 一种灵活有效的事件抽取数据增强框架-Mask-then-Fill
一种灵活有效的事件抽取数据增强框架-Mask-then-Fill
写在前面
今天给大家带来一篇事件抽取数据增强方法,全名为《Mask-then-Fill: A Flexible and Effective Data Augmentation Framework for Event Extraction》,即一种灵活有效的事件抽取数据增强框架-Mask-then-Fill。
介绍
事件抽取,即从非机构化文本中抽取指定的事件的触发词及其事件要素,为了减轻人工标注,常采用数据增强方法,对原有数据进行扩充,在有限的数据内,尽可能提高模型的效果及泛化性。目前,自然语言处理的数据增强方法主要分为两类:(1)修改原有训练数据样本;(2)生成+采样。而事件抽取任务需要在保持事件结构(触发器和参数)不变的情况下增加训练数据,因此“生成+采样”的方法并不适用,本论文主要采用“修改原有训练数据样本”方法进行数据增强。
如图1所示,现有对事件抽取进行数据增强的方法主要包括:(1)回译;(2)同义词替换;(3)BERT换词。但,同义词替换和回译方法缺乏语义多样性,只能生成语义相似的样本;而基于BERT的方法只能替换单词,不能改变语法,不能生成包含各种表达式的样本。
为了解决数据增强多样性的问题,该论文提出了“掩码-填充”方法,在保持原事件结构不变的情况下生成更多样化的数据。首先定义两种类型文本片段:(1)事件相关片段(触发词和事件要素);(2)附加片段。然后随机掩码一个附件片段,最后采用微调后的T5模型进行文本填充。
并且引入亲和度(Affinity)和多样性(Diversity)两个指标进行进一步研究,发现Mask-then-Fill方法增强的数据具有更好的多样性和更少的分布变化,在多样性和分布相似性之间实现了良好的平衡。
Mask-then-Fill Framework
掩码-填充框架如图2所示,文本主要包括事件相关片段(带颜色内容)和附加片段(带下划线内容),框架的核心是在不引入新的事件前提下,重写整个附属片段。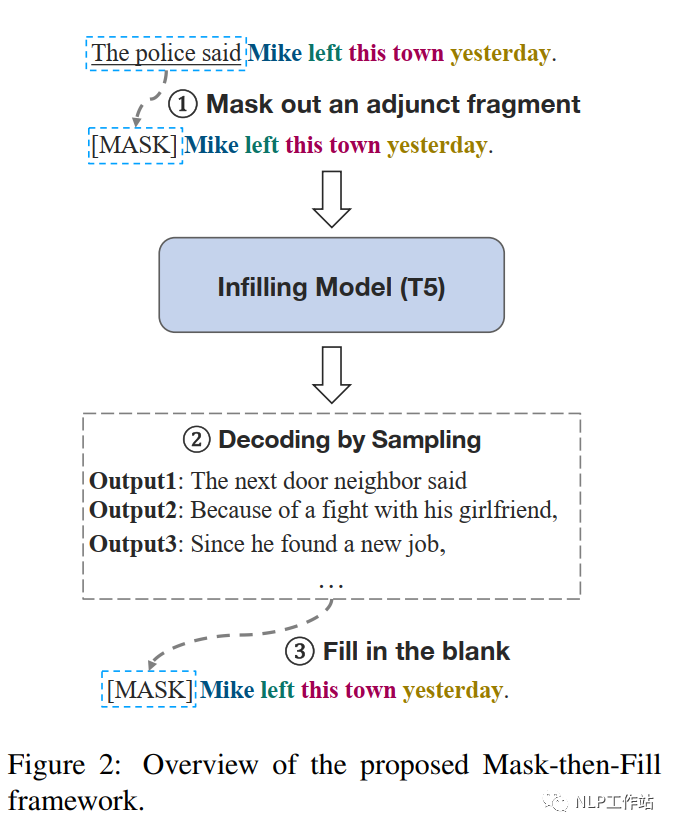

Experimental Setup
采用ACE2005数据集上进行对比实验,从训练集中随机抽取1000、4000和8000个样本来模拟低资源设置,创建小型、中型和大型训练集。并在数据增强时,仅对训练数据集进行数据增强,开发集和测试集保持不变。
在Text2Event模型和Text2Event模型两个具有代表性的事件抽取模型上进行实验,并对比与同义词替换、回译、BERT模型三种数据增强方法之间的差异。
Results and Analysis
如表1所示,整体上Mask-then-Fill方法最优。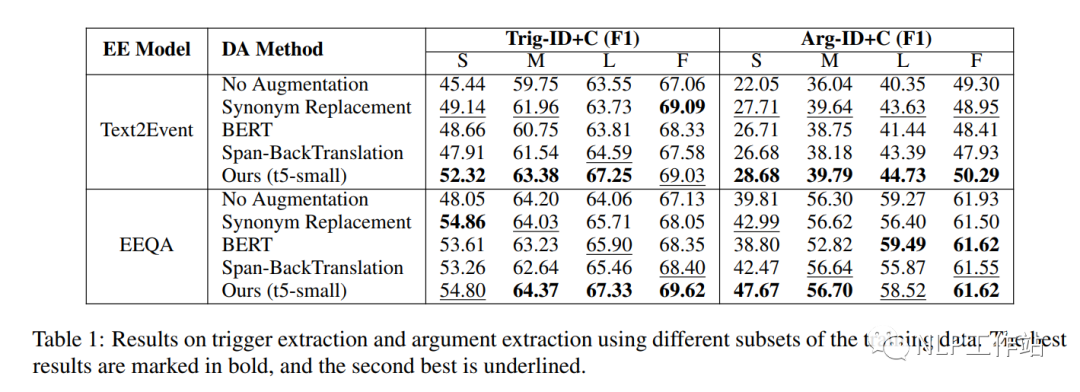
从表2可以看出,我Mask-then-Fill方法增强的数据具有更好的多样性和更少的分布偏移,在多样性和分布相似性之间取得了平衡。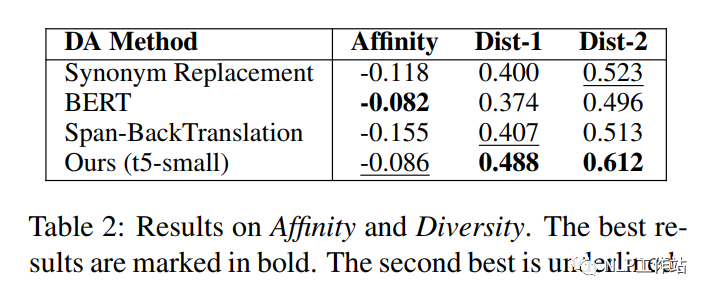
图3展示了由不同的数据增强方法生成的示例。
总结
该框架的主要优点在于可以将文本中任意长度的片段替换为可变长度的片段,而现有的方法只能替换单个单词或固定长度的片段。
审核编辑:刘清
-
J-BERT
+关注
关注
0文章
5浏览量
7818 -
触发器
+关注
关注
14文章
2027浏览量
61617 -
ACE
+关注
关注
0文章
21浏览量
10761 -
Fill
+关注
关注
0文章
4浏览量
2949
原文标题:事件抽取数据增强方法-Mask-then-Fill
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
CIC抽取滤波器MATLAB仿真和FPGA实现
怎样去设计一种CIC抽取滤波器并对其进行MATLAB仿真呢
一种基于复用组件的WEB测控软件框架设计
一种基于XML的可复用Web图表框架
有限状态机的一种实现框架
一种新的DSA图像增强算法

一种基于框架特征的共指消解方法

一种用于交通流预测的深度学习框架






 工商网监
工商网监
评论