 Linux内核之物理内存组织结构
Linux内核之物理内存组织结构
一、系统调用mmap
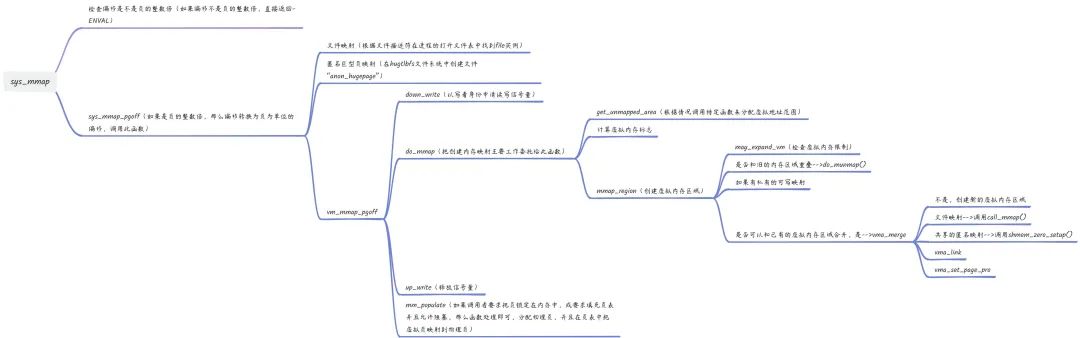
虚拟内存区域使用起始地址和结束地址描述,链表按起始地址递增排序。两系统调用区别:mmap指定的偏移的单位是字节,而mmap2指定的偏移的单位是页。ARM64架构实现系统调用mmap。
二、系统调用munmap
系统调用munmap用来删除内存映射,它有两个参数:起始地址和长度即可。它的主要工作委托给内核源码文件处理“mm/mmap.c”中的函数do_munmap。
vm_munmap -->do_munmap -->vma=find_vma(mm,start) -->error=__split_vma(mm,vma,start,0) -->last=find_vma(mm,end) -->interror=__split_vma(mm,last,end,1) -->munlock_vma_pages_all -->detach_vmas_to_be_unmapped -->unmap_region -->arch_unmap -->remove_vma_list
vma = find_vma(mm,start);//根据起始地址找到要删除的第一个虚拟内存区域vma
error = __split_vma(mm,vma,start,0);//如果只删除虚拟内存区域vma的部分,那么分裂虚拟内存区域vma
last = find_vma(mm,end);//根据结束地址找到要删除的最后一个虚拟内存区域vma
int error = __split_vma(mm,last,end,1);//如果只删除虚拟内存区域last的一部分,那么分裂虚拟内存区域vma
munlock_vma_pages_all;//针对所有删除目标,如果虚拟内存区域被锁定在内存中(不允许换出到交换区),调用函数解除锁定
detach_vmas_to_be_unmapped;//调用此函数,把所有删除目标从进程虚拟内存区域链表和树中删除,单独组成一条临时链表
unmap_region;//调用此函数,针对所有删除目标,在进程的页表中删除映射,并且从处理器的页表缓存中删除映射
arch_unmap;//调用此函数执行处理器架构特定的处理操作
remove_vma_list;//调用此函数,删除所有目标
三、物理内存组织结构
1.体系结构
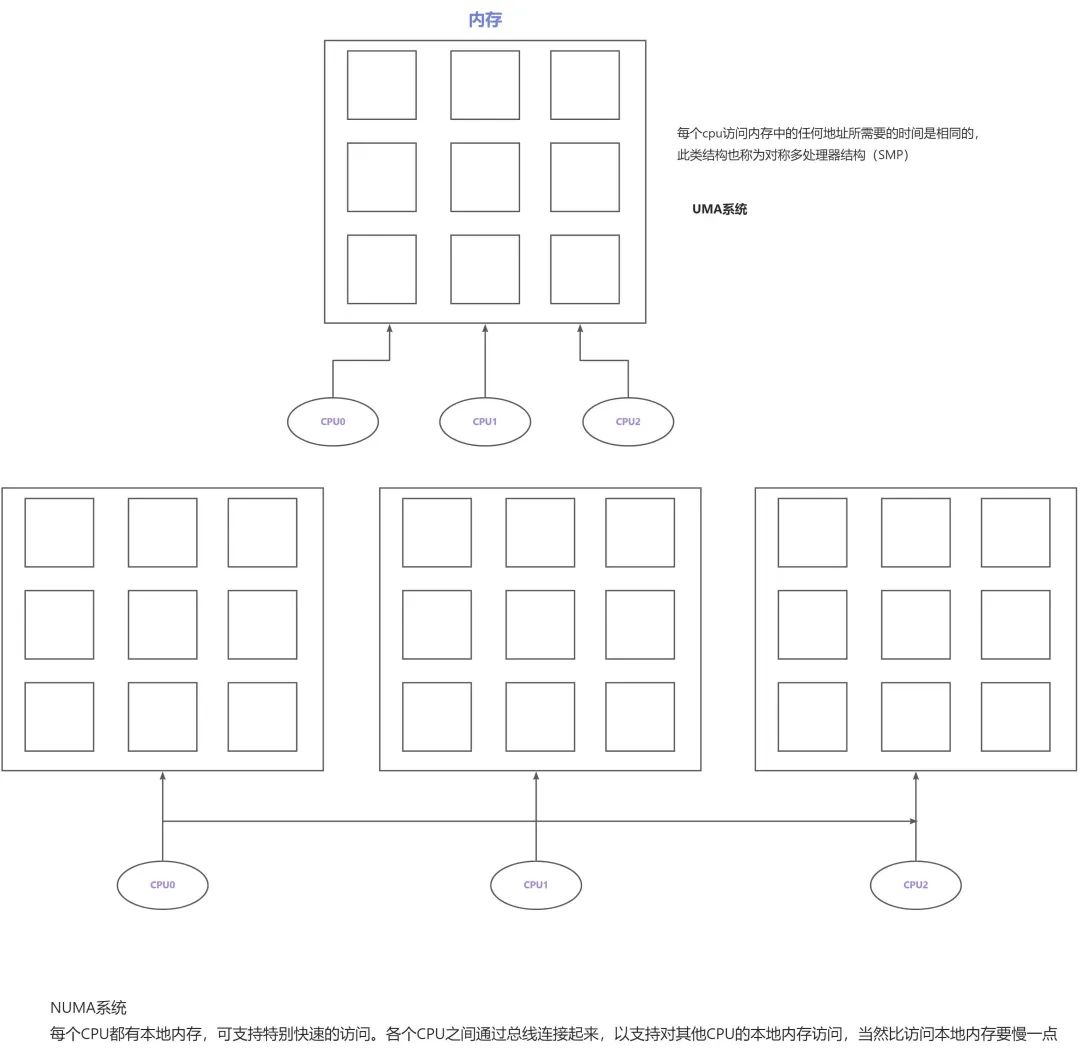
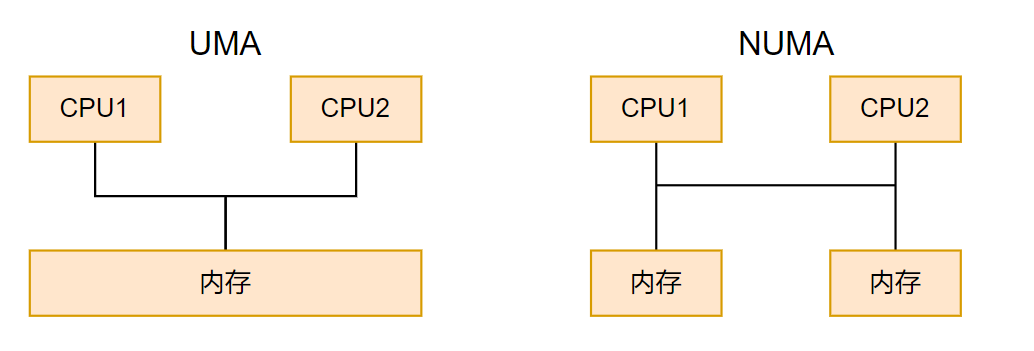
目前多处理器系统有两种体系结构:
非一致内存访问(Non-Unit Memory Access,NUMA):指内存被划分成多个内存节点的多处理器系统。访问一个内存节点花费的时间取决于处理器和内存节点的距离。
对称多处理器(Sysmmetric Muti-Processor,SMP):即一致内存访问(Uniform Memory Access,UMA),所有处理器访问内存花费的时间是相同的。
2.内存模型
内存模型是从处理器角度看到的物理内存分布,内核管理不同内存模型的方式存在差异。内存管理子系统支持3种内存模型:
平坦内存(Flat Memory):内存的物理地址空间是连续的,没有空洞。
不连续内存(Discontiguous Memory):内存的物理地址空间存在空洞,这种模型可以高效地处理空洞。
稀疏内存(Space Memory):内存物理地址空间存在空洞,如果要支持内存热插拔,只能选择稀疏内存模型。
3.三级结构
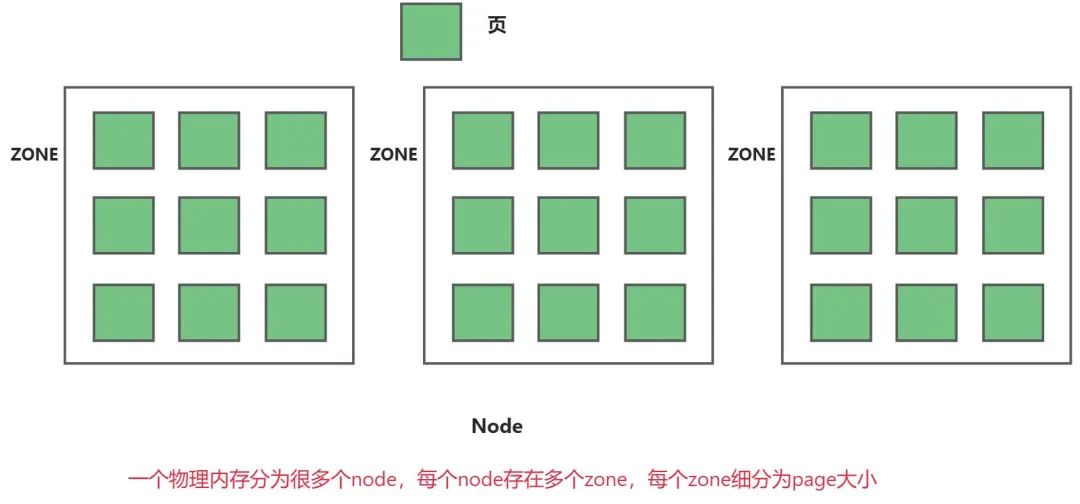
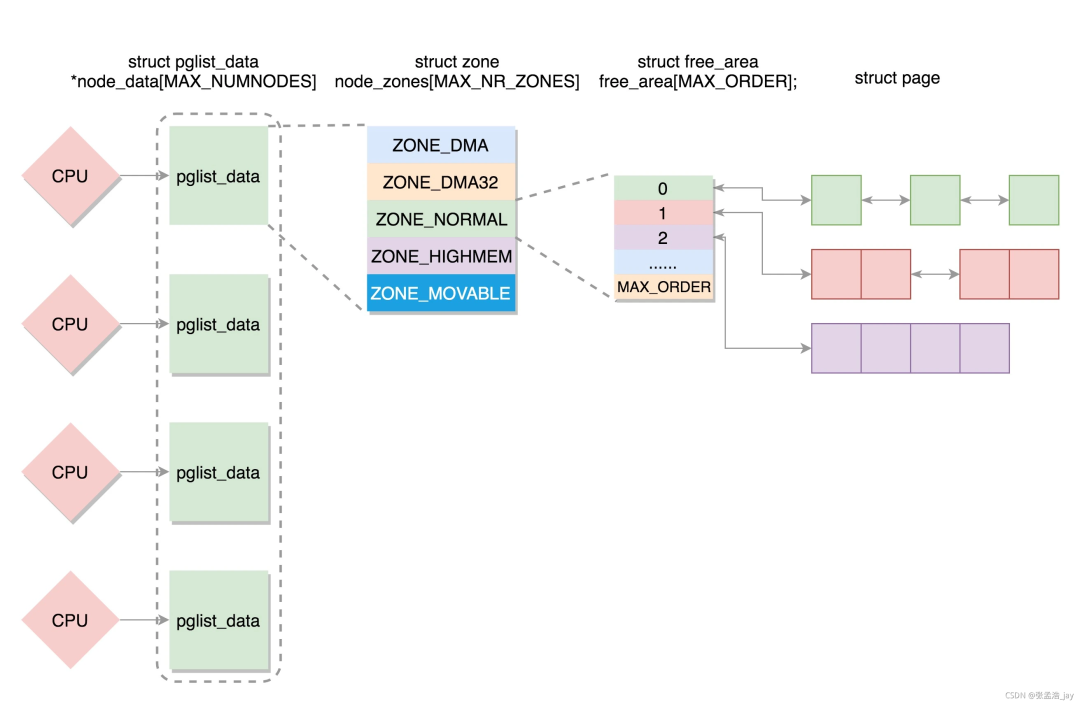
内存管理子系统使用节点(node)、区域(zone)、页(page)三级结构描述物理内存。
3.1 内存节点--->分为两种情况
NUMA体系的内存节点,根据处理器和内存距离划分;
在具有不连续内存的NUMA系统中,表示比区域的级别更高的内存区域,根据物理地址是否连续,每块物理地址连续的内存是一个内存节点。
内存节点使用结构体pglist_data描述内存布局
Linux内核源码如下:
typedefstructpglist_data{
structzonenode_zones[MAX_NR_ZONES];//内存区域数组
structzonelistnode_zonelists[MAX_ZONELISTS];//备用区域列表
intnr_zones;//该节点包含内存区域数量
#ifdefCONFIG_FLAT_NODE_MEM_MAP/*means!SPARSEMEM*///除了稀疏内存模型以外
structpage*node_mem_map;//页描述符数组
#ifdefCONFIG_PAGE_EXTENSION
structpage_ext*node_page_ext;//页的扩展属性
#endif
#endif
#ifndefCONFIG_NO_BOOTMEM
structbootmem_data*bdata;
#endif
#ifdefCONFIG_MEMORY_HOTPLUG
/*
*Mustbeheldanytimeyouexpectnode_start_pfn,node_present_pages
*ornode_spanned_pagesstayconstant.Holdingthiswillalso
*guaranteethatanypfn_valid()staysthatway.
*
*pgdat_resize_lock()andpgdat_resize_unlock()areprovidedto
*manipulatenode_size_lockwithoutcheckingforCONFIG_MEMORY_HOTPLUG.
*
*Nestsabovezone->lockandzone->span_seqlock
*/
spinlock_tnode_size_lock;
#endif
unsignedlongnode_start_pfn;//该节点的起始物理页号
unsignedlongnode_present_pages;/*物理页总数*/
unsignedlongnode_spanned_pages;/*物理页范围总的长度,包括空间*/
intnode_id;//节点标识符
wait_queue_head_tkswapd_wait;
wait_queue_head_tpfmemalloc_wait;
structtask_struct*kswapd;/*Protectedby
mem_hotplug_begin/end()*/
intkswapd_max_order;
enumzone_typeclasszone_idx;
#ifdefCONFIG_NUMA_BALANCING
/*Lockserializingthemigrateratelimitingwindow*/
spinlock_tnumabalancing_migrate_lock;
/*Ratelimitingtimeinterval*/
unsignedlongnumabalancing_migrate_next_window;
/*Numberofpagesmigratedduringtheratelimitingtimeinterval*/
unsignedlongnumabalancing_migrate_nr_pages;
#endif
#ifdefCONFIG_DEFERRED_STRUCT_PAGE_INIT
/*
*Ifmemoryinitialisationonlargemachinesisdeferredthenthis
*isthefirstPFNthatneedstobeinitialised.
*/
unsignedlongfirst_deferred_pfn;
#endif/*CONFIG_DEFERRED_STRUCT_PAGE_INIT*/
}pg_data_t;
node_mem_map此成员指向页描述符数组,每个物理页对应一个页描述符。
Node是内存管理最顶层的结构,在NUMA架构下,CPU平均划分为多个Node,每个Node有自己的内存控制器及内存插槽。CPU访问自己Node上内存速度快,而访问其他CPU所关联Node的内存速度慢。UMA被当作只一个Node的NUMA系统。
3.2 内存区域(zone)
内存节点被划分为内存区域。Linux内核源码分析:include/linux/mmzone.h
enumzone_type{
#ifdefCONFIG_ZONE_DMA
/*
*ZONE_DMAisusedwhentherearedevicesthatarenotable
*todoDMAtoallofaddressablememory(ZONE_NORMAL).Thenwe
*carveouttheportionofmemorythatisneededforthesedevices.
*Therangeisarchspecific.
*
*Someexamples
*
*ArchitectureLimit
*---------------------------
*parisc,ia64,sparc<4G
* s390 <2G
* arm Various
* alpha Unlimited or 0-16MB.
*
* i386, x86_64 and multiple other arches
* <16M.
*/
ZONE_DMA, /*Direct Memory Access,直接内存访问。如果有些设备不能直接访问所有内存,需要使用DMA区域。ISA*/
#endif
#ifdef CONFIG_ZONE_DMA32
/*
* x86_64 needs two ZONE_DMAs because it supports devices that are
* only able to do DMA to the lower 16M but also 32 bit devices that
* can only do DMA areas below 4G.
*/
ZONE_DMA32, /* 64位系统,如果既要支持能直接访问16MB以下内存设备,又要支持能直接访问4GB以下内存的32设备,必须使用此DMA32区域*/
#endif
/*
* Normal addressable memory is in ZONE_NORMAL. DMA operations can be
* performed on pages in ZONE_NORMAL if the DMA devices support
* transfers to all addressable memory.
*/
/*普通内存区域:
直接映射到内核虚拟地址空间的内存区域,又称为普通区域,又称为直接映射区域,又称为线性映射区域*/
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
/*
* A memory area that is only addressable by the kernel through
* mapping portions into its own address space. This is for example
* used by i386 to allow the kernel to address the memory beyond
* 900MB. The kernel will set up special mappings (page
* table entries on i386) for each page that the kernel needs to
* access.
*/
/*高端内存区域:
此区域是32位时代的产物,内核和用户地址空间按1:3划分,
内核地址空间只有1GB,不能把1GB以上内存直接映射到该地址*/
ZONE_HIGHMEM,
#endif
/*可移动区域:
它是一个伪内存区域,用来防止内存碎片*/
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
/*设备区域:
为支持持久内存热插拔增加的内存区域,每一个内存区域用一个zone结构体来描述*/
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};
每个内存区域使用一个zone结构体描述,如下为主要成员:
structzone{
/*Read-mostlyfields*/
/*zonewatermarks,accesswith*_wmark_pages(zone)macros*/
unsignedlongwatermark[NR_WMARK];//页分配器使用的水线
unsignedlongnr_reserved_highatomic;
/*
*Wedon'tknowifthememorythatwe'regoingtoallocatewillbe
*freeableor/anditwillbereleasedeventually,sotoavoidtotally
*wastingseveralGBoframwemustreservesomeofthelowerzone
*memory(otherwisewerisktorunOOMonthelowerzonesdespite
*therebeingtonsoffreeableramonthehigherzones).Thisarrayis
*recalculatedatruntimeifthesysctl_lowmem_reserve_ratiosysctl
*changes.
*/
longlowmem_reserve[MAX_NR_ZONES];//页分配器使用,当前区域保留多少页不能借给高的区域类型
#ifdefCONFIG_NUMA
intnode;
#endif
/*
*ThetargetratioofACTIVE_ANONtoINACTIVE_ANONpageson
*thiszone'sLRU.Maintainedbythepageoutcode.
*/
unsignedintinactive_ratio;
structpglist_data*zone_pgdat;//指向内存节点的pglist_data实例
structper_cpu_pageset__percpu*pageset;//每处理页集合
/*
*Thisisaper-zonereserveofpagesthatshouldnotbe
*considereddirtyablememory.
*/
unsignedlongdirty_balance_reserve;
#ifndefCONFIG_SPARSEMEM
/*
*Flagsforapageblock_nr_pagesblock.Seepageblock-flags.h.
*InSPARSEMEM,thismapisstoredinstructmem_section
*/
unsignedlong*pageblock_flags;
#endif/*CONFIG_SPARSEMEM*/
#ifdefCONFIG_NUMA
/*
*zonereclaimbecomesactiveifmoreunmappedpagesexist.
*/
unsignedlongmin_unmapped_pages;
unsignedlongmin_slab_pages;
#endif/*CONFIG_NUMA*/
/*zone_start_pfn==zone_start_paddr>>PAGE_SHIFT*/
unsignedlongzone_start_pfn;//当前区域的起始物理页号
/*
*spanned_pagesisthetotalpagesspannedbythezone,including
*holes,whichiscalculatedas:
*spanned_pages=zone_end_pfn-zone_start_pfn;
*
*present_pagesisphysicalpagesexistingwithinthezone,which
*iscalculatedas:
*present_pages=spanned_pages-absent_pages(pagesinholes);
*
*managed_pagesispresentpagesmanagedbythebuddysystem,which
*iscalculatedas(reserved_pagesincludespagesallocatedbythe
*bootmemallocator):
*managed_pages=present_pages-reserved_pages;
*
*Sopresent_pagesmaybeusedbymemoryhotplugormemorypower
*managementlogictofigureoutunmanagedpagesbychecking
*(present_pages-managed_pages).Andmanaged_pagesshouldbeused
*bypageallocatorandvmscannertocalculateallkindsofwatermarks
*andthresholds.
*
*Lockingrules:
*
*zone_start_pfnandspanned_pagesareprotectedbyspan_seqlock.
*Itisaseqlockbecauseithastobereadoutsideofzone->lock,
*anditisdoneinthemainallocatorpath.But,itiswritten
*quiteinfrequently.
*
*Thespan_seqlockisdeclaredalongwithzone->lockbecauseitis
*frequentlyreadinproximitytozone->lock.It'sgoodto
*givethemachanceofbeinginthesamecacheline.
*
*Writeaccesstopresent_pagesatruntimeshouldbeprotectedby
*mem_hotplug_begin/end().Anyreaderwhocan'ttolerantdriftof
*present_pagesshouldget_online_mems()togetastablevalue.
*
*Readaccesstomanaged_pagesshouldbesafebecauseit'sunsigned
*long.Writeaccesstozone->managed_pagesandtotalram_pagesare
*protectedbymanaged_page_count_lockatruntime.Idealyonly
*adjust_managed_page_count()shouldbeusedinsteadofdirectly
*touchingzone->managed_pagesandtotalram_pages.
*/
unsignedlongmanaged_pages;//伙伴分配器管理的物理页的数量
unsignedlongspanned_pages;//当前区域跨越的总页数,包括空洞
unsignedlongpresent_pages;//当前区域存在的物理页的数量,不包括空洞
constchar*name;//区域名称
#ifdefCONFIG_MEMORY_ISOLATION
/*
*Numberofisolatedpageblock.Itisusedtosolveincorrect
*freepagecountingproblemduetoracyretrievingmigratetype
*ofpageblock.Protectedbyzone->lock.
*/
unsignedlongnr_isolate_pageblock;
#endif
#ifdefCONFIG_MEMORY_HOTPLUG
/*seespanned/present_pagesformoredescription*/
seqlock_tspan_seqlock;
#endif
/*
*wait_table--thearrayholdingthehashtable
*wait_table_hash_nr_entries--thesizeofthehashtablearray
*wait_table_bits--wait_table_size==(1<< wait_table_bits)
*
* The purpose of all these is to keep track of the people
* waiting for a page to become available and make them
* runnable again when possible. The trouble is that this
* consumes a lot of space, especially when so few things
* wait on pages at a given time. So instead of using
* per-page waitqueues, we use a waitqueue hash table.
*
* The bucket discipline is to sleep on the same queue when
* colliding and wake all in that wait queue when removing.
* When something wakes, it must check to be sure its page is
* truly available, a la thundering herd. The cost of a
* collision is great, but given the expected load of the
* table, they should be so rare as to be outweighed by the
* benefits from the saved space.
*
* __wait_on_page_locked() and unlock_page() in mm/filemap.c, are the
* primary users of these fields, and in mm/page_alloc.c
* free_area_init_core() performs the initialization of them.
*/
wait_queue_head_t *wait_table;
unsigned long wait_table_hash_nr_entries;
unsigned long wait_table_bits;
ZONE_PADDING(_pad1_)
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER]; // 不同长度的空间区域
/* zone flags, see below */
unsigned long flags;
/* Write-intensive fields used from the page allocator */
spinlock_t lock;
ZONE_PADDING(_pad2_)
/* Write-intensive fields used by page reclaim */
/* Fields commonly accessed by the page reclaim scanner */
spinlock_t lru_lock;
struct lruvec lruvec;
/* Evictions & activations on the inactive file list */
atomic_long_t inactive_age;
/*
* When free pages are below this point, additional steps are taken
* when reading the number of free pages to avoid per-cpu counter
* drift allowing watermarks to be breached
*/
unsigned long percpu_drift_mark;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* pfn where compaction free scanner should start */
unsigned long compact_cached_free_pfn;
/* pfn where async and sync compaction migration scanner should start */
unsigned long compact_cached_migrate_pfn[2];
#endif
#ifdef CONFIG_COMPACTION
/*
* On compaction failure, 1<
3.3 物理页
页是内存管理当中最小单位,页面中的内存其物理地址是连续的,每个物理页由struct page描述。为了节省内存,struct page是个联合体。
页,又称为页帧,在内核当中,内存管理单元MMU(负责虚拟地址和物理地址转换的硬件)是把物理页page作为内存管理的基本单位。体系结构不同,支持的页大小也不同。(32位体系结构支持4KB的页、64位体系结构支持8KB的页、MIPS64架构体系支持16KB的页)
审核编辑:汤梓红
-
ARM
+关注
关注
134文章
9265浏览量
373252 -
内核
+关注
关注
3文章
1402浏览量
40918 -
Linux
+关注
关注
87文章
11414浏览量
212252 -
物理内存
+关注
关注
0文章
11浏览量
8545 -
虚拟内存
+关注
关注
0文章
78浏览量
8180
原文标题:Linux内核 | 物理内存组织结构
文章出处:【微信号:嵌入式开发AIoT,微信公众号:嵌入式开发AIoT】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一文详解Linux内核源码组织结构
Linux的内存管理是什么,Linux的内存管理详解
走进Linux内存系统探寻内存管理的机制和奥秘
Linux内存相关知识科普
Linux内核内存管理之内核非连续物理内存分配
Linux内核地址映射模型与Linux内核高端内存详解
带你了解Linux内核体系结构
Linux内核结构详解
如何避免Linux的物理内存碎片化
Linux0.11-内存组织和进程结构
一文解析Linux内存系统
STM32MP157 Linux系统移植开发篇7:Linux内核目录结构详解






 工商网监
工商网监
评论