 2023年你应该知道的所有机器学习算法
2023年你应该知道的所有机器学习算法
【CSDN 编者按】经过数十年的演进,人工智能走出了从推理,到知识,再到学习的发展路径。尤其近十年由深度学习开启神经网络的黄金新时代,机器学习成为解决人工智能面临诸多难题的重要途径。然而,这一涉及概率论、统计学、逼近论、凸分析、算法复杂度等理论的交叉学科让很多开发者犯难,尤其是纷繁复杂的各类算法。本文作者结合自身多年的工作经验和日常学习,汇编了一份2023年度的机器学习算法大全。希望在新的一年,这些算法可以成为开发者的“书签”,从而解决各类数据科学处理中面临的难题。
在过去的几年里,我根据自己的工作经验,与其他数据科学家的交流,包括在网上阅读到的内容,汇编了自认为最重要的机器学习算法。
今年,我想在去年发表文章的基础上提供各类别中更多的模型。希望提供一个工具和技术的宝库,你可以将其作为书签,这样就可以解决各种数据科学的问题了。
说到这里,让我们深入了解以下六种最重要的机器学习算法类型。
解释型算法
模式挖掘算法
集成算法
聚类算法
时间序列算法
相似度算法
解释型算法
机器学习面临的一大问题是理解各种模型如何达到最终预测,我们经常知道是“什么”,但很难解释“为什么”。
解释型算法帮助我们识别那些对我们感兴趣的结果有重要影响的变量。这些算法使我们能够理解模型中变量之间的关系,而不仅仅是用模型来对结果进行预测。
有几种算法可以用来更好地理解某个模型的自变量和因变量之间的关系。
算法
线性/逻辑回归:对因变量和一个或多个自变量之间的线性关系进行建模的一种统计方法——可用于了解基于t-检验和系数的变量之间的关系。
决策树:一种机器学习算法,为决策及其可能的后果创建一个树状模型,有助于通过观察分支进行分割的规则进而理解变量之间的关系。
主成分分析(PCA):一种降维技术,将数据投射到一个较低的维度空间,同时保留尽可能多的差异。PCA可用于简化数据或确定重要特征。
局部可解释模型——不可知论解释(LIME):一种解释机器学习模型预测的算法,使用线性回归或决策树等技术构建一个更简单的模型,通过预测周围情况局部近似地解释模型。
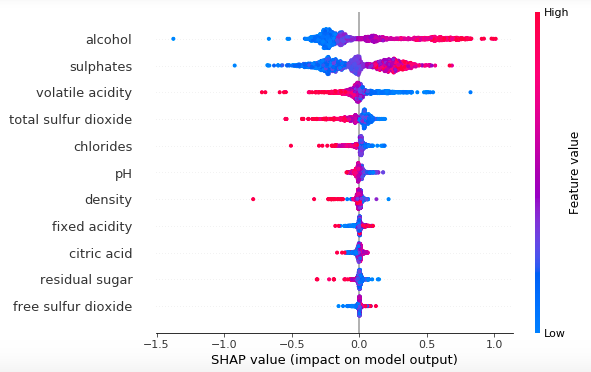
沙普利加法解释(SHAPLEY):一种解释机器学习模型的预测算法,通过基于“边际贡献”的方法计算每个特征对预测的贡献。在某些情况下,它比SHAP更准确。
沙普利近似法(SHAP):一种通过预估每个特征在预测中的重要性来解释机器学习模型预测的方法。SHAP使用一种叫做“合作博弈”的方法来近似Shapley值(Shapley value),通常比SHAPLEY更快。
模式挖掘算法
模式挖掘算法是一种数据挖掘技术,用于识别数据集中的模式和关系。这些算法可用于实现各种目的,如识别零售业中的客户购买模式,了解网站/应用程序的常见用户行为序列,或在科学研究中寻找不同变量之间的关系。
模式挖掘算法通常通过分析大型数据集和寻找重复模式或变量之间的关联展开工作。一旦这些模式被识别出来,它们就可以用来预测未来的趋势或结果,或者理解数据中的潜在关系。
算法
Apriori算法:一种用于在事务数据库中查找频繁项集的算法——高效且广泛用于关联规则挖掘任务。
递归神经网络 (RNN):一种神经网络算法,旨在处理序列数据,能够获取数据中的时间依赖性。
长短期记忆网络 (LSTM):一种循环神经网络,旨在可以更长时间地记住信息。LSTM能够获取数据中的长期依赖关系,通常用于语言翻译和语言生成等任务中。
使用等价类的序列模式发现(SPADE):一种通过将某种意义上等价的项目组合在一起,从而查找序列数据中经常出现的模式的方法。这种方法能够高效处理大型数据集,但可能不适用于稀疏数据。
前缀投影的模式挖掘(PrefixSpan):一种通过构建前缀树并修剪不常见项目的方式查找序列数据中常见模式的算法。PrefixScan能够高效处理大型数据集,但可能不适用于稀疏数据。

集成算法
作为机器学习技术,集成算法结合多模型,从而做出比任何单独模型更准确的预测。集成算法能够胜过传统机器学习算法的原因有几个:
多样性。通过结合多模型预测,集成算法可以捕捉到数据中更广泛的模式。
稳健性。集成算法通常对数据中的噪音和异常值不那么敏感,这可以使预测更加稳定和可靠。
减少过度拟合。通过对多模型的平均化预测,集成算法可以减少单个模型对训练数据的过度拟合,从而提升对新数据的集成。
提高准确性。集成算法已被证明在各种情况下都保持相较于传统机器学习算法的优势。
算法
随机森林:一种机器学习算法,它构建了一个决策树的集合,并根据树的多数“投票”进行预测。
极限梯度提升算法(XGBoost):一种梯度提升算法,使用决策树作为其基础模型,被称为最强的机器学习预测算法之一。
LightGBM:另一种梯度提升算法,旨在比其他提升算法更快、更高效。
CatBoost:一种梯度提升算法,专门被设计处理分类变量。
聚类算法
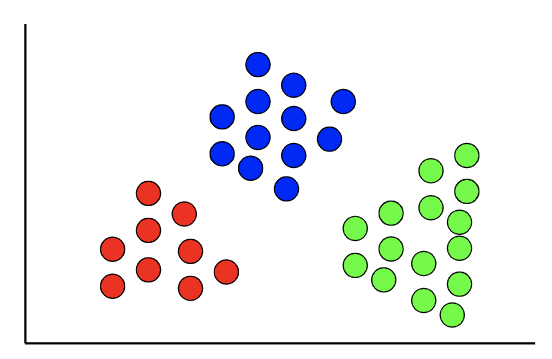
聚类算法是一种无监督的学习作业,用于将数据分为“群组”。与目标变量已知的监督式学习相比,聚类算法中没有目标变量。
这项技术对于寻找数据中的自然模式和趋势非常有用,并且经常在数据分析阶段使用,以获得对数据的进一步理解。此外,聚类算法可以用来根据各种变量将数据集划分为不同的部分,一个常见应用是在细分客户或用户的时候。
算法
K-Modes聚类:一种专门为分类数据设计的聚类算法,能够很好地处理高维分类数据,而且实现起来相对简单。
DBSCAN密度聚类:一种基于密度的聚类算法,能够识别任意形状的聚类。它对噪声处理相对稳健,能够识别数据中的异常值。
谱系聚类法:一种聚类算法,使用相似性矩阵的特征向量来将数据点归入聚类,能够处理非线性可分离的数据,并且相对高效。
时间序列算法
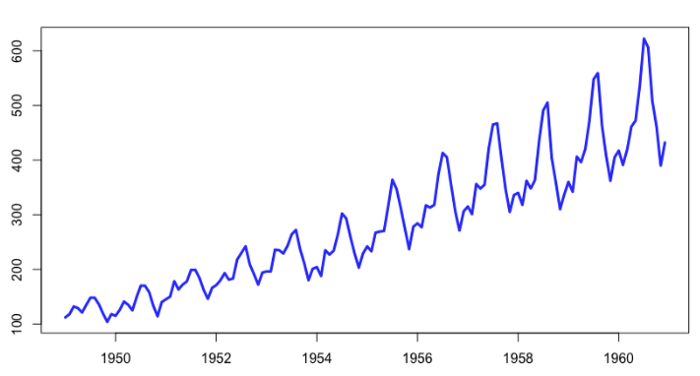
时间序列算法是用于分析与时间有关的数据的技术。这些算法考虑到一个系列中的数据点之间的时间依赖性,这在对未来价值进行预测时尤其重要。
时间序列算法被用于各种商业应用中,如预测产品需求、销售,或分析客户在一段时间内的行为,它们还可以用来检测数据中的异常情况或趋势变化。
算法
Prophet时间序列模型:一个由Facebook开发的时间序列预测算法,设计直观、易于使用。它的一些主要优势包括处理缺失数据和预测趋势变化,对异常值具有鲁棒性,可以快速拟合。
自回归综合移动平均法(ARIMA):一种用于预测时间序列数据的统计方法,对数据和其滞后值之间的相关性进行建模。ARIMA可以处理广泛的时间序列数据,但比其他的一些方法更难实现。
指数平滑法:一种预测时间序列数据的方法,使用过去数据的加权平均来进行预测。指数平滑法的实现相对简单,可以用于广泛的数据,但可能不如更复杂的方法表现出色。
相似度算法
相似度算法被用来衡量一对记录、节点、数据点或文本之间的相似性。这些算法可以基于两个数据点之间的距离(如欧氏距离)或文本的相似性(如Levenshtein算法)。
这些算法有广泛应用,尤其在推荐方面特别有用。它们可以用来识别类似的项目或向用户推荐相关内容。
算法
欧氏距离:对欧氏空间中两点之间直线距离的测量。欧氏距离计算简单,在机器学习中被广泛使用,但在数据分布不均匀的情况下可能不是最佳选择。
余弦相似度:基于两个向量之间的角度来衡量它们的相似度。
Levenshtein算法:一种测量两个字符串之间距离的算法,基于将一个字符串转化为另一个字符串所需的最小单字符编辑数(插入、删除或替换)。Levenshtein算法通常用于拼写检查和字符串匹配的任务中。
Jaro-Winkler算法:一种测量两个字符串之间相似度的算法,基于匹配字符的数量和转置的数量。它与Levenshtein算法类似,经常被用于记录链接和实体解析的任务中。
奇异值分解(SVD):一种矩阵分解方法,将一个矩阵分解为三个矩阵的乘积,在最先进的推荐系统中,奇异值分解是重要的组成部分。
审核编辑 :李倩
-
算法
+关注
关注
23文章
4609浏览量
92859 -
机器学习
+关注
关注
66文章
8414浏览量
132602
原文标题:值得收藏!2023 年,你应该知道的所有机器学习算法~
文章出处:【微信号:AI科技大本营,微信公众号:AI科技大本营】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
NPU与机器学习算法的关系
【每天学点AI】KNN算法:简单有效的机器学习分类器
机器学习算法原理详解

名单公布!【书籍评测活动NO.35】如何用「时间序列与机器学习」解锁未来?
2023年机器人行业展望:CEO们揭秘行业“关键词”
【年度精选】2023年度top5榜单——电路设计论坛资料
【年度精选】2023年度top5榜单——电机控制资料
【年度精选】2023年度top5榜单——电机控制经验
【年度精选】2023年度top5榜单——鸿蒙开发经验
OpenHarmony社区运营报告(2023年12月)
华秋2023年度大事记~~
新年惊喜!盖楼有奖~一起来见证华秋2023年度高光时刻吧
目前主流的深度学习算法模型和应用案例






 工商网监
工商网监
评论