 国内最大自动驾驶智算中心发布,为何车企纷纷自建智算中心?
国内最大自动驾驶智算中心发布,为何车企纷纷自建智算中心?
电子发烧友网报道(文/李弯弯)前不久,毫末智行与火山引擎共同发布了中国自动驾驶行业最大的智算中心——毫末“雪湖·绿洲”(MANA OASIS)。据毫末智行CEO顾维灏介绍,MANA OASIS的算力高达67亿亿次/秒,存储带宽可达2T/秒,通信带宽达到800G/秒,可以为自动驾驶技术的持续迭代提供充足动力。
不仅仅是自动驾驶车自身算力,智算中心也成为车企和自动驾驶公司竞争的焦点。众所周知,自动驾驶行业的领军企业特斯拉在几年前就已经建立自己的智算中心,并且还自研芯片以提升效率。国内除了毫末智行,小鹏汽车在今年8月也宣布已经建成自动驾驶智算中心。
多方面优化,MANA OASIS训练效率提升100倍
结合自动驾驶近十年的发展历史,毫末智行认为,可以将近十年的自动驾驶技术发展分成三个阶段:最早的硬件驱动方式,可以称为自动驾驶的1.0时代;最近几年的软件驱动方式,可称之为自动驾驶的2.0时代;即将发生,并将持续发展的数据驱动方式,是自动驾驶的3.0时代。数据驱动也是自动驾驶发展公认的方向,而它对智算中心的要求很高。
因此毫末和火山引擎共同定制了一个属于自动驾驶的智算中心。具体来看,在系统架构方面,如下图,左边是高性能存储,基于高性能并行文件系统VePFS,可以提供高达2T/s的读取速度,并且支持百亿级小文件高速读写。右边是计算平台,提供了充沛的算力,每台服务器配置8个GPU卡,通过600G/s的双向NVSwitch高速互联,进行通信。服务器之间通过4张200G带宽的RDMA网络互联,提供高达800G/s的网络带宽。
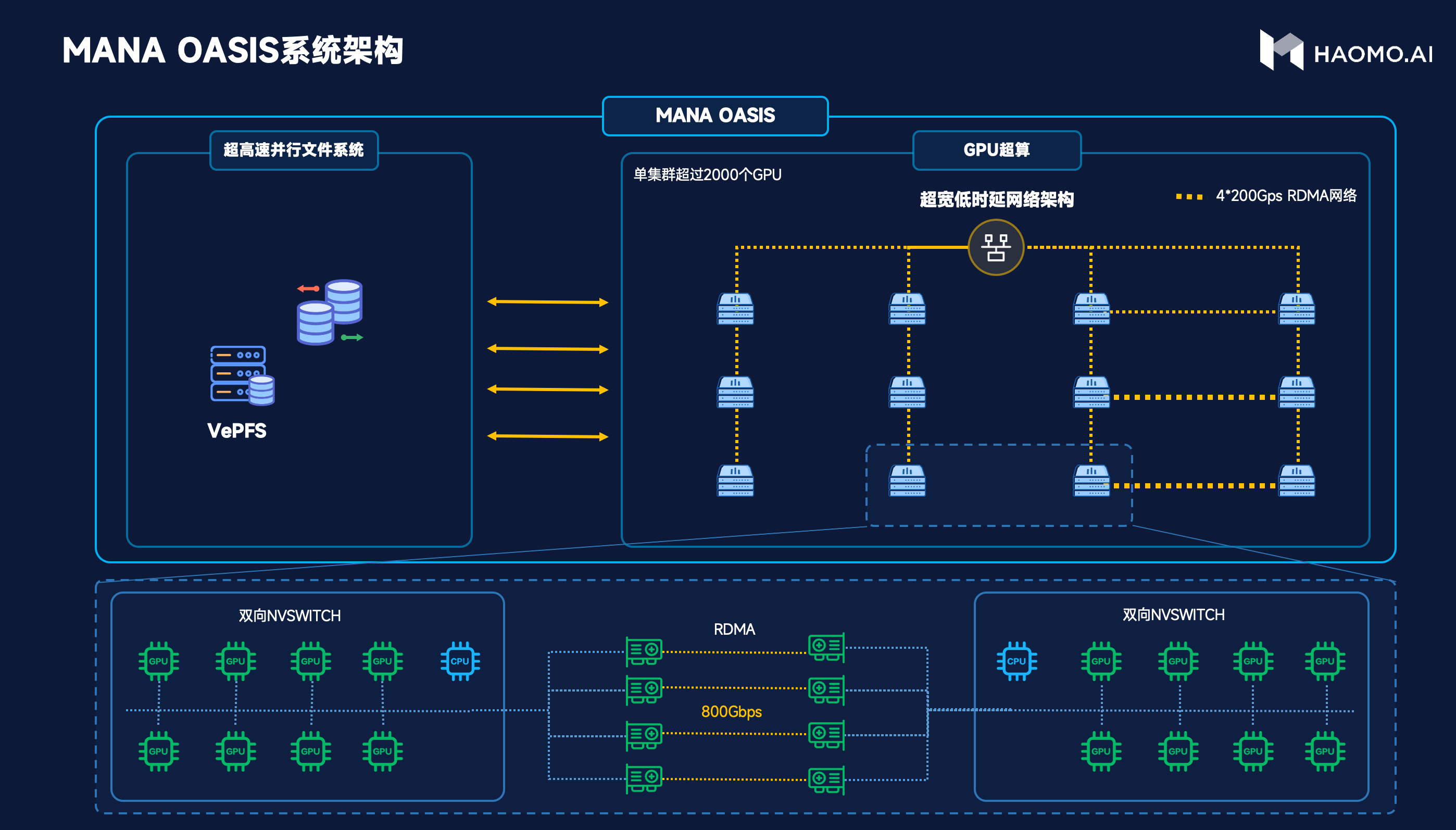
在数据管理上,为了充分发挥智算中心的价值,让GPU持续饱和运行,毫末经过2年多研发,建立了全套面向大规模AI训练的毫末文件系统。在采集端,把数据按照训练的要求,以4D Clip为单位组织文件形态;在传输端,基于毫末场景库,对数据进行场景化分析,打上各类Tag,方便模型基于Tag从不同维度对数据进行采样、分布统计、语料提取;在训练端,基于分级存储理念,把对象存储、高性能、显存充分整合,实现高容量与高性能并存。
最终实现了百P数据筛选速度提升10倍、百亿小文件随机读写延迟小于500us。在毫末文件系统的加持下,消除数据瓶颈,GPU利用率从60%提升到接近80%。
在MANA OASIS的训练加速上也做了大量优化。大家都知道,transformer大模型的训练成本非常高,训练一个大模型有时成本高达几千万。毫末在此方向深入研究,借鉴了学术界最新的研究成果,基于Sparse MoE,可以根据计算特点,进行稀疏激活,提高计算效率,实现单机8卡就能训练百亿参数大模型的效果。
毫末智算中心也实现了跨机共享expert的方法,完成千亿参数规模大模型的训练,而且训练成本降低到百卡周级别。在此基础上,毫末基于自己的业务特点,设计并实现了业界领先的多任务并行训练系统,能同时处理图片、点云、结构化文本等多种模态的信息,既保证了模型的稀疏性,又提升了计算效率。结合多方面的优化,毫末智算中心的训练效率提升了100倍。
为何小鹏、特斯拉等车企要建立自己的智算中心
除了毫末智行,小鹏汽车、特斯拉等车企也已建设自己的智算中心。今年8月,小鹏汽车宣布在乌兰察布建成当时中国最大的自动驾驶智算中心“扶摇”,用于自动驾驶模型训练。“扶摇”基于阿里云智能计算平台,算力可达600PFLOPS(每秒浮点运算60亿亿次),将小鹏自动驾驶核心模型的训练速度提升了近170倍。
通过与阿里云合作,“扶摇”以更低成本实现了更强算力。具体来看,对GPU资源进行细粒度切分、调度,将GPU资源虚拟化利用率提高3倍,支持更多人同时在线开发,效率提升十倍以上。在通讯层面,端对端通信延迟降低80%至2微秒。
整体计算效率上,实现了算力的线性扩展。存储吞吐比业界20GB/s的普遍水准提升了40倍,数据传输能力相当于从送快递的微型面包车,换成了20多米长的40吨集装箱重卡。此外,阿里云机器学习平台PAI提供了模型训练部署、推理优化等AI工程化工具,比开源框架训练性能提升30%以上。
“扶摇”支持小鹏自动驾驶核心模型的训练时长从7天,缩短至1小时内,大幅提速近170倍。据介绍,“扶摇”正用于小鹏城市NGP辅助驾驶系统的算法模型训练。和高速道路相比,城市路段的交通状况更为复杂,自动驾驶特殊场景的数据集规模增加了上百倍。
早几年前,特斯拉就已经建立了自己的AI计算中心——Dojo,总计使用了1.4万个英伟达的GPU来训练AI模型。为了进一步提升效率,特斯拉在2021年发布了自研的AI加速芯片D1,25个D1封装在一起组成一个训练模块(Training tile),然后再将训练模块组成一个机柜(Dojo ExaPOD)。在今年10月的AI Day上,特斯拉展示了自有AI计算中心的最新进展,用自研的D1芯片打造的计算设备能够提升30%的模型训练效率。
可以看到,车企和自动驾驶公司自建智算中心,能够在性能上进行多方面的优化,提升效率。此外在成本上也会更有利,何小鹏此前谈到,对于智能汽车公司来说,算力成本将会从今天的亿元级别上升到将来的十亿元级别。因此,如果持续使用公有云服务,边际成本将会不断上涨。如果自行组建智算中心,一次性投资约在数千万到1亿元以内,长期来看性价比更高。
不仅仅是自动驾驶车自身算力,智算中心也成为车企和自动驾驶公司竞争的焦点。众所周知,自动驾驶行业的领军企业特斯拉在几年前就已经建立自己的智算中心,并且还自研芯片以提升效率。国内除了毫末智行,小鹏汽车在今年8月也宣布已经建成自动驾驶智算中心。
多方面优化,MANA OASIS训练效率提升100倍
结合自动驾驶近十年的发展历史,毫末智行认为,可以将近十年的自动驾驶技术发展分成三个阶段:最早的硬件驱动方式,可以称为自动驾驶的1.0时代;最近几年的软件驱动方式,可称之为自动驾驶的2.0时代;即将发生,并将持续发展的数据驱动方式,是自动驾驶的3.0时代。数据驱动也是自动驾驶发展公认的方向,而它对智算中心的要求很高。
因此毫末和火山引擎共同定制了一个属于自动驾驶的智算中心。具体来看,在系统架构方面,如下图,左边是高性能存储,基于高性能并行文件系统VePFS,可以提供高达2T/s的读取速度,并且支持百亿级小文件高速读写。右边是计算平台,提供了充沛的算力,每台服务器配置8个GPU卡,通过600G/s的双向NVSwitch高速互联,进行通信。服务器之间通过4张200G带宽的RDMA网络互联,提供高达800G/s的网络带宽。
在数据管理上,为了充分发挥智算中心的价值,让GPU持续饱和运行,毫末经过2年多研发,建立了全套面向大规模AI训练的毫末文件系统。在采集端,把数据按照训练的要求,以4D Clip为单位组织文件形态;在传输端,基于毫末场景库,对数据进行场景化分析,打上各类Tag,方便模型基于Tag从不同维度对数据进行采样、分布统计、语料提取;在训练端,基于分级存储理念,把对象存储、高性能、显存充分整合,实现高容量与高性能并存。
最终实现了百P数据筛选速度提升10倍、百亿小文件随机读写延迟小于500us。在毫末文件系统的加持下,消除数据瓶颈,GPU利用率从60%提升到接近80%。
在MANA OASIS的训练加速上也做了大量优化。大家都知道,transformer大模型的训练成本非常高,训练一个大模型有时成本高达几千万。毫末在此方向深入研究,借鉴了学术界最新的研究成果,基于Sparse MoE,可以根据计算特点,进行稀疏激活,提高计算效率,实现单机8卡就能训练百亿参数大模型的效果。
毫末智算中心也实现了跨机共享expert的方法,完成千亿参数规模大模型的训练,而且训练成本降低到百卡周级别。在此基础上,毫末基于自己的业务特点,设计并实现了业界领先的多任务并行训练系统,能同时处理图片、点云、结构化文本等多种模态的信息,既保证了模型的稀疏性,又提升了计算效率。结合多方面的优化,毫末智算中心的训练效率提升了100倍。
为何小鹏、特斯拉等车企要建立自己的智算中心
除了毫末智行,小鹏汽车、特斯拉等车企也已建设自己的智算中心。今年8月,小鹏汽车宣布在乌兰察布建成当时中国最大的自动驾驶智算中心“扶摇”,用于自动驾驶模型训练。“扶摇”基于阿里云智能计算平台,算力可达600PFLOPS(每秒浮点运算60亿亿次),将小鹏自动驾驶核心模型的训练速度提升了近170倍。
通过与阿里云合作,“扶摇”以更低成本实现了更强算力。具体来看,对GPU资源进行细粒度切分、调度,将GPU资源虚拟化利用率提高3倍,支持更多人同时在线开发,效率提升十倍以上。在通讯层面,端对端通信延迟降低80%至2微秒。
整体计算效率上,实现了算力的线性扩展。存储吞吐比业界20GB/s的普遍水准提升了40倍,数据传输能力相当于从送快递的微型面包车,换成了20多米长的40吨集装箱重卡。此外,阿里云机器学习平台PAI提供了模型训练部署、推理优化等AI工程化工具,比开源框架训练性能提升30%以上。
“扶摇”支持小鹏自动驾驶核心模型的训练时长从7天,缩短至1小时内,大幅提速近170倍。据介绍,“扶摇”正用于小鹏城市NGP辅助驾驶系统的算法模型训练。和高速道路相比,城市路段的交通状况更为复杂,自动驾驶特殊场景的数据集规模增加了上百倍。
早几年前,特斯拉就已经建立了自己的AI计算中心——Dojo,总计使用了1.4万个英伟达的GPU来训练AI模型。为了进一步提升效率,特斯拉在2021年发布了自研的AI加速芯片D1,25个D1封装在一起组成一个训练模块(Training tile),然后再将训练模块组成一个机柜(Dojo ExaPOD)。在今年10月的AI Day上,特斯拉展示了自有AI计算中心的最新进展,用自研的D1芯片打造的计算设备能够提升30%的模型训练效率。
可以看到,车企和自动驾驶公司自建智算中心,能够在性能上进行多方面的优化,提升效率。此外在成本上也会更有利,何小鹏此前谈到,对于智能汽车公司来说,算力成本将会从今天的亿元级别上升到将来的十亿元级别。因此,如果持续使用公有云服务,边际成本将会不断上涨。如果自行组建智算中心,一次性投资约在数千万到1亿元以内,长期来看性价比更高。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
自动驾驶
+关注
关注
787文章
13992浏览量
167635 -
智算中心
+关注
关注
0文章
80浏览量
1863
发布评论请先 登录
相关推荐
信而泰CCL仿真:解锁AI算力极限,智算中心网络性能跃升之道
引言 随着AI大模型训练和推理需求的爆发式增长,智算中心网络的高效性与稳定性成为决定AI产业发展的核心要素。信而泰凭借自主研发的 CCL(集合通信库)评估工具 与 DarYu-X系列测试仪 ,为智算
智算中心的核心硬件是什么?
智算中心,作为人工智能时代的关键基础设施,其核心硬件的构成与性能直接影响着智能计算的效率与质量。以下是对智算中心核心硬件的详细阐述:一、AI芯片AI芯片是专门为加速人工智能计算而设计的

算智算中心的算力如何衡量?
作为当下科技发展的重要基础设施,其算力的衡量关乎其能否高效支撑人工智能、大数据分析等智能应用的运行。以下是对智算中心算力衡量的详细阐述:一、算力的基本定义与单位1、
智算中心会取代通用算力中心吗?
随着人工智能(AI)技术的飞速发展,计算需求不断攀升,数据中心行业正经历着前所未有的变革。传统的通用算力中心与新兴的智算中心之间的竞争日益激
宁畅助推智算中心发展迈入新阶段
在“全局智算”战略下,宁畅正式发布“全栈全液”AI基础设施方案 ,在业内首先实现了“全栈全液”的智算中心建设能力,助推智算
OCTC发布"算力工厂"!力促智算中心高效规划建设投运
创新提出面向未来数据中心的"算力工厂"模式,核心是以规(划)、建(设)、运(营)一体化的交钥匙工程,实现智算中心快速投运、绿色低碳,在当前AIGC算

中国移动智算中心(哈尔滨)成为最大单集群智算中心
9月6日最新资讯,中国移动智算中心(哈尔滨)正式宣告投入运营,这一里程碑事件不仅标志着中国移动在智能计算领域的又一重大突破,更确立了其在全球运营商中拥有最大规模单集群智算
FPGA在自动驾驶领域有哪些应用?
FPGA(Field-Programmable Gate Array,现场可编程门阵列)在自动驾驶领域具有广泛的应用,其高性能、可配置性、低功耗和低延迟等特点为自动驾驶的实现提供了强有力的支持。以下
发表于 07-29 17:09
中国算力中心市场持续增长,智能算力规模快速崛起
7月24日,中国信息通信研究院(简称“中国信通院”)权威发布了《中国算力中心服务商分析报告(2024年)》,该报告深入剖析了中国算力中心市场
智算中心加速布局,上游计算、存储、互联都涉及哪些芯片技术
的人工智能应用需求。 近期,中国各地纷纷加快数字基建项目的建设步伐,智算中心成为布局重点。从北京到四川,从宁夏到河南,多地智算中心项目相
算力中心:数字经济发展的新引擎
随着数字经济的快速发展,算力中心正逐渐成为推动经济发展的重要力量。算力中心是指能够提供大规模、高效率、低成本算力服务的计算
未来已来,多传感器融合感知是自动驾驶破局的关键
方面表示,这是L4级自动驾驶公司和车企为了打造Robotaxi量产车,在国内成立的首个合资公司。首款车型已完成产品定义,正在进行设计造型的联
发表于 04-11 10:26





 工商网监
工商网监
评论