 NeRF的研究目的是合成同一场景不同视角下的图像
NeRF的研究目的是合成同一场景不同视角下的图像
NeRF,即Neural Radiance Fields(神经辐射场)的缩写。研究员来自UCB、Google和UCSD。
Title:NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
Paper:https://arxiv.org/pdf/2003.08934.pdf
Code:https://github.com/bmild/nerf
写这篇文章的动机是,一方面NeRF实在太重要了代表着计算机视觉、图像学结合的未来重要方向;另一方面NeRF对于计算机视觉背景的同学有一定的理解门槛,这篇文章试图以最小背景知识补充、最少理解成本为前提介绍NeRF。
整体介绍
NeRF的研究目的是合成同一场景不同视角下的图像。方法很简单,根据给定一个场景的若干张图片,重构出这个场景的3D表示,然后推理的时候输入不同视角就可以合成(渲染)这个视角下的图像了。
「3D表示」有很多种形式,NeRF使用的是辐射场,然后用「体渲染」(Volume Rendering)技术,给定一个相机视角,把辐射场渲染成一张图像。选用辐射场+体渲染的原因很简单,全程可微分。这个过程很有意思,可以理解为把一个空间朝一个方向上拍扁,空间中的颜色加权求和得到平面上的颜色。
辐射场

体渲染
所谓体渲染,直观地说,我们知道相机的焦点,焦点和像素的连线可以连出来一条射线,我们可以对这条射线上所有的点的颜色做某种求和就可以得到这个像素的颜色值。
理论上,我们可以对这条射线经过空间上的每个点的密度(只和空间坐标相关)和颜色(同时依赖空间坐标和入射角)进行某种积分就可以得到每个像素的颜色。当每个像素的颜色都计算出来,那么这个视角下的图像就被渲染出来了。如下图所示:

从相机焦点出发,往一个像素连出一条射线,获取射穿过空间中每个点的属性,进行积分得到这个像素的颜色
为了顺利完成上面过程,我们可能需要维护硕大无朋Tensor来表示辐射场,查表获取RGB和密度。这里一个问题是空间有多大表就有多大,同时只能是离散表示的。NeRF要做的事情是用一个神经网络来建模辐射场,这样无论空间有多大,不影响我们表示辐射场的所需要的存储量,而且这个辐射场表示是连续的:�Θ:(�,�,�,�,�)→(�,�,�,�
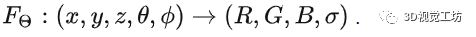
用神经网络来代替查表的方式表示辐射场
整体过程
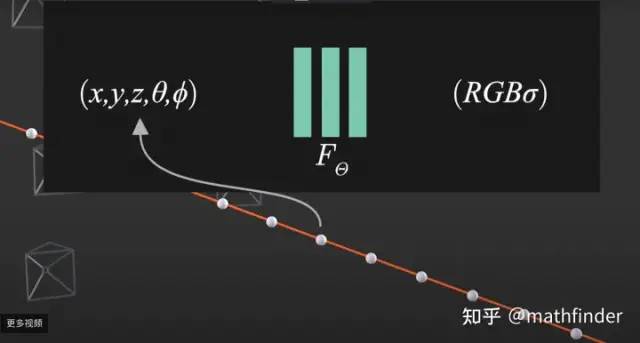
因为神经网络是可微分的,选取的体渲染方法是可微分;体渲染得到的图片和原图计算MSE Loss。整个过程可端到端地用梯度回传来优化非常漂亮。整个训练Pipeline如下图所示:
看到这,读者就已经大致理解NeRF的原理了,后面章节是NeRF的具体细节。
用辐射场做体渲染
前面我们已经大致理解体渲染的过程是怎么做了。可是怎么沿着射线对空间中的颜色进行积分呢?如果我们把射线看作是光线,可以直观得到这个积分要满足的两个条件:
1、一个点的密度越高,射线通过它之后变得越弱,密度和透光度呈反比
2、一个点的密度越高,这点在这个射线下的颜色反应在像素上的权重越大

而实际渲染过程,我们只能把射线平均分成N个小区间,每个区间随机采样一个点,对采样得到的点的颜色进行某种加权求和:

神经辐射场的两项优化点
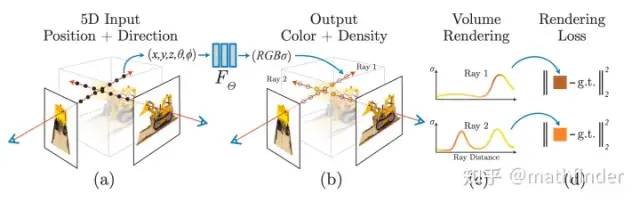
Positional encoding
类似Transformer的做法,把坐标和视角用更高维度的表示作为网络输入,来解决渲染图像比较糊的问题:
Hierachical volume sampling

Architecture
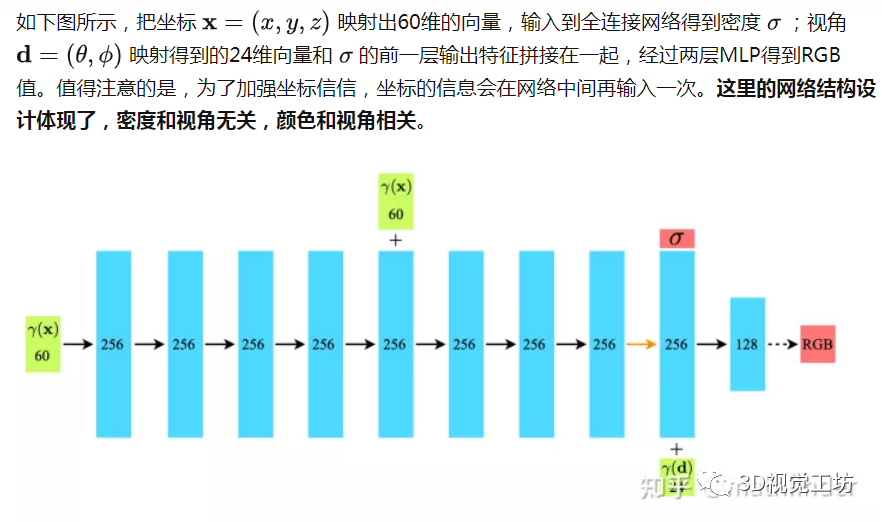
私货
无论从方法的开创性,还是发表后两年多的影响力来看。在笔者心目中,ECCV 2020的Best Paper没给NeRF,不得不说是一个遗憾。
审核编辑 :李倩
-
3D
+关注
关注
9文章
2875浏览量
107474 -
神经网络
+关注
关注
42文章
4771浏览量
100704 -
RGB
+关注
关注
4文章
798浏览量
58458
原文标题:都2023年了,我不允许你还不懂NeRF
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
大华股份鸿鹄智能物联主机 赋能万千场景数视升级

电压放大器在合成射流高效掺混机理研究中的应用

视觉新纪元:解码LED显示屏的视角、可视角、最佳视角的最终奥秘

NVIDIA Instant NeRF将多组静态图像变为3D数字场景
LiDAR4D:基于时空新颖的LiDAR视角合成框架

什么是SLAM?基于3D高斯辐射场的SLAM优势分析
电压放大器在合成射流高效掺混机理研究中的应用
谷歌模型合成工具怎么用
基于NeRF/Gaussian的全新SLAM算法






 工商网监
工商网监
评论