 在构建时间方面Rust和C++究竟谁能更胜一筹呢?
在构建时间方面Rust和C++究竟谁能更胜一筹呢?
谷歌 Chromium 规模的项目在新硬件上的构建时间长达一小时,而在老硬件上的构建时间更是达到了六个小时。虽然也有海量的调整方案能加速构建速度,还有不少削减构建内容但极易出错的捷径供人选择,再加上数千美元的云计算能力,Chromium 的构建时间仍是接近十分钟。这点我完全无法接受,人们每天都是怎么干活的啊?
有人说 Rust 也是一样,构建时间同样令人头疼。但事实就是如此,还是这仅仅是一种反 Rust 的宣传手段?在构建时间方面 Rust 和 C++ 究竟谁能更胜一筹呢?
构建速度和运行时性能对我来说非常重要。构建测试的周期越短,我编程就越高效、越快乐。我会不遗余力地让我的软件速度更快,让我的客户也越快乐。因此,我决定亲自试试 Rust 的构建速度到底怎么样,计划如下:
找一个 C++ 项目
把项目中的一部分单独拿出来
逐行将 C++ 代码重写为 Rust
优化 C++ 和 Rust 项目的构建
对比两个项目的构建测试时间
我的猜想如下(有理有据的猜测,但不是结论):
Rust 的代码行数比 C++ 少。C++ 中多数函数和方法都需要声明两次:一次在 header 里,一次在实现文件里。但 Rust 不需要,因此代码行数会更少。
C++ 的完整构建时间比 Rust 长(Rust 更胜一筹)。在每个.cpp 文件里,都需要重新编译一次 C++ 的 #include 功能和模板,虽然都是并行运行,但并行不等于完美。
Rust 的增量构建时间比 C++ 长(C++ 更胜一筹)。Rust 一个 crate(独立可编译单元)一编译,但 C++ 是按文件编译。因此代码每次变动,Rust 要读取的比 C++ 多。·
对此,大家怎么看呢
42% 的人认为 C++ 会赢,35% 同意“看情况”,另外 17% 的则觉得 Rust 会让我们大吃一惊。
那么结果到底如何呢?下面让我们进入正题。
编写 C++ 和 Rust 的测试对象 找个项目
考虑到我未来一个月都要花在重写代码上,什么样的代码最合适?我认为得满足以下几点:
很少或不用第三方依赖(标准库可以使用);
能在 Linux 和 macOS 上运行(我不怎么管 Windows 上的构建时间);
大量测试套组(不然我没法确定 Rust 代码的正确性);
FFI(外部函数接口)、指针、标准或自定义容器、功能类和函数、I/O、并发、泛型、宏、SIMD(单指令多数据流)、继承等等,多少都有使用。
其实答案也很简单,直接找我前几年一直在做的项目就行。我用的是一个 JavaScript 词法分析器,quick-lint-js 项目。
quick-lint-js 的吉祥物 Dusty
截取 C++ 代码
quick-lint-js 项目中 C++ 部分的代码行数超过 10 万,要把这些全改成 Rust 得花上我半年时间,不如只关注 JavaScript 词法分析部分,其中涉及项目中的:
诊断系统
翻译系统(用于诊断)
各种内存分配器和容器(如 bump 分配器、适用于 SIMD 的字符串)
各种功能类函数(如 UTF-8 解码器、SIMD 内在包装器)
测试的辅助代码(如自定义断言宏)
C 的 API
可惜这部分代码里不涉及并发或 I/O,我测试不了 Rust 里 async/await 的编译时间开销,但这只是 quick-lint-js 项目里的一小部分,所以我还不用太担心。
我首先把所有的 C++ 代码都复制到新项目里,然后删掉已知与词法分析无关的部分,比如分析器和 LSP 服务器。我甚至一不小心删多了代码,最后不得不重新把这些代码添了回去。在我不断截代码的过程中,C++ 的测试一直保持了通过状态。
在彻底将 quick-lint-js 项目中涉及词法分析的部分全截出来之后,项目中 C++ 的代码大约有 1.7 万行。

重写代码
至于要怎么重写这上千行的 C++ 代码,我选择按部就班:
找一个适合转换的模块;
复制黏贴代码、测试、搜索替换并修改部分语法、继续运行 cargo(Rust 的构建系统和包管理器)测试直到构建测测试都通过;
如果这个模块依赖另一个模块,那就找到被依赖的模块,继续进行第二步,然后再回到现在这个模块;
如果还有模块没转换,再回到第一步。
主要影响 Rust 和 C++ 构建时间的问题在于,C++ 的诊断系统是通过大量代码生成、宏、constexpr(常量表达式)实现的,而我在重写 Rust 版时,则用了代码生成、proc 宏、普通宏以及一点点 const 实现。传闻 proc 宏速度很慢,也有说是因为代码质量太差导致的 proc 宏速度慢。希望我写的 proc 宏还可以(祈祷~)。
我写完才发现,原来 Rust 项目比 C++ 项目还要大,Rust 代码 17.1k 行,而 C++ 只有 16.6k 行。
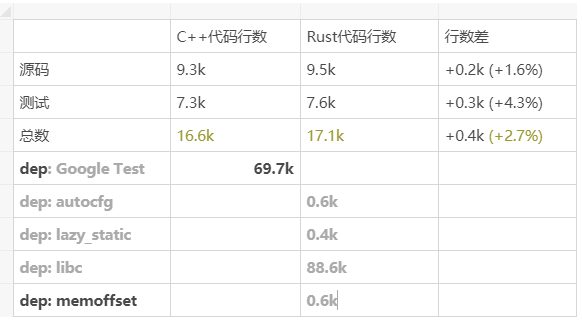
优化 Rust 构建
构建时间很重要,因为我在截取 C++ 代码之前就已经做好了 C++ 项目构建时间的优化,所以我现在只需要对 Rust 项目的构建时间做同样的优化即可。以下是我觉得可能会优化 Rust 构建时间的条目:
更快的链接器
Cranelift 后端
编译器和链接器标志
工作区与测试布局区分
最小化依赖功能
cargo-nextest
使用 PGO 自定义工具链
更快的链接器
我第一步要做的是分析构建,我用的是 -Zself-profile rustc 标志。在这个标志所生成的两个文件里,其中一个文件中的 run_linker 阶段颇为突出:

第一轮 -Zself-profile 结果
之前我通过向 Mold 链接器的转换成功优化了 C++ 的构建时间,那这套对 Rust 能否行得通?
Linux:链接器性能几乎一致。(数据越小越好)

可惜,Linux 上虽然确实有提升,但效果不明显。那 macOS 上的优化又表现如何?在 macOS 上默认链接器的替代品有两种,lld 和 zld,效果如下:
macOS:链接器性能几乎不变。(数据越小越好)

可以看出,macOS 上替换默认链接器的效果同样不明显,我怀疑这可能是因为 Linux 和 macOS 上的默认链接器对我的小项目而言已经做到了最好,这些优化后的链接器(Mold、lld、zld)在大型项目上效果非常好。
Cranelift 后端
让我们再回到 -Zself-profile 的另一篇报告上,LLVM_module_codegen_emit_obj 和 LLVM_passes 阶段颇为突出:
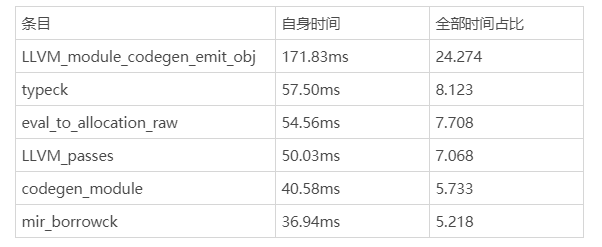
-Zself-profile 的第二轮结果
传闻可以把 rustc 的后端从 LLVM 换成 Cranelift,于是我又用 rustc Cranelift 后端重新构建了一遍,-Zself-profile 结果看起来不错:
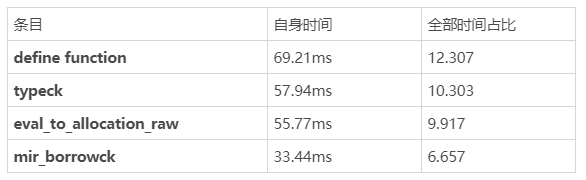
使用 Cranelife 的 -Zself-profile 第二轮结果
可惜,在实际的构建中 Cranelife 比 LLVM 慢。
Rust 后端:默认 LLVM 比 Cranelift 强。(测试于 Linux,数据越小越好)
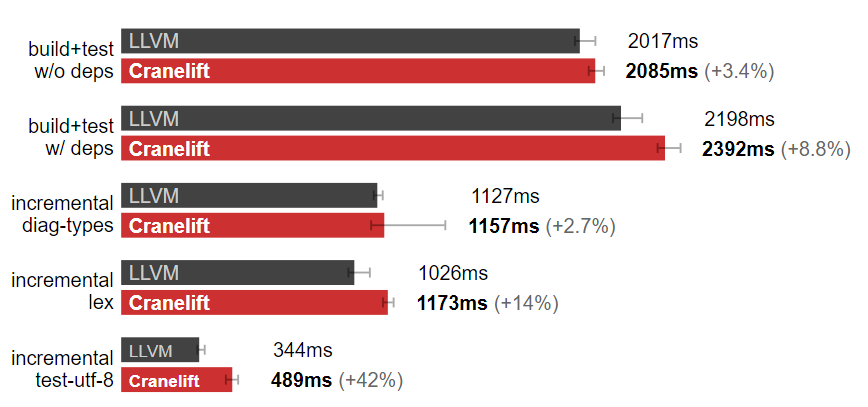
2023 年 1 月 7 日更新:rustc 的 Cranelift 后端维护者 bjorn3 帮我看了下为什么 Cranelift 在我的项目上效果不佳:可能是 rustup 的开销导致的。如果绕过这部分 Cranelife 效果可能会有提升,上图中的结果没有采用任何措施。
编译器和链接器标志
编译器里有一堆可以加快(或减缓)构建速度的选项,让我们一一试过:
-Zshare-generics=y (rustc) (Nightly only)
-Clink-args=-Wl,-s (rustc)
debug = false (Cargo)
debug-assertions = false (Cargo)
incremental = true 且 incremental = false (Cargo)
overflow-checks = false (Cargo)
panic = 'abort' (Cargo)
lib.doctest = false (Cargo)
lib.test = false (Cargo)
rustc 标志:快速构建优于调试构建。(测试于 Linux,数据越小越好)
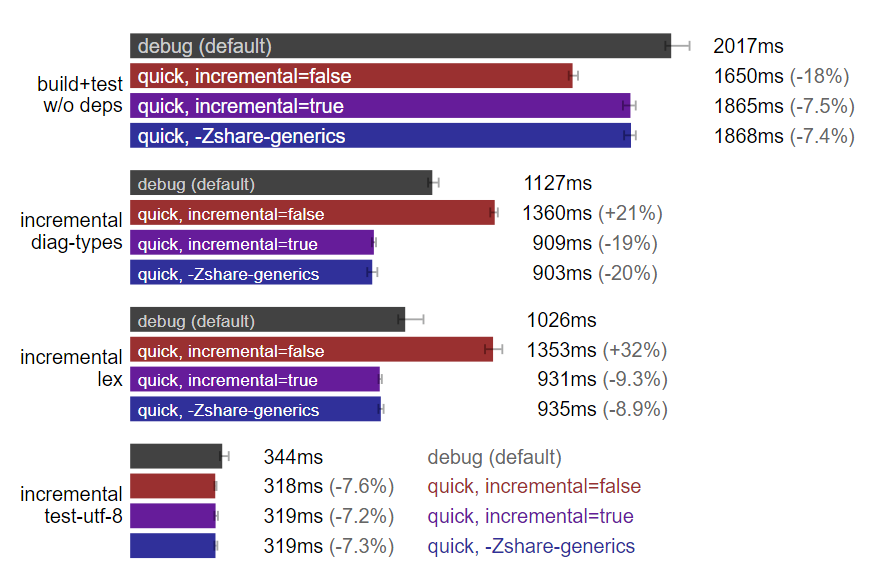
注:图中的“quick, -Zshare-generics=y”与“quick, incremental=true”且启用“-Zshare-generics=y”标志相等同,其余柱状图没有标识“-Zshare-generics=y”是因为没有启用该标志,后者意味着需要 nightly rust 编译器。
上图中使用的多数选项都有文档可查,但我还没找到有人写过加 -s 的链接。子命令 -s 将包括 Rust 标准库静态链接在内的所有调试信息全部剥离,让链接器做更少的工作,从而减少链接时间。
工作区与测试布局
在文件的物理位置问题上,Rust 和 Cargo 都提供了部分灵活性。对我的项目而言,以下是三种合理布局:

理论上来说,如果我们把代码拆成多个 crate,cargo 就可以并行化 rustc 的调用。鉴于我的 Linux 机器上有一个 32 线程的 CPU,macOS 机器上有一个 10 线程的 CPU,并行化应该可以降低构建时间。
对一个 crate 而言,Rust 项目中的测试有很多可运行的地方:

由于依赖周期的存在,我没办法做“源码文件内的测试”这个布局的基准,但其他布局组合里我都做了基准:
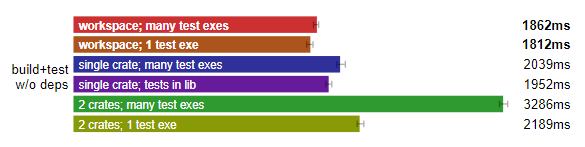
Rust 完整构建:工作区布局最快。(测试于 Linux,数据越小越好)
Rust 增量构建:最佳布局不明。(测试于 Linux,数据越小越好)
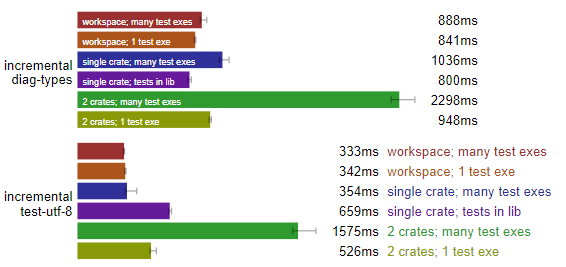
工作区设置中,无论是分成多个可执行测试(many test exes),还是合并成一个可执行测试,似乎都能斩获头筹。所以后续我们还是按照“工作区 + 多个可执行文件”的配置吧。
最小化依赖功能
多个 crate 的拆分支持可选功能,而部分可选功能都是默认启用的,具体功能可以通过 cargo tree 命令查看:
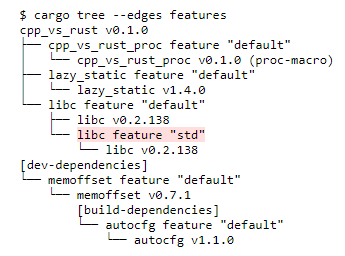
让我们把 crate 之一,libc 中的 std 功能关掉,测试后再看看构建时间有没有变化。
Cargo.toml
[dependencies]
+libc = { version = "0.2.138", default-features = false }
-libc = { version = "0.2.138" }
关掉libc功能后没有任何变化。(测试于Linux,数据越小越好)

构建时间没有任何变化,有可能 std 功能实际没什么大影响。不管怎么说,让我们进入下一个环节。
cargo-nextest
作为一款据说“比 cargo 测试快 60%”的工具,cargo-nextest 对于我这个代码中 44% 都是测试的项目来说非常合适。让我们来对比下构建和测试时间:
Linux:cargo-nextest 减慢了测试速度。(数据越小越好)
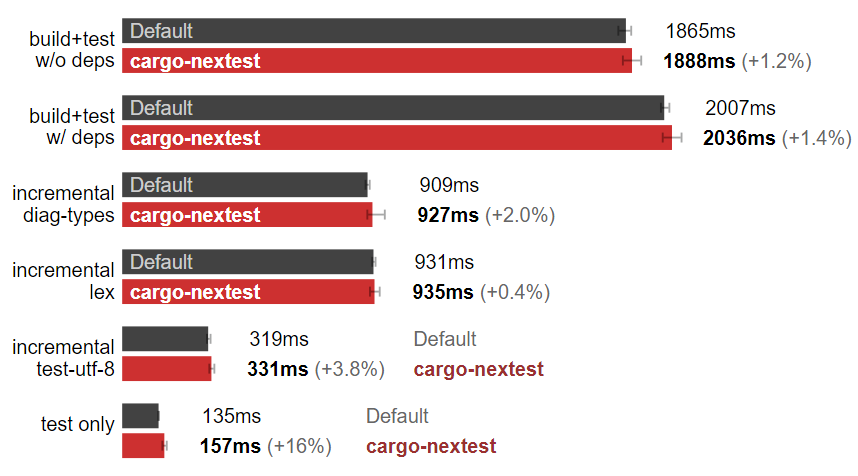
在我的 Linux 机器上,cargo-nextest 帮了倒忙,虽然输出不错,不过……
示例 cargo-nextest 测试输出:
PASS [ 0.002s] cpp_vs_rust::test_locale no_match PASS [ 0.002s] cpp_vs_rust::test_offset_of fields_have_different_offsets PASS [ 0.002s] cpp_vs_rust::test_offset_of matches_memoffset_for_primitive_fields PASS [ 0.002s] cpp_vs_rust::test_padded_string as_slice_excludes_padding_bytes PASS [ 0.002s] cpp_vs_rust::test_offset_of matches_memoffset_for_reference_fields PASS [ 0.004s] cpp_vs_rust::test_linked_vector push_seven
那 macOS 上怎么说?
macOS:cargo-nextest 加快了构建测试。(数据越小越好)
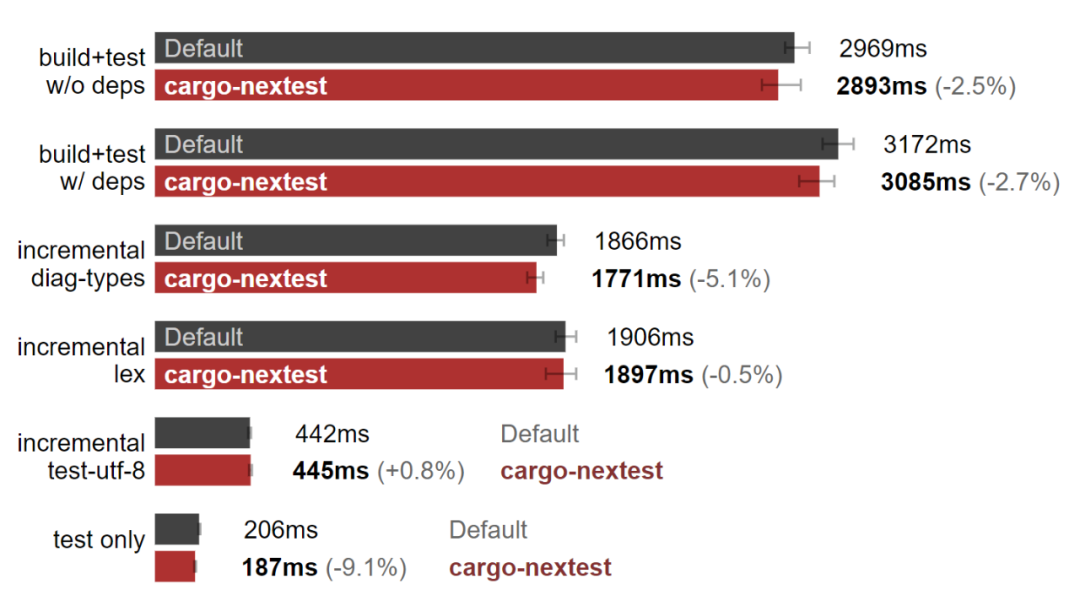
在我的 MacBook pro 上,cargo-nextest 确实提高了构建测试的速度。但为什么 Linux 上没有呢?难道是和硬件有关?
在下面测试中,我会在 macOS 上使用 cargo-nextest,但 Linux 上的测试不用。
使用 PGO 自定义工具链
我发现 C++ 编译器的构建如果用配置文件引导的优化(PGO,也称作 FDO),会有明显的性能提升。因此,让我们试试用 PGO 优化 Rust 工具链的同时,也用 LLVM BOLT 加上 -Ctarget-cpu=native 进一步优化 rustc。
Rust 工具链:自定义工具链是最快的。(测试于 Linux,数据越小越好)
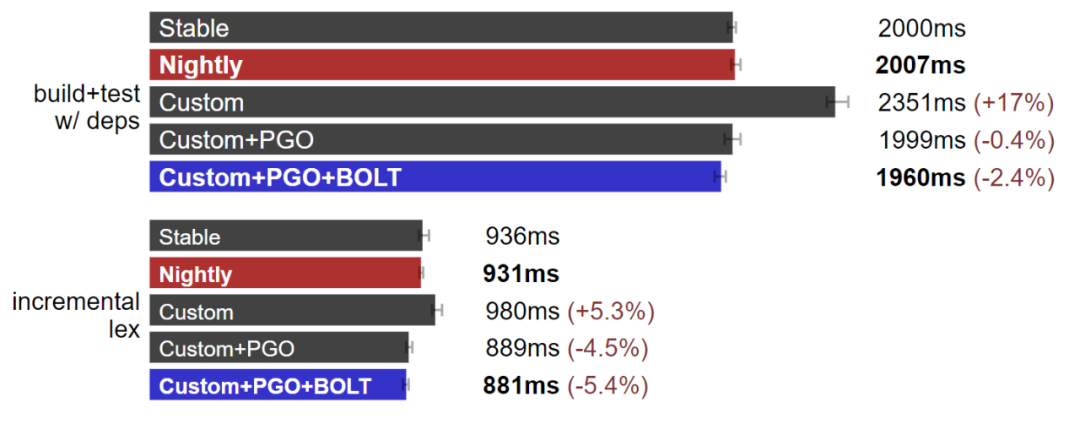
如果你好奇的话,可以看看这段工具链构建脚本。可能不适用于你的机器,但只要我能运行就行:https://github.com/quick-lint/cpp-vs-rust/blob/953429a4d92923ec030301e5b00face1c13bb92b/tools/build-toolchains.sh
与 C++ 编译器相比,通过 rustup 发布的 Rust 工具链似乎已经是优化完成的结果。PGO 加上 BOLT 的组合只带来了不到 10% 的性能提升。但有提升就是好的,所以在后续与 C++ 的竞争中我们会继续使用这个速度最快的工具链。
我第一次搭建的 Rust 自定义工具链比 Nightly 还要慢 2%,我在 Rust config.toml 的各种选项中反复调整,不断交叉检查 Rust 的 CI 构建脚本以及我自己的脚本,最终在好几天的挣扎后才让这二者性能持平。在我最终润色这篇文章时,我进行了 rustup 更新,拉取 git 项目,并重头又建了一遍工具链。结果这次我的自定义工具链速度更快了!有可能是我在 Rust 仓库里提交错了代码……
优化 C++ 构建
在最初的 C++ 项目 quick-lint-js 中,我已经用常见的手段优化了编译时间,比如用 PCH、禁用异常和 RTTI、调整编译标志、删除非必要 #include、将代码从头中移出、外置模板实例等方法。但此外还有一些 C++ 编译器和链接器我没试过,在我们进入 C++ 和 Rust 的对比之前,先从这些里面挑出最适合我们的。
Linux:自定义 Clang 是最快的工具链。(数据越小越好)
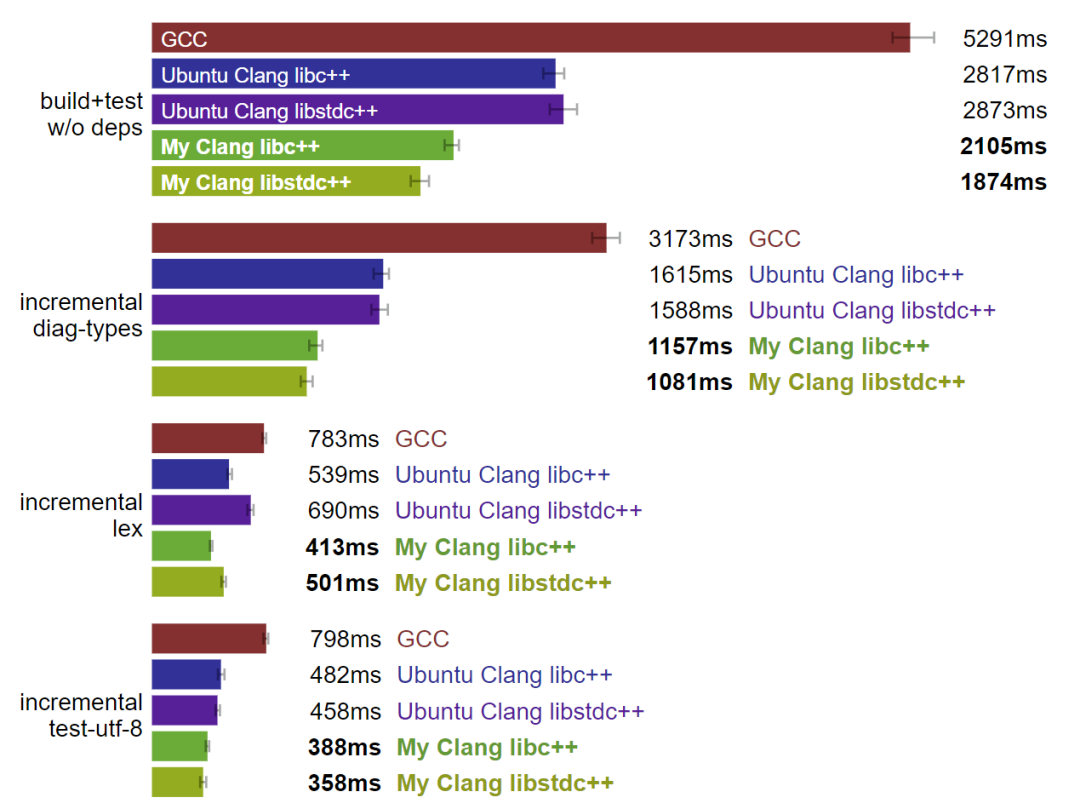
很明显,Linux 上的 GCC 是个特例,而 Clang 的表现则要好上很多。我自定义构建的 Clang(和 Rust 工具链一样,也是用 PGO 和 BOLT 构建的)相较于 Ubuntu 的 Clang,显著优化了构建时间,而 libstdc++ 的构建略快于平均 libc++ 的速度。
那我的自定义 Clang 加上 libstdc++ 在 C++ 和 Rust 的对比中表现如何呢?
macOS:Xcode 是最快的工具链。(数据越小越好)
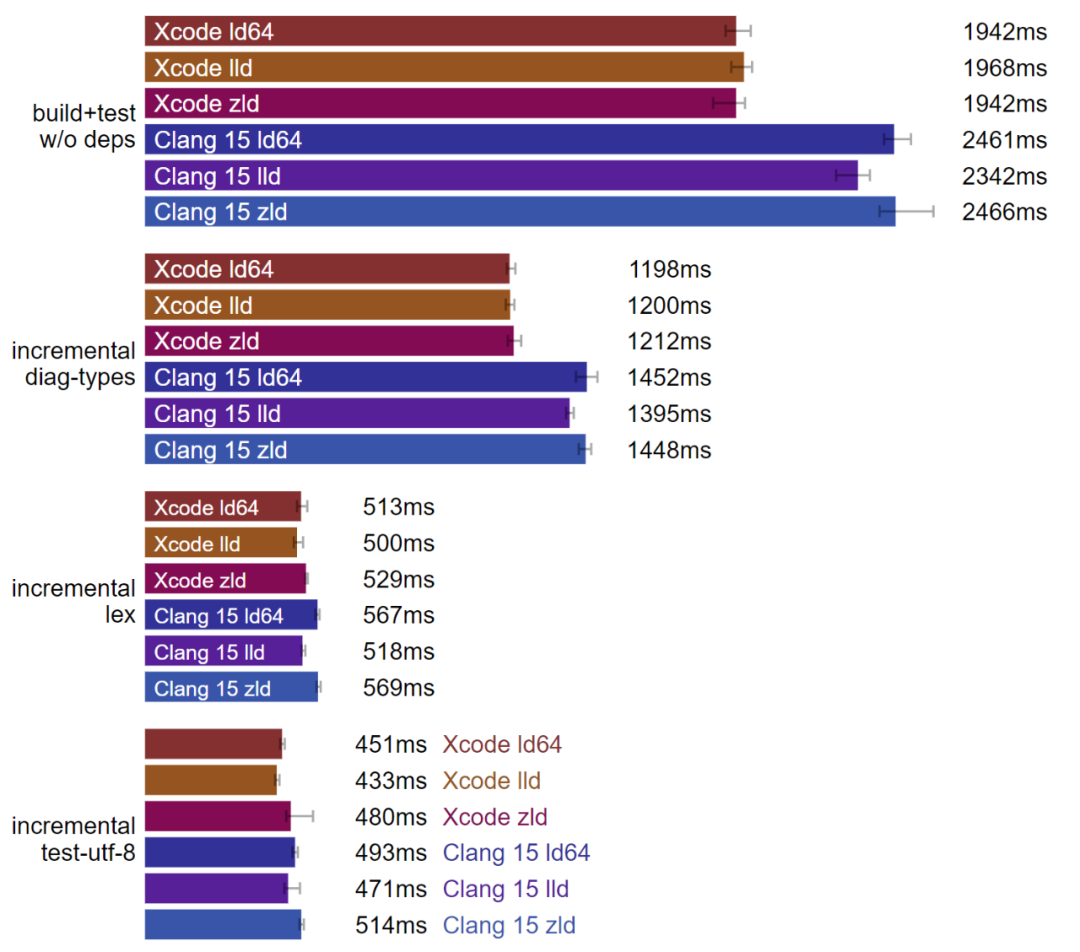
在 macOS 上,搭配 Xcode 的 Clang 工具链似乎要比 LLVM 网站上的 Clang 工具链优化得更好。
C++20 模块
我的 C++ 代码用的是 #include,但如果用 C++20 中新增加的 import 又会怎么样呢?C++20 的模块是不是理论上来说应该会让编译速度超级快?
我在项目了尝试过 C++20 模块,但直到 2023 年的 1 月 3 日,Linux 上的 CMake 模块支持过于实验性质了,我甚至连“hello world”都没跑起来。
或许 2023 年中 C++20 模块会大放异彩,对于我这种超级在意构建时间的人来说,真是这样就太好了。但目前为止,我还是继续用经典 C++ 的 #include 和 Rust 做对比吧。
对比 C++ 和 Rust 的构建时间
通过把 C++ 项目改写成 Rust,并尽可能地优化 Rust 的构建时间后,问题来了:C++ 和 Rust 究竟谁更快呢?
很可惜,答案是“看情况”!
Linux:Rust 部分情况下构建速度超越 C++。(数据越小越好)
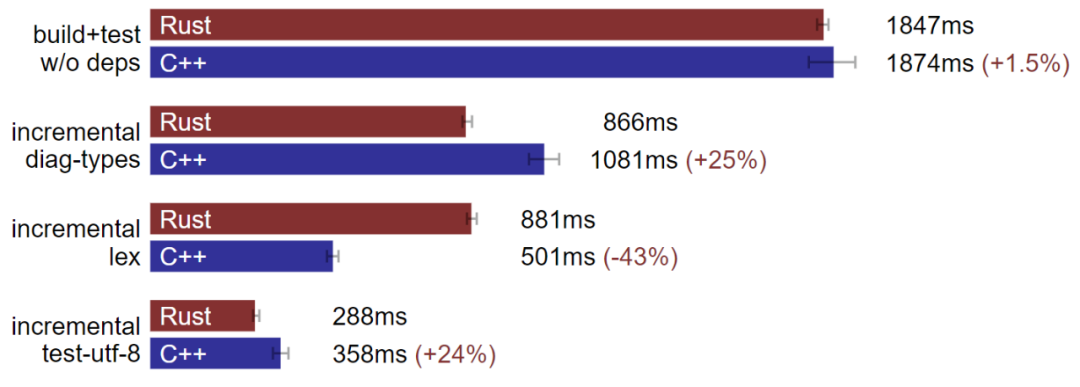
在我的 Linux 机器上,部分情况下 Rust 的构建速度确实优于 C++,但也有速度持平或逊于 C++ 的情况。在增量 lex 的基准上,我们修改了大量源码,Clang 比 rustc 速度快,但在其他增量基准上,rustc 又会反超 Clang。
macOS:C++ 构建速度通常快于 Rust。(数据越小越好)
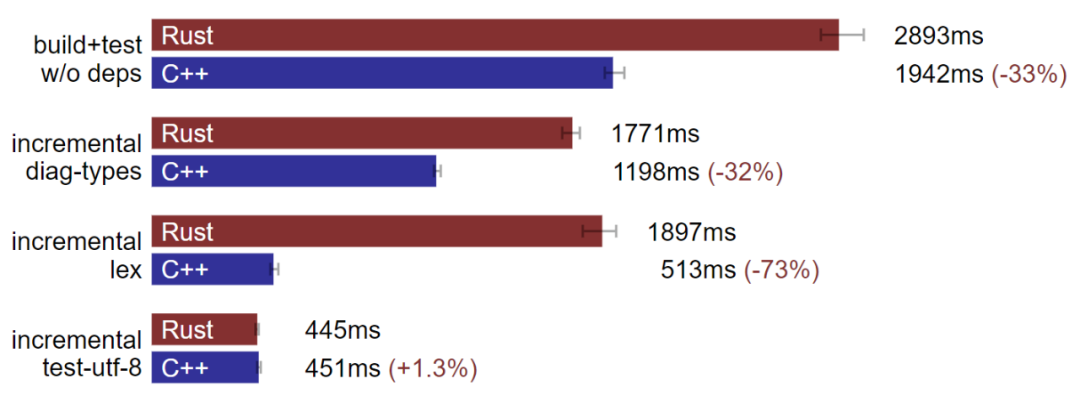
但我的 macOS 机器上情况却截然不同。C++ 的构建速度常常快上 Rust 许多。在增量测试 utf-8 的基准,我们修改中等数量测试文件,rustc 编译速度会略微超过 Clang,但在包括全量构建等其他基准上,Clang 很明显效果要更好。
超过 17k 行代码
我基准测试的项目只有 17k 行代码,算是小型项目,那么对超过 10 万行代码的大型项目来说,又是什么情况呢?
我把最大的模块,也就是词法分析器的代码复制粘贴了 8、16 以及 24 遍,分别用来测试。因为我的基准里也包括了运行测试的时间,我觉得构建时间即使是对于那些能瞬间构建完的项目,也应该会线性增长。
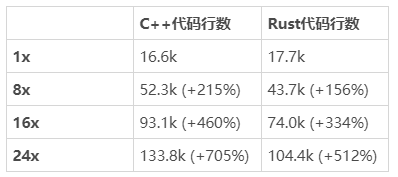
倍数扩大后 C++ 完整构建优于 Rust。(测试于 Linux,数据越小越好)
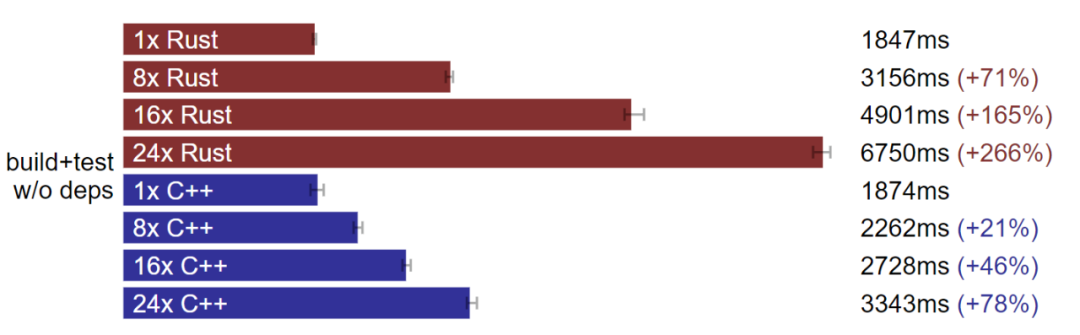
倍数扩大后 C++ 增量构建优于 Rust。(测试于 Linux,数据越小越好)
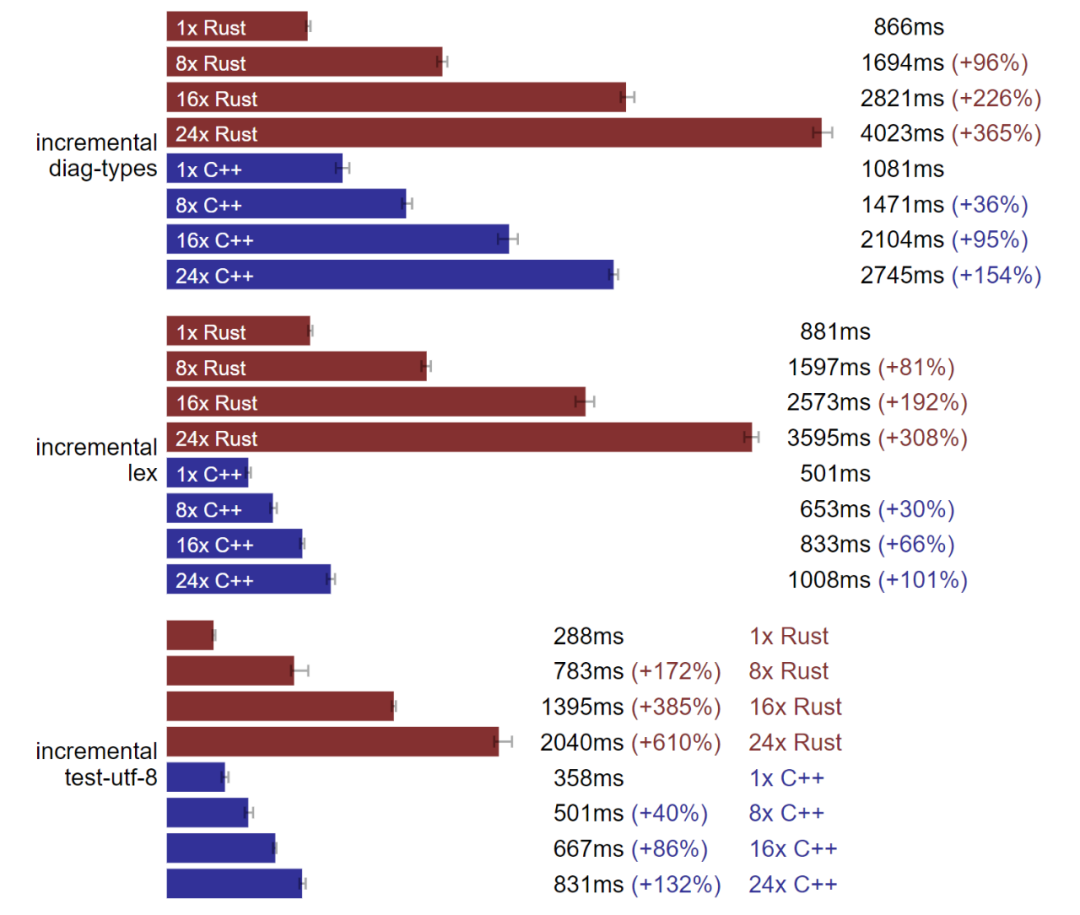
Rust 和 Clang 确实都是线性扩大,这点很好。
正如预期中一样,修改 C++ 的头文件,也就是增量 diag-type 会大幅影响构建时间。而由于 Mold 链接器的存在,其他增量基准中构建时间的扩展系数很低。
Rust 构建的扩展性让我很失望,即使只是增量 utf-8 测试的基准,无关文件的加入也不应该让它的构建时间如此受影响。测试所用的 crate 布局时“工作区且多个可执行测试”,因此 utf-8 测试应该能独立编译可执行文件。
结 论
编译时间对 Rust 而言算是问题吗?答案是肯定的。虽然也有一些可以加快编译速度的提示和技巧,但却没有效果非常显著的数量级改进,这让我在开发 Rust 时非常高兴。
Rust 的编译时间和 C++ 相比呢?确实也很糟。至少对我的编码风格来说,Rust 在大型项目上开发的编译时间甚至更加远比 C++ 还要糟糕。
再回过头看看我当初的假设,几乎全军覆没:
Rust 改写版代码行数比 C++ 多;
在全量构建上,C++ 相比 Rust 在 1.7 万行代码上构建时间相似,在 10 万行代码上构建时间要少;
在增量构建上,Rust 相比 C++ 在部分情况构建时间要短,在 1.7 万行上构建时间要长,在 10 万行代码上构建时间甚至更长。
我不爽吗?确实。在改写过程中,我不断学习着 Rust 相关的知识,比如 proc marco 能替代三个不同代码生成器,简化构建流水线,让新开发者们日子更好过。但我完全不想念头文件,以及 Rust 的工具类真的很好用,特别是 Cargo、rustup 以及 miri。
但我决定不把 quick-lint-js 项目中剩下的代码也改成 Rust,但如果 Rust 的构建时间能有明显优化,或许我会改变主意。当然,前提是我还没被 Zig 迷走心神。
附注
源码
删减后的 C++ 项目源码、移植版 Rust(包括不同的项目布局)、代码生成脚本和基准测试脚本、GPL-3.0 及以上。
Linux 机器
名称:strapurp
CPU:AMD Ryzen 9 5950X (PBO; stock clocks) (32 threads) (x86_64)
RAM:G.SKILL F4-4000C19-16GTZR 2x16 GiB (overclocked to 3800 MT/s)
操作系统:Linux Mint 21.1
内核:Linux strapurp 5.15.0-56-generic #62-Ubuntu SMP Tue Nov 22 1914 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
Linux 性能治理器:schedutil
CMake:版本 3.19.1
Ninja:版本 1.10.2
GCC:版本 12.1.0-2ubuntu1~22.04
Clang(Ubuntu):版本 14.0.0-1ubuntu1
Clang (自定义):版本 15.0.6(Rust fork; 代码提交 3dfd4d93fa013e1c0578d3ceac5c8f4ebba4b6ec)libstdc++ for Clang:版本 11.3.0-1ubuntu1~22.04
Rust 稳定版:1.66.0 (69f9c33d7 2022-12-12)
Rust Nightly:版本 1.68.0-nightly (c7572670a 2023-01-03)
Rust(自定义):版本 1.68.0-dev (c7572670a 2023-01-03)
Mold:版本 0.9.3 (ec3319b37f653dccfa4d1a859a5c687565ab722d)
binutils:版本 2.38
macOS 机器
名称:strammer
CPU:Apple M1 Max (10 threads) (AArch64)
RAM:Apple 64 GiB
操作系统:macOS Monterey 12.6
CMake:版本 3.19.1
Ninja:版本 1.10.2
Xcode Clang:Apple clang 版本 14.0.0 (clang-1400.0.29.202) (Xcode 14.2)
Clang 15:版本 15.0.6 (LLVM.org website)
Rust 稳定版:1.66.0 (69f9c33d7 2022-12-12)
Rust Nightly:版本 1.68.0-nightly (c7572670a 2023-01-03)
Rust(自定义):版本 1.68.0-dev (c7572670a 2023-01-03)
lld:版本 15.0.6
zld:代码提交 d50a975a5fe6576ba0fd2863897c6d016eaeac41
基准
用 deps 的构建和测试
C++:cmake -S build -B . -G Ninja && ninja -C build quick-lint-js-test && build/test/quick-lint-js-test 计时
Rust:cargo fetch 未计时,再用 cargo test 计时
不用 deps 的构建和测试
C++:cmake -S build -B . -G Ninja && ninja -C build gmock gmock_main gtest 未计时, 再用 ninja -C build quick-lint-js-test && build/test/quick-lint-js-test 计时
Rust:cargo build --package lazy_static --package libc --package memoffset" 未计时, 再用 cargo test 计时
增量 diag-types
C++:构建和测试未计时,随后修改 diagnostic-types.h,再用 ninja -C build quick-lint-js-test && build/test/quick-lint-js-testRust:构建和测试未计时,修改 diagnostic_types.rs 后,cargo test
增量 lex
同增量 diag-types,但使用 lex.cpp/lex.rs
增量 utf-8 测试
同增量,但使用 test-utf-8.cpp/test_utf_8.rs
每个可执行基准均采用 12 个样本,弃置前两个,基准仅显示最后十个样本的平均性能。误差区间展示最小与最大样本间区别。
审核编辑:刘清
-
解码器
+关注
关注
9文章
1156浏览量
41127 -
SIMD
+关注
关注
0文章
35浏览量
10366 -
UTF-8
+关注
关注
0文章
13浏览量
7891 -
LSP
+关注
关注
0文章
13浏览量
9859 -
rust语言
+关注
关注
0文章
57浏览量
3049
原文标题:我用 Rust 改写了自己的C++项目:这两个语言都很折磨人!
文章出处:【微信号:AI前线,微信公众号:AI前线】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Oculus Rift与PS VR:谁会更胜一筹?
射频技术和射频标识对比分析谁更胜一筹?
公共云与私有云大比拼 成本计算谁更胜一筹?
华为P10上线预售!华为P10对比iPhone7,谁将更胜一筹?

努比亚M2今日发布,对比小米6s,谁能更胜一筹?
小米电视4 55吋与雷鸟I55参数对比,谁能更胜一筹?
微软、谷歌、英特尔都发力AI,3巨头谁更胜一筹?
在各项生物识别技术中,哪种识别技术更胜一筹?
MelNet 捕捉“高层结构”更胜一筹
安规电容与薄膜电容大比拼,究竟谁更胜一筹?
UVLED面光源与传统光源对比:谁更胜一筹?






 工商网监
工商网监
评论