 为什么要用洋葱架构?洋葱架构层是如何构成的
为什么要用洋葱架构?洋葱架构层是如何构成的
领域驱动设计(Domain-driven design,DDD)是一种为复杂需求开发软件的方法,它将软件的实现与不断发展的核心业务概念模型紧密地结合在一起。
领域是一个知识的范畴。它指的是我们的软件所要模拟的业务知识。领域驱动设计的中心是领域模型,它对一个领域的流程和规则有着深刻的理解。洋葱架构实现了这一概念,并极大地改善了代码的品质,降低了复杂性,并且支持不断发展的企业系统。
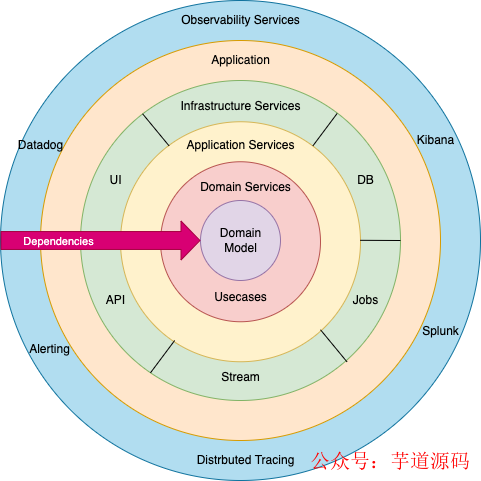
为什么要用洋葱架构?
领域实体是核心和中心部分。洋葱架构是建立在一个领域模型上的,其中各层是通过接口连接的。其背后的思想是,在领域实体和业务规则构成架构的核心部分时,尽可能将外部依赖性保持在外。
它提供了灵活、可持续和可移植的架构。
各层之间没有紧密的耦合,并且有关注点的分离。
由于所有的代码都依赖于更深的层或者中心,所以提供了更好的可维护性。
提高了整体代码的可测试性,因为单元测试可以为单独的层创建,而不会影响到其他的模块。
框架/技术可以很容易地改变而不影响核心领域。例如,RabbitMQ 可以被 ActiveMQ 取代,SQL 可以被 MongoDB 取代。
原则
洋葱架构是由多个同心层构成,它们相互连接,并朝向代表领域的核心。它是基于控制反转(Inversion of Control,IoC)的原则。该架构并不关注底层技术或框架,而是关注实际的领域模型。它是基于以下原则:
依赖性
圆圈代表不同的责任层。一般来说,我们潜入得越深,就越接近于领域和业务规则。外圈代表机制,内圈代表核心领域逻辑。外层依赖于内层,而内层则对外圈一无所知。通常情况下,属于外圈的类、方法、变量和源代码依赖于内圈,但是反过来也一样。
数据格式/结构可能因层而异。外层的数据格式不应该被内层使用。例如,API 中使用的数据格式可以与 DB 中用于持久化的数据格式不同。数据流可以使用数据传输对象。每当数据跨层/跨界时,它应该以方便该层的形式出现。例如,API 可以有 DTO,DB 层可以有 Entity Objects,这取决于存储在数据库中的对象与领域模型的不同。
数据封装
每个层/圈封装或隐藏内部的实现细节,并向外层公开接口。所有的层也需要提供便于内层消费的信息。其目的是最小化层与层之间的耦合,最大化跨层垂直切面内的耦合 。我们在较深的层定义抽象接口,并在最外层提供其具体实现。这样可以确保我们专注于领域模型,而不必过多地担心实现细节。我们还可以使用依赖性注入框架,比如 Spring,在运行时将接口与实现连接起来。例如,领域中使用的存储库和应用服务中使用的外部服务在基础设施层实现。
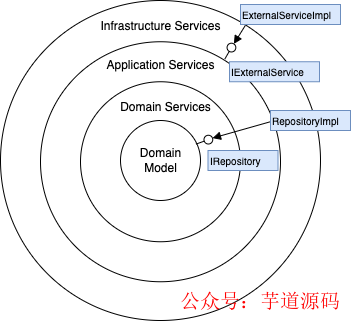
洋葱架构中的数据封装
关注点的分离
应用被分为若干层,每一层都有一组职责,并解决不同的关注点。每一层都作为应用中的模块/包/命名空间。
耦合性
低耦合性,可以使一个模块与另一个模块交互,而不需要关注另一个模块的内部。所有的内部层都不需要关注外部层的内部实现。
洋葱架构层
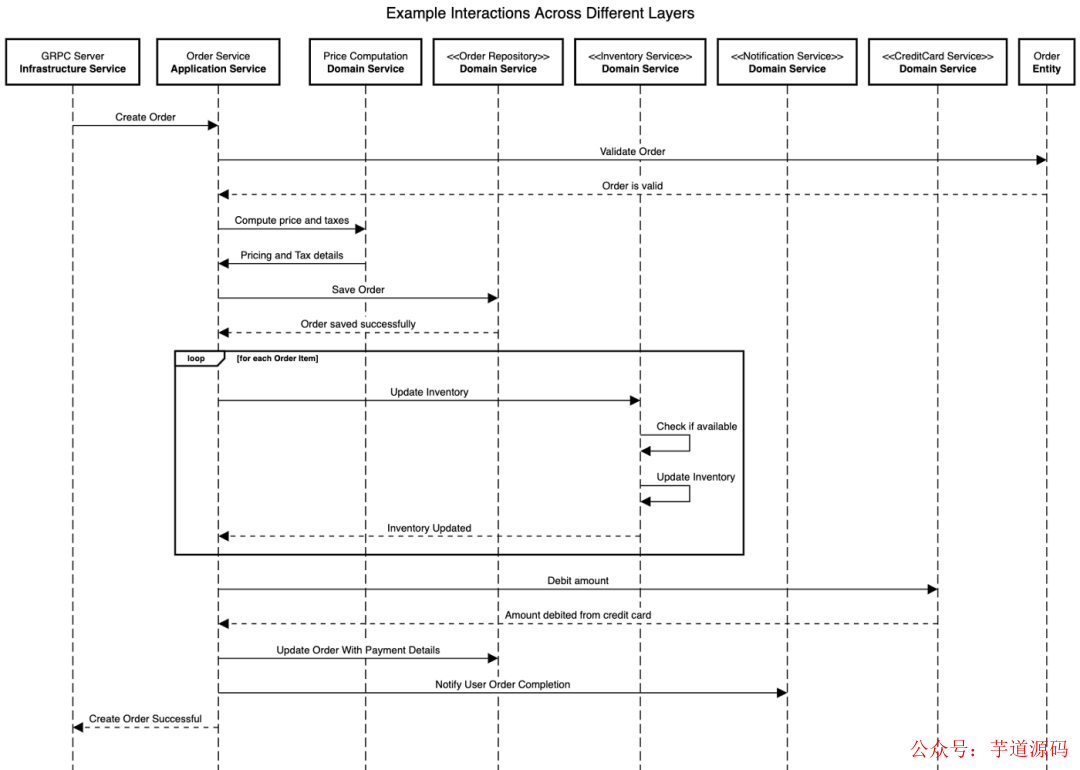
让我们通过一个创建订单的用例来了解架构的不同层和它们的职责。当收到一个创建订单的请求时,我们会对这个订单进行验证,将这个订单保存在数据库中,更新所有订单项目的库存,借记订单金额,最后向客户发送订单完成的通知。
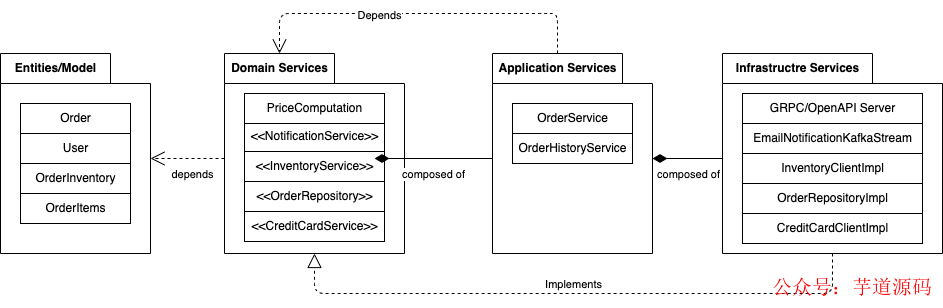
说明各层之间的依赖关系的包图
领域模型/实体
领域实体是领域驱动设计的基本构件,它们被用来在代码中为通用语言的概念建模。实体是在问题域中具有唯一身份的领域概念。领域实体封装了属性和实体行为。它应该是独立于数据库或网络 API 等特定技术的。例如,在订单领域,订单是一个实体,并具有像 OrderId、Address、UserInfo、OrderItems、PricingInfo 这样的属性以及像 AddOrderItems、GetPricingInfo、ValidateOrder 这样的行为。
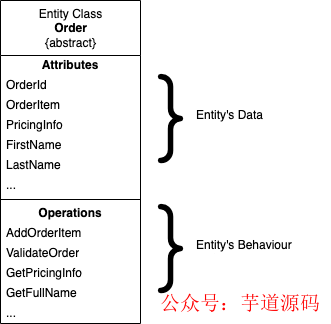
订单实体类
领域服务
领域服务负责保持领域逻辑和业务规则。所有的业务逻辑应该作为领域服务的一部分来实现。领域服务由应用服务协调,以服务于业务用例。它们不是典型的 CRUD 服务,通常是独立的服务。领域服务负责复杂的业务规则,如在处理订单时计算价格和税收信息,保存和更新订单的订单库接口,更新购买物品信息的库存接口等。
它包含了对其目标非常关键的算法,并且将用例作为应用的核心来实现。
应用服务
应用服务也被称为“用例”,是只负责协调请求步骤的服务,不应该有任何业务逻辑。应用服务与其他服务交互,以满足客户的请求。让我们考虑一下用例,用一个物品清单创建一个订单。我们首先需要计算价格,包括税收计算/折扣等,保存订单项目并向客户发送订单确认通知。定价计算应该是领域服务的一部分,但涉及定价计算、检查可用性、保存订单和通知用户的协调工作应该是应用服务的一部分。应用服务只能由基础设施服务调用。
基础设施服务
基础设施服务也被称为基础设施适配器,是洋葱架构的最外层。这些服务负责与外部世界交互,不解决任何领域的问题。这些服务只是与外部资源通信,没有任何逻辑。例如:外部通知服务、GRPC 服务器端点、Kafka 事件流适配器、数据库适配器。
可观察性服务
可观察性服务负责监控应用。这些服务有助于执行以下任务:
数据收集(指标、日志、痕迹):主要使用库/侧线来收集代码执行期间的各种数据。
数据存储:使用能够集中存储所收集的数据的工具(分类、索引等)。
可视化:使用允许你对收集的数据进行可视化的工具。
一些例子包括 Splunk、ELK、Grafana、Graphite、Datadog。
测试策略
洋葱架构的不同层有不同的职责,相应地也有不同的测试策略。测试金字塔是一个很好的框架,它规定了不同类型的测试。属于领域模型、领域服务和应用服务的业务规则应通过单元测试进行测试。当我们移动到外层时,在基础设施服务中进行集成测试更有意义。对于我们的应用,端到端测试和 BDD 是最合适的测试策略。
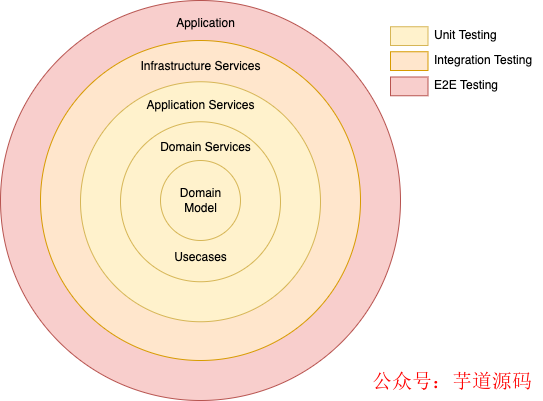
针对不同层的测试策略
微服务
当孤立地看待每个微服务时,洋葱架构也适用于微服务。每个微服务都有自己的模型、自己的用例,并定义了自己的外部接口,用于检索或修改数据。这些接口可以用一个适配器来实现,该适配器通过公开 HTTP Rest、GRPC、Thrift Endpoints 等连接到另一个微服务。它很适合微服务,在微服务中,数据访问层不仅包括数据库,还包括例如一个 http 客户端,以从另一个微服务,甚至从外部系统获取数据。
应用结构和层数
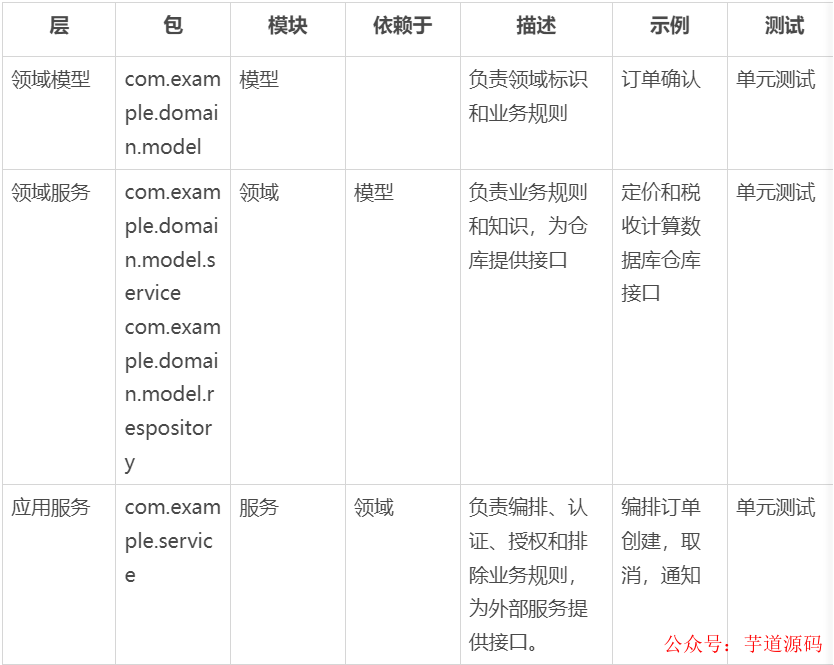
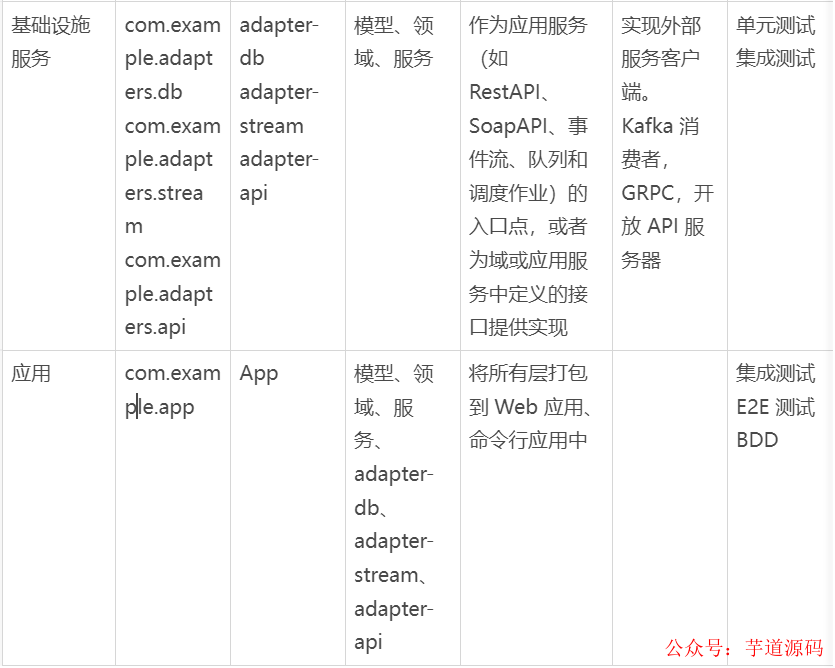
应用结构和层,包括层如何映射到模块以及它们之间的依赖关系。它还描述了对不同层使用什么样的测试策略
模块化与打包
有两种方法来组织应用的源代码:
要么,我们可以将所有的包放在一个模块/项目中,要么将应用分为不同的模块/项目,每个模块/项目负责洋葱架构中的一个层。
这在很大程度上取决于应用的复杂性和项目的规模,将源代码分为多个模块。在微服务架构中,模块化可能有意义,也可能没有意义,这取决于复杂性和用例。
框架、客户端和驱动
基础设施层由网络或服务器的框架、数据库的客户端、队列或外部服务组成。它负责配置和缝合所有的外部服务和框架。洋葱架构提供了解耦功能,因此在任何时候交换技术都会变得更容易。
我们需要每个层吗?
将我们的应用分层组织有助于实现关注点的分离。但我们需要所有的层吗?也许需要,也许不需要。这取决于用例和应用的复杂性。根据应用的需要,也可以创建更多的抽象层。例如,对于没有很多业务逻辑的小型应用,拥有领域服务可能没有意义。无论哪一层,依赖关系都应该是从外层到内层。
总结
洋葱架构在开始时可能似乎有些困难,但是在业界已经得到了普遍的认可。这是一种让软件易于演进的强有力架构。通过把应用划分为几层,可以使系统更加易于测试、维护和移植。它有助于在旧框架过时时轻松采用新框架/技术。与其他架构风格类似,如六边形、分层、简洁的架构等,它为常见问题提供了一个解决方案。
审核编辑:刘清
-
适配器
+关注
关注
8文章
1952浏览量
68012 -
SQL
+关注
关注
1文章
763浏览量
44123 -
RBAC
+关注
关注
0文章
44浏览量
9966 -
mongodb
+关注
关注
0文章
22浏览量
365
原文标题:详解DDD“洋葱架构”
文章出处:【微信号:芋道源码,微信公众号:芋道源码】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
正在建立Onion洋葱中国站,大家有什么好的建议?
谈谈如何设计MCU程序3层架构
三层架构的原理及作用_三层架构怎么用
没有人能够拒绝洋葱的魅力 realme X大师版 洋葱6月27日正式开售
realme X大师版 洋葱已正式开售
谈谈后端架构的演进过程:N-Layered和DDD架构介绍
架构与设计 常见微服务分层架构的区别和落地实践





 工商网监
工商网监
评论