 动态内存分配优化了Blackfin处理器软件的集成
动态内存分配优化了Blackfin处理器软件的集成
典型的DSP通常具有少量快速片上存储器。微控制器通常可以访问更大的外部存储器。Blackfin处理器具有分层内存架构,结合了两种方法的优点,提供具有不同性能级别的多个级别的内存。对于需要最大确定性的应用,它可以在单个内核时钟周期内访问片内SRAM。对于代码大小较大的系统,可以使用更大的片上和片外存储器,但延迟会增加。
就其本身而言,此层次结构仅具有中等实用性;今天的高速处理器通常以慢得多的速度运行,因为较大的应用程序只能容纳较慢的外部存储器。为了提高性能,程序员可以选择手动将密钥代码移入和移出内部SRAM。此外,在架构中添加数据和指令缓存使外部存储器更易于管理。缓存减少了指令和数据手动移动到处理器内核的过程。这极大地简化了编程模型,无需担心管理进入内核的数据和指令流。
虽然Blackfin的存储器用途广泛且易于在许多应用中使用,但在某些应用中,例如嵌入式手机系统,任何嵌入式处理器的内存分配都可能很困难。在这种应用中,指令高速缓存不能提供与手动移入和移出SRAM相同的代码管理级别。本文建议使用动态内存分配工具来应对这一挑战。
为移动电话平台开发协议栈和应用软件的一个基本要素是系统中内存资源的高效处理。过去,内存资源是“手动”分配给系统内的每一段代码;但是,视频和语音识别等模块数量的增加使得使用这种方法的解决方案在优化方面更具挑战性。动态内存分配器可用于在大型应用程序中分配和释放内存,无需手动管理此任务。本文描述了动态内存分配的一些原则,并演示了一个特定的实现,该实现考虑了整体系统考虑因素以及Blackfin内存划分为具有各种属性(价格,速度,双访问可能性)的不同空间。
内存管理解决方案
在大型嵌入式应用中,可以实现多种内存管理方法。主要方法如下所述。
堆叠。所有变量和缓冲区都可以简单地在函数之上声明。它们存储在堆栈空间中,并且仅在退出函数时释放该空间。该解决方案的主要缺点是堆栈增长,例如,堆栈在函数的生命周期内不断增长。它的生存期有时可能很长,因为函数可能是递归的和/或可中断的。
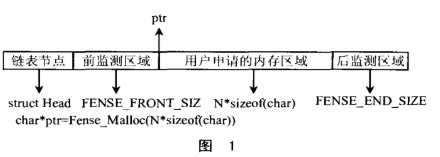
手动重叠。另一种流行的解决方案包括使用在链接阶段定义的部分对缓冲区地址进行硬编码。这比在堆栈中分配更灵活一些,因为它允许内存重叠。如果两个模块永远不会相互中断,则它们的临时内存可以共享相同的内存部分。然而,随着模块数量的增加,对于集成系统来说,这种解决方案确实变得难以管理。此外,其他内存问题(例如不适当的重叠或给定部分的缓冲区大小不足)可能很难跟踪。更糟糕的是,当需要新功能需要两个以前从未及时重叠的功能来同时运行时,情况就更加困难了。图 1 显示了一个基于重叠的手动实现示例。

图1.手动重叠内存。
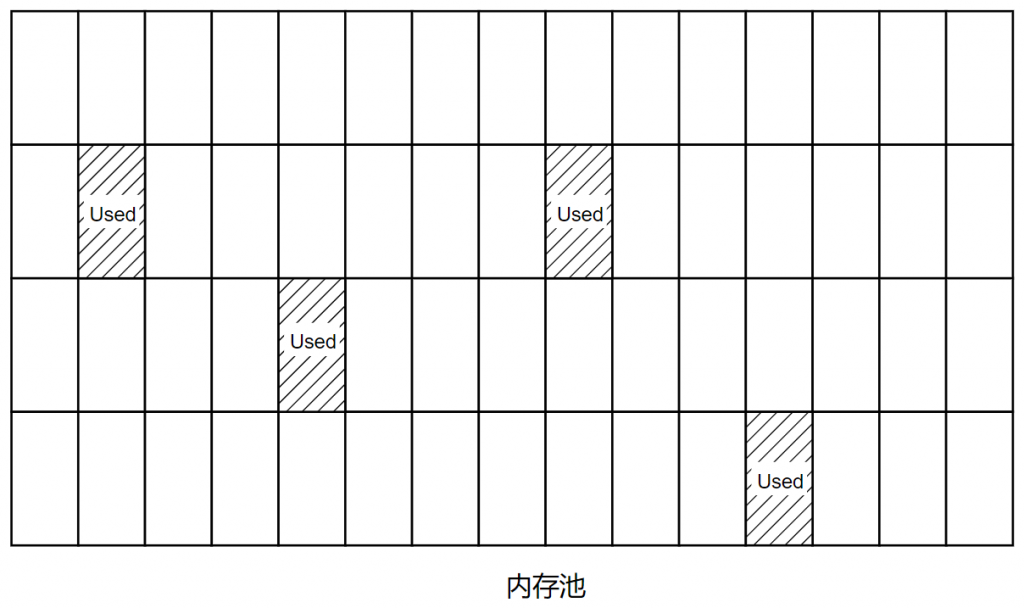
动态分配。 动态分配可实现内存重叠:一旦不需要内存空间,就会释放内存空间并可以重用。与堆栈分配方法不同,动态分配不会导致不受控制的内存空间增加。实际上,函数使用的内存在不需要时会立即释放,而不是等待函数结束。
开发动态内存分配器时要考虑哪些功能?
动态内存分配器由两个函数组成:一个分配内存空间;另一个释放内存。分配会保留一些空间来处理内存请求。调用 free 函数后,将释放保留的空间,并可用于满足进一步的请求。例如,让我们构建一个非常基本的动态内存分配器来理解这段代码必须处理的所有权衡。我们将从一些基本定义开始,然后描述分配器。
块。假设分配器可以为所需的内存提供大内存空间的块。很容易理解,不能拿走整个空间来满足第一个请求。相反,初始内存空间可以拆分为不同大小的不同块。
标头。当发出内存请求时,我们如何知道给定的片段足够大?大小必须保存在内存中的某个地方。一种解决方案是将其保存在块内的标头中。这是内存开销的一个元素。此外,标头中至少需要有一个位专用于指示块是空闲的还是正在使用的。
在块中徘徊。如果第一个块太小,我们如何跳转到下一个块?如果所有块在内存中都是连续的,则知道块的大小就足以跳转到下一个块。另一种解决方案包括保留指向标头中下一个块的指针 - 这是链表的原则。
找到合适的。我们如何选择哪个空闲块将服务于请求?一个必要的条件是找到一个大小至少为所需大小的空闲块。然后可以使用满足此要求的第一个块。此策略称为“先拟合”。另一个策略(最合适的策略)包括查找可以容纳请求的最小可用块。这是动态内存分配器必须处理的最具挑战性的困境:速度与内存大小。第一次适合的速度很快,但可能会导致巨大的记忆损失,而找到最佳适合的替代方案需要时间。通过使用多个块(bins)链表可以达成折衷,其中每个列表都有其相似大小的块。最适合的策略选择数据桶,而第一次适合的策略选择数据桶中的区块。
碎片化。另一种解决方案包括使用首次适合策略,并释放大于请求的区块末尾。此解决方案的一个缺点是,内存很快由几个分散的未使用内存块(大小不同,通常很小)组成。由于产生的可用空间很小,未来的分配很困难。这种情况称为内存碎片。
为了加快请求速度,一些分配器基于免费块的链接列表。这样可以节省一些时间,因为搜索可以避免考虑所有正在使用的块。但是,这种方法确实有一个缺点。如果只将空闲块保存在列表中,则很难将它们全部连续放置在内存中;此问题会阻止分配器获取两个相邻的中等块并将它们放在一起(或合并它们)以构建一个更大的块。
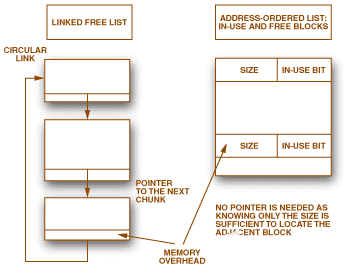
图2.动态分配器的示例。
现在,我们已经介绍了所有的概念和折衷方案,以了解为Blackfin移动电话系统设计的分配器:ADIalloc。
当前实现:ADIalloc
信号处理功能(例如新的视频和音频标准)的不断增加促使人们开发一种称为ADIalloc的分配器,用于手机应用。它旨在通过避免不必要的内存重叠来帮助缩短使用处理器的产品的上市时间,并通过减少峰值内存使用量来降低成本。
基本原则
当前的实现更侧重于速度性能而不是内存开销。内存被分区到箱中。每个箱都包含大小相等的内存块。箱中的块具有连续的地址,允许从一个块快速跳转到下一个块。查找适合请求的区块的策略最适合 bin 和 bin-first fit in - 这意味着第一个空闲块,因为所有块的大小相同。此外,选择箱中块的大小是为了便于找到最佳箱:它们都由 2 的幂相关。bin (N+1) 中的块是 bin N 中块大小的两倍(bin N 也可以包含 0 个块......
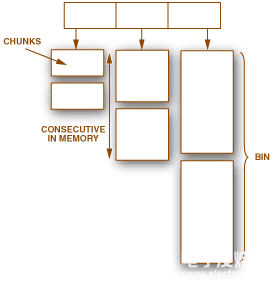
图3.ADIalloc的箱/块配置。
某些软件模块有时可能需要一个“大”块。但是,如果允许大块,则内存将被分区为非常少的块。最好不要有一个大块,最好有两个较小的块,在少数需要的情况下合并在一起形成一个大块。因此,允许将两个块合并在一起。
为了保证速度,每个块都有一个标头,指示它是否可用并合并。对于合并的块,合并的同伴或“伙伴”的大小保留在标头中。这用于在这对夫妇被释放时快速恢复好友的标题。
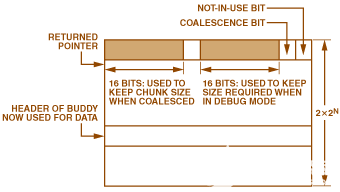
图4.ADIalloc 中的区块。
黑鳍金枪鱼特有的是什么
Blackfin为内存分配器增加了另一个维度:它的数据内存空间被划分为几个内存级别。内存级别在价格、速度和双访问可能性方面具有不同的特征:
外部存储器Lext体积大,使用成本更低,但访问延迟更高。
片上存储器L1具有快速访问功能。它本身分为不同的银行和子银行,允许从不同的子银行同时访问两项数据(双重访问)。
L2在价格和速度方面介于两者之间。但是,可以通过将其缓存到 L1 中来提高其速度。缓存是一个额外的维度。
堆叠。虽然(如前所述)在堆栈中分配所有变量不是一个好的解决方案,但仍然需要一个堆栈。对于小型缓冲区、循环计数器和索引,由于分配而丢失周期是没有意义的。然而,在系统集成阶段之前,某些缓冲区的分配(堆栈或动态)可能存在一些不确定性。这就是为什么堆栈被视为额外的内存级别。
缓存。如上所述,Blackfin可以将L2内存缓存到L1或L1的一部分中。在这种情况下,最好不必将分配器的代码重新调整到新的内存中。在初始化期间,分配器能够从一些专用的Blackfin寄存器中读取缓存配置,然后决定其箱和块。然而,由于分配器必须在任何平台上进行测试,因此它必须保持最低限度的Blackfin特异性。只有读取数据缓存配置是特定于 Blackfin 的。除此之外,分配器可以在带有Blackfin以外的编译器的PC上进行全面测试。唯一的区别是内存资源的选择与平台的速度或双访问功能无关。
凭借上述所有功能,ADIalloc成为一款重要的软件。因此,只要这不会过度影响循环次数,它应该尽可能“灵活”。
分配器的灵活性
宏。C宏广泛用于ADIalloc实现。事实上,ADIalloc本身就是一个宏。第一个好处是能够快速将一个分配器替换为另一个分配器,而无需重写调用 ADIalloc 的所有软件。例如,这可用于研究不同动态分配器的性能。
阿洛卡。宏的另一个优点是能够将 Stack 用作内存级别,而不必以比使用 malloc 更复杂的方式调用分配器。实际上,在 Stack 中分配无法通过函数调用来实现。相反,当使用 Stack 作为内存级别调用 ADIalloc 时,将执行“alloca”。(大多数编译器都提供 Alloca。它仅在执行 alloca 指令时保留堆栈上的空间 — 这与函数顶部的堆栈上的声明不同,后者为函数生存期保留空间。宏 ADIalloc 测试所需的内存级别,并将其重定向到分配器或对分配器的函数调用,ADI_alloc。
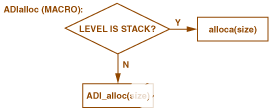
图5.通过 ADIalloc 进行堆栈分配。
存储所需的内存级别。能够处理Blackfin上的不同内存级别是一个非常大的优势。为了充分利用此功能,内存级别在编译时不是固定的。因此,对于每个分配,分配器允许测试不同的内存级别,而无需重写或重新编译软件模块的 C 代码。软件模块附带一个表,其中包含此类或此类分配所需的内存级别。表的内容可以在运行时更改,就像在特定地址写入新的所需内存级别一样简单。然而,应该注意的是,如果无法提供所需的内存级别,分配器会选择另一个级别 - 就内存访问速度而言最接近的级别。
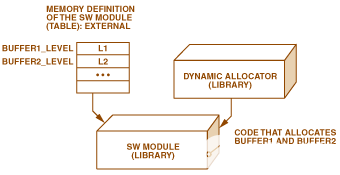
图6.输入表:所需的内存级别。
更改箱/块配置。ADIalloc的另一个灵活功能是能够更改箱和块配置,而无需重新编译分配器的代码。实际上,定义此配置的所有变量都保存在表中。在初始化期间读取表。可以随时更改表的内容,这将在下次调用初始化时修改 bins/chunks 配置。不必在编译时修复拆分的箱/块,作为下一个功能,可以在分配器周围有一个智能包装器来动态调整内存大小。我们还可以想到一个系统运行两个需要两种不同内存配置的连续任务。任务完成后,将使用最适合第二个任务的配置调用分配器初始化。
最后,ADIalloc有两种形式:第一种用于开发和集成,第二种用于最终产品。在开发过程中,调试功能是必需的。下一节将提供有关当前实现以及如何充分利用调试功能的更多详细信息。
调试功能如何改进实现
使用内存分配器时的常见问题是分配器导致的低效率以及未正确分配和释放内存的风险,主要导致内存泄漏。
分配器知道内存分区。它还知道请求的内存量以及哪些内存地址可用。这允许开发调试功能以采取措施避免内存泄漏。
跟踪已被遗忘的免费。内存泄漏的第一个原因是在分配了内存但从未释放时。这很容易预防。在调试模式下(不是在正常模式下,因为此测试需要许多周期),分配器会生成内存使用情况的统计信息。如果上一个报告显示某些内存空间仍在使用中,则表示已忘记空闲空间。为了更深入地跟踪问题,可以使用另一个报告,其中包含缓冲区名称,它们的地址,以及它们是否被释放或分配(每次调用分配器或free函数时都会生成报告)。
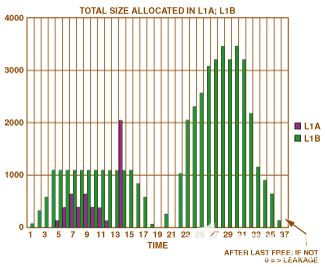
图7.如何跟踪已被遗忘的免费。
跟踪使用的空间是否超过保留的空间。另一种类型的泄漏发生在缓冲区分配的空间少于其所需空间,并开始使用已分配给它的空间之外的空间时。在调试模式下,分配器使用特殊代码(该代码成为“真实”基准面的可能性非常低)“标记”所有可用内存空间。它不仅标记空闲块,而且还包括分配不需要的块中的所有地址。在每个分配的块中,所需的大小也保留为分配的块的一部分。因此,每次输入分配器(对于新分配或免费分配)时,它都会验证:
免费块仅包含特殊代码
分配的块包含所需大小和块末尾之间的特殊代码
执行此检查的函数也可以在分配器外部随时调用。当发现泄漏时,将生成消息并将其传递到另一个模块,该模块以一种或另一种形式输出(屏幕,特殊的可视化工具,用于实时分析的高速记录器等)。

图8.用于跟踪分配器消息的查看器示例(泄漏情况)。
帮助选择箱/块配置。分配器调试功能还可以部分解决有关分配器效率低下的问题。在调试模式下,分配器保存诸如所需内存与分配的内存、每个箱使用的块数等数据。这提供了一种简单的方法来避免效率低下,例如使用一些从未使用的箱大小。
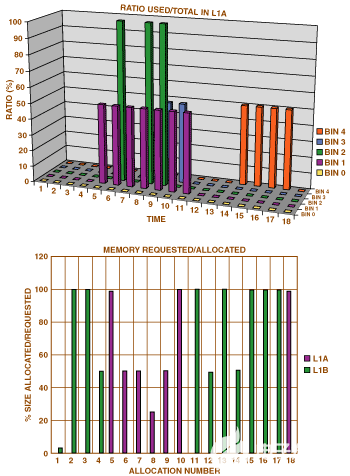
图9.捕获的数据有助于选择最佳箱/块配置。
内存级别之间的内存重新分区。一个很大的问题是如何在不同的软件之间分配内存级别。显然,快速存取存储器最适合每一段代码。然而,由于这种记忆是有限的,因此必须做出选择。只有在将整个软件模块内置到系统中后,才能做出此选择。通常,时间关键型任务需要最快的内存。分配器可以协助做出此类选择。
分配器更加有用,因为它可以与包装器一起交付,该包装器负责为特定模块运行所有可能的内存配置,同时节省所需的周期数。这有助于了解无法为特定缓冲区获得最快内存对周期的影响。
表一. 业绩汇总表
| 表中的索引 | L1_B | 通过/失败 | L2 | 通过/失败 | 莱克斯特 | 通过/失败 |
| p通道实例 | -82 |
通过 |
-71 |
通过 |
-119 | 通过 |
|
pSharedMemStruct |
-73 |
通过 |
-66 |
通过 |
-109 |
通过 |
|
pShared_BurstDec_CCDec_Interleave |
94 |
通过 |
56 |
通过 |
-48 |
通过 |
|
pShared_EQ_CCDec_Mod_Info |
5 |
通过 |
-81 |
通过 |
-67 |
通过 |
|
CC_Dec_IO_EDGE_PDTCH |
130* |
通过 |
-74 |
通过 |
-324 |
通过 |
| p去交错 | -232 |
通过 |
-57 |
通过 |
18115 |
通过 |
| pOutHeader | 15 |
通过 |
-116 |
通过 |
506 |
通过 |
| pScratch_Header_Decoder | -281 |
通过 |
- 83 |
通过 |
3719 |
通过 |
| 度量 | -82 |
通过 |
10440 |
通过 |
123346 |
通过 |
| pPathMetric | -417 |
通过 |
-84 |
通过 |
77394 |
通过 |
| pOutRLC_Data | -199 |
通过 |
-83 |
通过 |
1832 |
通过 |
| pScratch_Data_Decoder | -75 |
通过 |
450 |
通过 |
23624 |
通过 |
表中显示的数字表示与参考配置相比,在新配置中运行单元测试所需的周期数的差异。参考配置是模块编写器默认提供的配置。PASS 表示对新配置运行单元测试的结果与运行引用配置的结果相同。参考循环次数为:128078。
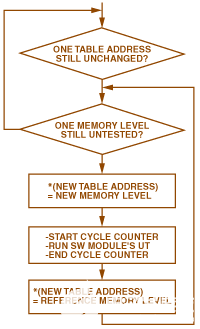
图 10.单元测试流程图。
包装器运行软件模块单元测试 (UT)。第一次运行它时,要求分配器返回指针的名称以及它查找内存级别的表的地址。收集需要查找内存级别的所有地址后,包装器会针对所有可能的内存配置重新运行 UT。
结论
当前的ADIalloc实现是动态内存分配器的一种可能实现。它的使用表明,当前实现最有用的功能是调试功能。它们减少了与动态分配相关的风险(特别是渗漏的风险)。同时,它们有助于更好地管理复杂的内存结构。现在,在手机应用程序中,在Blackfin中添加新的软件模块变得更加容易,而无需重新设计模块之间的内存划分。
审核编辑:郭婷
-
处理器
+关注
关注
68文章
19076浏览量
228679 -
dsp
+关注
关注
552文章
7955浏览量
347798 -
存储器
+关注
关注
38文章
7413浏览量
163465
发布评论请先 登录
相关推荐
动态内存管理模块的设计原理与实现
使用C语言实现简单动态内存分配
内存的动态内存分配实现
嵌入式C语言动态内存分配
请问使用动态内存分配安全吗?
使用动态内存分配安全吗
RTThread的动态内存空间该如何去分配呢
动态内存错误的静态检测






 工商网监
工商网监
评论