 YOLOv6 v3.0实时目标检测重磅升级
YOLOv6 v3.0实时目标检测重磅升级
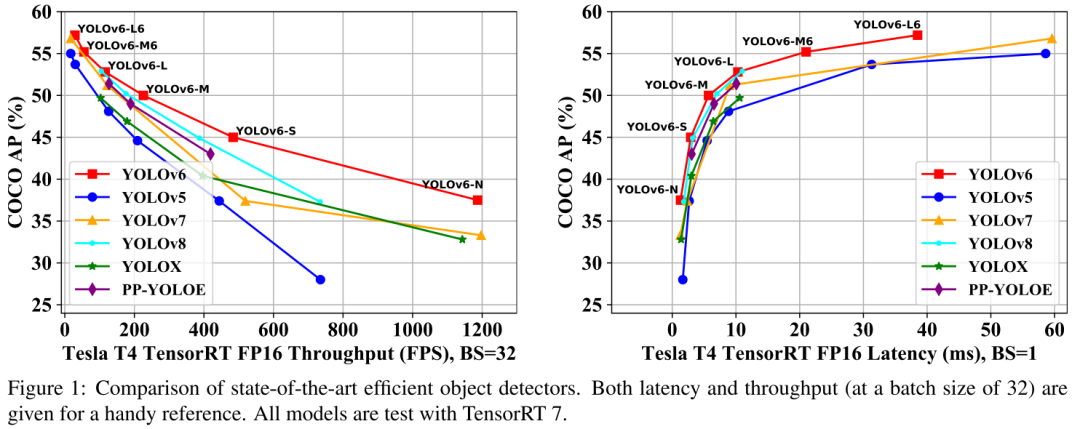
YOLOv6 v3.0的主要贡献简述如下:
对检测器的Neck部件进行了翻新:引入BiC(Bi-directional Concatenation)提供更精确的定位信息;将SPPF简化为SimCSPSPPF,牺牲较少的速度提升更多的性能。
提出一种AAT(Anchor-aided training)策略,在不影响推理效率的情况下同时受益于Anchor-basedAnchor-free设计理念。
对YOLOv6的Backbone与Neck进行加深,在更高分辨率输入下达成新的SOTA性能。
提出一种新的自蒸馏策略提升YOLOv6小模型的性能,训练阶段采用更大的DFL作为增强版辅助回归分支。
本文方案
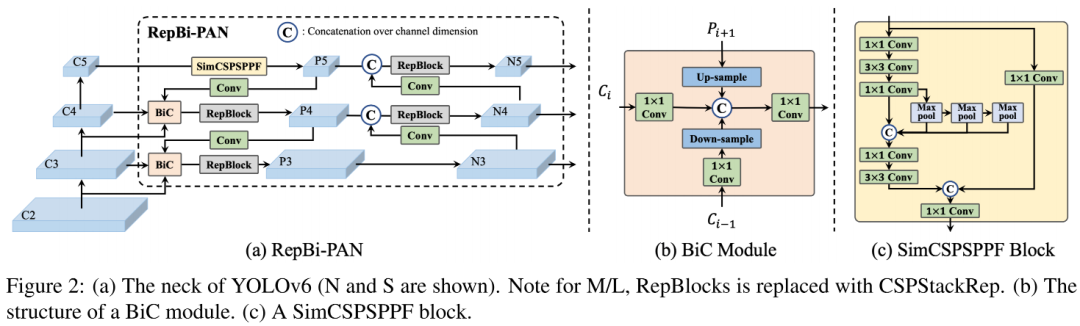
Network Design
在网络架构方面,本文主要从Neck与SPP两个维度进行改进:
在Neck方面,本文设计了一种增强的PAN模块,它次用BiC模块对三个近邻层特征进行集成(可参考上图b),额外引入了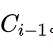 。这种处理截止可以保留更精确的定位信息,对于小目标定位非常重要。
。这种处理截止可以保留更精确的定位信息,对于小目标定位非常重要。
在SPP方面,本文对YOLOv5 v6.1版本的SPPF进行了简化,得到了所谓的SimCSPSPPF(可参考上图c)。
Anchor-Aided Training
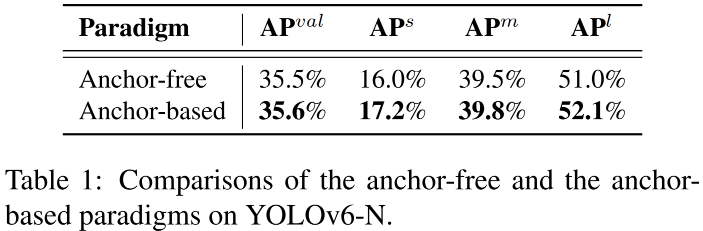
YOLOv6是一种追求更高推理速度的Anchor-free检测器。然而,作者发现:在同等配置(YOLOv6-N)下,相比Anchor-free方案,Anchor-based方案可以带来额外的性能增益,见上表。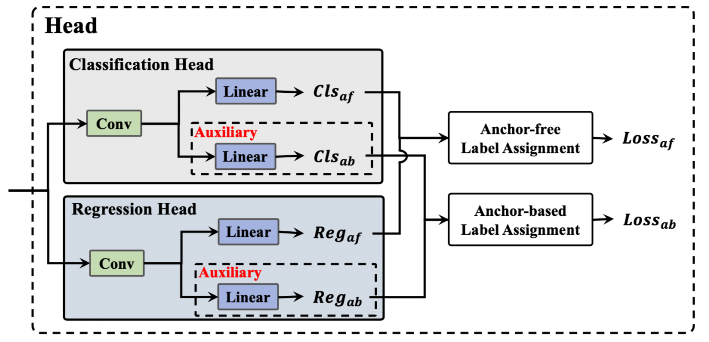
有鉴于此,作者提出了AAT策略(即Anchor辅助训练,见上图),它引入了一个Anchor-based辅助分支以组合两种方案的优势。通过这种训练策略,源自的辅助分支的引导信息可以被有效的嵌入到Anchor-free分支。在推理阶段,辅助分支将被移除掉。也就是说,AAT策略属于"赠品",加量不加价的那种。
Self-distillation
在YOLOv6早期版本中,自蒸馏仅在大模型中得到应用,采用的普通KL散度蒸馏。知识蒸馏损失与整体损失定义如下:超参数用于对两个损失进行平衡。在训练的早期,源自老师模型的软标签更易于学习;而在训练的后期,学生模型从硬标签中受益更多。
因此,作者设计了一种cosine weight decay调整机制:由于DFL会对回归分支引入额外的参数,极大程度影响小模型的推理速度。因此,作者针对小模型设计了一种DLD(Decoupled Localization Distillation)以提升性能且不影响推理速度。具体来说,在小模型中插入一个增强版回归分支作为辅助。在自蒸馏阶段,小模型受普通回归分支与增强回归分支加持,老师模型近使用辅助分支。
需要注意:普通分支仅采用硬标签进行训练,而辅助分支则用硬标签与源自老师模型的软标签进行训练。完成蒸馏后,仅普通分支保留,辅助分支被移除。这种训练策略又是一种加量不加价的"赠品"。
Experiments
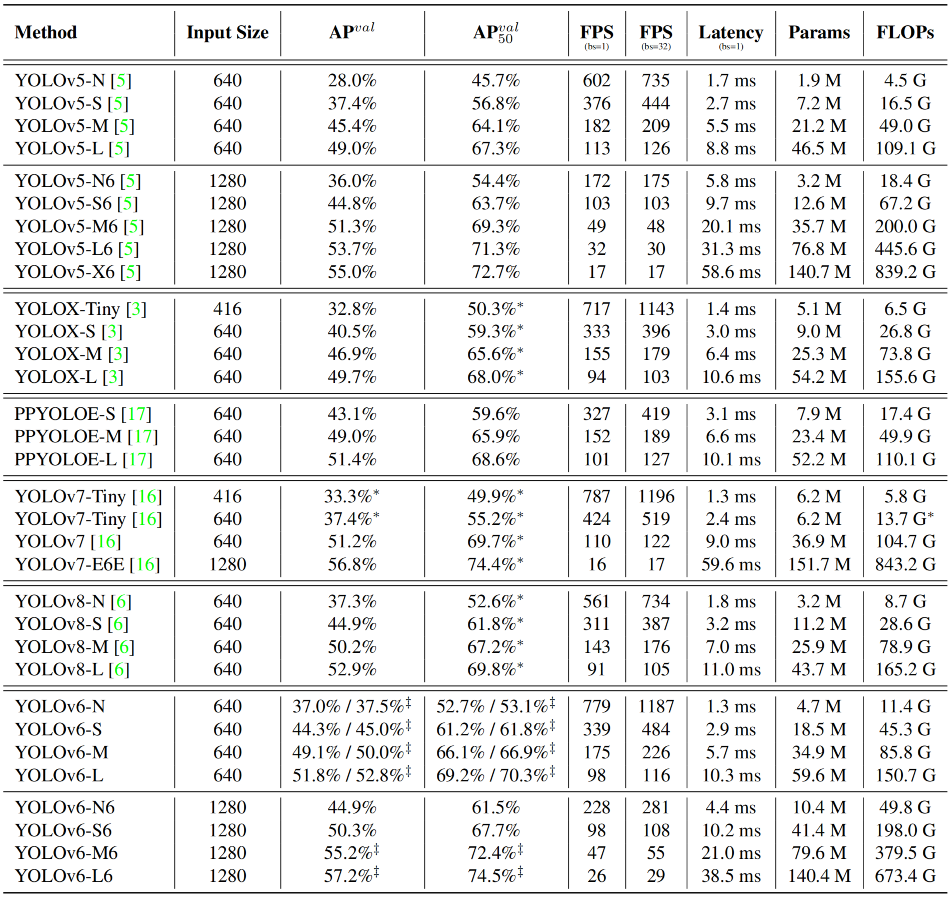
上表给出了不同方案的性能对比,可以看到:
相比YOLOv5-N、YOLOv7-Tiny,YOLOv6-N指标分别提升9.5%、4.2%,同时具有最佳速度。
相比YOLOX-S、PPYOLOE-S、YOLOv6-S指标分别提升3.5%、0.9%且速度更快;
YOLOv6-M比YOLOv5-M指标高4.6%、速度相当,比YOLOX-M、PPYOLOE-M指标高3.1%、1.0%且速度更快;
除了比YOLOv5-L更高更快外,YOLOv6-L比YOLOX-L、PPYOLOE-L分别高3.1%、1.4%且速度相当。
相比YOLOv8,YOLOv6在所有尺寸下取得了相当的精度,同时具有更优的吞吐性能。
除了上述常规模型尺寸外,作者还进一步提升了输入分辨率并添加了C6特征,与YOLOv5等方案对比:
相比YOLOv5系列(即YOLOv5-N6/S6/M6/L6/X6),YOLOv6具有更高的AP、相当的速度;
相比YOLOv7-E6E,YOLOv6-L6指标高出0.4%,推理速度快36%。
审核编辑:刘清
-
检测器
+关注
关注
1文章
875浏览量
47888
原文标题:超越YOLOv8!YOLOv6 v3.0实时目标检测重磅升级!
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
电脑店U盘启动盘制作工具V3.0(智能装机版)
YOLOv6中的用Channel-wise Distillation进行的量化感知训练
茂名信息网 v3.0
FilterPro v3.0设计工具的最新版本
NodeMCU V3.0 Arduino开发之点灯

YOLOv6在LabVIEW中的推理部署(含源码)

YOLOv6模型文件的输入与输出结构

YOLOv8+OpenCV实现DM码定位检测与解析






 工商网监
工商网监
评论