 编译器优化教程:寄存器分配 2
编译器优化教程:寄存器分配 2
线性扫描
接下来介绍一种不同思路的算法:线性扫描。算法描述如下[4]:
LinearScanRegisterAllocation:
active := {}
for i in live interval in order of increasing start point
ExpireOldIntervals(i)
if length(avtive) == R
SpillAtInterval(i)
else
register[i] := a regsiter removed from pool of free registers
add i to active, sorted by increasing end point
ExpireOldInterval(i)
for interval j in active, in order of increaing end point
if endpoint[j] >= startpoint[i]
return
remove j from active
add register[j] to pool of free registers
SpillAtInterval(i)
spill := last interval in active
if endpoint[spill] > endpoint[i]
register[i] := register[spill]
location[spill] := new stack location
remove spill from active
add i to active, sorted by increasing end point
else
location[i] := new stack location
live interval其实就是变量的生命期,用活跃变量分析可以算出来。不过需要标识第一次出现和最后一次出现的时间点。
举个例子:
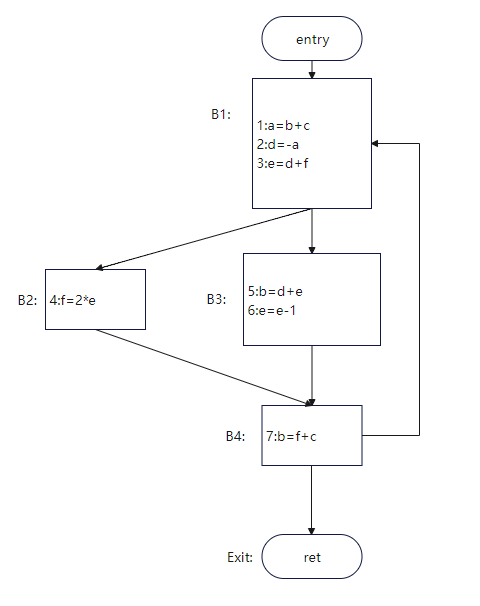
图10
| 变量名 | live interval |
|---|---|
| a | 1,2 |
| d | 2,3,4,5 |
| e | 3,4,5,6 |
llvm中实现
在上文中介绍的算法都是作用在最普通的四元式上,但LLVM-IR是SSA形式,有PHI节点,但PHI节点没有机器指令表示,所以在寄存器分配前需要把PHI节点干掉,消除PHI节点的算法限于篇幅不展开,如感兴趣的话请后台留言。
llvm作为工业级编译器,有多种分配算法,可以通过llc的命令行选项-regalloc=pbqp|greedy|basic|fast来手动控制分配算法。
不同优化等级默认使用算法也不同:O2和O3默认使用greedy,其他默认使用fast。
fast算法的策略很简单,扫描代码并为出现的变量分配寄存器,寄存器不够用就溢出到内存。用途主要是 调试 。
basic算法以linearscan为基础并对life interval设置了溢出权重而且用优先队列来存储life interval。
greedy算法也使用优先队列,但特点是先为生命期长的变量分配寄存器,而短生命期的变量可以放在间隙中,详情可以参考[5]。
pbqp算法全称是Partitioned Boolean Quadratic Programming,限于篇幅,感兴趣的读者请查阅[6]。
至于具体实现,自顶向下依次是:
TargetPassConfig::addMachinePasses含有寄存器分配和其他优化addOptimizedRegAlloc中是与寄存器分配密切相关的pass,比如上文提到的消除PHI节点addRegAssignAndRewriteOptimized是实际的寄存器分配算法- 寄存器分配相关文件在lib/CodeGen下的RegAllocBase.cpp、RegAllocGreedy.cpp、RegAllocFast.cpp、RegAllocBasic.cpp和RegAllocPBQP.cpp等。
- RegAllocBase类定义了一系列接口,重点是selectOrSplit和enqueue/dequeue方法,数据结构的重点是priority queue。selectOrSplit方法可以类比上文中提到的SpillAtInterval。priority queue类比active list。简要代码如下:
void RegAllocBase::allocatePhysRegs() {
// 1. virtual reg其实就是变量
while (LiveInterval *VirtReg = dequeue()) {
// 2.selectOrSplit 会返回一个可用的物理寄存器然后返回新的live intervals列表
using VirtRegVec = SmallVector4>;
VirtRegVec SplitVRegs;
MCRegister AvailablePhysReg = selectOrSplit(*VirtReg, SplitVRegs);
// 3.分配失败检查
if (AvailablePhysReg == ~0u) {
...
}
// 4.正式分配
if (AvailablePhysReg)
Matrix->assign(*VirtReg, AvailablePhysReg);
for (Register Reg : SplitVRegs) {
// 5.入队分割后的liver interval
LiveInterval *SplitVirtReg = &LIS->getInterval(Reg);
enqueue(SplitVirtReg);
}
}
}
至于这四种算法的性能对比,我们主要考虑三个指标:运行时间、编译时间和溢出次数。
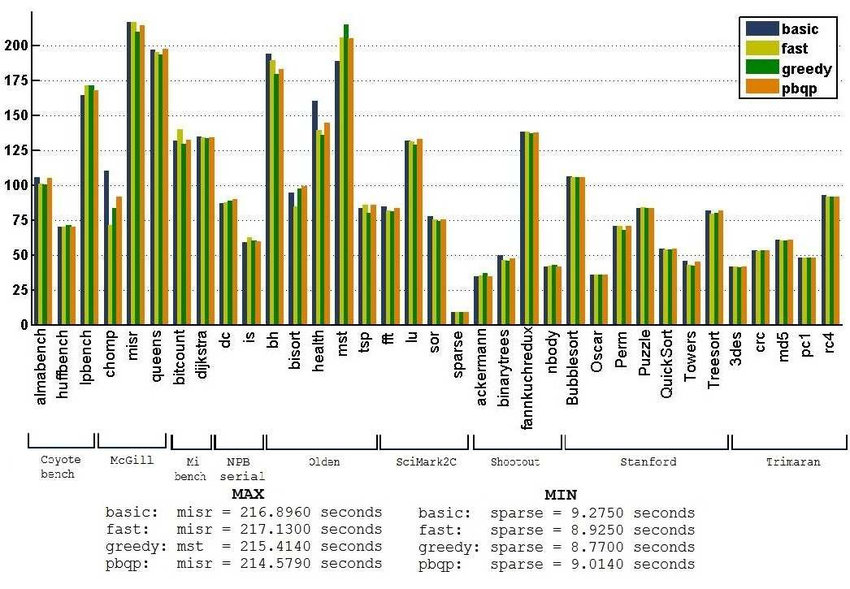
图11 各算法的运行时间,图源[6]
横坐标是测试集,纵坐标是以秒为单位的运行时间
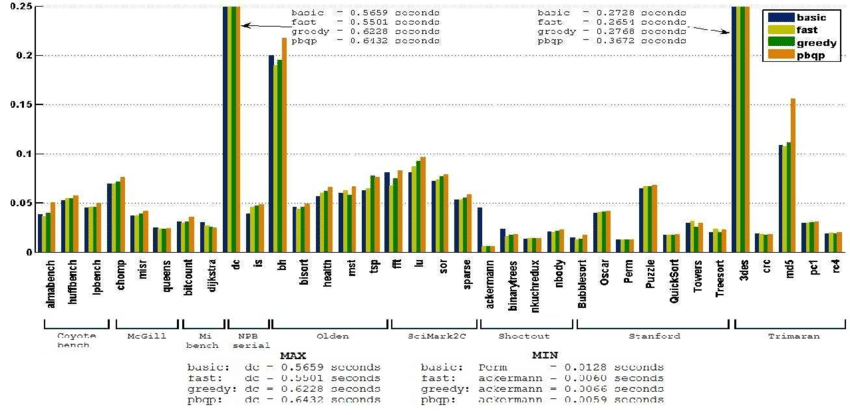
图12 各算法的编译时间,图源[6]
横坐标是测试集,纵坐标是编译时间
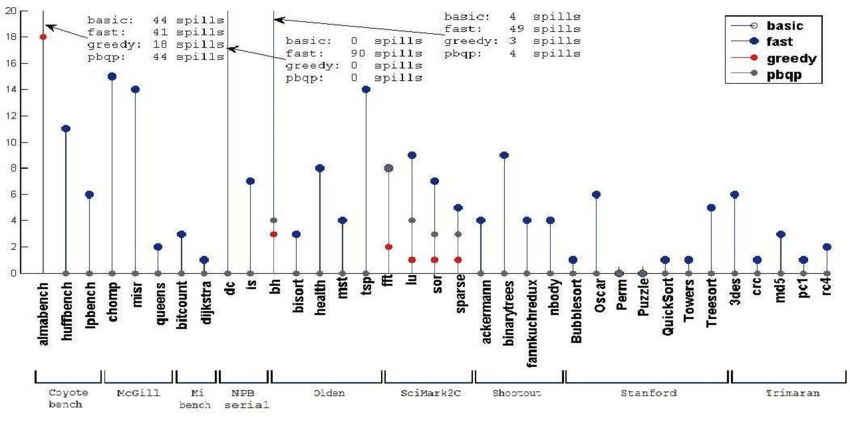
图13 各算法的溢出次数,图源[6]
从这三幅图可以看出greedy算法在大多数测试集上都优于其他算法,因此greedy作为默认分配器是可行的。
小结
我们通过一个例子介绍了活跃变量分析和图着色算法。借助活跃变量分析,我们知道了变量的生命期,有了变量生命期建立干涉图,对干涉图进行着色。如果着色失败,可以选择某个变量溢出到内存中。之后在RIG的基础上介绍了寄存器合并这一变换。
然后我们简单介绍了不同思路的寄存器分配算法:linearscan。最后介绍了llvm12中算法的实现并对比了llvm中四种算法的性能差异。
参考
- http://www.cs.cmu.edu/afs/cs.cmu.edu/academic/class/15745-s18/www/lectures/L5-Intro-to-Dataflow-pre-class.pdf
- http://web.cecs.pdx.edu/~mperkows/temp/register-allocation.pdf
- http://www.cs.cmu.edu/afs/cs.cmu.edu/academic/class/15745-s18/www/lectures/L12-Register-Allocation.pdf http://www.cs.cmu.edu/afs/cs.cmu.edu/academic/class/15745-s18/www/lectures/L13-Register-Coalescing.pdf
- http://web.cs.ucla.edu/~palsberg/course/cs132/linearscan.pdf
- http://blog.llvm.org/2011/09/greedy-register-allocation-in-llvm-30.html
- T. C. d. S. Xavier, G. S. Oliveira, E. D. d. Lima and A. F. d. Silva, "A Detailed Analysis of the LLVM's Register Allocators," 2012 31st International Conference of the Chilean Computer Science Society, 2012, pp. 190-198, doi: 10.1109/SCCC.2012.29.
-
寄存器
+关注
关注
31文章
5280浏览量
119738 -
代码
+关注
关注
30文章
4708浏览量
68167 -
编译器
+关注
关注
1文章
1613浏览量
48991
发布评论请先 登录
相关推荐
编译器优化导致USART波特率配置错误,请问这是为什么?如何解决?
编译器优化那些事儿(5):寄存器分配
编译器优化的静态调度介绍

C编译器及其优化
静态变量、自动变量与寄存器变量的存储

基于C++编译器的节点融合优化方法
编译器的优化选项





 工商网监
工商网监
评论