 利用Python读取多份Excel的小技巧
利用Python读取多份Excel的小技巧
在使用 Python 批量处理 Excel 时经常需要批量读取数据,常见的方式是结合glob模块,可以实现将当前文件夹下的所有csv批量读取,并且合并到一个大的DataFrame中
df_list = []
for file in glob.glob("*.csv"):
df_list.append(pd.read_excel(file))
df = pd.concat(df_list)
但是这样要求读取的每一个csv文件格式、列名都是一样的。
如果想要将每一个csv独立的进行读取,可以使用os模块来循环遍历当前文件夹中的 CSV 文件,然后使用 Pandas 的read_csv函数来读取每个文件
import os
import pandas as pd
df_list = []
for file in os.listdir():
if file.endswith(".csv"):
df_list.append(pd.read_csv(file))
现在,df_list中的每个元素都是一个DataFrame,但是这样依旧不够完美,调用的时候依旧需要手动从列表中提取。
那如何自动读取当前文件夹下全部CSV数据,并将每个CSV赋给不同的变量
可以使用Python中的globals()函数,它返回一个字典,其中包含当前程序的所有全局变量,例如我们可以使用如下语法来为字典中的某个键赋值:
globals()[key] = value
所以,使用下面的代码可以实现自动读取当前文件夹下全部CSV数据,并将每个CSV赋给不同的变量
df_list = [] for i, file in enumerate(os.listdir()): if file.endswith(".csv"): df_list.append(pd.read_csv(file)) for i, df in enumerate(df_list): globals()[f'df{i+1}'] = df
当然,类似的方法还可以应用于读取Excel的不同sheet,例如假设data.xlsx有10个sheet
df_list = [pd.read_excel("data.xlsx", sheet_name=i) for i in range(10)]
for i, df in enumerate(df_list):
globals()[f"df{i+1}"] = df
如果你不清楚数据有多少Sheet,也可以使用sheet_name=None,然后根据返回的字典自动读取
df_list = pd.read_excel("data.xlsx", sheet_name=None)
for i, (name, df) in enumerate(df_list.items()):
globals()[f"df_{name}"] = df
审核编辑:刘清
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
python
+关注
关注
56文章
4819浏览量
85441 -
csv
+关注
关注
0文章
39浏览量
5915
原文标题:如何用 Python 批量循环读取 Excel ?
文章出处:【微信号:DBDevs,微信公众号:数据分析与开发】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
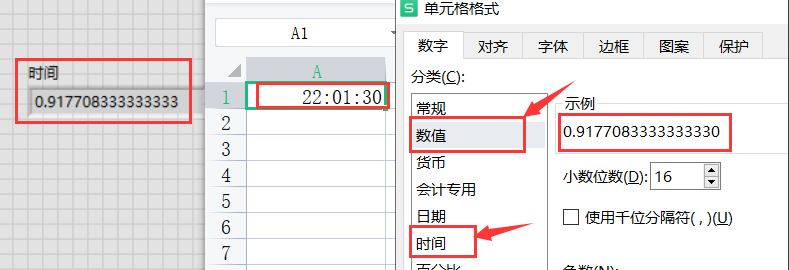
LabVIEW读取Excel数据时间转换设计
利用LabVIE读取出Excel中的时间为带小数点的数值型,需将其进行转换。转换过程如下分为含年月日和不含年月日两种转换方式。
发表于 12-20 08:54
•8861次阅读
Python利用pandas读写Excel文件
使用pandas模块读取Excel文件可以更为方便和快捷。pandas可以将Excel文件读取为一个DataFrame对象,方便进行数据处理和分析。

python导出excel格式的oracle数据报表讲解
python导出excel格式的oracle数据报表讲解(通信电源技术期刊官网)-该文档为python导出excel格式的oracle数据报表讲解文档,是一
发表于 09-28 13:10
•7次下载

Excel新功能要逆天 微软把Python加入Excel
Excel新功能要逆天 微软把Python加入Excel Excel新功能要逆天了,比如你可以在Excel里快速实现机器学习天气预测模型,可
微软正在将Python引入Excel
微软现代工作总经理Stefan Kinnestrand解释说:“您可以使用Python Plots和libraries在Excel中操纵和探索数据,然后使用Excel的公式、图表和数据透视表来进一步
如何使用Python和pandas库读取、写入文件
在本文中,我将介绍如何使用 Python 和 pandas 库读取、写入文件。 1、安装 pip install pandas 2、读取 import pandas as pd df
如何使用Python读取写入Word文件
01 准备 Python 是一种通用编程语言,也可以用于处理 Microsoft Word 文件。在本文中,我将向你介绍如何使用 Python 和 python-docx 库读取、写入
Python中Excel转PDF的实现步骤
将Excel文件转换为PDF可以方便储存表格数据,此外在打印或共享文档时也能确保表格样式布局等在不同设备和操作系统上保持一致。今天给大家分享一个使用第三方Python库Spire.XLS for Python 实现





 工商网监
工商网监
评论