 DPU发展面临的困境和机遇
DPU发展面临的困境和机遇
编者按
有一些投资人认为,DPU赛道比较鸡肋:CPU/GPU同量级的高投入,但市场规模却不大。并且因为DPU跟用户的业务休戚相关,很多用户倾向自研,这进一步导致公开市场规模更加有限。
即使强如NVIDIA,其DPU已经发布两年左右,目前仍没有用户真正大规模采用。这里面存在的问题到底是什么?有没有破解之道?
这篇文章会对DPU发展过程中存在的问题进行细致分析,抛砖引玉,期待更优的、可大范围落地的创新型产品出现。
更本质的,DPU是在目前算力困境的大背景下产生的,预示着一个新的算力时代的到来。行业需要更多的技术创新,更好的服务 “东数西算”国家大战略和数字经济发展。
1 DPU发展面临的困境
1.1 芯片研发成本高昂
摩尔定律预示了:芯片工艺的发展,会使得晶体管数量大约每两年提升一倍。虽然工艺的进步逐步进入瓶颈,但Chiplet越来越成为行业发展的重点,这使得芯片的晶体管数量可以再一次数量级的提升。
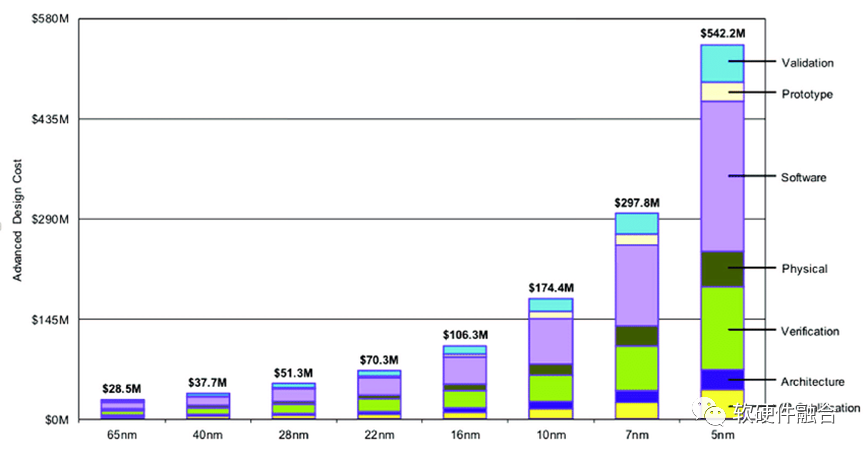
在先进工艺的设计成本方面,知名半导体研究机构Semiengingeering统计了不同工艺下芯片所需费用(费用包括了):
28nm节点开发芯片只需要5130万美元;
16nm节点则需要1亿美元;
7nm节点需要2.97亿美元;
到了5nm节点,费用高达5.42亿美元;
3nm节点的研发费用,预计将接近10亿美元。
就意味着,大芯片需要足够通用,足够大范围落地,才能在商业逻辑上成立。做一个基本的估算:
终端场景,(大)芯片的销售量至少需要达到数千万级才能有效摊薄一次性的研发成本;
在数据中心场景,则需要50万甚至100万以上的销售量,才能有效摊薄研发成本。
并且,在研发方面的投入,DPU相比CPU、GPU还要更高:
开发DPU芯片,不但需要高性能CPU IP、高性能总线IP,还包括高速PCIe、Ethernet以及DDR/HBM等;
还需要开发非常多的、并且开发难度也非常高的各类加速引擎,如网络协议处理加速引擎、高性能网络加速引擎、存储加速引擎、各类安全加速引擎等;
还需要把IaaS等很多上层的软件服务融入到芯片的软硬件方案中,并且需要跟不同用户的不同场景进行对接。
1.2 多领域场景需求

CPU性能瓶颈之后,传统在CPU侧软件运行的工作任务,很多会沉淀到硬件去加速。这样,就需要有一个平台来承载这些加速,而DPU就是这个承载各类加速的芯片平台。
CPU通过标准ISA实现软硬件解耦,CPU引擎也就只有一类,CPU设计工程师可以不用太过关心具体的需求,而只需要关注具体的CPU设计即可。
GPU也通过CUDA以及GPGPU架构实现了软硬件解耦,GPU引擎也只有一类,并且 GPU的设计工程师也是只需要把重心放在GPU的具体设计中。
跟CPU和GPU的设计相比,DPU有如下两个难点:
多场景,挑战更大。相比CPU和GPU的单个引擎类型,DPU的处理引擎(或者说涉及的领域/场景)会有很多,如基础设施层的虚拟化、网络、存储、安全等的处理引擎,以及各类开发库、文件系统、数据库、网络访问等的处理引擎。
场景的软硬件解耦难度大。CPU和GPU实现了软硬件解耦,软件开发者和芯片开发者可以并行不悖,各自相对独立的完成工作。而到了DPU的领域加速,要想实现软硬件解耦非常困难;如果硬是要要采用ASIC的完全定制硬件加速,则是场景和硬件完全紧耦合,开发难度更大,灵活性更低,风险更高。
当然,这里有个矛盾:承载更多领域和场景的功能,可以提升DPU价值;但承载这么多的功能,开发难度却又非常大。那么,均衡点在哪里?有没有既可以卸载更多领域和场景的功能,又不提升开发难度的办法?
1.3 宏观视角看需求:场景的横向和纵向差异性
软件的迭代很快,大概3-6个月;而芯片的迭代很慢,开发周期2年,生命周期5年,合计七年的时间,很难支撑软件的这么频繁而长期的迭代。
差异性主要体现在两方面:
业务场景的横向差异性,指的是即使在同一领域,不同用户的业务逻辑仍有差异,甚至同一企业(用户),其内部也会有很多不同的团队,在同一领域的业务逻辑也存在差异。
业务场景的纵向差异性,指的是同一用户/同一团队业务逻辑的长期快速迭代。
针对业务场景的纵向和横向的差异,主要有三类做法:
芯片厂家,根据自身对场景的理解,给出的自认为最优化的方案(场景定制方案)。这样,其实有点越庖代俎,消除了不同用户业务场景的差异性,也限制了用户的业务创新。用户会对芯片厂家形成强依赖关系,这是用户不愿意看到的。
一些大用户,自身具备芯片研发实力,根据自身业务需求,定制芯片。但大用户内部也是由许多不同的小团队组成,不同团队业务场景仍然存在差异性,定制芯片也存在技术的、商业逻辑的方方面面的挑战。
前两类都是定制的解决方案,这里则是通用的解决方案。“授人以鱼,不如授人以渔”,通过通用的设计,确保在每个领域,都能够实现一定程度上的软硬件解耦。芯片公司提供“通用”的硬件平台,让用户通过编程的方式实现业务差异化,“让用户掌控一切”。挑战则在于,存在通用的解决方案吗?通用解决方案的软硬件如何解耦?
1.4 针对场景定制设计是一件高难度的事情
复杂的系统,软硬件设计需要解耦。只有通过解耦,才能解放彼此,各自努力又相互协同,最终实现功能强大、性能强劲的系统。
通常,大家都以为,定制设计是性能和效率最优的。但实际上,却不是这样:
定制设计,没有冗余,理论上是最极致的性能。但因为定制设计是场景跟硬件设计完全耦合,硬件开发的难度很高,难以实现超大规模的定制设计。
理论上来说定制设计的资源效率是最高的,但由于定制设计必然覆盖的场景较小,芯片设计为了覆盖尽可能多的场景,不得不实现功能超集。实际的功能利用率和资源效率反而不是最高。
定制设计功能完全确定,难以覆盖复杂计算场景的差异化要求。差异化包含两个方面:横向的不同用户的差异化需求,纵向的单个用户的长期快速迭代。
即使同一场景,不同芯片厂家的定制设计引擎架构依然五花八门,毫无生态可言。
因此,可以认为,定制设计是一项非常高难度,并且“吃力不讨好”的事情。特别是在云和边缘计算等,对灵活可编程能力有着极高的要求的,复杂场景,定制设计更是难有用武之地。
1.5 价值和定位不高
目前,对于DPU的定义,行业还存在一些争议,大家对DPU的功能定义依然没有定论。那么DPU的市场规模到底有多少?我们以中国市场为例:
如果认为DPU就是加速卡:那么则是完全碎片化的市场,每个领域的加速市场规模大概在5亿RMB左右。因为碎片化,随着其他整合方案越来越流行之后,加速卡未来的市场则有可能会快速萎缩。
如果定位SmartNIC:智能网卡只在一些纯网络加速的场景有用,市场规模大概50亿RMB左右。而计算类的则是相对综合的场景,不但需要网络,还需要存储、虚拟化、安全等场景加速。
如果定位基础设施处理器IPU(基本等同于DPU,不同的命名方式):市场规模在500亿左右,这就比较符合市场规模预期。但即便如此,IPU的价值定位仍然要比CPU和GPU低,而研发资源投入和风险却又比CPU和GPU高。这一里一外的差距,即是DPU发展最大的挑战。
针对DPU的功能定位,目前形成共识的说法是:DPU作为CPU和GPU的辅助,负责一些数据类处理的加速。这样的定位,则成了DPU发展的天花板和魔咒。
1.6 用户的诉求:支撑自身的业务创新
互联网行业,目前有很多客户开始自研芯片,这是一个重要的趋势:
很多人认为,互联网公司为了构建自己的护城河,开始构建一套“封闭”体系。
我更多的是认为:随着互联网云和边缘计算的发展,上层的软件业务对底层硬件要求越来越高。而传统的芯片公司,虽然有一些先进的技术,但局限于闭门造车,这些技术并没有为客户带来新的更大的价值,反而在一些方面,约束了客户的价值发挥。
这些矛盾,逼迫着一些有实例自研的用户,不得不“自己动手,丰衣足食”,开始了自研之路。
那么,“想喝牛奶,真的要自己养牛吗?”用户的诉求到底是什么?这里我们深入分析一下:
更高性能/成本比。性价比是永恒的话题,都希望最低廉的成本下提供最高的性能价值。
差异化。toB市场,互联网云计算公司需要有足够理想的硬件平台,能够支撑自身业务的差异化,也能够支撑云计算提供差异化的价值给到云的用户(也即用户的用户)。
可迭代。软件的迭代很快,而为了延迟设备的生命周期(也是一种降成本的手段),则需要硬件能够尽可能支持软件服务的更长期迭代。
快速业务创新。用户的业务是核心竞争力,而研发芯片不是。用户需要的是能够自己掌控一切的开发平台,来实现业务创新,来增强自身的核心竞争力。
如果存在通用的芯片方案,能够满足上述这些需求,用户不会产生平台依赖,不对用户自身业务的核心竞争力构成威胁,并且功能更加强大,性能更加强劲,价格更具有显著优势,客户还需要自研吗?
人类发展的过程,就是从“男耕女织”到“手工作坊”,再到流水线的“工业化大生产”,再到现在的“全球化大分工”。从更宏大更长期的视角看,随着时间推移,很多技术会沉淀,云计算这样的互联网底层技术也不例外。互联网整个技术体系会继续枝繁叶茂,并且会持续的、更精细化的分工。而底层的芯片,唯有创新,才能真正帮助客户,成就客户。
2 跳脱束缚,寻找更大的机遇
2.1 通过增强功能来覆盖更多场景
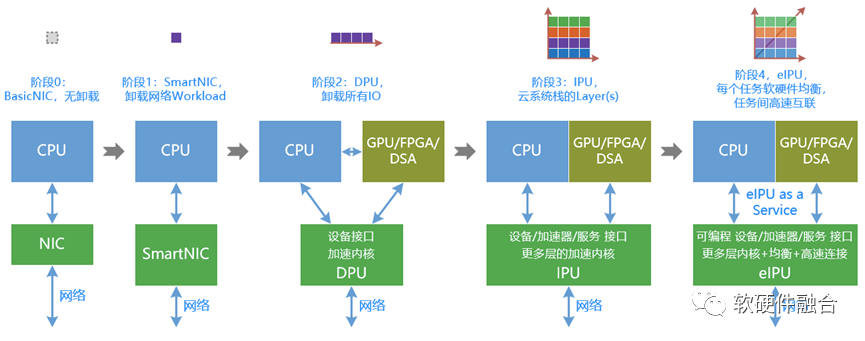
我们站在CPU工作任务卸载到硬件加速的视角来看:
阶段0:CPU性能足够,由于其灵活可编程能力很好,是数据中心处理器当仁不让的第一选择。
随着CPU性能提升缓慢,有一些性能敏感的任务需要加速。于是有了各类加速器(卡),这个时候都局限于某一个特定任务的加速,各个加速方案是完全独立的孤岛。网络加速是比较特殊的一个,因为其刚好处在整个服务器的I/O路径上,价值更大,应用领域也更多。
更进一步的,虚拟化的底层基础设施,如虚拟化管理、网络(包括设备虚拟化和网络服务)、存储(包括设备虚拟化和存储服务)、安全等,都可以从CPU侧卸载到硬件加速。
更进一步的,全栈卸载。只有整个系统堆栈中的任务足够性能敏感(占用非常多的CPU资源),并且大范围的被部署,则此任务就适合被卸载到硬件加速。其性能/成本比的优化效果也更加立竿见影。
但即便如此,这个承载了各类加速的平台,即DPU,其功能和价值还依然不够。它,需要跳脱束缚,自成一体。
CPU、GPU和DPU,既相互协作,又相互竞争。“得入口者得天下”:
传统观点认为,DPU是CPU/GPU的任务卸载加速。
按照软硬件融合演进的观点:DPU/IPU则是数据中心算力和服务的核心,而独立CPU/GPU则是DPU的扩展。
我们详细讲解一下:
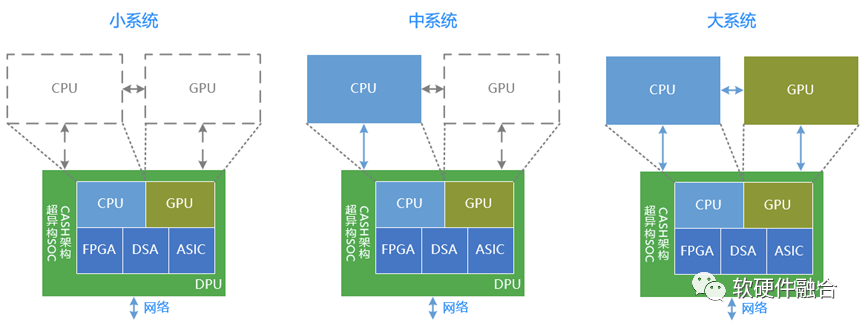
小系统。DPU自身是包含CPU、GPU、FPGA、DSA、ASIC等各种处理引擎的一个超大的SOC。本身就能处理所有的任务。在一些业务应用层算力要求不高的情况下,最小计算系统的独立的DPU就能满足计算的要求。
中系统。DPU+CPU。在一些场景,业务应用层有更高的算力要求,或者必须业务和基础设施分离。这样,DPU+CPU的中等计算系统能够满足此类场景需求。
大系统。DPU+CPU+GPU。例如AI训练类的场景,例如一些应用需要加速的场景,并且需要业务和基础设施分离。这样的时候,DPU+CPU+DPU的最大就成为必须的选择。
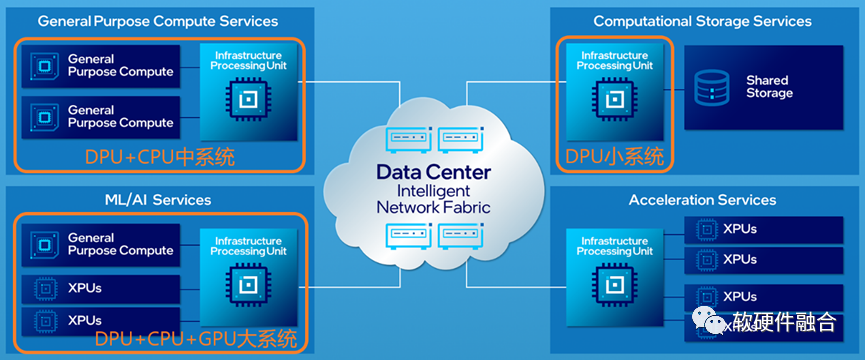
最后,上图是Intel认为的数据中心未来架构图,在这张图中,IPU成为数据中心中最关键的处理器:
后台的存储服务器和加速器池化服务器采用的是DPU小系统;
通用计算服务器采用的是DPU+CPU的中系统;
AI服务器采用的是DPU+CPU+GPU的大系统。
2.2 通过通用可编程能力来提升功能覆盖
我们以网络交换芯片为例。网络交换芯片通常是一个紧耦合的ASIC芯片设计,随着需要支持的网络协议和功能越来越多,ASIC芯片并不都能一一满足用户需求。
有很多用户(特别是巨头用户),都有非常多的创新的和自定义的协议及功能需求。如果把需求反馈给芯片厂家(如博通、思科等),它们再在新一代的芯片研发中心去支持(并且,是否支持新的协议或功能还需要内部决策,有可能一些认为不太重要的协议或功能就无法得到支持),然后等到用户更新到自己的软件服务中去,至少需要2年时间。
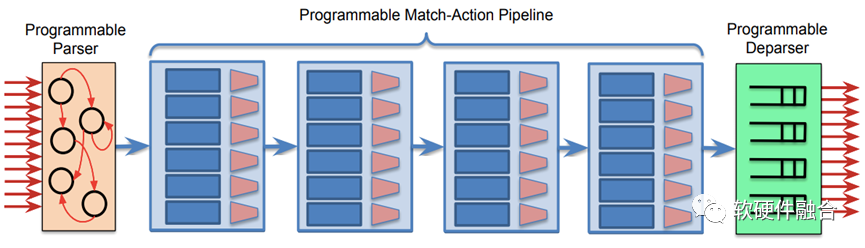
Intel收购的Barefoot提供了可编程交换机,在没有软件编程的情况下,交换机是没有具体功能的。通过编程,用户可以实现自己想要的任何网络协议和功能的支持,甚至实现一些用户自定义协议。并且,这种可编程能力是在ASIC级别的处理引擎上实现,也即能达到ASIC级别的性能。大家把这种网络可编程的ASIC称之为网络DSA。
同样的,其他各种领域和场景都可以采用类似的设计,来实现一定程度的功能可编程,来提升硬件所能覆盖的功能范围。
2.3 超异构计算,更充分的利用更加庞大的晶体管资源
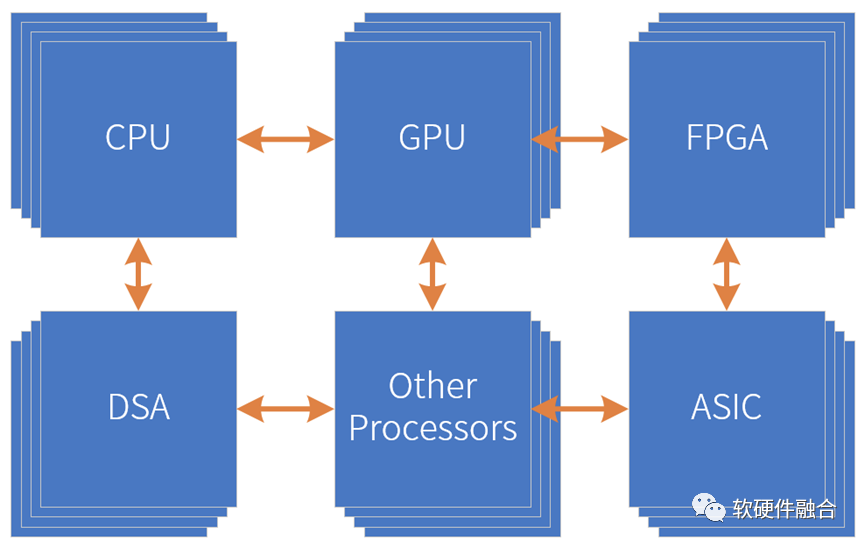
芯片工艺带来的资源规模越来越大,所能支撑的设计规模也越来越大,这给架构创新提供了非常坚实的基础。我们可以采用多种处理引擎共存,“专业的人做专业的事情”,来共同协作的完成复杂系统的计算任务。并且,CPU、GPU、FPGA、一些特定的算法引擎,都可以作为IP,被集成到更大的系统中。这样,构建一个更大规模的芯片设计成为了可能。这里,我们称之为“超异构计算”。如上图所示,超异构指的是由CPU、GPU、FPGA、DSA、ASIC以及其他各种形态的处理器引擎共同组成的超大规模的复杂芯片系统。
超异构计算本质上是系统芯片SOC(System on Chip),但准确的定义应该是宏系统芯片MSOC(Macro-System on Chip)。如果不能认识到超异构和传统SOC的区别,那么则无法把握问题本质。
站在系统的角度,传统SOC是单系统,而超异构宏系统,即多个系统整合到一起的大系统。传统SOC和超异构系统芯片的主要区别和联系如下表所示。
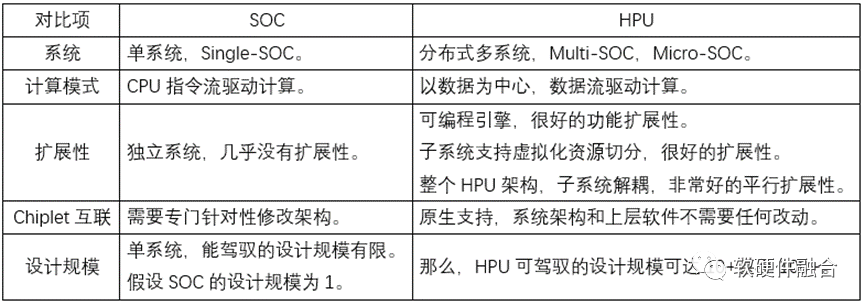
从DPU持续扩展,成就广义的DPU:
DPU成为一个灵活的SOC,既可以作为CPU/GPU的助手,也可以独立工作。就像2.1节提到的DPU小系统,但这个SOC系统规模较小,价值仍有待提高。
通过超异构,进一步提升DPU的系统规模,让DPU能够覆盖更多复杂计算场景。
自成一体,成就更大的价值。
当然,这个时候,DPU的定义已经无法覆盖这个功能强大的处理器了,称之为超异构处理器HPU更合适一些。
2.4 多领域多场景的挑战,唯有开源开放
可支持的领域和场景包括:
网络领域,包括VPC、EIP、LB、网关等场景;
存储领域,包括本地存储、分布式块存储、对象存储、冷存储等场景;
安全领域,包括网络安全、数据加密、零信任、可信计算等场景;
虚拟化领域,包括计算机虚拟化管理、容器虚拟化管理、监控、设备模拟、运行时和热迁移等具体场景;
甚至,可以包括应用层的各类加速领域和场景。
这些领域和场景,每一个都涉及到非常强大的既有生态,已经有若干得到行业大范围使用各类开源(或闭源)软件。没有任何一家芯片功能能够“独占”这些生态,能做的,只有去拥抱既有生态。对芯片公司来说,要做的是:把传统硬件定义软件的模式,彻底的变成软件定义硬件的模式。
另一方面,也需要软件架构和开放模式的改变,软件需要原生支持硬件加速。在软件设计的时候,控制平面和计算平面分离,可以支持计算平面既可以在软件运行,也可以下沉到硬件运行。真正实现“软件定义一切,硬件加速一切”。
讲完了单个领域和场景的视角,我们再回到整体系统的视角。
通常,我们是通过一些虚拟抽象层把硬件平台的不一致性“烙平”,也即把差异化的硬件屏蔽,提供给上层软件一致性的访问接口。随着性能需求的进一步提升,虚拟化都完全沉淀到硬件加速。硬件平台的接口则直接暴露给上层的VM和容器。软件运行平台需要高可用,需要硬件支持软件在不同平台迁移,这样就需要完全一致的硬件平台。
这样就会形成一对新的矛盾:
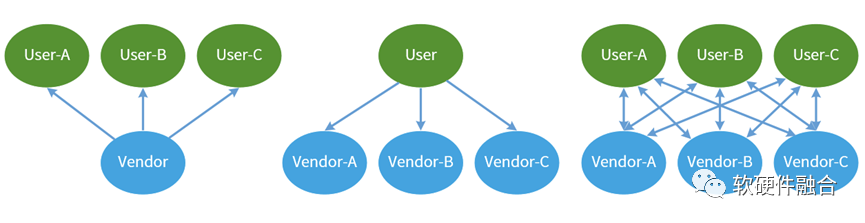
站在芯片厂家的视角,期望的是,一颗芯片,能够被众多厂家采用。也即是自己的硬件平台,很多用户都采用。甚至,私心一点,希望用户捆绑到自己私有的架构平台上,让用户形成依赖。
站在用户的视角,一方面是商业方面(不形成特定厂家依赖)的考虑,一方面是技术方面(即上面提到的跨硬件平台迁移,需要硬件一致性)的考虑。用户需要的是一致性的硬件平台。即所有芯片供应商提供给自己的是一个一致性的平台。甚至可能的话,是自己软件定义的硬件平台。
因此,最终的结果,是芯片厂家和一些主流的客户一起,形成行业共识,即形成一个开源开放的行业生态。
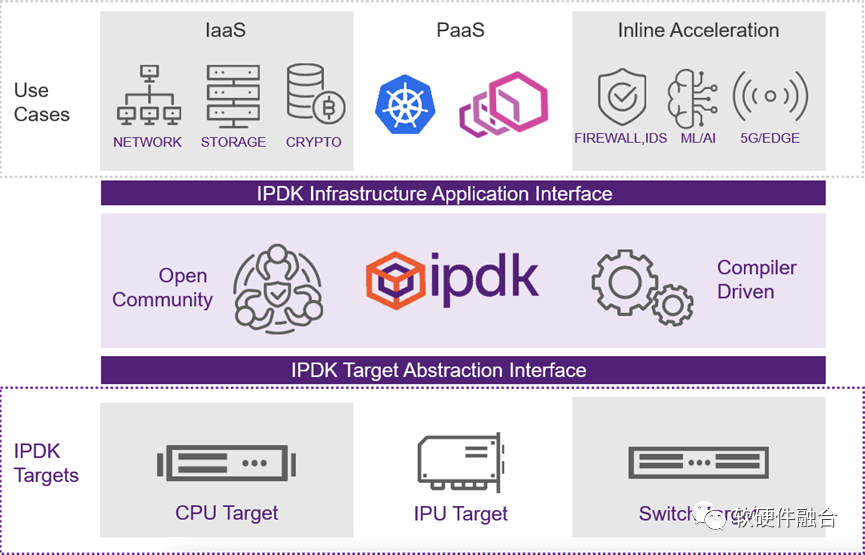
基础设施程序员开发套件 (IPDK) 是Intel发起的一个开源的、供应商无关的驱动程序和 API 框架,用于在 CPU、IPU、DPU 或交换机上运行的基础设施卸载和管理。IPDK在Linux中运行,并使用一套完善的工具(如 SPDK、DPDK 和 P4)来启用平台中的网络虚拟化、存储虚拟化、工作负载供应、信任根和卸载功能。2022年3月15日,由Intel、Redhat和F5等发起Open Programmable Infrastructure Event,邀请了产业界的相关公司共同探讨IPU/DPU软件生态建设。这些事件,可以认为是行业巨头在力推开源开放的整体生态,并试图在其中占据主导作用。
更长远的看,开源开放的生态是行业发展的大事情。在可预见的未来,这件事情会彻底改变IT行业的生态逻辑。国内的厂商,不管是做DPU的,还是做CPU、GPU以及做AI芯片的,大家都应快速跟进、积极参与甚至引领这个开放可编程平台和生态。虽然目前还只聚焦在DPU领域。
3 一些结论
DPU的未来发展如何?基于软硬件融合理念,这里给出几个关于未来五年行业发展的推断,与大家探讨:
DPU是超异构计算时代来临的一个起始;
未来所有(大)芯片都会是超异构芯片;
超异构和SOC是两个完全不同的概念;
超异构大芯片需要足够通用,而不是专用;
超异构需要开源开放的生态;
要想驾驭超异构的超大系统规模,就需要软硬件融合。
审核编辑:汤梓红
-
芯片
+关注
关注
456文章
51004浏览量
425253 -
cpu
+关注
关注
68文章
10887浏览量
212357 -
NVIDIA
+关注
关注
14文章
5047浏览量
103347 -
gpu
+关注
关注
28文章
4759浏览量
129123 -
DPU
+关注
关注
0文章
365浏览量
24217
原文标题:DPU发展面临的困境和机遇
文章出处:【微信号:阿宝1990,微信公众号:阿宝1990】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
《数据处理器:DPU编程入门》DPU计算入门书籍测评
2018年车联网的发展现状和发展机遇解读
DVB-H接收器设计所面临的机遇和挑战讨论
我国物联网发展面临什么困境
国产模数转换ADC芯片的现状如何、会面临什么困境和历史机遇?
业内首部白皮书《DPU技术白皮书》——中科院计算所主编
大禹智芯宣布加入欧拉开源社区,助力构建DPU行业发展新生态
什么是DPU?
2022年中国DPU行业白皮书 DPU将成为CPU、GPU后的第三块主力芯片






 工商网监
工商网监
评论