 什么是数字仿真?
什么是数字仿真?
数字硬件建模SystemVerilog(三)-仿真

数字仿真是一种软件程序,它将逻辑值变化(称为激励)应用于数字电路模型的输入,以实际硅传播这些逻辑值变化的相同方式通过模型传播该激励,并提供观察和验证该激励结果的机制。
SystemVerilog是一种使用0和1的数字仿真语言。该语言不表示仿真电压、电容和电阻。SystemVerilog提供的编程结构,用于对数字电路建模、对激励发生器建模以及对验证检查器建模。
示例1.4说明了一个可以仿真的简单数字电路模型。这与前面示例1.3所示的电路相同。

示例1-4:带有输入和输出端口的设计模型(32位加法器/减法器)在本例中,请注意模型具有输入端口和输出端口。为了仿真该模型,必须提供将逻辑值应用于输入端口的激励,并且必须提供响应检查器以观察输出端口。
使用testbench封装激励生成和响应验证。在SystemVerilog中有许多方法可以对测试台进行建模,测试台中的代码可以是简单的编程语句,也可以是复杂的面向对象、事务级编程,示例1-5说明了32位加法器/减法器设计的简单testbench。


示例1-5:32位加法器/减法器模型的testbench例1-5中的主要代码块是一个初始化过程,它是一种过程块,过程块包含编程语句和时序信息,用于指示仿真器做什么以及什么时候做。SystemVerilog有两种主要类型的程序块:initial procedures and always procedures。
初始过程是用关键字initial定义的。初始过程,不管其名称如何,都不用于初始化设计。相反,初始过程只执行一次编程语句。当到达最后一条语句时,对于给定的仿真运行,不会再次执行初始过程。初始过程不可综合,也不用于RTL建模。本系列着重于编写用于仿真和合成的RTL模型,因此不再深入讨论初始过程。
Always过程是用关键字always、always_comb、always_ff和always_latch定义的,Always过程是一个无限循环,当过程完成过程中最后一条语句的执行时,过程自动返回到开头,并再次启动过程。对于RTL建模,Always程序必须以灵敏度列表开始;例如示例1-4)中所示的@(posedge clk)定义。后面将更详细地讨论各种形式的always程序。
过程块可以包含一条语句,也可以包含一组语句。过程块中的多个语句在关键字begin和end之间分组(验证代码还可以在关键字fork和join、join_any或join_none之间分组语句)。begin和end之间的语句按其列出的顺序执行,即:从第一条语句开始,到最后一条语句结束。
示例1-5中的初始过程包含一个重复循环。这个循环被定义为执行10次。循环的每个过程:
- l、 延迟到c1k信号的下降沿。
-
- 为设计的a、b和mode输入生成随机值。
-
- 延迟到clk的下一个下降沿,然后调用检查结果任务(子例程)以验证设计输出是否与计算的预期结果匹配。
该设计在其时钟输入的上升沿工作。测试台使用同一时钟的相对边缘,以避免在设计使用的时钟边缘上驱动输入和读取设计的输出。如果测试台在时钟的下降沿驱动值,则在设计使用输入之前,这些输入的稳定设置时间为零。同样,如果测试台在时钟的下降沿验证设计结果,那么这些设计输出稳定的时间将为零。
在同一时刻修改和读取值被称为simulation竞争条件。使用设计时钟的相对边缘来驱动激励是测试台避免设计仿真竞争条件的一种简单方法,例如满足设计设置和保持时间要求。
测试台被建模为具有输入和输出端口的模块,类似于正在验证的设计。最后一步是将测试台端口连接到设计端口,并生成时钟。这是在顶级模块中完成的。示例1-6显示了这方面的代码。

示例1-6:将测试台连接到设计的顶层模块# 系统Verilog仿真器
所有SystemVerilog仿真器都有很多共同点,这对于理解如何编写能够正确仿真的SystemVerilog RTL模型至关重要。这些功能包括:编译、精化、仿真时间和仿真事件调度(compilation elaboration simulation time and simulation event scheduling),下面将讨论仿真的这些方面。
编译和精化Compilation and elaboration
SystemVerilog源代码需要编译和详细说明才能进行仿真。编译包括根据IEEE SystemVerilog标准中定义的规则检查SystemVerilog源代码,以确保其语法和语义正确。精化将构成设计和测试台的模块和组件绑定在一起。精化还解析可配置代码,例如常量的最终值、向量大小和仿真时间缩放。
IEEE SystemVerilog标准没有定义精确的编译和精化过程。标准允许每个仿真器供应商以供应商认为最适合该产品的方式定义该过程以及编译和精化之间的划分。一些仿真器将编译和精化过程作为单个步骤进行组合,而其他仿真器将这些过程划分为单独的步骤。一些仿真器可能在编译阶段捕获源代码中某些类型的错误,而其他仿真器在精化阶段捕获这些错误。这些差异不会影响本系列中讨论的RTL编码风格和指南,但了解所使用的仿真器如何处理RTL源代码的编译和精化是有帮助的。请参阅特定仿真器的文档,了解该产品如何处理编译和精化。
源代码顺序
SystemVerilog语言,与大多数语言一样;如果不是所有编程语言在源代码顺序上都有一定的依赖关系,那么在引用这些定义之前,必须编译用户定义的类型声明和声明包。用户定义的类型声明和包通常与使用声明的RTL代码位于不同的文件中。这意味着设计者必须注意这些文件是按正确的顺序编译的,因此声明是common的,在被引用之前堆积起来.
并非所有声明都是顺序相关的,例如,SystemVerilog允许在编译模块之前引用模块名称。在模块内,任务和函数可以在定义之前调用,只要定义在模块内。
全局声明和$unit声明空间
SystemVerilog允许在名为unit中的声明可以由多个文件共享,全局声明依赖于编译顺序,必须在引用之前编译,全局unit添加定义,这可能会导致随意的全局定义,从而难以确保在引用定义之前对其进行编译.
SystemVerilog编译器指令,如“定义文本宏和”时间刻度时间缩放,也属于$unit space,全局声明必须在受指令影响的代码之前编译。
最佳做法准则1-1
将包用于全局声明,而不是$unit声明空间。
单文件和多文件编译
当涉及多个文件时,IEEE SystemVerilog标准定义了两种编译/精化范例的规则:多文件编译和单文件编译。
多文件编译范例允许同时编译多个源代码文件。一个文件中的全局声明和编译器指令对于在声明和指令之后编译的其他文件中的源代码是可见的。
单文件编译范例允许独立编译每个文件。一个文件中的任何全局声明或编译器指令仅在该文件中可见。无论文件的编译顺序如何,其他文件都不会看到这些声明或指令。
所有仿真器和合成编译器都支持多文件范例,但并非所有工具都支持单文件编译,但是,默认情况下,支持两种范例的工具不一定使用相同的范例。默认情况下,某些工具使用单文件编译,多文件编译需要特定于工具的调用选项。默认情况下,其他工具使用多文件编译,并且需要调用选项进行单文件编译或增量重新编译。
关于仿真或者验证方面,还有很多很多内容,但是不是本系列重点,所以这里推荐《systemverilog验证》了解更多关于SV的仿真和验证知识。
-
数字电路
+关注
关注
193文章
1630浏览量
80906 -
模型
+关注
关注
1文章
3378浏览量
49334 -
数字仿真
+关注
关注
0文章
17浏览量
8106
发布评论请先 登录
相关推荐
使用ADS和VSA(89600)进行数字仿真错误怎么办?
什么是全数字仿真平台
什么是全数字仿真平台
使用Pulseview***数字设计仿真协议解码
高精度游移方位捷联惯导系统的数字仿真
基于LabVIEW的数字仿真实验平台的设计
基于实时数字仿真的保护校验与评估系统
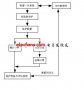
简单数字钟仿真电路图大全(五款数字钟仿真电路图)
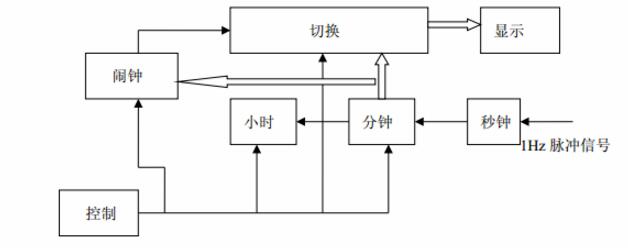
HLA雷达对抗数字仿真系统的应用





 工商网监
工商网监
评论