 感存算一体化智能成像系统中使用的两种不同类型的架构总结
感存算一体化智能成像系统中使用的两种不同类型的架构总结
编者按
人工智能视觉芯片是一种可以同时获取图像、处理图像的半导体芯片,这种芯片可以将获取的图像数据进行并行处理,最终输出处理结果。人工智能视觉芯片的目标是在传感器内部实现复杂图像处理,包括图像识别和分类。
中国工程院罗毅院士研究团队在中国工程院院刊《Engineering》2022年第7期发表《感存算一体化智能视觉芯片的展望》一文。文章总结了感存算一体化智能成像系统中使用的两种不同类型的架构(即在传感单元内或附近进行计算),然后讨论了未来的发展方向(包括与算法匹配的架构、3D集成技术、新型材料和先进器件)。文章指出,感存算一体化智能成像系统的最终目标是实现更高效的AI硬件,该硬件系统具有低功耗、高速、高分辨率、高识别准确率和大规模集成的特点,同时具有可编程性。另外,为了将感存算一体化智能成像系统商业化,需要在物理学、材料学、计算机科学、电子学和生物学等领域进行更深入的研究。
近年来,人工智能(AI)的应用变得越来越广泛,其发展也随着生物学、数学的进步而日渐成熟。然而,AI的发展也对系统的计算能力和能量效率提出了更高的要求,因此迫切需要新的硬件架构来满足AI的需求。AI的目标是使机器获得类似人的智能,当前的硬件体系在执行计算时仍然基于传统的冯·诺依曼架构。首先通过传感器得到物理信号,然后将信号传输至计算中心结合算法进行感知,这种信息处理的模式与人脑完全不同。以视觉为例,人类的视觉系统(包含视觉皮层)是高度紧凑和高效的,其中,视网膜上的数亿光敏神经元与预处理、控制神经元相连接,能够实现感光和信号预处理(增强图像、提取特征等)。一旦光敏神经元检测到冗余信号,视觉系统会将其弱化,仅将关键信息传输至大脑皮层进行深度处理。
目前常用的人工成像硬件系统的功能并不像人类视觉系统那样,如电荷耦合器件(CCD)阵列和互补金属氧化物半导体(CMOS)阵列,这类传感器通过总线将图像数据串行传输至存储器和处理单元进行交互运算(即冯·诺依曼架构)。
尽管当前的成像硬件系统在传感单元密度、响应时间和波长范围方面优于人类视觉系统,但在执行复杂AI任务时,它们的功耗和延时变成了不可忽略的问题。在大多数图像处理任务中,超过90%的图像数据是冗余且无用的,随着像素数量的快速增长,数据冗余量显著增加,给模数转换(ADC)和数据传输带来了严重负担,并限制了实时图像处理技术的发展。因此,AI的发展会迅速消耗硬件资源,并产生对新型硬件系统的强烈需求。
受人类视觉系统的启发,部分研究尝试将一些处理任务转移至图像传感器内,从而实现原位计算,并且减少数据传输。
在20世纪90年代,加州理工学院的Mead和Mahowald提出了人工智能视觉芯片,他们构想了一种可以同时获取图像、处理图像的半导体芯片,这种芯片可以将获取的图像数据进行并行处理,最终输出处理结果。早期的视觉芯片旨在模仿视网膜的预处理功能,但只能实现简单图像处理,如图像滤波和边缘检测,而后逐渐提出在传感器内部实现复杂图像处理,包括图像识别和分类,这也成为了人工智能视觉芯片的目标。此外,在2006年提出视觉芯片需要具备可编程功能,从而通过软件控制灵活地处理各种应用场景。在2021年,Liao等总结了生物视网膜的原理,并讨论了基于新兴器件的智能视觉传感器发展。Wan等概述了用于神经拟态传感计算的电子、光学以及混合光电计算技术。
目前有两种主要的智能视觉芯片架构。
(1)架构一:传感单元内部计算。这种架构的光电探测器被置于模拟存储器和计算单元中,以组成处理元件(PE),然后利用PE电路来实现原位传感功能,并处理传感器获得的模拟信号。这种架构如图1(a)所示,其优势在于具有高度并行处理速度。然而,模拟存储器和计算单元占用了较大的面积,使得PE电路比传统传感单元大得多,这导致像素填充因子较低,并限制了成像分辨率。
(2)架构二:传感单元附近计算。由于较低的填充因子,视觉芯片难以采用原位传感和计算相结合的架构。相反,将像素阵列和处理电路物理分离,但仍然保持片上并行连接,这使得二者可以根据系统要求进行独立设计和优化。这种架构如图1(b)所示,首先通过总线从像素阵列中获取传感数据(模拟),并转换成数字信号,然后在附近的处理单元内进行计算。这种架构具有广域图像处理、高分辨率和大规模并行处理的优势,并且可以在数字处理电路中结合现有的AI算法(包括人工神经网络等)。
目前,视觉芯片的神经元规模只有102~103个,远少于视网膜和皮层(1010个),因此,感存算一体化智能视觉芯片需要更大规模的集成。其中一种方法是通过片上光学卷积神经网络(CNN)和光学脉冲神经网络(SNN)实现大规模高并行运算,以显著提高计算效率。另一种方法是采用三维(3D)集成技术,使用硅通孔(TSV)垂直集成空间中的功能层(传感器、存储器、计算、通信等)。在2017年,索尼提出了一种3D集成视觉芯片,像素分辨率为1296×976,处理速度达到1000 fps。部分研究人员认为,3D集成芯片已经成为一种必然趋势,但在架构设计和引线互连等方面仍然需要更深入的研究。研究证明,虽然短互连可以降低功耗和延迟,但由于层间距离较短可能会导致散热难题。因此,解决3D集成的可靠性问题和提高性能至关重要。
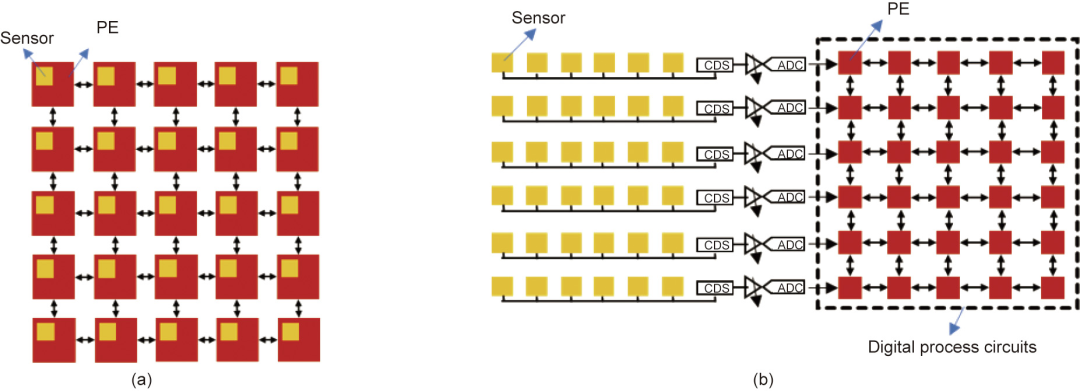
图1. 视觉芯片架构。(a)传感单元内部计算;(b)传感单元附近计算。CDS:双精度采样。
近些年来,在AI发展需求的驱动下,涉及新型材料和先进器件的技术不断涌现,也为感存算一体化智能成像系统提供了新方案。
(1)具有探测和记忆功能的材料(DAM)。
光电突触器件被视为构建感存算一体化智能成像系统的一种方式,并有望促进视网膜仿生技术的发展。研究发现,一些金属氧化物(氧化物半导体、二元氧化物等)、氧化物异质结和二维(2D)材料在实现光电突触器件方面有巨大的潜力。光电突触具有临时记忆能力和突触可塑性,如短时程可塑性(STP)和长时程可塑性(LTP),可以通过光信号进行调制以完成实时图像处理。这类器件有许多优点,它提供了一种非接触式的写入方法(光写入),权重写入过程具有高速并行的特点。
然而,这类器件仍然面临一些挑战,包括脉冲写入下电导非线性变化和由于较大的照明强度而导致的高能耗。在写入过程中,光刺激用于实现增强突触活性,而电刺激用于抑制突触活性。具体来说,器件的电导在光脉冲作用下逐渐增加,而在负电脉冲作用下则逐渐减小,这类似于生物突触中的增强和抑制,器件的电导变化对应突触的活性变化。此外,研究指出负光响应或者光刺激用于抑制突触活性可以实现全光调制的复杂神经功能。目前大多数研究侧重于在器件中模拟突触行为[如兴奋性突触后电流(EPSC)、成对脉冲易化(PPF)、STP、LTP等],因为模仿人眼视网膜神经元仍然是一大挑战。
为了模仿视网膜,光电突触器件的大规模集成有待进一步研究。在DAM材料中,基于二元氧化物(如ZnO、HfO2、AlOx等)的器件具有结构简单和CMOS兼容性的优点,这是大规模集成的关键因素。相反,与集成电路(IC)基础结构不兼容的材料可以通过采用异质集成、异质外延、键合和三维异质集成等技术来实现。
(2)结合传感器与存储器的器件结构。
近些年来,随着半导体器件的发展,部分研究提出采用先进器件代替PE电路,如新型存储器件[如阻变存储器(RRAM)和其他忆阻器等。例如,两类器件通过串联的方式来实现固有特性的结合,使传感器阵列具有可编程性,并且将光学图像转变为易于识别的信息。
这种结构将单个像素的占地面积显著降低到4F2的理论极限(F是工艺的特征尺寸),可以实现高填充因子的集成方式。然而,与CCD不同的是,该阵列不显示破坏性读出,也不显示任何积分行为。在该阵列中,乘加运算(MAC)可以通过模拟域中的基尔霍夫定律直接实现。然而,大规模集成引起的串扰是一个亟待解决的问题。有研究报道了一种由单光子雪崩二极管(SPAD)和忆阻器组成的系统,用于处理脉冲事件形式的信息,从而完成实时成像识别。
随着新型材料与器件的发展,感存算一体化智能成像系统也同样需要新的架构和算法来适配其应用。
例如,深度学习算法(如DNN、CNN、SNN等)是目前较为成熟的图像处理技术,而如何将其应用于感存算一体化智能成像系统是一个亟待解决的难题。SNN通过对时间并行编码的神经信号进行编码和处理,为提高计算效率提供了一种很有前景的解决方案。
本文总结了感存算一体化智能成像系统中使用的两种不同类型的架构(即在传感单元内或附近进行计算),然后讨论了未来的发展方向(包括与算法匹配的架构、3D集成技术、新型材料和先进器件)。总之,感存算一体化智能成像系统的最终目标是实现更高效的AI硬件,该硬件系统具有低功耗、高速、高分辨率、高识别准确率和大规模集成的特点,同时具有可编程性。为了将感存算一体化智能成像系统商业化,需要在物理学、材料学、计算机科学、电子学和生物学等领域进行更深入的研究。
审核编辑:刘清
-
传感器
+关注
关注
2557文章
51930浏览量
760025 -
CMOS
+关注
关注
58文章
5851浏览量
237107 -
图像识别
+关注
关注
9文章
525浏览量
38664 -
人工智能
+关注
关注
1801文章
48259浏览量
243353 -
视觉芯片
+关注
关注
1文章
45浏览量
11601
原文标题:感存算一体化智能视觉芯片的展望
文章出处:【微信号:信息与电子工程前沿FITEE,微信公众号:信息与电子工程前沿FITEE】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
到底什么是“通感一体化”?
【云智易申请】一体化机柜监控设计
什么是机电一体化
机电一体化系统
基于RISC-V开放架构的存算一体化芯片解决方案


曙光存储一体化存力方案发布
什么是通感算一体化?通感算一体化的应用场景

存算一体化与边缘计算:重新定义智能计算的未来






 工商网监
工商网监
评论