 NVIDIA Triton 系列文章(11):模型类别与调度器-2
NVIDIA Triton 系列文章(11):模型类别与调度器-2
在上篇文章中,已经说明了有状态(stateful)模型的“控制输入”与“隐式状态管理”的使用方式,本文内容接着就继续说明“调度策略”的使用。
(续前一篇文章的编号)
(3) 调度策略(Scheduling Strategies)在决定如何对分发到同一模型实例的序列进行批处理时,序列批量处理器(sequence batcher)可以采用以下两种调度策略的其中一种:
现在简单说明以下配置的内容: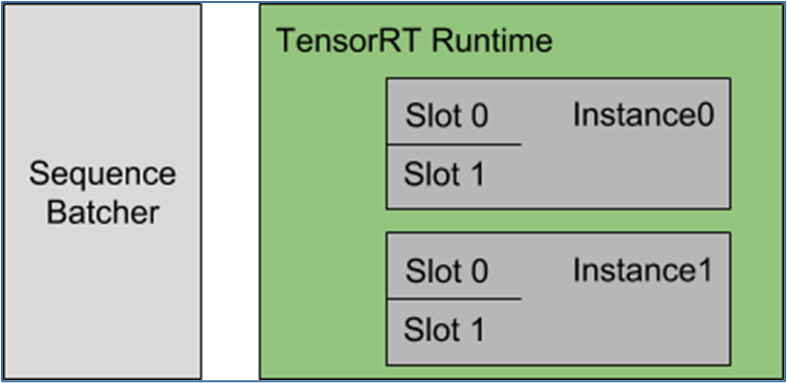 每个模型实例都在维护每个批处理槽的状态,并期望将给定序列的所有推理请求分发到同一槽,以便正确更新状态。对于本例,这意味着 Triton 可以同时 4 个序列进行推理。
使用直接调度策略,序列批处理程序会执行以下动作:
每个模型实例都在维护每个批处理槽的状态,并期望将给定序列的所有推理请求分发到同一槽,以便正确更新状态。对于本例,这意味着 Triton 可以同时 4 个序列进行推理。
使用直接调度策略,序列批处理程序会执行以下动作:
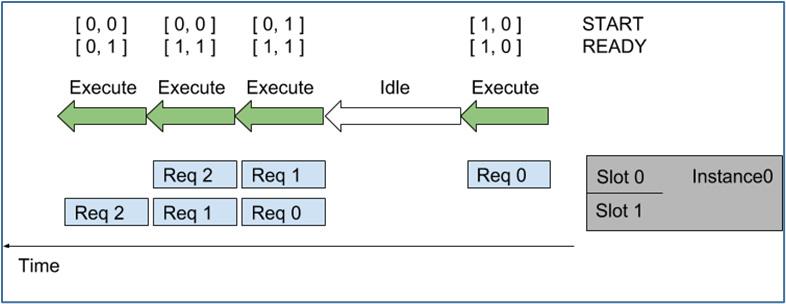
下图显示使用直接调度策略,将多个序列调度到模型实例上的执行:
 图左显示了到达 Triton 的 5 个请求序列,每个序列可以由任意数量的推理请求组成。图右侧显示了推理请求序列是如何随时间安排到模型实例上的,
图左显示了到达 Triton 的 5 个请求序列,每个序列可以由任意数量的推理请求组成。图右侧显示了推理请求序列是如何随时间安排到模型实例上的,
 随着时间的推移(从右向左),会发生以下情况:
随着时间的推移(从右向左),会发生以下情况:
在本示例中,模型需要序列批量处理的开始、结束和相关 ID 控制输入。下图显示了此配置指定的序列批处理程序和推理资源的表示。
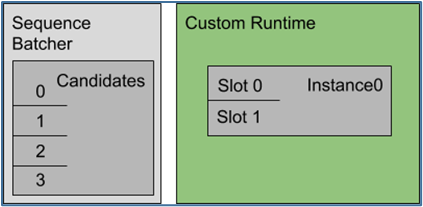 使用最旧的调度策略,序列批处理程序会执行以下工作:
使用最旧的调度策略,序列批处理程序会执行以下工作:
下图显示将多个序列调度到上述示例配置指定的模型实例上,左图显示 Triton 接收了四个请求序列,每个序列由多个推理请求组成:
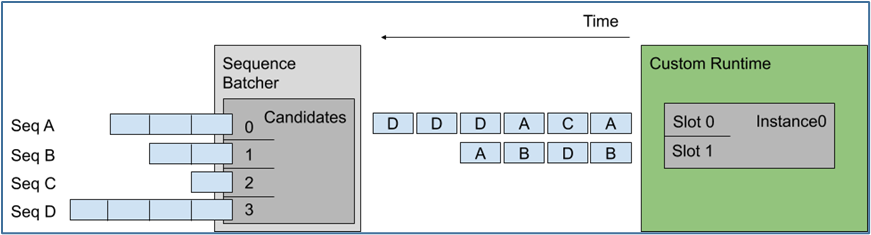 这里假设每个请求的长度是相同的,那么左边候选序列中送进右边批量处理槽的顺序,就是上图中间的排列顺序。
最旧的策略从最旧的请求中形成一个动态批处理,但在一个批处理中从不包含来自给定序列的多个请求,例如上面序列 D 中的最后两个推理不是一起批处理的。
以上是关于有状态模型的“调度策略”主要内容,剩下的“集成模型”部分,会在下篇文章中提供完整的说明。
这里假设每个请求的长度是相同的,那么左边候选序列中送进右边批量处理槽的顺序,就是上图中间的排列顺序。
最旧的策略从最旧的请求中形成一个动态批处理,但在一个批处理中从不包含来自给定序列的多个请求,例如上面序列 D 中的最后两个推理不是一起批处理的。
以上是关于有状态模型的“调度策略”主要内容,剩下的“集成模型”部分,会在下篇文章中提供完整的说明。
- 直接(direct)策略
| name: "direct_stateful_model"platform: "tensorrt_plan"max_batch_size: 2sequence_batching{ max_sequence_idle_microseconds: 5000000direct { } control_input [{name: "START" control [{ kind: CONTROL_SEQUENCE_START fp32_false_true: [ 0, 1 ]}]},{name: "READY" control [{ kind: CONTROL_SEQUENCE_READY fp32_false_true: [ 0, 1 ]}]}]}#续接右栏 | #上接左栏input [{name: "INPUT" data_type: TYPE_FP32dims: [ 100, 100 ]}]output [{name: "OUTPUT" data_type: TYPE_FP32dims: [ 10 ]}]instance_group [{ count: 2}] |
- sequence_batching 部分指示模型会使用序列调度器的 Direct 调度策略;
- 示例中模型只需要序列批处理程序的启动和就绪控制输入,因此只列出这些控制;
- instance_group 表示应该实例化模型的两个实例;
- max_batch_size 表示这些实例中的每一个都应该执行批量大小为 2 的推理计算。
每个模型实例都在维护每个批处理槽的状态,并期望将给定序列的所有推理请求分发到同一槽,以便正确更新状态。对于本例,这意味着 Triton 可以同时 4 个序列进行推理。
使用直接调度策略,序列批处理程序会执行以下动作:
| 所识别的推理请求种类 | 执行动作 |
| 需要启动新序列 | 1. 有可用处理槽时:就为该序列分配批处理槽2. 无可用处理槽时:就将推理请求放在积压工作中 |
| 是已分配处理槽序列的一部分 | 将该请求分发到该配置好的批量处理槽 |
| 是积压工作中序列的一部分 | 将请求放入积压工作中 |
| 是最后一个推理请求 | 1. 有积压工作时:将处理槽分配给积压工作的序列2. 有积压工作:释放该序列处理槽给其他序列使用 |
图左显示了到达 Triton 的 5 个请求序列,每个序列可以由任意数量的推理请求组成。图右侧显示了推理请求序列是如何随时间安排到模型实例上的,
- 在实例 0 与实例 1 中各有两个槽 0 与槽 1;
- 根据接收的顺序,为序列 0 至序列 3 各分配一个批量处理槽,而序列 4 与序列 5 先处于排队等候状态;
- 当序列 3 的请求全部完成之后,将处理槽释放出来给序列 4 使用;
- 当序列 1 的请求全部完成之后,将处理槽释放出来给序列 5 使用;
随着时间的推移(从右向左),会发生以下情况:- 序列中第一个请求(Req 0)到达槽 0 时,因为模型实例尚未执行推理,则序列调度器会立即安排模型实例执行,因为推理请求可用;
- 由于这是序列中的第一个请求,因此 START 张量中的对应元素设置为 1,但槽 1 中没有可用的请求,因此 READY 张量仅显示槽 0 为就绪。
- 推理完成后,序列调度器会发现任何批处理槽中都没有可用的请求,因此模型实例处于空闲状态。
- 接下来,两个推理请求(上面的 Req 1 与下面的 Req 0)差不多的时间到达,序列调度器看到两个处理槽都是可用,就立即执行批量大小为 2 的推理模型实例,使用 READY 显示两个槽都有可用的推理请求,但只有槽 1 是新序列的开始(START)。
- 对于其他推理请求,处理以类似的方式继续。
- 最旧的(oldest)策略
| 直接(direct)策略 | 最旧的(oldest)策略 |
|
direct {} |
oldest { max_candidate_sequences: 4 } |
使用最旧的调度策略,序列批处理程序会执行以下工作:
| 所识别的推理请求种类 | 执行动作 |
| 需要启动新序列 | 尝试查找具有候选序列空间的模型实例,如果没有实例可以容纳新的候选序列,就将请求放在一个积压工作中 |
| 已经是候选序列的一部分 | 将该请求分发到该模型实例 |
| 是积压工作中序列的一部分 | 将请求放入积压工作中 |
| 是最后一个推理请求 | 模型实例立即从积压工作中删除一个序列,并将其作为模型实例中的候选序列,或者记录如果没有积压工作,模型实例可以处理未来的序列。 |
这里假设每个请求的长度是相同的,那么左边候选序列中送进右边批量处理槽的顺序,就是上图中间的排列顺序。
最旧的策略从最旧的请求中形成一个动态批处理,但在一个批处理中从不包含来自给定序列的多个请求,例如上面序列 D 中的最后两个推理不是一起批处理的。
以上是关于有状态模型的“调度策略”主要内容,剩下的“集成模型”部分,会在下篇文章中提供完整的说明。
原文标题:NVIDIA Triton 系列文章(11):模型类别与调度器-2
文章出处:【微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
英伟达
+关注
关注
22文章
3778浏览量
91148
原文标题:NVIDIA Triton 系列文章(11):模型类别与调度器-2
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Triton编译器与GPU编程的结合应用
Triton编译器简介 Triton编译器是一种针对并行计算优化的编译器,它能够自动将高级语言代码转换为针对特定硬件优化的低级代码。
Triton编译器如何提升编程效率
在现代软件开发中,编译器扮演着至关重要的角色。它们不仅将高级语言代码转换为机器可执行的代码,还通过各种优化技术提升程序的性能。Triton 编译器作为一种先进的编译器,通过多种方式提升
Triton编译器在高性能计算中的应用
高性能计算(High-Performance Computing,HPC)是现代科学研究和工程计算中不可或缺的一部分。随着计算需求的不断增长,对计算资源的要求也越来越高。Triton编译器作为一种
Triton编译器的优化技巧
在现代计算环境中,编译器的性能对于软件的运行效率至关重要。Triton 编译器作为一个先进的编译器框架,提供了一系列的优化技术,以确保生成的
Triton编译器的优势与劣势分析
Triton编译器作为一种新兴的深度学习编译器,具有一系列显著的优势,同时也存在一些潜在的劣势。以下是对Triton编译
Triton编译器的常见问题解决方案
Triton编译器作为一款专注于深度学习的高性能GPU编程工具,在使用过程中可能会遇到一些常见问题。以下是一些常见问题的解决方案: 一、安装与依赖问题 检查Python版本 Triton编译器
Triton编译器支持的编程语言
Triton编译器支持的编程语言主要包括以下几种: 一、主要编程语言 Python :Triton编译器通过Python接口提供了对Triton
Triton编译器与其他编译器的比较
Triton编译器与其他编译器的比较主要体现在以下几个方面: 一、定位与目标 Triton编译器 : 定位:专注于深度学习中最核心、最耗时的
Triton编译器功能介绍 Triton编译器使用教程
Triton 是一个开源的编译器前端,它支持多种编程语言,包括 C、C++、Fortran 和 Ada。Triton 旨在提供一个可扩展和可定制的编译器框架,允许开发者添加新的编程语言
NVIDIA助力提供多样、灵活的模型选择
在本案例中,Dify 以模型中立以及开源生态的优势,为广大 AI 创新者提供丰富的模型选择。其集成的 NVIDIAAPI Catalog、NVIDIA NIM和Triton 推理服务
NVIDIA Nemotron-4 340B模型帮助开发者生成合成训练数据
Nemotron-4 340B 是针对 NVIDIA NeMo 和 NVIDIA TensorRT-LLM 优化的模型系列,该系列包含最先进

使用NVIDIA Triton推理服务器来加速AI预测
这家云计算巨头的计算机视觉和数据科学服务使用 NVIDIA Triton 推理服务器来加速 AI 预测。
在AMD GPU上如何安装和配置triton?
最近在整理python-based的benchmark代码,反过来在NV的GPU上又把Triton装了一遍,发现Triton的github repo已经给出了对应的llvm的commit id以及对应的编译细节,然后跟着走了一遍,也顺利的安装成功,只需要按照如下方式即可完

利用NVIDIA产品技术组合提升用户体验
本案例通过利用NVIDIA TensorRT-LLM加速指令识别深度学习模型,并借助NVIDIA Triton推理服务器在





 工商网监
工商网监
评论