 云原生场景下实现编译加速
云原生场景下实现编译加速
背景
云原生下的流水线是通过启动容器来运行具体的功能步骤,每次运行流水线可能会被调度到不同的计算节点上。这会导致一个问题:容器运行完是不会保存数据的,每当流水线重新运行时,又会重新拉取代码、编译代码、下载依赖包等等。在云原生场景下,不存在本地宿主机编译代码、构建镜像时缓存的作用,大大延长了流水线运行时间,浪费很多不必要的时间、网络和计算成本。在许多流水线场景中,同一条流水线的多次执行之间是有关联的。如果能够用到上一次的执行结果,则可以大幅缩短执行时间。为了提高用户使用流水线的体验,我们加入支持缓存的功能,挂接远程储存管理构建缓存,可以实现同一个项目的编译依赖复用,在同一条流水线的多次运行中,共享同一份缓存。目标
通过实现云原生流水线的缓存技术,实现代码编译的缓存复用,平均加速流水线 3~5 倍;实现方案
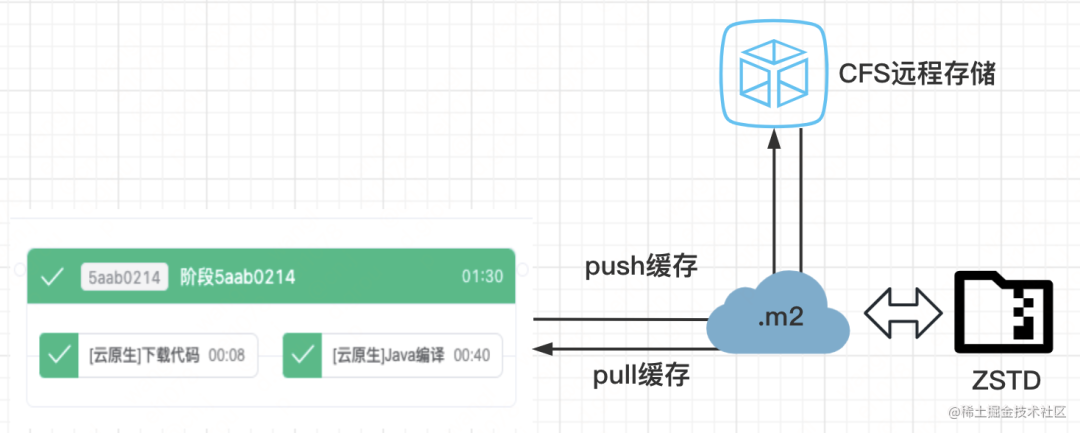
我们将需要进行缓存的文件,使用 zstd 的方式进行压缩,通过远程挂载 cfs,将构建的缓存持久化到 cfs 上的指定位置。当下一次构建开始的时候,判断缓存是否被命中,如果命中缓存,我们从 cfs 上的指定位置 pull 对应的缓存压缩包,解压到相应目录下。所用工具 - cfs+zstd
非用户自定义镜像,将需要的工具打到引擎的基础镜像中,作为所有镜像的基础工具。用户自定义镜像,不和用户镜像进行强绑定,如果需要使用缓存功能,可以使用 Restore 缓存原子和 Save 缓存原子,设置缓存 key 和缓存目录,实现缓存功能。1 cfs 远程挂载
・将工具和启动脚本,配置文件打到基础镜像・在开启缓存的位置,启动脚本,开始挂载 cfs
_, err = c.ScriptAction.Sh([]string{
"sh",
"-c",
"modprobe fuse;cd /export/servers/tools/cfs;sudo ./cfs-client-randomwrite -c fuse.json",
})
2 zstd 压缩
针对现有的几种压缩方式进行了性能对比,最后选用了 zstd 进行压缩。Zstd,全称 Zstandard,是 Facebook 于 2016 年开源的新无损压缩算法。Zstd 还可以以压缩速度为代价提供更强的压缩比,速度与压缩率的比重可通过增量进行配置。与 zlib、lz4、xz 等当前流行的压缩算法不同,Zstd 寻求一种压缩性能与压缩率通吃的方案,而实际上它也确实做到了。在由官方所列出的表格中,可以看到,Zstd 不仅具备优秀的压缩性能,在压缩率上也有非常亮眼的表现。在过去的两年里,Linux 内核、HTTP 协议、以及一系列的大数据工具(包括 Hadoop 3.0.0,HBase 2.0.0,Spark 2.3.0,Kafka 2.1.0)等都已经加入了对 zstd 的支持。常见的压缩算法性能对比: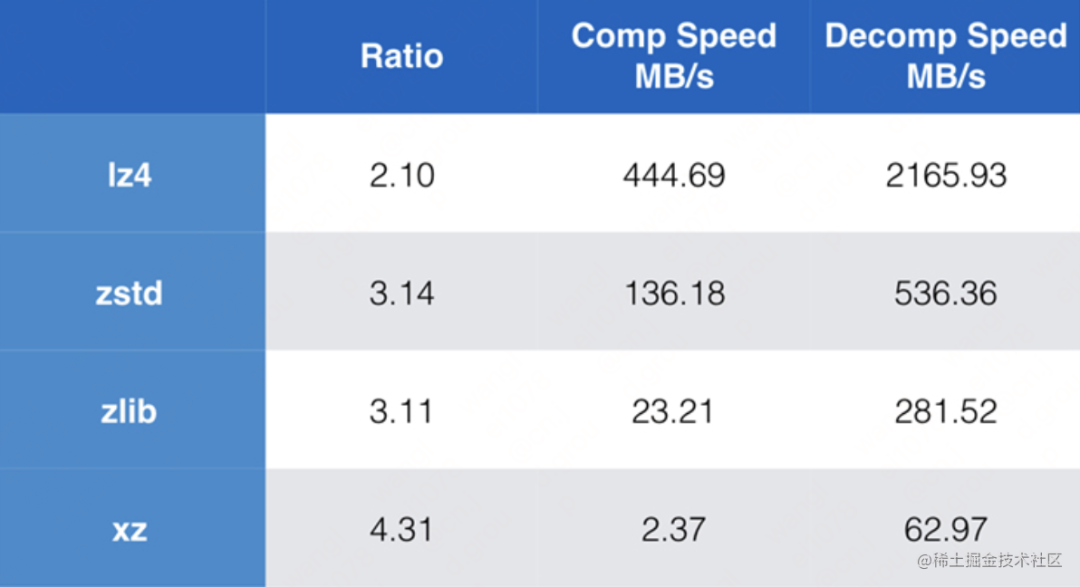 压缩包大小对比:
压缩包大小对比:| 依赖包的大小 | 465M | 压缩效率 |
|---|---|---|
| tar 压缩 | 423M | 14s 左右 |
| zstd 压缩 | 205M | 1s 左右 |
缓存的实现
我们借鉴了 github cache action,zadig,gitlab 等缓存的处理方式,同时结合服务自身的特点将整体分成三步・检查是否命中缓存:根据缓存 key,判断缓存是否命中
| 缓存 key | 缓存的唯一标识 |
|---|---|
| 不同语言编译原子 | 根据下载代码的代码库地址自动获取 设置的缓存 key:home_auth/home-auth-center |
| 用户自定义镜像 | 自定义缓存 key |
・pull 缓存
当缓存命中后,根据缓存路径,找到挂载到 cfs 上的缓存压缩包,解压到指定的缓存目录下・push 缓存:将依赖包进行压缩,放到 cfs 的挂载目录下
| 依赖包的大小 | 465M |
|---|---|
| tar 压缩 | 423M |
| zstd 压缩 | 205M |
缓存的使用限制和回收策略
使用限制
目前存储缓存数没有限制,存储库中所有缓存的总大小限制是根据申请的 cfs 的大小限制:20G。回收策略
我们会删除 7 天内未被访问的任何缓存。利用 etcd 的 watch 机制,实现缓存的回收。etcd 可以Watch指定的键、前缀目录的更改,并对更改时间进行通知。BASE 引擎中,缓存的清除策略借助 etcd 来实现。缓存过期策略:在编译加速的实现中,每个需要缓存的项目都有对应的缓存 key,通过 etcd 监控 key,并且设置过期时间,例如 7 天,如果在 7 天之内再次命中 key,则通过 lease 进行续约;7 天之内 key 都没有被使用,key 就会过期删除,通过监听对应的前缀,在过期删除的时候,调用删除缓存的方法。
storage.Watch("cache/",
func(id string) {
//do nothing
},
func(id string) {
CleanCache(id)
})
不同技术栈的最佳实践
1 Java
以 Maven 构建工具为例,其默认配置文件位于 conf/settings.xml 文件中,默认指定环境变量 $M2_HOME 来设置缓存目录,这样同一条流水线多次执行可以复用 ${M2_HOME}/.m2 目录 (缓存目录),甚至同一个应用下的多个分支之间都可以使用同一个缓存目录,就像本地构建一样。| | BASE 执行 |
|---|---|
| 无缓存 | 平均时间:5.26min |
| 有缓存 | 平均时间:41.462s |
| 提升效率 | 提升 87.3% |
| 缓存命中率 | 接近 100% |
2 NodeJs
在 nodejs 编译中,我们的缓存目录是当前用户空间,针对 node_modules 文件进行压缩打包,push 到 cfs;如果缓存命中,从 cfs 上 pull 并且解压到当前用户空间下,恢复缓存。使用举例
| | BASE 执行 |
|---|---|
| 无缓存 | 平均时间:58s |
| 有缓存 | 平均时间:29s |
| 提升效率 | 提升 50% |
| 缓存命中率 | 接近 100% |
3 Golang 编译
Golang 缓存路径通过$GOCACHE环境变量控制,将$GOCACHE的内容压缩成 zstd 的包,上传到 cfs 的指定路径下。pull 缓存的时候,拉取到对应的$GOCACHE。| | BASE 执行 |
|---|---|
| 无缓存 | 平均时间:117s |
| 有缓存 | 平均时间:18s |
| 提升效率 | 提升 84.6% |
| 缓存命中率 | 接近 100% |
4 GCC 编译
我们使用 ccache 进行缓存实现。ccache(“compilercache” 的缩写)是一个编译器缓存,该工具会高速缓存编译生成的信息,并在编译的特定部分使用高速缓存的信息。ccache 的缓存目录:CCACHE_DIR,我们将这个目录下的文件进行压缩,push 到 cfs,当第二次运行并且命中缓存,从 cfs 上 pull 并解压到 CCACHE_DIR 指定的目录下。总结
在不同语言的编译原子内部,默认开启缓存的设置。第一次运行流水线的时候,会进行依赖的下载,第二次运行流水线,会命中缓存,无需进行依赖的下载,提高了流水线执行的效率。缓存默认保存 7 天。自定义镜像进行缓存的最佳实践
为了满足用户使用自定义镜像的方式触发流水线,我们增加了两个通用的缓存原子。Restore 缓存:恢复缓存Save 缓存:保存缓存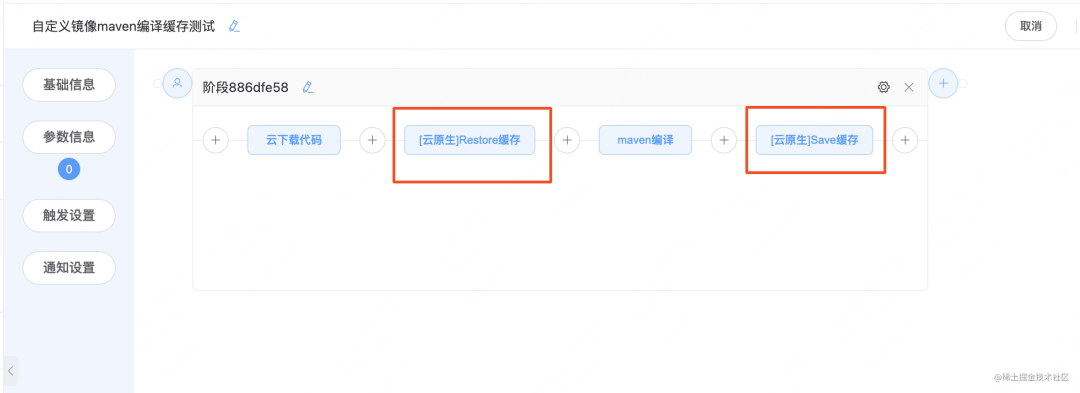 在编译之前,添加 Restore 缓存原子
在编译之前,添加 Restore 缓存原子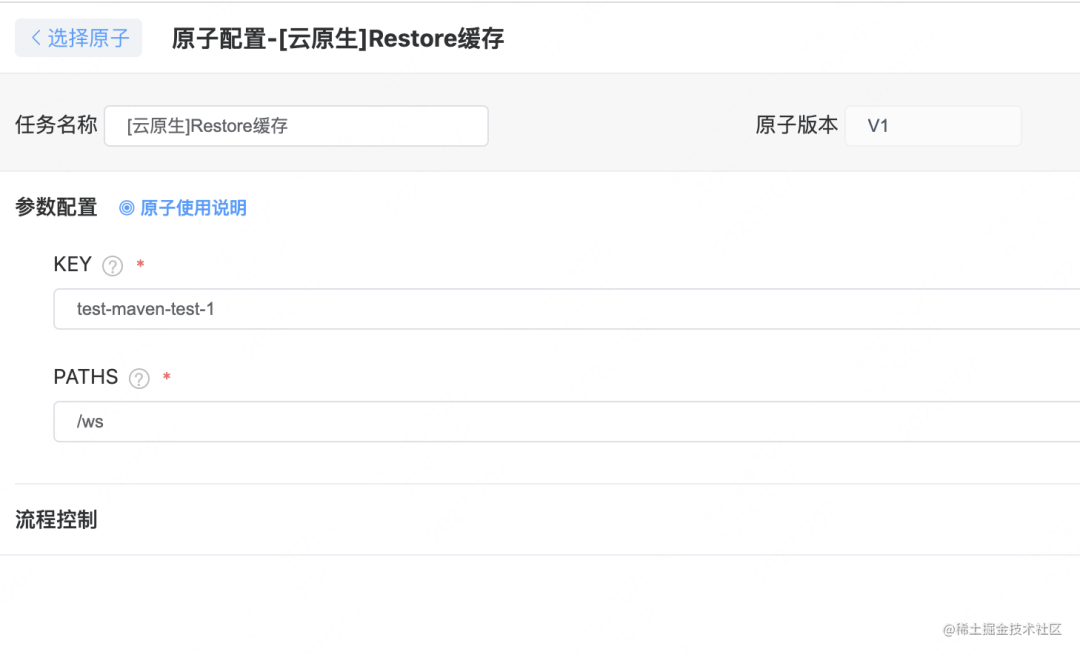 在编译之后,添加 Save 缓存原子
在编译之后,添加 Save 缓存原子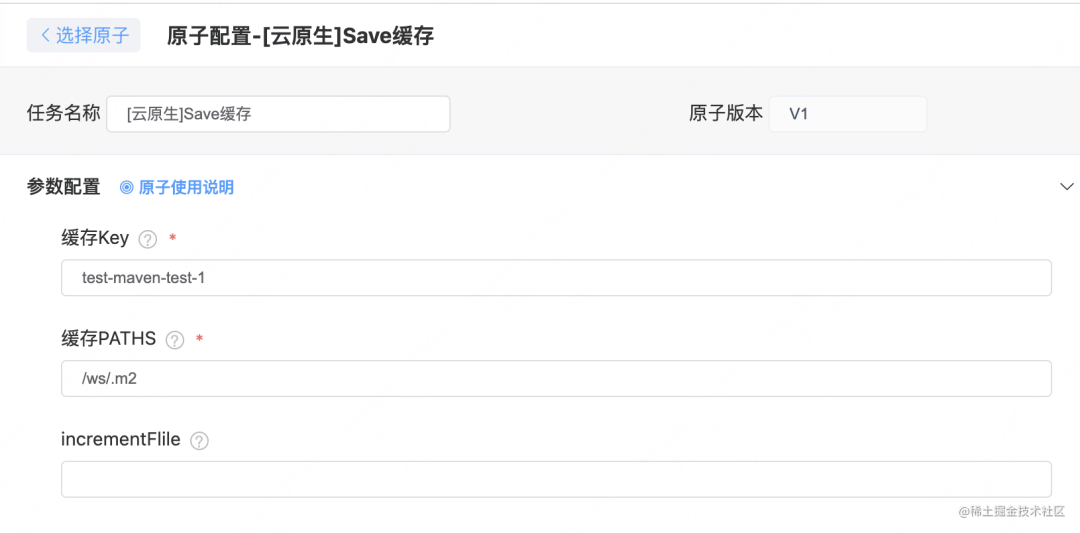
使用举例
在 maven 编译原子中,默认开启了 maven 编译的缓存;同时还有 nodejs 的编译构建,所以我们增加了 restore 原子和 save 原子
| | BASE 执行 |
|---|---|
| 无缓存 | 平均时间:21min57s 其中 maven: 17min83s nodejs: 4min19s |
| 有缓存 | 平均时间:4min20s 其中 maven: 1min10s nodejs: 2min36s |
| 缓存效率提升 | maven:93.7% nodejs:39.8%(nodejs 编译中有包含单元测试) |
| 缓存命中率 | 接近 100% |
未来规划
・不同编译原子,向用户开放配置,如是否开启缓存,设置缓存 key
・实现不同语言编译原子增量 push 缓存功能
审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
流水线
+关注
关注
0文章
120浏览量
25702 -
编译
+关注
关注
0文章
657浏览量
32850 -
云原生
+关注
关注
0文章
248浏览量
7947
原文标题:云原生场景下实现编译加速
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
性能提升1倍,成本直降50%!基于龙蜥指令加速的下一代云原生网关
不打折的情况下,用户部署网关的资源成本直降 50%。(图 8/云原生网关)MSE 云原生网关优势:网关直连业务 Pod IP,不经过传统 Cluster IP,RT 更低。支持 HTTPS 硬件
发表于 08-31 10:46
只需 6 步,你就可以搭建一个云原生操作系统原型
的时候,会发生什么故事?本文整理自 [2022 年阿里巴巴开源开放周技术演讲],让作者带我们走进这场技术盛宴。本次的分享主题围绕三个方面展开:首先简要介绍一下[龙蜥云原生 SIG(Special
发表于 09-15 14:01
云原生应用中的“云”指的是什么?
云原生应用是独立的小规模松散耦合服务的集合,旨在提供备受认可的业务价值,例如快速融合用户反馈以实现持续改进。简而言之,通过云原生应用开发,您可以加速构建新应用,优化现有应用并在
引领云原生2.0时代,赋能新云原生企业
十年云计算浪潮下,DevOps、容器、微服务等技术飞速发展,云原生成为潮流。Forrester首席分析师戴鲲表示,云原生是企业数字化转型的基础,企业需要建立云原生优先的战略,构建一体化
云原生解决了什么问题?
尽管Heroku、Pivotal、CNCF等众多厂商都对云原生下了不同的定义,但从本质上考虑,因为云原生构建了易观测松耦合容错性高的系统,所以其始终都在追求着三大目标:加速创新、降低成本、提高效率。

如何更好地构建云原生应用生态,推动业界更好地落地云原生
信息通信研究院相关调研数据显示,2019年我国云原生产业市场规模已达350.2亿元。数字经济大潮下,传统行业的数字化转型成为云原生产业发展的强劲驱动力,“新基建”带来的万亿级资本投入,也将在未来几年推动
解读腾讯云原生 鹅厂云原生的“新路”与“历承”
在云计算产业中,云原生是一个长期讨论的“老话题”。而在今年新基建、产业数字化的宏观背景下,云原生的应用主体开始扩张,关于这条技术路径的讨论也重新火热了起来。 云原生突然“翻红”的原因,
云原生技术下的华为云DevOps实践之路
和重视。 同样,为了应对业务的敏捷发布,应用平台的弹性诉求,商业环境的变化,云原生时代已到来,云原生技术已经应用到企业核心业务。 云原生与DevOps是什么关系?其技术优势如何与DevOps结合,才能更加高效便捷的实施呢?
华为云中什么是云原生服务中心
、统一存储、全域分发,帮助您简化云原生服务的生命周期管理。 UCS深度集成云原生服务中心的功能,可真正实现服务的开箱即用,有效提升云原生服务能力与质量,支持服务的订阅、部署、升级、更新
发表于 07-27 15:44
•700次阅读
什么是分布式云原生
体验,让客户在使用云原生应用时,感受不到地域、跨云、流量的限制,把云原生的能力带入到企业的每一个业务场景,加速千行百业拥抱云原生。 分布式
发表于 07-27 15:52
•1567次阅读
云原生应用加速 数字化+降本增效成为共识
云原生应用的概念由云和原生两个部分组成,云在这里指的是云平台,也就是平台即服务(Platform as a Service,PaaS);原生应用指的是专门针对云平台而设计和实现的,充分
发表于 07-27 16:30
•607次阅读
Java与云原生的矛盾原因
前阵子在 B 站刷到了周志明博士的视频,主题是云原生时代下 Java,主要内容是云原生时代下的挑战与 Java 社区的对策。
KubeOS:面向云原生场景的容器操作系统
在云原生场景下,容器和 Kubernetes 在开发、测试、生产中的应用越来越广泛,传统的操作系统往往会带来安全性、运维开销、OS 版本等方面的问题,容器操作系统即容器 OS 是针对云原生
中科驭数携手DaoCloud道客开拓DPU在云原生计算场景的应用
近日,中科驭数与DaoCloud 道客正式达成战略合作。本次合作依托中科驭数DPU技术优势与DaoCloud 道客云原生技术面向智算、超算、金融交易、电信等高性能云原生应用场景和行业领域,共同
云原生和非云原生哪个好?六大区别详细对比
云原生和非云原生各有优劣,具体选择取决于应用场景。云原生利用云计算的优势,通过微服务、容器化和自动化运维等技术,提高了应用的可扩展性、更新速度和成本效益。非





 工商网监
工商网监
评论