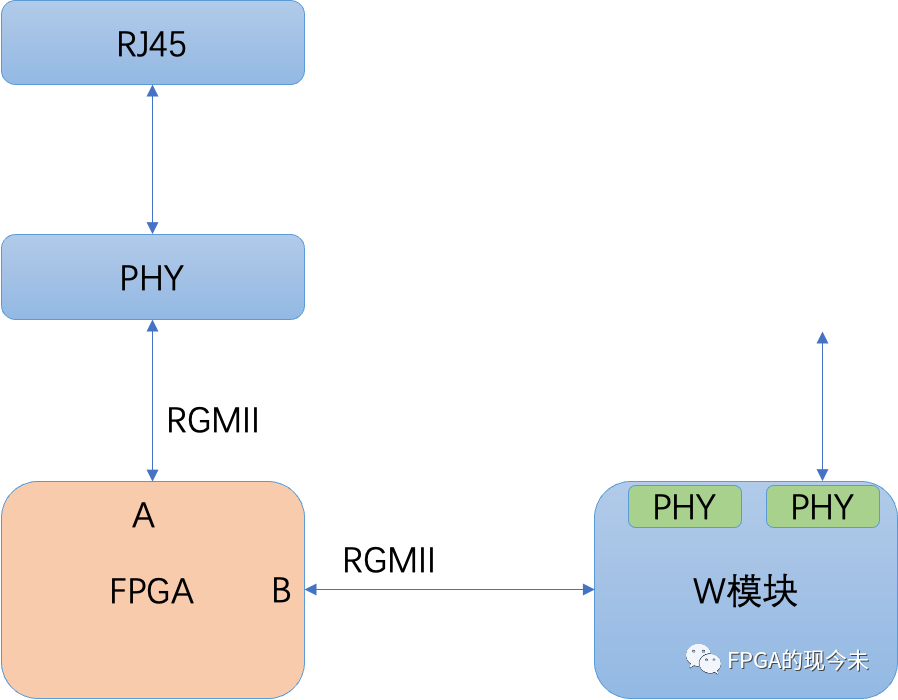
RGMII接口案例:二个设备共享一个PHY
升级至4K超高清12G-SDI接口时需要考虑的三个问题

通过安装该Linux-HA软件可以实现Linux双机系统的高可用性解决方案





 工商网监
工商网监
评论