 谷歌提出PaLI:一种多模态大模型,刷新多个任务SOTA!
谷歌提出PaLI:一种多模态大模型,刷新多个任务SOTA!
PaLI-17B 在多个 benchmark 上都达到了 SOTA。
语言和视觉任务的建模中,更大的神经网络模型能获得更好的结果,几乎已经是共识。在语言方面,T5、GPT-3、Megatron-Turing、GLAM、Chinchilla 和 PaLM 等模型显示出了在大文本数据上训练大型 transformer 的明显优势。视觉方面,CNN、视觉 transformer 和其他模型都从大模型中取得了很好的结果。language-and-vision 建模也是类似的情况,如 SimVLM、Florence、CoCa、GIT、BEiT 和 Flamingo。
在这篇论文中,来自谷歌的研究者通过一个名为 PaLI (Pathways Language and Image)的模型来延续这一方向的研究。

PaLI: A Jointly-Scaled Multilingual Language-Image Model
论文:https://arxiv.org/abs/2209.06794
PaLI 使用单独 “Image-and-text to text” 接口执行很多图像、语言以及 "图像 + 语言" 任务。PaLI 的关键结构之一是重复使用大型单模态 backbone 进行语言和视觉建模,以迁移现有能力并降低训练成本。
在语言方面,作者复用有 13B 参数的 mT5-XXL。mT5-XXL 已经把语言理解和泛化能力一体打包。作者通过实验证明这些功能可以维护并扩展到多模态情况。
在视觉方面,除复用 2B 参数 ViT-G 模型外,作者还训练了拥有 4B 参数的模型 ViT-e("enormous")。ViT-e 在图像任务上表现出很好的性能(ImageNet 上准确率达到 90.9%;ObjectNet 准确率达到 84.9%)。
作者发现了联合 scaling 视觉和语言组件的好处,视觉提供了更好的投入回报(每个参数 / FLOP 带来的准确度提升)。实验结果表明,最大的 PaLI 模型——PaLI-17B 在两种任务模式下表现相对平衡,ViT-e 模型约占总参数的 25%。而先前的大规模视觉和语言建模工作,情况并非总是如此(Wang 等人,2022a;Alayrac 等人,2022),因为视觉和语言 backbone 之间的先验量表并不匹配。
作者通过将多个图像和 (或) 语言任务转换为广义的类似 VQA 的任务,实现它们之间的知识共享。使用 “image+query to answer” 来构建所有任务,其中检索和回答都表示为文本标记。这使得 PaLI 能够使用跨任务的迁移学习,并在广泛的视觉和语言问题中增强 language-and-image 理解能力:图像描述、视觉问答、场景文本理解等(如图 1 所示)。

为了训练 PaLI-17B,作者构建了全新的大容量 image-and-language 数据集 WebLI,包含 10B 的图文对数据,WebLI 数据集包含 100 多种语言的文本。通过训练模型用多种语言执行多模态任务,这大大增加了任务的多样性,并测试了模型在跨任务和跨语言之间有效扩展的能力。作者也提供了数据卡来介绍有关 WebLI 及其构造的信息。
PaLI-17B 在多个 benchmark 上都达到了 SOTA,表现优于某些强大的模型(见表 1)。
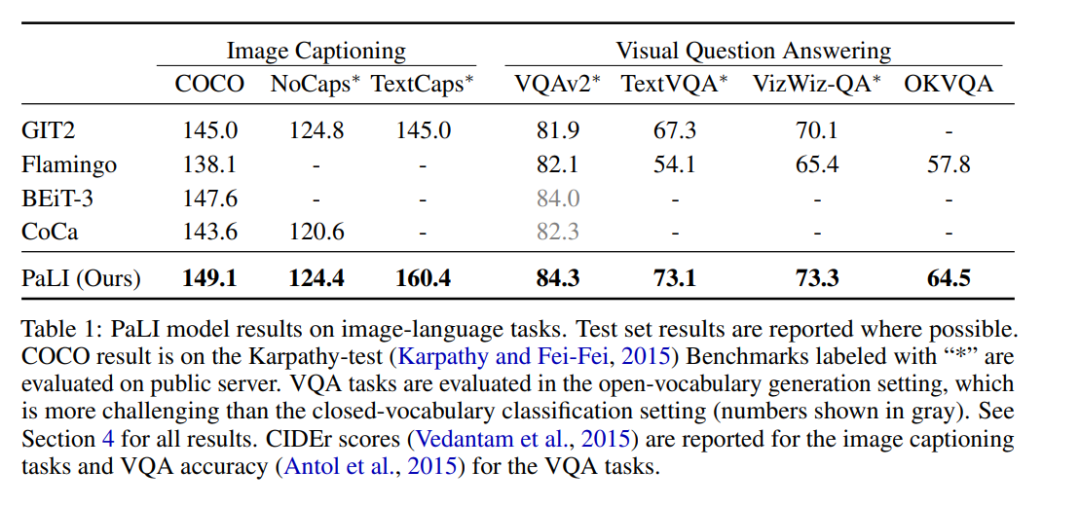
具体来说,PaLI 在 COCO 数据集 benchmark 上的表现优于多数新旧模型,在 Karpaty 分割上的得分为 149.1。PaLI 在 VQAv2 上使用类似 Flamingo 的开放词汇文本生成的设置达到 84.3% 的最新 SOTA,该结果甚至优于在固定词汇分类环境中评估的模型,例如 CoCa、SimVLM、BEiT-3。作者的工作为未来的多模态模型提供了 scaling 路线图。Model scaling 对于多语言环境中的语言图像理解特别重要。作者的结果支持这样一个结论:与其他替代方案相比,scaling 每个模式的组件会产生更好的性能。
这篇文章在知乎上引发了一些讨论。有人感叹说,「刚要汇报 beit3,随便一刷知乎,又被超了」(引自知乎用户 @走遍山水路)。还有人认为,论震撼程度,PaLI 比不上 BEiT-3,「毕竟 model scaling 这事大家已经比较麻了」。但「谷歌把这个大家伙做出来了,还达到了一系列新 SOTA,并且零样本都已经做得很突出,还是非常令人敬佩」(引自知乎用户 @霜清老人)。

来自知乎用户 @霜清老人的评价。链接:https://www.zhihu.com/question/553801955?utm_source
以下是论文细节。
模型架构
作者使用 PaLI 的目的是执行单模态(语言、视觉)和多模态(语言和视觉)任务。这些任务中的许多任务最好由不同的模型处理。如图像分类及许多 VQA 需要从固定集合中预测元素,而 language-only 任务和图像描述需要开放词汇文本生成。作者通过使用所有任务所需的通用接口来解决该问题:模型接受图像和文本字符串作为输入,并生成文本作为输出。在预训练和微调时使用相同的接口。由于所有任务都使用相同的模型执行,即没有任务特定的参数,因此使用基于文本的提示指导模型需要执行的任务。
图 2 展示了模型架构的高阶示意图。其核心是一个文本 encoder-decoder transformer。为了将视觉作为输入,向文本编码器提供视觉“tokens”:视觉 transformer 将图像作为输入,并输出相关特征。通过交叉注意力将视觉 token 传递到 encoder-decoder 模型之前,不会将池化应用于视觉 transformer 的输出。
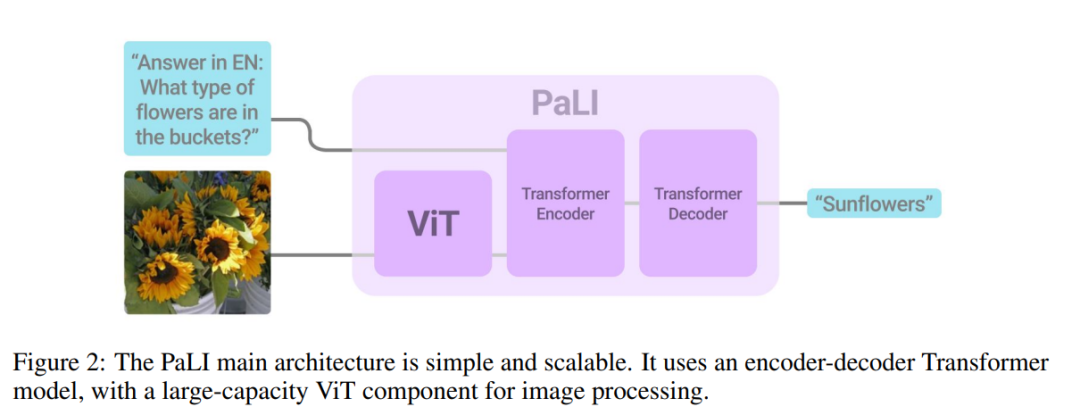
作者重复使用之前训练过的单模态模型。对于文本 encoder-decoder,重复使用预训练的 mT5(Xue 等,2021)模型,而对于图像编码,则重复使用大型 vanilla ViT 模型(Dosovitskiy 等,2021; Zhai 等,20222a)。
实验结果
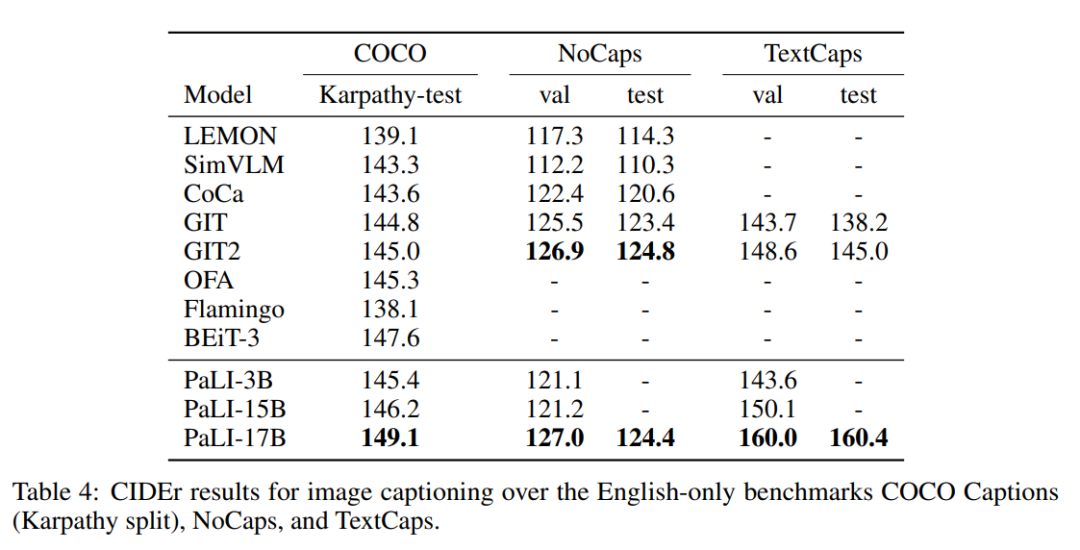
作者在三个纯英文图像的 benchmark 上评估了 PaLI 模型的变体,结果如表 4 所示。
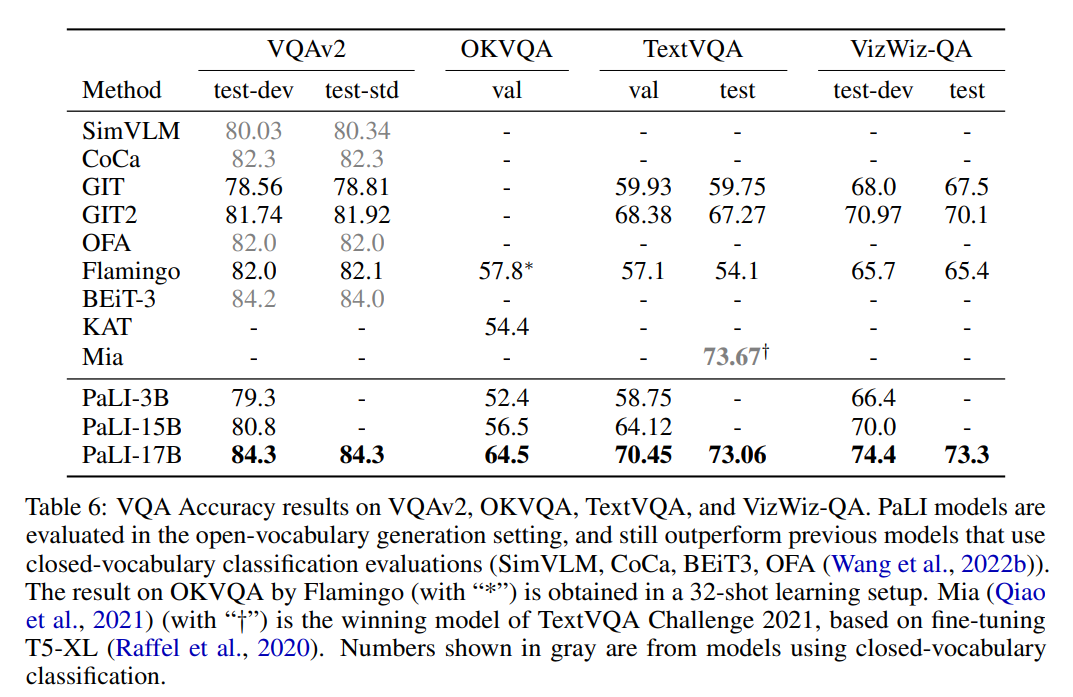
作者对四个仅英文视觉问答(VQA)benchmark 进行评估,结果见表 6。
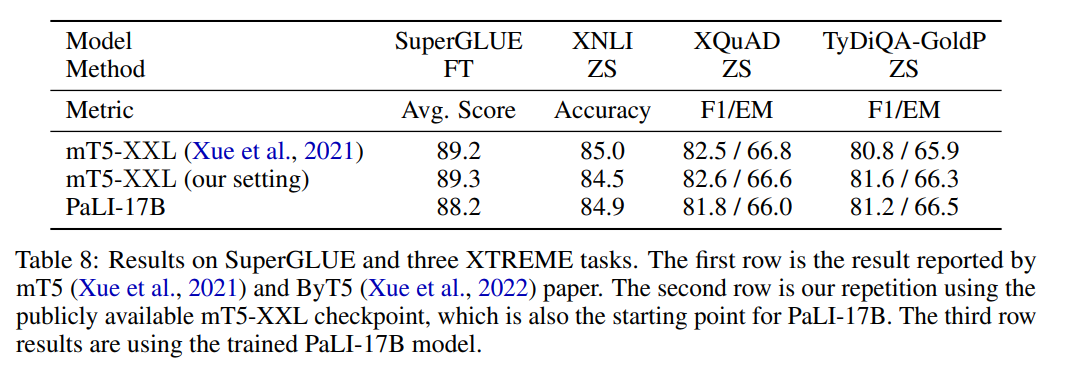
作者将 mT5-XXL 和 PaLI-17B 在一系列语言理解任务 benchmark 进行比较,对比结果如表 8 所示。
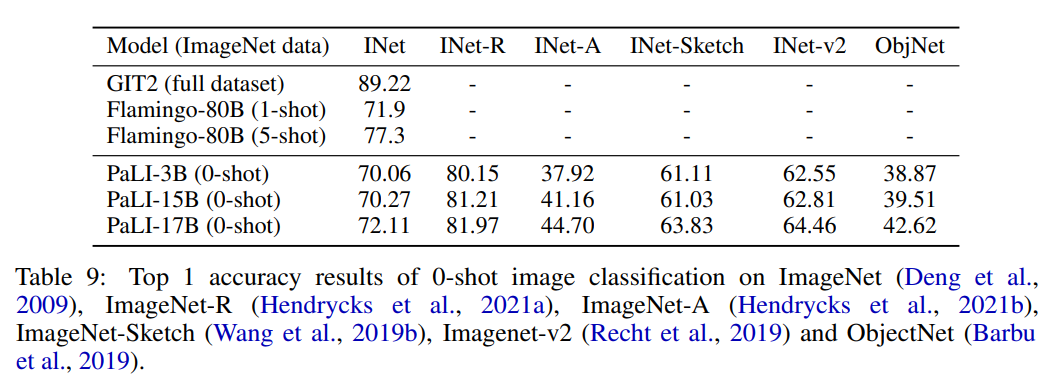
作者使用 224x224 分辨率(在高分辨率预微调之前)对 PaLI 模型在 Imagenet 和 Imagenet OOD 数据集上进行评估,评估结果如表 9 所示。
审核编辑 :李倩
-
神经网络
+关注
关注
42文章
4772浏览量
100857 -
图像
+关注
关注
2文章
1086浏览量
40492 -
模型
+关注
关注
1文章
3254浏览量
48895 -
大模型
+关注
关注
2文章
2476浏览量
2819
原文标题:ICLR 2023 | 谷歌提出PaLI:一种多模态大模型,刷新多个任务SOTA!
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
商汤日日新多模态大模型权威评测第一

一文理解多模态大语言模型——上

Waymo利用谷歌Gemini大模型,研发端到端自动驾驶系统
利用OpenVINO部署Qwen2多模态模型
智谱AI发布全新多模态开源模型GLM-4-9B
谷歌发布多模态AI新品,加剧AI巨头竞争
李未可科技正式推出WAKE-AI多模态AI大模型

谷歌推出多模态VLOGGER AI
蚂蚁集团推出20亿参数多模态遥感基础模型SkySense
谷歌模型软件有哪些功能
蚂蚁推出20亿参数多模态遥感模型SkySense
韩国Kakao宣布开发多模态大语言模型“蜜蜂”
机器人基于开源的多模态语言视觉大模型






 工商网监
工商网监
评论