 内存带宽瓶颈如何破?
内存带宽瓶颈如何破?
内存带宽是当下阻碍某些应用程序性能的亟需解决的问题,现在你可以通过地选择芯片来调整 CPU 内核与内存带宽的比率,并且您可以依靠芯片制造商和系统构建商进一步推动它。
如果 CPU 在内存带宽和某些情况下的内存容量方面不受限制,那么考虑一下 HPC 和 AI 计算会是什么样子是很有趣的。或者更准确地说,如果内存相对于计算而言不是那么昂贵。或许,我们可以对前者做点什么,我们会脸色发青,也许会死于等待对后者发生的事情,正如我们上周简要谈到的那样。
有时候,你所能做的就是做一个止血带,即使你不能立即永久性地解决手头的问题,也要试着继续运动。或者脚,或者伤口所在的地方。这让我们思考,现在的服务器购买者如何通过服务器CPU和系统制造商的一些适度调整,至少可以使每个核心的内存带宽更加平衡。
正如去年的图灵奖得主、行业名人Jack Dongarra在主题演讲中恰当地指出的那样,几十年来,情况一年比一年糟糕。
我们考虑这个问题已经有一段时间了,早在 2019 年 8 月,IBM 就对 Power10 处理器进行了预览,并且预期(但从未交付过)高带宽 Power9'——这是 Power9 “prime”,而不是打字错误——系统蓝色巨人在 2019 年 10 月与我们谈到了我们对具有高内存带宽的系统的兴趣。(我们称它为 Power E955,这样它就有了一个名字,尽管它从未推出过。)IBM 展示了它的 OpenCAPI 内存接口 (OMI) 以及它随 Power10 机器一起提供的内存,但这张图表概括了 IBM 的内容相信它可以在各种技术的电源芯片插座上做:
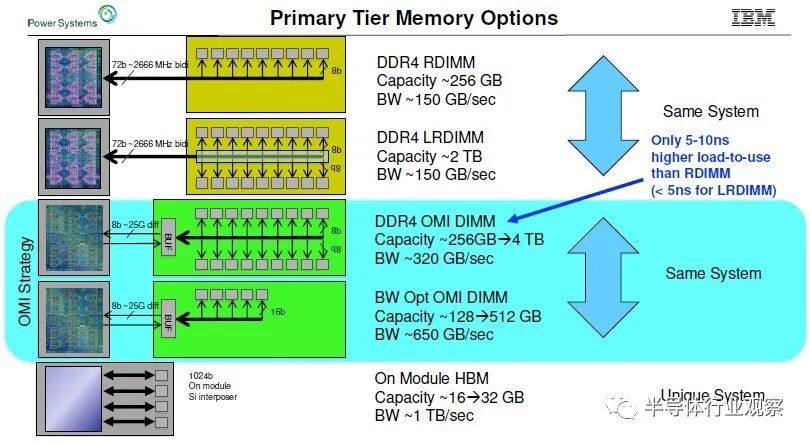
IBM 的 OMI 差分 DDR 内存,它使用串行接口和 SerDes,本质上与处理器上用于 NUMA、NVLink 和 OpenCAPI 端口的“Bluelink”信号相同,与普通的并行 DDR4 接口有很大不同,具体DDR 协议,无论是 DDR4 还是 DDR5,都位于存储卡上的缓冲芯片上,而从存储卡到 CPU 的接口是一种更通用的 OMI 协议。
这种早在 2019 年就在开发中的 OMI 内存提供了大约 320 GB/秒的每个插槽和从 256 GB 到 4 TB 的每个插槽的容量。通过带宽优化版本,将内存模块数量减少四分之一,并为每个插槽提供 128 GB 至 512 GB 的 DDR4 容量,IBM 可以将 Power9 芯片上的内存带宽提高到 650 GB/秒,并且借助预计在 2021 年推出的 Power10 服务器,它可以使用时钟速度更快的 DDR5 内存将速度提高到 800 GB/秒。
同时,对于预计在 2020 年交付的 Power9 系统,IBM 估计如果它使用 HBM2 堆叠内存,它可以提供 16 GB 到 32 GB 的容量,并提供大约 1 TB/秒的每个插槽带宽。这是每个插槽的大量内存带宽,但内存容量并不是很大。
无论出于何种原因——我们认为无论它们是什么,它们都不是好产品,但这可能与蓝色巨人与当时的代工合作伙伴 Globalfoundries 的技术和法律困难有关——Power9 系统,很可能是四路机器每个插座中都带有双芯片模块,从未面世。
但早在 2022 年 7 月,“带宽野兽”的想法就被重新命名为 Power E1050,作为 Power10 中端系统阵容的一部分。
当“Cirrus”Power10 处理器规格于 2020 年 8 月公布时,IBM 表示该芯片每个内核的峰值内存带宽为 256 GB/秒,每个内核的持续内存带宽为 120 GB/秒。Power10 芯片上有 16 个内核,但为了在 IBM 的新代工合作伙伴三星的 7 纳米工艺上获得更好的产量,最多只有 15 个内核处于活动状态。关于去年 7 月推出的入门级和中端 Power10 机器、4、8、10 和 12 核在 SKU 堆栈中可用,而 15 核变体仅在可扩展到 16 插槽的高端“Denali”Power E1080 系统中可用。目前尚不清楚这些峰值和持续内存带宽数据是否适用于 DDR5 内存,但我们怀疑是这样。IBM 确实交付了使用基于 DDR4 内存的 OMI 内存的 Power E1050(和其他 Power10 机器),并在其演示中表示配备 DDR5 内存的 Power10 的内存流性能将是 DDR4 内存的 2 倍。
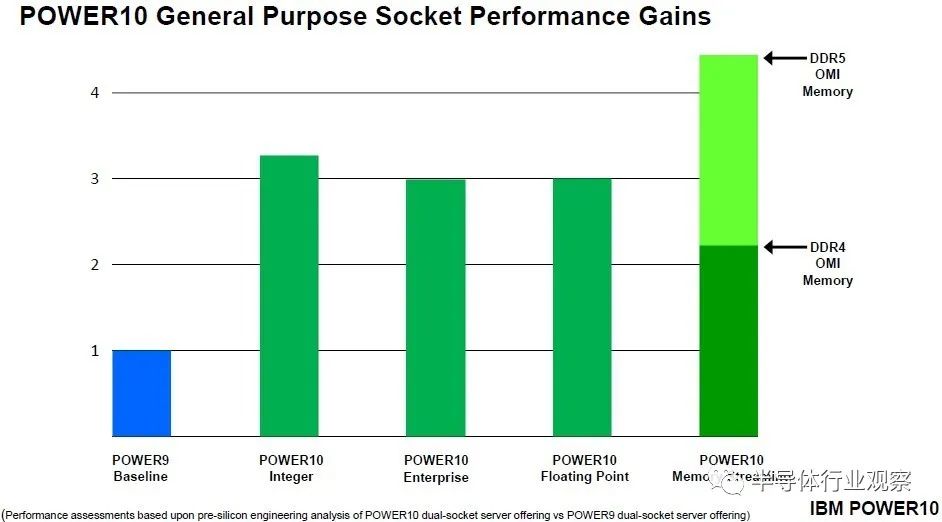
以上比较针对的是单芯片 Power10 模块。对于双芯片模块,将它们加倍,然后针对保持在与单芯片模块相同的热包络内所需的降档时钟速度进行调整。
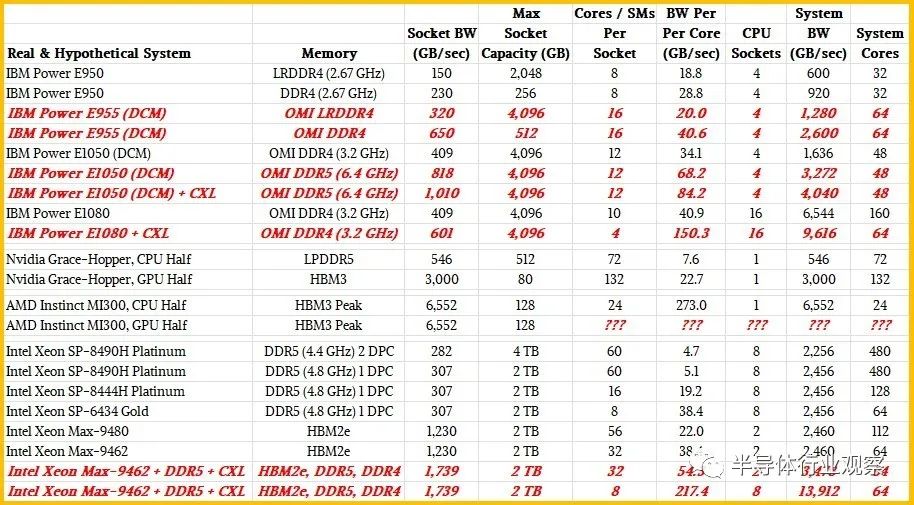
采用 Power E1050 机器,服务器最多有四个 Power10 DCM,总共有 96 个核心。这八个小芯片共有八个 OMI 内存控制器,支持多达 64 个差分 DIMM,DDR4 内存运行频率为 3.2 GHz,并在内核之间提供 1.6 TB/秒的总带宽。也就是说,在系统中 96 个核心的峰值时,每个 Power10 核心的内存带宽为 17 GB/秒。
首先,让我们回到核心技术。Power E1050的臃肿配置使用了12核Power10芯片,但有一款48核的改型只使用了6核芯片。(是的,Power10内核的成品率只有37.5%。)这使得每核带宽翻了一番,达到34 GB/秒。如果你改用运行在6.4 GHz的DDR5内存,这是昂贵的,而且价格并不合理,那么你可以获得每核高达68 GB/秒的内存带宽。
现在,理论上,如果CXL内存扩展器可用,您可以进一步推动这个真正的Power E1050,您可以在CXL内存上的每个插槽消耗PCI-Express 5.0带宽的56个通道中的48个,添加6个x8 CXL内存扩展器,每个扩展器以32 GB/秒的速度产生另外192 GB/秒的内存带宽(当然,还有一些附加延迟)。这使得你的总带宽达到1.8 TB/秒,每核带宽达到38 GB/秒。如果IBM使每个Power10芯片上的内核数更小,那么每个内核的内存带宽就可以调高。如果每个芯片有4个内核,每个系统有32个内核,那么每个内核的内存带宽最高可达57.1 GB/秒。转到DDR5内存+ CXL内存,每个核心可以达到84 GB/秒。
01进入混合计算引擎
请注意,没有人说这很便宜。但对于某些工作负载,这可能是一个比将代码移植到GPU或等待CPU-GPU混合计算引擎(AMD的Instinct MI300A, Nvidia的Grace-Hopper, Intel的Falcon Shores)上市更好的答案。虽然这些处理器每个核心都有很高的内存带宽,但内存容量将受到限制,因此比IBM Power10和英特尔“Sapphire Rapids”Max系列CPU(混合HBM 2e/DDR5内存)的性能要有限得多。
英伟达Grace芯片拥有72个核心和16组LPDDR5内存,总容量为512 GB,每个插槽的内存为546 GB/秒。计算出来每个核的内存带宽为7.6 GB/秒。Hopper GPU拥有132个流多处理器(相当于CPU的核心),其HBM3堆叠内存的带宽最高可达3000 GB/秒。(在H100加速器上,有5个堆栈产出80gb。)计算出来,每个GPU“核心”的带宽为22.7 GB/秒,这只是给你一个参考框架。如果您将Grace上的所有LPDDR5内存视为一种类似cxl的内存,则可以将CPU-GPU复合物的内存容量提高到总共592 GB,并将聚合内存带宽提高到3,536 GB/秒。根据您的意愿在该综合体中分配核心和SMs。您可以将GPU视为CPU核心的非常昂贵的快速内存加速器,计算出每个Grace核心的内存带宽为49.3 GB/秒,每个Hopper SM的内存带宽为26.9 GB/秒。
上面提到的Power10系统就在这个范围内,没有太多的工程方法。
对于AMD Instinct MI300A,我们知道它有128 GB的HBM3堆叠内存,分布在8个组、6个GPU和2个12核Epyc 9004 CPU芯片上,但我们不知道带宽,也不知道MI300A包上的6个GPU芯片集合上的短信数量。我们可以对带宽做一个有根据的猜测。HBM3以每引脚6.4 Gb/秒的速度运行信令,最多可达16个通道。根据堆叠的DRAM芯片数量(从4个到16个)和它们的容量(每个堆栈从4 GB到64 GB),您可以获得不同的容量和带宽。
使用16 Gb DRAM,最初的HBM3堆栈预计每个堆栈提供819 Gb /秒的带宽。看起来AMD可能会使用8个16gb芯片堆栈,每个堆栈有8个芯片,这将提供128 Gb的容量,并将产生6552 Gb /秒的总带宽,以去年4月HBM3规范宣布时的预期速度。我们认为MI300A封装上的Epyc 9004芯片有16个内核,但其中只有12个用于提高产量和可能的时钟速度,当这些Epyc内核达到HBM3内存时,每个内核的内存带宽将达到惊人的273 GB/秒。
很难说这六个GPU芯片上有多少短信,但与之前的AMD和Nvidia GPU加速器相比,每条短信的带宽可能会非常高。但是,同样,每个计算引擎的总内存为128 GB并不是很大的容量。
而且,为了抑制我们的热情,由于热的原因,AMD可能不得不削减DRAM堆栈和/或HBM3内存速度,因此可能达不到我们预期的带宽数字。即使是每个CPU核心带宽的一半,这也会令人印象深刻。同样,对于只使用cpu的应用程序,GPU是一个非常昂贵的附加组件。
任何CXL内存可能挂在这个处理器上以增加额外的容量,这将在这方面有所帮助,但不会对每个核心或SM的带宽增加太多。
我们对未来的英特尔猎鹰海岸CPU-GPU混合处理器的了解还不够多,根本无法进行任何计算。
02在CPU和NUMA拯救HBM吗?
这让我们想到了英特尔的蓝宝石Rapids与HBM2e内存,它也有一种模式,同时支持HBM2e和DDR5内存。我们之所以对Sapphire Rapids感兴趣,不仅是因为它在某些变体中支持HBM2e堆叠内存,还因为它在其他变体中也具有八路NUMA可伸缩性。
我们认为可以允许创建一个八路,hbm功能的系统,同时使用DDR5和CXL主存。让我们从头开始,从普通的Sapphire Rapids Xeon SP CPU开始。
据我们所能估计,Sapphire Rapids Xeon SP上的8个DDR5内存通道可以在一个插座上提供略高于307 GB/秒的内存带宽。如果每个通道有一个DIMM,运行频率为4.8 GHz,则最大容量为2tb。使用每个通道两个内存,每个插槽的容量可以翻倍,达到4 TB,但运行速度较慢的4.4 GHz,每个插槽只能产生282 GB/秒的内存带宽。(后一种情况是内存容量大,而不是内存带宽大。)在Xeon SP-8490H上,每个通道有一个内存,60个内核运行在1.9 GHz,计算出来每个内核的带宽只有5.1 GB/秒。如果你使用Xeon SP-8444H处理器,它只有16个核心,但运行在更高的2.9 GHz,所以你可以恢复掉核时失去的一些性能,每个核心的带宽为19.2 GB/秒。
好吧,如果你想提高插座上每个核心的内存带宽,你可以切换到Xeon SP-6434,它有8个内核,运行频率为3.7 GHz。在4.8 GHz DDR5速度下,每核带宽将增加一倍,达到38.4 GB/秒。这个处理器上活动的UPI链路少了一个,因此双插座服务器上的耦合效率会低一些,而且延迟和带宽也会低一些。这与使用3.2 GHz DDR4内存的六核Power10芯片大致相同,类似于Grace Arm服务器CPU上的每个核从其本地LPDDR5内存中看到的情况。
现在,让我们谈谈蓝宝石急流HBM变体。顶部的bin Max系列CPU有56个核,四个HBM2e堆栈有64gb的容量和1230gb /秒的总带宽。计算出来,每个核的内存带宽为22 GB/秒。低仓部分有32个核,相同的1230 GB/秒内存,或每个核38 GB/秒。如果在插座上添加DDR5内存,则可以再增加307 GB/秒,如果添加CXL内存扩展器,则可以再增加192 GB/秒。所以现在32个核心的内存总量达到了1729 GB/秒,也就是54 GB/秒。
现在,让我们将其发挥到极致,利用NUMA互连将8个Sapphire Rapids HBM插座(英特尔不允许这样做)连接在一起,并将每个插座在4 GHz下运行的内核数降至8个内核。这将产生64个运行频率为4 GHz的内核,比蓝宝石Rapids 60核至强SP-8490H更具魅力。但是现在,将HBM、DDR5和CXL内存全部添加进来后,这8个插槽的内存带宽总计为13,912 GB/秒,每个核的总带宽为217.4 GB/秒。
我们确信,这不会是一个便宜的盒子。但话说回来,Power E1050也不是。
如果IBM将Power E1080的核心拨下来,并添加CXL扩展器,它可以通过16个插槽获得一些东西,这将是连接到这16个插槽的OMI内存的6544 GB/秒,再加上PCI-Express 5.0总线上的6个CXL内存模块的3,072 GB/秒,总共9,616 GB/秒。你想要多少核?每个Power10 SCM有4个内核,即64个内核,计算出来每个内核的主存带宽为150 GB/秒。
关键是,有一种方法可以构建专注于每个核心更好的内存带宽的服务器节点,因此适合加速某些类型的HPC和分析工作负载,甚至可能是部分AI训练工作负载。你的计算能力会比内存容量或内存带宽的限制更大,你必须非常小心,不要因为没有足够的内核从内存中提取数据和向内存中插入数据而使昂贵的内存负担过重。
顺便说一下,我们不太确定这种带宽野兽方法如何加速人工智能训练——也许只在预训练的模型上进行修剪和调整。我们有一种预感,即使是GPU在GPU核心时延和附加的HBM2e和HBM3堆叠内存带宽之间也存在不平衡,因此它们无法在接近峰值计算效率的任何地方运行。
我们充分认识到,这一切都不便宜。但GPU加速的机器也不是。但是,对于某些工作负载来说,更好地平衡计算、内存带宽和内存容量可能比将内存分割成碎片并将数据集分散到几十个CPU上更好。不可否认,您确实需要以不同的方式加速这些工作负载——并跨内存层次结构对它们进行编程——以突破极限。
这就是思想实验的作用。
审核编辑:刘清
-
处理器
+关注
关注
68文章
19471浏览量
231468 -
IBM
+关注
关注
3文章
1777浏览量
74936 -
DDR
+关注
关注
11文章
717浏览量
65631 -
HPC
+关注
关注
0文章
327浏览量
23886 -
电源芯片
+关注
关注
43文章
1106浏览量
77345
原文标题:内存带宽瓶颈如何破?IBM的方法!
文章出处:【微信号:算力基建,微信公众号:算力基建】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
内存扩展CXL加速发展,繁荣AI存储

使用 Memtester 对华为云 X 实例进行内存性能测试

南亚科技与补丁科技携手开发定制超高带宽内存
固定带宽与动态带宽的区别
HBM4需求激增,英伟达与SK海力士携手加速高带宽内存技术革新
前端总线与内存频率怎么配
正常音量信号输入tas5548后破音的原因?怎么解决?
三星电子突破瓶颈,HBM3e内存芯片获英伟达质量认证
成都汇阳投资关于跨越带宽增长极限,HBM 赋能AI新纪元
集成32GB HBM2e内存,AMD Alveo V80加速卡助力传感器处理、存储压缩等

NuLink PHY技术:突破计算芯片内存瓶颈






 工商网监
工商网监
评论