 有了Fine-tune-CoT方法,小模型也能做推理,完美逆袭大模型
有了Fine-tune-CoT方法,小模型也能做推理,完美逆袭大模型
大型语言模型可以用来教小得多的学生模型如何进行一步一步地推理。本文方法显著提高了小型 (~0.3B 参数) 模型在一系列任务上的性能,在许多情况下甚至可以达到或超过大型模型的性能。
语言模型(LMs)在各种下游任务中表现出色,这主要归功于它们通过 Transformer 架构(Vaswani et al.,2017)和大量网络训练数据获得的可扩展性。先前的语言模型研究遵循了在大型语料库上预先训练,然后在下游任务上微调的范式(Raffel et al.,2020; Devlin et al.,2018)。最近,大型语言模型(LLMs)向人们展示了其上下文泛化能力:通过仅在几个上下文样例或纯自然语言任务描述上调整就能完成下游任务(Brown et al.,2020; Sun et al.,2021)。
如果给语言模型生成一些 prompting,它还向人们展示了其解决复杂任务的能力。标准 prompting 方法,即为使用少样本的问答对或零样本的指令的一系列方法,已经被证明不足以解决需要多个推理步骤的下游任务(Chowdhery 等,2022)。
但是,最近的研究已经证明,通过包含少数思维链(CoT)推理的样本(Wang 等,2022b)或通过 promp 来让模型逐步思考的方法(Kojima 等,2022)可以在大型语言模型中促成复杂的推理能力。
基于 promp 的思维链方法的主要缺点是它需要依赖于拥有数十亿参数的巨大语言模型(Wei et al,2022b;Kojima et al,2022)。由于计算要求和推理成本过于庞大,这些模型难以大规模部署(Wei et al,2022b)。因此,来自韩国科学技术院的研究者努力使小型模型能够进行复杂的推理,以用于实际应用。
有鉴于此,本文提出了一种名为微调思维链的方法,该方法旨在利用非常大的语言模型的思维链推理能力来指导小模型解决复杂任务。

论文链接:https://arxiv.org/pdf/2212.10071.pdf
项目地址:https://github.com/itsnamgyu/reasoning-teacher
为了详细说明,本文应用现有的零样本思维链 prompting(Kojima 等人,2022)从非常大的教师模型中生成推理,并使用它们来微调较小的学生模型。
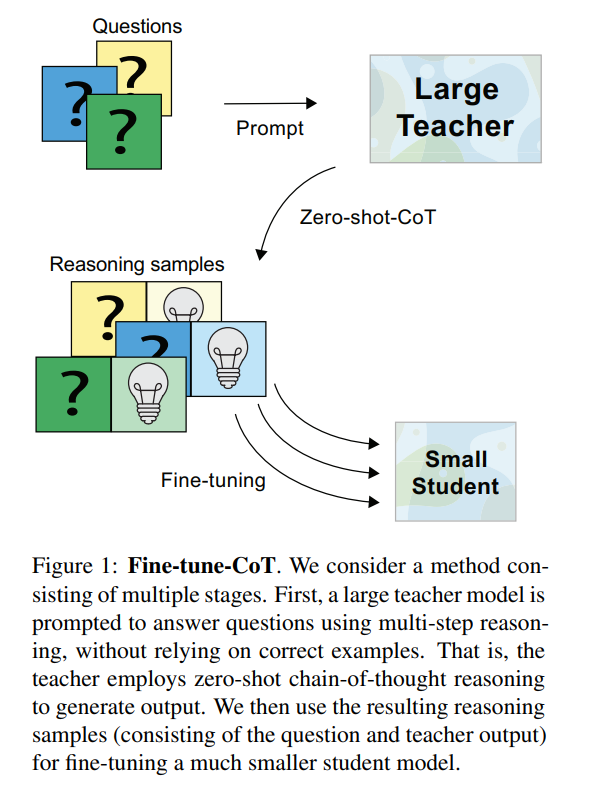
研究者注意到,与标准的 prompting 类似,对于训练语言模型来解决复杂推理的任务来说,纯微调往往是不够的。虽然已经有人尝试用规定好的推理步骤对小模型进行微调来解决这个问题,但这些方法需要巨量的推理注释,而且往往还需要与特定任务匹配的训练设置(Nye 等人,2021;Cobbe 等人,2021)。
本文提出的方法,由于基于语言模型的教师具有显著的零样本推理能力(Kojima 等人,2022),无需手工制作推理注释及特定任务设置,可以很容易地应用于新的下游任务。从本质上讲,本文的方法保留了基于 prompting 的思维链的多功能性,同时模型规模还不是很大。
研究者还对本文中的方法提出了一种扩展,称为多样化推理,这种扩展方法通过为每个训练样本生成多个推理方案来最大限度地提高对思维链进行微调的教学效果。具体来说可以通过简单的重复随机抽样来实现。多样化推理的动机是,多种推理路径可以用来解决复杂的第二类任务(Evans, 2010)。本文认为,这种推理路径的多样性以及语言模板的加入可以大大有助于复杂推理的微调。
本文使用公开的 GPT-3 模型对思维链微调和各类任务及规模的多样化推理进行了实证评估。本文提出的微调方法在复杂任务的小模型中具备明显的推理性能,而以前基于 prompting 的方法则只具有接近随机的性能。
本文表明,在思维链微调方法下的小模型在某些任务中的表现甚至超过了它们的大模型老师。通过多样化的推理,研究者发现维链微调方法的性能是高度可扩展的,并且即使在很少的训练例子中也能具备较高的样本效率和显著的推理性能。研究者对思维链微调方法在众多数据集上的表现进行了彻底的样本研究和消融实验,在小模型上证明了其价值。在此过程中,本文揭示了微调在思维链推理中前作没有被考虑到的一些重要细微差别。
方法概览
本文提出了思维链微调方法,这是一种与下游任务无关的方法,可以在小型语言模型中实现思维链推理。该方法的核心思想是使用基于 prompting 的思维链方法从非常大的教师模型中生成推理样本,然后使用生成的样本对小型学生模型进行微调。
这种方法保留了任务无偏的基于 prompt 思维链方法的优点,同时克服了其对过大模型的依赖性。为了最大限度地提高通用性,本文在教师模型上使用了最新的零样本思维链 prompting 方法(Kojima 等人,2022),因为此方法不需要任何手工注释的推理解释。作者注意到,本文提出的方法其实并不限于这种教师模型的 prompting 方式。文本将思维链微调方法拆解为三个步骤,如下图所示。
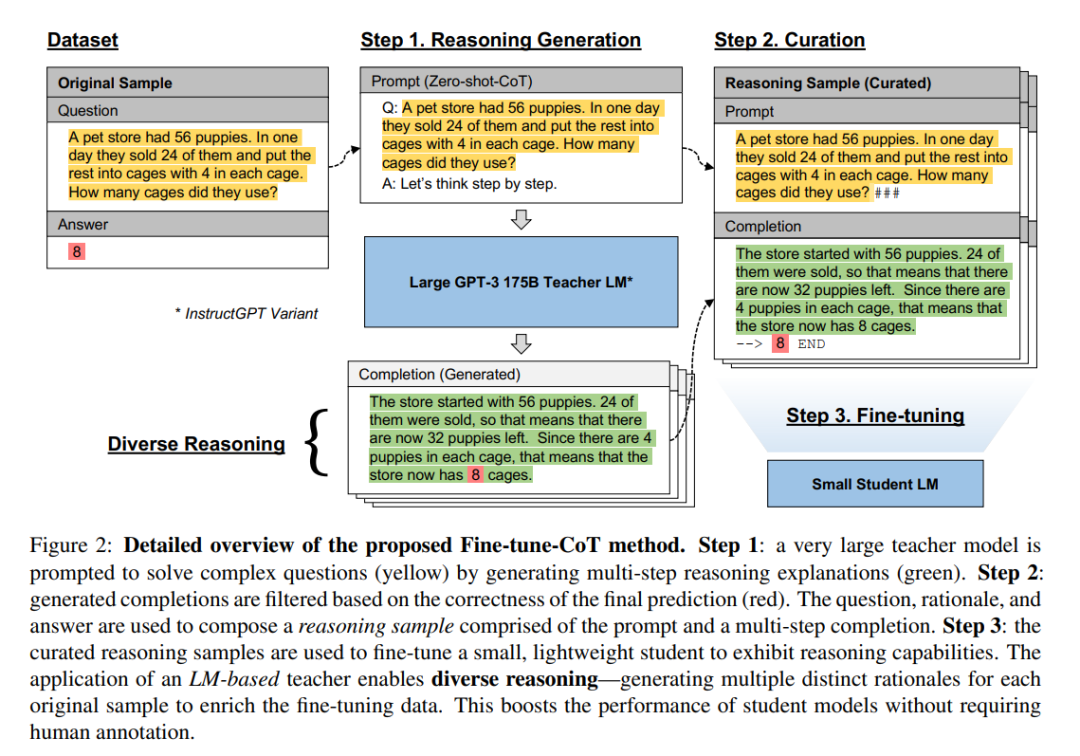
步骤 1—— 推理生成
首先,本文利用一个大型的教师模型来为一个给定的任务生成思维链推理解释。本文定义一个由问题 Q^i 和其真实答案 a^i 组成为一个标准样本 S^i,然后使用零样本思维链来为教师模型生成一个推理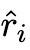 来解决问题 q^i,并生成最终的答案预测
来解决问题 q^i,并生成最终的答案预测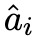 。由此产生的文本序列,包括 prompt 和生成结果,均采取以下形式
。由此产生的文本序列,包括 prompt 和生成结果,均采取以下形式
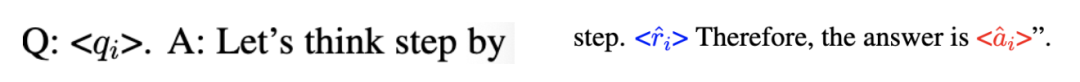
第 2 步 —— 整理
为了制备用于微调的样本,本文对生成的样本进行了过滤,并将其重新格式化为 prompt-completion 形式的成对数据。对于过滤,本文将教师模型的最终预测值与真实答案 a^i 进行比较,这与之前的一些工作是相同的(Zelikman 等人,2022;Huang 等人,2022)。对于所有这样的实例 i,本文将(S_i , , )重新打包成一个推理样本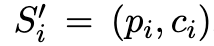 ,也就是一个 prompt-completion 形式的成对数据。由于本文提出的方法旨在为特定任务训练高效的模型,所以使用基于特殊字符的文本格式来尽量减少标记的使用。具体来说,p_i 采用「
,也就是一个 prompt-completion 形式的成对数据。由于本文提出的方法旨在为特定任务训练高效的模型,所以使用基于特殊字符的文本格式来尽量减少标记的使用。具体来说,p_i 采用「
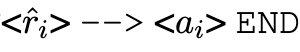
的形式。作者注意到,基于答案预测的过滤并不能确保推理的正确性,特别是对于可能出现随机猜测的多选题。遗憾的是,以前的工作中这个问题还没有得到解决。
步骤 3—— 微调
最后,本文使用开源的 OpenAI API 在集成的推理样本上对一个小型的预训练学生模型进行微调。本文使用与预训练时相同的训练目标,即自回归语言建模目标,或者用 token 预测(Radford 等人,2018)。
多样化推理
为了最大限度地提高思维链微调方法的对样本的使用效率,本文提出可以为每个训练样本生成多种推理解释,从而增强微调数据。本文将此称为多样化推理。详细来说,对于一个给定的样本 S_i,本文不是采用贪心解码策略的零样本思维链方法来获得单一的「解释 — 答案」形式的成对数据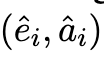 ,而是采用随机抽样策略,即用 T 代表温度抽样,然后获得 D 批不同的生成数据
,而是采用随机抽样策略,即用 T 代表温度抽样,然后获得 D 批不同的生成数据
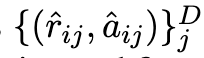
。随后对推理样本整理和微调工作就像上面一样进行。本文把 D 称为推理的多样性程度。多样化推理的动机是,多种推理路径可以用来解决复杂的任务,即第二类任务(Evans, 2010)。
在样本研究中,研究者确认多样化推理样本包含各种推理路径以及语言模板,这一点也可以在细化的学生模型中观察到。这与 Wang 等人(2022b);Zelikman 等人(2022);Huang 等人(2022)的成果类似,多样化推理路径被生成并被边缘化以找到最优答案。多样化推理也与 Yoo 等人(2021)有相似之处,后者利用大模型语言模型的生成能力,合成的样本来增加训练数据。
实验结果
下表将思维链微调方法的学生模型,与现有的对下游任务不敏感的方法 —— 零样本学习(Kojima 等人,2022)以及标准的零样本 prompt 和没有任何推理的微调方法进行对比,并记录了准确率。
思维链微调在相同的任务中性能明显更突出,这显示出使用较小的模型比零样本思维链方法收益更大。
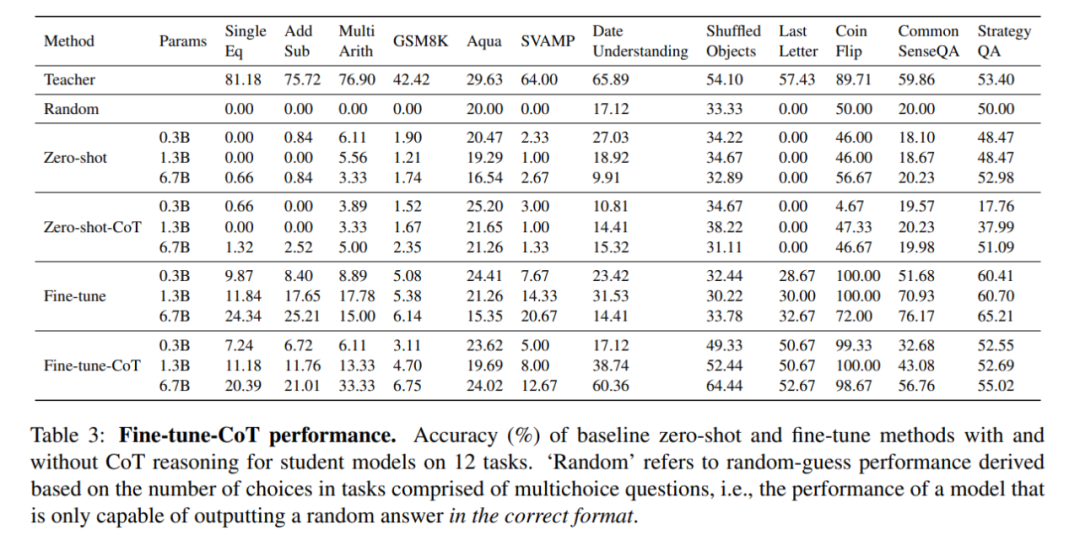
上表还显示,思维链微调对小模型非常有效。同样地,本文还发现思维链微调在很多任务中的表现优于 vanilla 微调,如上表所示。
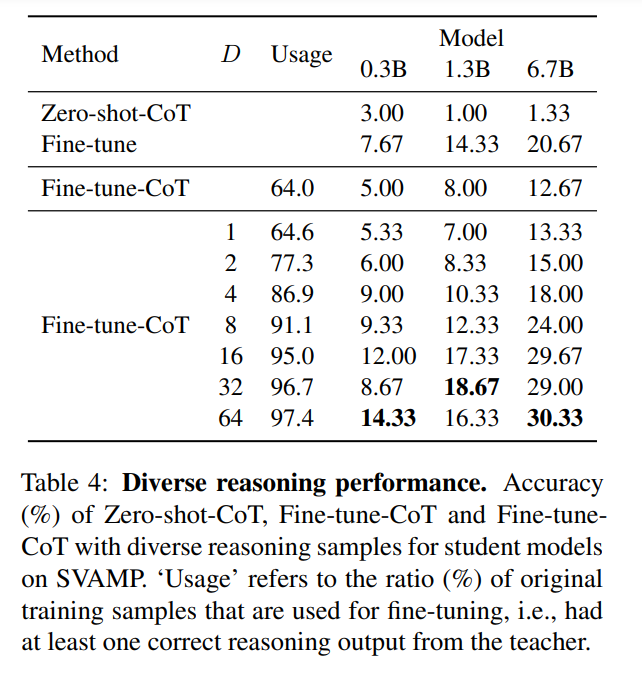
下表显示,多样化的推理可以显著提高使用思维链微调的学生模型的性能。
审核编辑 :李倩
-
模型
+关注
关注
1文章
3374浏览量
49320 -
语言模型
+关注
关注
0文章
545浏览量
10358 -
大模型
+关注
关注
2文章
2660浏览量
3273
原文标题:有了Fine-tune-CoT方法,小模型也能做推理,完美逆袭大模型
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【大语言模型:原理与工程实践】揭开大语言模型的面纱
【大语言模型:原理与工程实践】大语言模型的应用
基于LS-SVM逆模型的青霉素发酵软测量方法
用tflite接口调用tensorflow模型进行推理
【飞凌RK3568开发板试用体验】RKNN模型推理测试
压缩模型会加速推理吗?
HarmonyOS:使用MindSpore Lite引擎进行模型推理
全新科学问答数据集ScienceQA让深度学习模型推理有了思维链
LLM大模型推理加速的关键技术
Google Gemma 2模型的部署和Fine-Tune演示
FPGA和ASIC在大模型推理加速中的应用







 工商网监
工商网监
评论