 支持Python和Java的BigCode开源轻量级语言模型
支持Python和Java的BigCode开源轻量级语言模型

BigCode 是一个开放的科学合作组织,致力于开发大型语言模型。
近日他们开源了一个名为 SantaCoder 的语言模型,该模型拥有 11 亿个参数,可以用于 Python、Java 和 JavaScript 这几种编程语言的代码生成和补全建议。
根据官方提供的信息,训练 SantaCoder 的基础是 The Stack(v1.1)数据集,SantaCoder 虽然规模相对较小,只有 11 亿个参数,在参数的绝对数量上低于 InCoder(67 亿)或 CodeGen-multi(27 亿),但 SantaCoder 的表现则是要远好于这些大型多语言模型。
不过也正是参数远远不及 GPT-3 等参数超过千亿级别的超大型语言模型,SantaCoder 适用的编程语言范围也比较有限,仅支持 Python、Java 和 JavaScript 三种语言。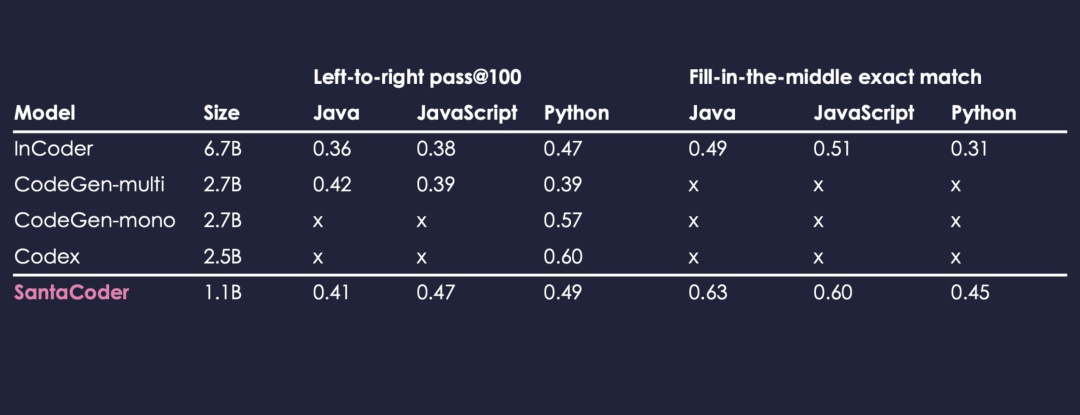
为了照顾用户隐私和保证训练质量,在训练模型之前,BigCode 注释了 400 个样本,并建立和不断完善 RegEx 规则,以便在训练前从数据集的代码中删除诸如电子邮件地址、密钥和 IP 地址等敏感信息。
为了让开发者可以放心使用 SantaCoder 生成的代码,BigCode 推出了Dataset Search搜索工具。
通过这个工具,开发者可以找出代码的来源,以便在 SantaCoder 产生的代码属于某一个项目的情况下,用户能够遵守相应的许可要求。
此外,BigCode 还推出了「Am I in The Stack?」工具,开发者可以检查自己名下的仓库是否是训练数据集的一部分,可以将自己的开源仓库从数据集中删除。
BigCode 目前已经在 Huggingface 网站中提供了 SantaCoder 演示。
审核编辑:刘清
-
JAVA语言
+关注
关注
0文章
138浏览量
21698 -
javascript
+关注
关注
0文章
526浏览量
56589 -
python
+关注
关注
59文章
4892浏览量
90408 -
GPT
+关注
关注
0文章
376浏览量
17013
原文标题:BigCode开源轻量级语言模型,仅支持Python、JS和Java
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
轻量级Java表达式引擎aviator的基本使用
轻量级Agent平台怎么测试?
轻量级的ui框架如何去制作
后端选择 java, 还是 python?
适用于Java的嵌入式脚本语言是什么
Lite Actor:方舟Actor并发模型的轻量级优化
最流行的编程语言java,python

基于YOLO改进的轻量级交通标识检测模型

一款适合初学者超轻量级C语言网络库—Dyad




评论